4. 分布式计算模型 MapReduce
- 1. MapReduce 概述
- 1. 概念
- 2. 程序演示
- 1. 计算 WordCount
- 2. 计算圆周率 π
- 3. 核心架构组件
- 4. 编程流程与规范
- 1. 编程流程
- 2. 编程规范
- 3. 程序主要配置参数
- 4. 相关问题
- 1. 为什么不能在 Mapper 中进行 “聚合”(加法)?为什么需要 “减速器”
- 2. RecordReader 的作用
- 5. 单词统计案例
- 1. 过程分析
- 2. 案例编写
- 1. 相关说明
- 2. JDK(Java)数据类型与 Hadoop 数据类型的对照关系
- 3. Mapper 类
- 4. Reducer 类
- 5. 主调度程序
- 6. 程序打成 jar 包在 HDFS 执行
- 3. Web 页面查看
- 4. 案例总结
- 5. 集群运行模式
- 2. MapReduce 组件
- 1. 分区组件 Partitioner
- 1. Partition 组件作用
- 2. 需求与思路
- 3. 示例代码
- 4. 相关问题与知识点
- 5. 编写自定义分区器
- 2. 排序组件与序列化
- 1. 排序组件 WritableComparable
- 2. 序列化与反序列化
- 3. 排序组件结合序列化的案例
- 3. 局部合并组件/合路器 Combiner
- 1. Combiner 概述
- 2. 案例:局部合并 Map 阶段的结果
- 4. 分组组件 Group
- 1. 概述
- 2. 案例:求每一个订单中成交额最大的一笔交易
- 3. 知识点与组件调优
- 1. 知识点
- 1. MapReduce 框架中的分布式缓存
- 2. Reducers 之间如何通信
- 3. SequenceFileInputFormat
- 2. 组件的默认内存与调节建议
- 3. MapReduce 项目实战
- 需求一:统计每个手机号的数据包和流量总和
- 需求二:将需求一中结果按照 upFlow 流量倒排
- 需求三:手机号码分区
- 4. MapReduce 的 Shuffle 和 YARN
- 1. Shuffle 原理详解
- 1. Shuffle 概述
- 2. Shuffle 机制
- 3. Shuffle 图解优化版
- 4. Shuffle 核心执行流程图
- 5. Shuffle 详细图解
- 6. 环形缓冲区内部图解
- 7. Shuffle 优化
- 2. 资源调度框架 YARN
- 1. YARN概述
- 2. Hadoop 版本间对比
- 3. YARN 的重要概念
- 1. 主节点 ResourceManager
- 2. 从节点 NodeManager
- 3. 容器 Container
- 4. YARN 架构图
- 5. 作业提交流程
- 5. hadoop 宕机
1. MapReduce 概述
1. 概念
map 并发 reduce 汇总
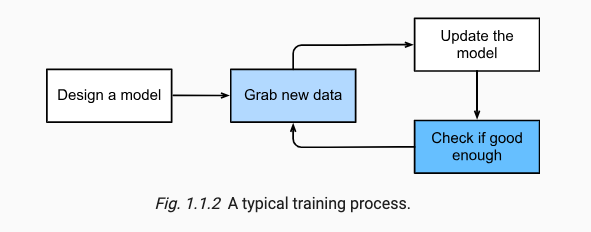
MapReduce 是一个分布式的计算编程框架(或编程模型),属于一个半成品,并行计算框架。
在一个完整的分布式计算任务代码编写过程中,对程序员来说,除了业务之外的所有代码都不写最好。封装通用代码,对业务代码提供编写规范。
【MapReduce 核心功能】:将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
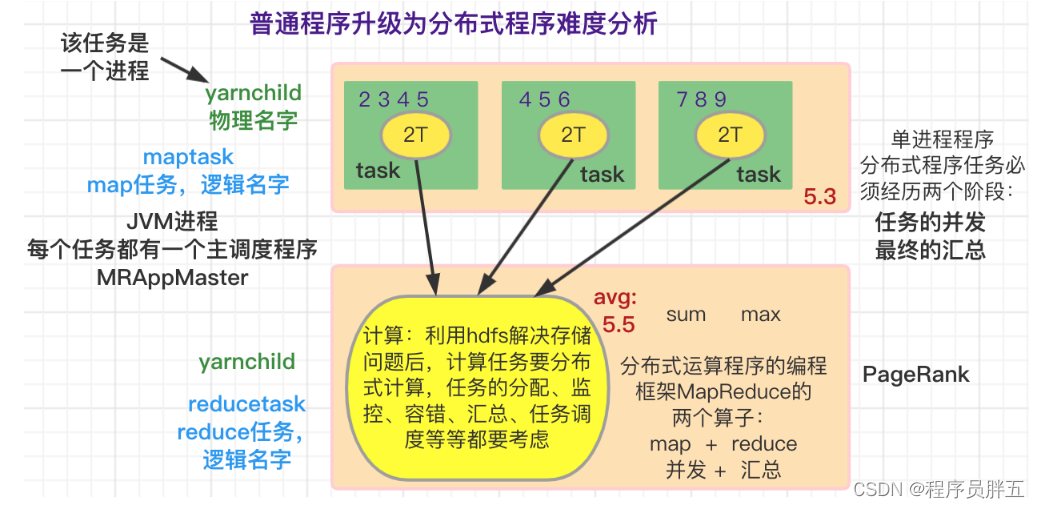
普通程序升级为分布式程序难度分析:
相关说明:
- 增加了计算任务调度的复杂性
- 求和求最值都可以,但求平均值不能用。因为并发计算完和单个执行完再汇总得到的结果不一致
- 任务的协调和分配是很大的问题,MapReduce 把这些都搞定,用户仅根据它提供的业务代码规范做开发即可
分布式版本遇到的问题:
- 数据量变大后引发的问题:存储和计算
- 利用 HDFS 解决存储,计算任务要分散计算
- 分散计算的问题:
- 任务的分配:找到数据存储在哪些节点上,然后在这些节点上对该数据块启动计算任务
- 监控:执行任务节点很多,个别节点上的任务出现问题,需要对其进行处理
- 容错
- 中间结果的汇总
- 运算的逻辑至少分为了两个阶段:map 并发 + reduce 汇总
- 这两个阶段的任务启动、协调
- 运算程序到底如何执行、程序和计算如何互相流转
- 多阶段计算任务的分配
为什么需要 MapReduce?
- 海量数据在单机上处理的话,由于硬件资源有限,无法胜任
- 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂性和开发难度
- 引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,将分布式计算中的复杂性交由框架去处理
2. 程序演示
1. 计算 WordCount
(1)HDFS 上创建一个 wc 的文件夹
[root@hadoop0 ~]# hdfs dfs -mkdir -p /0320/mr/wc
(2)本地准备一个 txt 文件并上传到 HDFS wc 目录下
[root@hadoop0 ~]# cat /home/data/mr/wc.txt
hello hadoop
hello mapreduce
[root@hadoop0 ~]# hadoop fs -put /home/data/mr/wc.txt /0320/mr/wc
(3)执行官方 WordCount 案例(该条语句会对 /0320/mr/wc/ 文件夹下的文件进行单词的个数处理,将结果存储在 /0320/mr/wcout 文件夹下,该文件夹自动创建):
hadoop jar /software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /0320/mr/wc/wc.txt /0320/mr/wcout
(4)查看 HDFS /0320/mr/ 下会多出 wcout 文件夹,查看其内容(单词个数统计的结果在 part-r-00000 文件内)
[root@hadoop0 ~]# hdfs dfs -ls /0320/mr/wcout/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2023-03-20 18:14 /0320/mr/wcout/_SUCCESS
-rw-r--r-- 1 root supergroup 29 2023-03-20 18:14 /0320/mr/wcout/part-r-00000
[root@hadoop0 ~]# hdfs dfs -cat /0320/mr/wcout/p*
hadoop 1
hello 2
mapreduce 1
2. 计算圆周率 π
运行官方案例,给定 map 数量和 reduce 数量:5、5,这两个数给的越大,计算结果越准确,但计算时间会更长
[root@hadoop0 ~]# cd /software/hadoop/share/hadoop/mapreduce/
[root@hadoop0 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 5 5
Number of Maps = 5
Samples per Map = 5
Wrote input for Map #0
...
Wrote input for Map #4
Starting Job
...
Job Finished in 4.468 seconds
Estimated value of Pi is 3.68000000000000000000
[root@hadoop0 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 50 50
Number of Maps = 50
Samples per Map = 50
Wrote input for Map #0
Wrote input for Map #1
... Wrote input for Map #49
Starting Job
...
Job Finished in 9.635 seconds
Estimated value of Pi is 3.14080000000000000000
3. 核心架构组件
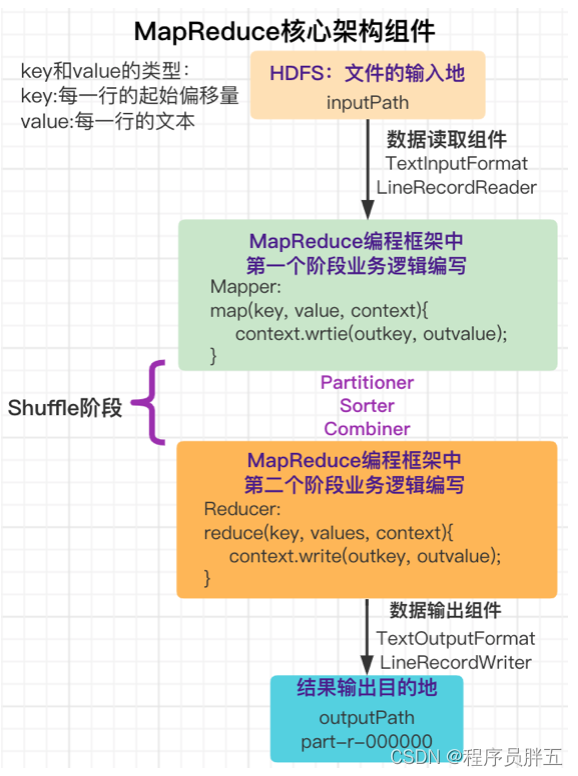
组件说明:
- inputPath:输入文件,可以是一个目录,也可以是个文件
- TextInputFormat/LineRecordReader:数据读取组件
- Mapper:执行业务逻辑计算,主要通过 map() 方法处理,输出 key 和 value 的值,context 是写入上下文的组件
- Shuffle:分区 Partitioner、排序 Sorter、局部合并 Combiner、分组 Group
- Reducer:reduce() 方法接收到一组 (key, value) 的数据
- TextOutputFormat/LineRecordWriter:数据输出组件
- outputPath:结果文件的位置
开发说明:
- 写业务逻辑代码的组件:map()、reduce()
- 最外层写组件调度程序,将各个组件串行起来
- 对于业务需求不是很特别,则无需修改其他组件的内容
4. 编程流程与规范
1. 编程流程

2. 编程规范
1. MapReduce 程序的业务编码分为两大部分
- 配置程序的运行信息
- 编写该 MapReduce 程序的业务逻辑,并且业务逻辑的 map 阶段和 reduce 阶段分别继承 Mapper 类和 Reducer 类
2. MapReduce 程序具体编写规范
- 用户编写的程序分为三个部分:Mapper、Reducer、Driver(提交运行 MapReduce 程序的客户端)
- Mapper 的输入和输出数据都是 KV 对的形式(KV 的类型可自定义)
- Mapper 中的业务逻辑写在 map() 方法中,map() 方法(maptask 进程)对每一个 <k,v> 组调用一次
- Reducer 的输入数据类型对应Mapper的输出数据类型,也是 KV 对的形式
- Reducer 的业务逻辑写在 reduce() 方法中,ReduceTask 进程对每一组相同K的 <k,v> 组调用一次 reduce() 方法
- 用户自定义的 Mapper 和 Reducer 都要继承各自的父类
- 整个程序需要一个 Driver 来进行提交,提交的是一个描述了各种必要信息的 job 对象
3. 程序主要配置参数
MapReduce 框架中用户需要指定的主要配置参数有:
- 分布式文件系统中作业的输入位置
- 作业在分布式文件系统中的输出位置
- 数据输入格式
- 数据输出格式
- 包含 Map 功能的类
- 包含 Reduce 函数的类
- 包含映射器、减速器和驱动程序类的 jar 文件
4. 相关问题
1. 为什么不能在 Mapper 中进行 “聚合”(加法)?为什么需要 “减速器”
- 不能在 Mapper 中执行 “聚合”(加法),是因为在 Mapper 函数中不会发生排序。排序只发生在 Reducer 端,没有排序聚合是无法完成的
- 在 “聚合” 期间,我们需要所有映射器函数的输出,这些输出在映射阶段可能无法收集,因为映射器可能运行在存储数据块的不同机器上
- 最后,如果我们尝试在 Mapper 上聚合,它需要在可能运行在不同机器上的所有 Mapper 函数之间进行通信。因此它会消耗高网络带宽并可能导致网络瓶颈
2. RecordReader 的作用
- InputSplit 定义了一个工作片段,但没有描述如何访问它。RecordReader 类 从其源加载数据并将其转换为适合 Mapper 任务读取的(键、值)对。RecordReader 实例由 “输入格式” 定义
5. 单词统计案例
1. 过程分析
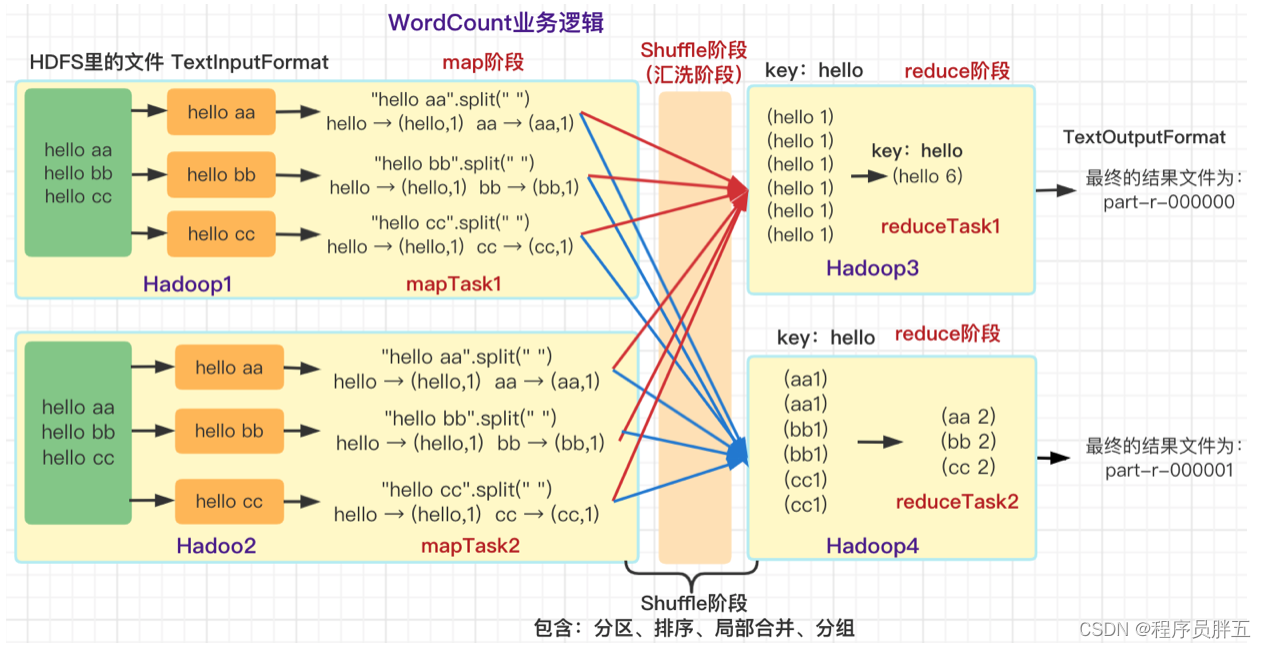
- Map 并行 阶段:TextInputFormat 组件对每个节点上的文件内容进行遍历读取,以
行为单位获取到对应数据,使用split()方法将单词分隔开,每个单词组织成 (word, 1) 的形式 - Shuffle 阶段:经过 分区、排序、局部合并、分组 阶段,将每个节点上组织好的单词进行
Hash分析,选出相同的单词放到单独的节点上 - Reduce 汇总 阶段:将相同单词个数进行统计,得出 (word, count) 的形式,TextOutputFormat 组件将得到的数据存到 part-r-0000 这样格式的文件内(part 表示部分,r 表示 reduce 的结果,map 的结果是 m)
- 主要是 Map 和 Reduce 两阶段
说明:
- 如果 Shuffle 到 Reduce 阶段,该节点挂了,主节点会找一台可用节点把这些数据放上去重新执行
- Hadoop 平台查看某一个时间段执行的任务信息:jobhistory
2. 案例编写
1. 相关说明
Map 和 Reduce 为程序员提供了一个清晰的操作接口抽象描述。MapReduce 中定义了如下的 Map 和 Reduce 两个抽象的编程接口,由用户去编程实现 Map 和 Reduce。MapReduce 处理的数据类型是 <key, value> 键值对
Map: (k1, v1) → [(k2, v2)]
Recude: (k2, [v2]) → [(k3, v3)]
程序划分为:Mapper 类、Reducer 类、整个的主调度程序
- 依赖文件:pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2. JDK(Java)数据类型与 Hadoop 数据类型的对照关系
String、Long 等是 JDK 里的数据类型,在序列化时效率低。Hadoop 为了提高效率,自定义了一套序列化的类型。在 Hadoop 的程序中,如果要进行序列化(写磁盘、网络传输等),一定要使用 Hadoop 实现的序列化的数据类型:
| Java 类型 | Hadoop 类型 |
|---|---|
| Long | LongWritable |
| String | Text |
| Integer | IntWritable |
| Null | NullWritable |
3. Mapper 类
Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 类
- KEYIN:指框架读取到的数据集的 key 的类型,默认情况下读取到的 key 是一行数据相对整个文本开头的偏移量。当 key 类型是 JDK 的 Long 类型时,对应 Hadoop 的 LongWritable
- VALUEIN:指框架读取到的数据集的 value 的类型,默认情况下读取到的 value 是一行文本。value 的类型是 String,对应 Hadoop 的 Text
- KEYOUT:指用户自定义的业务逻辑方法中返回数据的 key 的类型,由用户根据业务逻辑自己决定。在 WordCount 程序中,该 key 是单词,key 的类型是 JDK 的 String 类型,对应 Hadoop 的 Text
- VALUEOUT:指用户自定义的业务逻辑方法中返回数据的 value 的类型,由用户根据业务逻辑自己决定。在 WordCount 程序中,该 value 是次数(个数),value 类型是 Long 类型,对应 Hadoop 的 LongWritable
实现 map(KEYIN key, VALUEIN value, Context context) 方法
- key:偏移量
- value:一行的文本数据
- context:上下文对象
代码:WordMapper.java
package WordCount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// key:偏移量、value:一行的文本数据、context:上下文对象
public class WordMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 切分单词
String[] words = value.toString().split(" ");
// 2. 计数一次,将单词转换成类似于 <hello, 1> 这样的key-value键值对
for (String word : words) {
// 3. 写入上下文
context.write(new Text(word), new LongWritable(1));
}}}
4. Reducer 类
Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 类
- KEYIN:Map 阶段输出过来的 key(单词)的类型(Text)
- VALUEIN:Map 阶段输出过来的 value(次数)的类型(LongWritable)
- KEYOUT:最终要输出的 key 的类型,即单词的类型
- VALUEOUT:最终输出的 value 的类型,即次数的类型
实现 reduce(KEYIN key, Iterable<VALUEIN> values, Context context) 方法
- key:单词
- values:相同单词的次数
- context:上下文对象
代码:WordReducer.java
package WordCount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
// key: 偏移量、value: 一行的文本数据、context: 上下文对象
public class WordReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
// 1. 定义一个统计的变量
long count = 0;
// 2. 迭代
for (LongWritable value : values) {
count += value.get();
}
// 3. 写入到上下文中
context.write(key, new LongWritable(count));
}}
5. 主调度程序
相关说明:
- 主类:将 Mapper 和 Reducer 阶段串起来,提供程序运行入口
- main 是程序的入口,用一个
Job对象管理这个程序运行的很多 参数- 指定用哪个类作为 Mapper 的业务逻辑类,指定哪个类用 Reducer 的业务逻辑类…等等其他的各种需要的参数
- args
- 该程序在本地获取文件并将执行结果存储在本地指定目录下
- 输出结果的目录不能存在,否则报错
代码:JobMain.java
package WordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/* 一、初始化一个Job对象 */
Job job = Job.getInstance(new Configuration(), "WordCount");
/* 二、设置Job对象的相关信息,里面包含8个小步骤 */
// 1. 设置输入路径,让程序能找到输入文本的位置
job.setInputFormatClass(TextInputFormat.class); // 默认的输入类的类型,可以不写
// 本地文件
TextInputFormat.addInputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/data.txt"));
// hdfs文件
// TextInputFormat.addInputPath(job, new Path("hdfs://hadoop0:8020/0320/mr/wc/wc.txt"));
// 2. 设置Mapper的类型,并设置k2,v2
job.setMapperClass(WordMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 3,4,5,6 四个步骤都是shuffle阶段,暂时按默认的
// 7. 设置Reducer的类型,并设置k3,v3
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 8. 设置输出路径,让程序把结果放到一个地方去
job.setOutputFormatClass(TextOutputFormat.class); // 默认的输出类的类型,可以不写
TextOutputFormat.setOutputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/wcout"));
// TextOutputFormat.setOutputPath(job, new Path("hdfs://hadoop0:8020/0320/mr/wc/wcout"));
/* 三、等待程序完成 */
boolean b = job.waitForCompletion(true);
System.out.println(b);
System.exit(b ? 0 : 1); // 退出程序
}}
- 待执行的文件内容:
# /Users/jason93/Desktop/BigData/file/mr/data.txt
hello hadoop
hello mapreduce
- 执行结果返回 true,在本地查看新生成的文件内容:
➜ ~ ls -lrt /Users/jason93/Desktop/BigData/file/mr/wcout
total 8
-rw-r--r-- 1 jason93 staff 29 3 21 08:52 part-r-00000
-rw-r--r-- 1 jason93 staff 0 3 21 08:52 _SUCCESS
➜ ~ cat /Users/jason93/Desktop/BigData/file/mr/wcout/p*
hadoop 1
hello 2
mapreduce 1
6. 程序打成 jar 包在 HDFS 执行
需求:将 MapReduce 模块打包成 jar 格式运行在 HDFS 上
(1)将 JobMain.java 文件中的输入输出都替换成 HDFS 上的路径
- 注意:HDFS 上相应路径下要上传 wc.txt
TextInputFormat.addInputPath(job, new Path("hdfs://hadoop0:8020/0320/mr/wc/wc.txt"));
TextOutputFormat.setOutputPath(job, new Path("hdfs://hadoop0:8020/0320/mr/wc/wcout"));
(2)idea 在 Maven 中找到 MapReduce 模块中的 lifecycle 的 package 双击,等待返回 BUILD SUCCESS
(3)在本地 MapReduce 模块的 target 里找到 MapReduce-1.0-SNAPSHOT.jar,用 xshell 或 filezilla 等传输软件传入 CentOS 机器,cd 到该文件目录下
(4)复制 JobMain 时鼠标右击选择 copy reference 即可
(5)执行 jar:
[root@hadoop0 mr]# hadoop jar MapReduce-1.0-SNAPSHOT.jar WordCount.JobMain
...
# 最后返回 true
(6)最后做下验证,查看下的文件及其内容
[root@hadoop0 mr]# hdfs dfs -ls /0320/mr/wc/wcout
Found 2 items
-rw-r--r-- 1 root supergroup 0 2023-03-21 08:44 /0320/mr/wc/wcout/_SUCCESS
-rw-r--r-- 1 root supergroup 29 2023-03-21 08:44 /0320/mr/wc/wcout/part-r-00000
[root@hadoop0 mr]# hadoop fs -cat /0320/mr/wc/wcout/p*
hadoop 1
hello 2
mapreduce 1
3. Web 页面查看
MapReduce 执行 Job 后,若 DataNode 由 Yarn 托管,可以在 Yarn 的页面查看 JobHistory
(1)需要配置相关文件如下:
- yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop0:19888/jobhistory/logs/</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
- mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop0:19888</value>
</property>
(2)启动 zk、Hadoop 之后,再在每个节点启动 JobHistory 服务:
/software/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
[root@hadoop0 spark]# jps
10359 JobHistoryServer
(3)执行一个 MapReduce 任务:
[root@hadoop0 hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar pi 10 10
- 最后等待完成:
(4)Web 页面查看 http://hadoop0:8088/
- http://hadoop0:19888/ 也可以
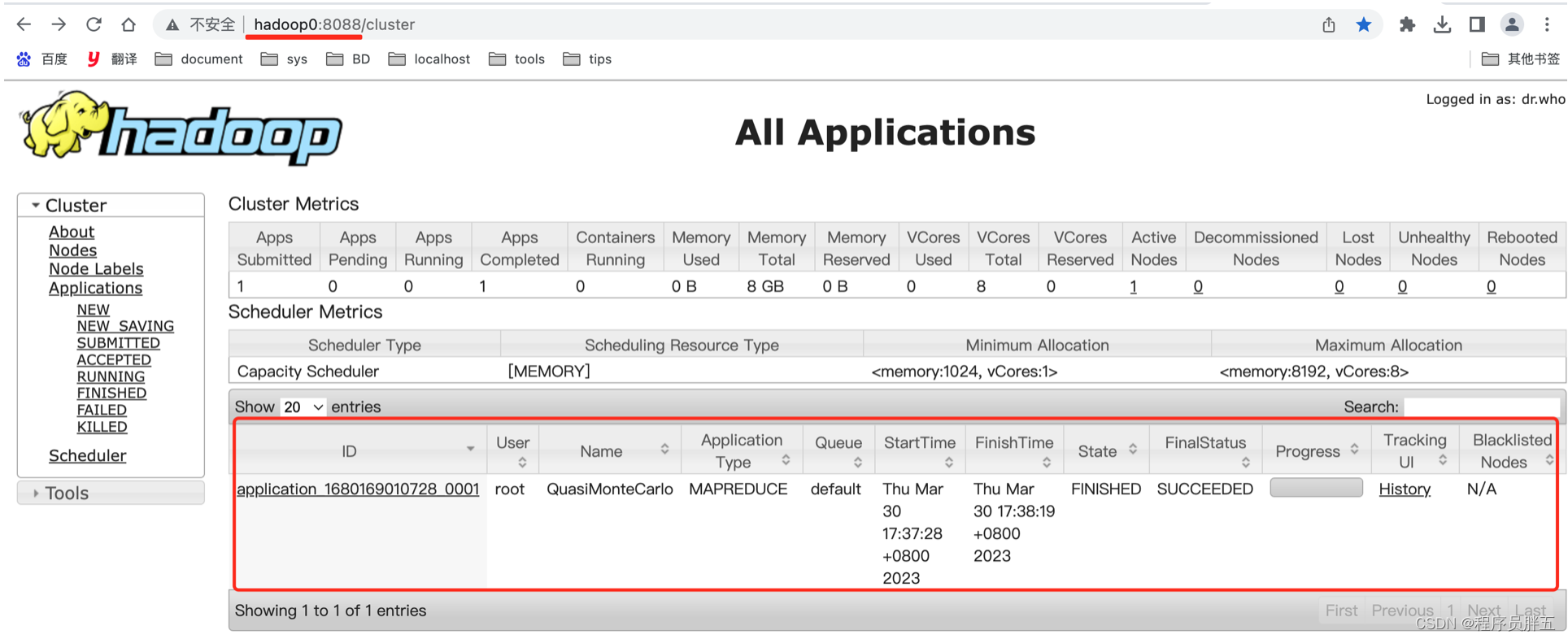
4. 案例总结
执行流程图:
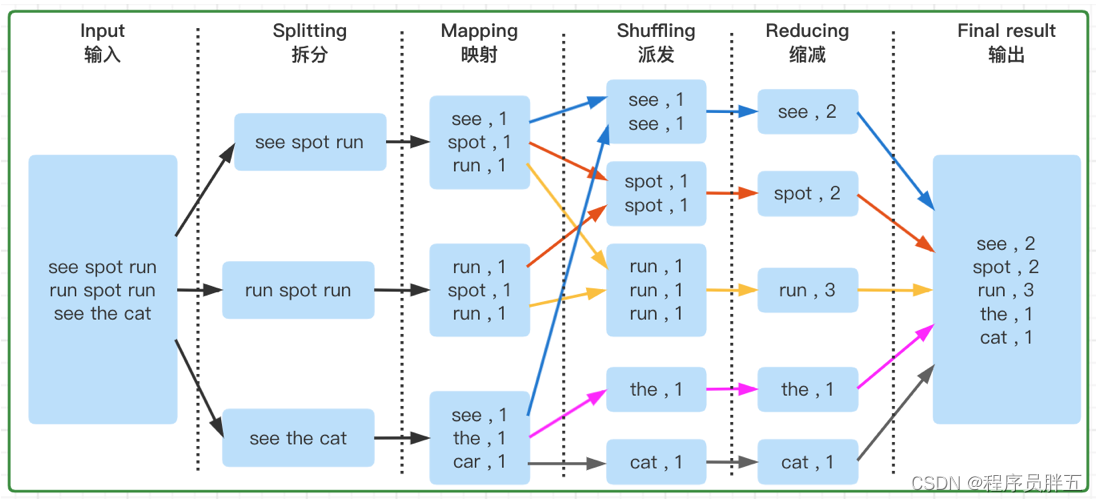
- Map 和 Reduce 有先后顺序:Map 阶段在前,Reduce 阶段在后。Map 内部有多个线程并发执行每个块上的任务,Reducer 后汇总
- JobMain 中输入输出的路径配置以及其他地址的相关配置应该写入一个配置文件,在此处做引用,不要写死,可通过 main 的
args参数输入
5. 集群运行模式
- 将 MapReduce 程序提交给 YARN 集群,分发到很多节点上并发执行
- 处理的数据和输出的结果应该位于 HDFS 文件系统
- 提交集群的实现步骤:将程序打成 jar 包,然后在集群的任一节点上用
hadoop命令启动:
hadoop jar jar包名 class类名
2. MapReduce 组件
1. 分区组件 Partitioner
1. Partition 组件作用
确保单个键的所有值都进入同一个 Reducer,从而允许在 Reducer 上均匀分布 Map 输出。它通过确定哪个 Reducer 负责特定键,将 Mapper 输出重定向到 Reducer
2. 需求与思路
需求:根据单词的长度进行判断,单词长度 >= 6 的在一个结果文件中,单词长度 < 6 的在另一个文件中,以便于再快速查询
思路:
- 定义 Mapper 逻辑
- 定义 Reducer 逻辑
- 自定义分区 Partitioner(这个案例主要的逻辑在这里面)
- 主调度入口 JobMain
3. 示例代码
说明:Mapper 和 Reducer 跟上边 WordCount 一样,只是多了 Partitioner
继承 Partitioner<KEY, VALUE> 类
- KEY:单词的类型
- VALUE:单词的次数的类型
实现 getPartition(KEY key, VALUE value, int numPartitions) 方法
- key:Reduce 输出的 key 的类型
- value:Reduce 输出的 value 的类型
- numPartitions:指定分区数
MyPartitioner.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text, LongWritable> {
// return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
@Override
public int getPartition(Text text, LongWritable longWritable, int numPartitions) {
// return 的 0 和 1 是分区编号
if (text.toString().length() >= 6) {
return 0;
} else { // 小于5的
return 1;
}}}
JobMain.java 相关说明:
- 需求:根据单词的长度给单词出现次数的结果存储到不同文件中
- 代码与上边的 WordCount 的 JobMain 一样,只是增加了分区设置和指定了 Reduce 的任务数
// 3,4,5,6 Shuffle,3.设置分区
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(2);
- 运行后返回 true,去指定目录下查看:
➜ ~ ls -lrt /Users/jason93/Desktop/BigData/file/mr/partwcout
total 16
-rw-r--r-- 1 jason93 staff 21 3 21 09:28 part-r-00000
-rw-r--r-- 1 jason93 staff 8 3 21 09:28 part-r-00001
-rw-r--r-- 1 jason93 staff 0 3 21 09:28 _SUCCESS
➜ ~ cat /Users/jason93/Desktop/BigData/file/mr/partwcout/part-r-00000
hadoop 1
mapreduce 1
➜ ~ cat /Users/jason93/Desktop/BigData/file/mr/partwcout/part-r-00001
hello 2
4. 相关问题与知识点
- Mapper、Reducer 的上下文是怎么传递交互的?
- context 封装一个对象,相当于一个消息载体,在上下文之间进行传递
- 执行程序没报错,但最后返回 false,如何排查原因?
- 去输入输出的地方找,很有可能是切分单词 split 设置错误;或查看 import 引入的包是否正确
- 分区是 2,设置的 setNumReduceTasks 的个数是 3,那最终的结果文件是几个?
- 结果是 3 个。编号后缀 0 和 1 的有内容,2 的为空
- NumReduceTasks 设置多少,并发就是多少
5. 编写自定义分区器
可按照以下步骤轻松编写 Hadoop 作业的自定义分区器:
- 创建一个扩展 Partitioner 类的新类
- 覆盖方法 getPartition,在 MapReduce 中运行的包装器中
- 使用 set Partitioner 方法 将自定义分区程序添加到作业,或将自定义分区程序作为配置文件添加到作业
2. 排序组件与序列化
1. 排序组件 WritableComparable
Writable 有一个子接口 WritableComparable,它既可以实现序列化,又可以 对 key 进行比较。可通过自定义 key 实现 WritableComparable 来实现排序功能。
说明:Writable 只实现序列化和反序列化,没有比较的方法
2. 序列化与反序列化
概念:
- 序列化:(Serialization):结构化对象转换为字节流
- 反序列化(Deserialization):把字节流转换为结构化对象
使用场景:在进程间传递对象或持久化对象时,需要序列化对象成字节流;反之当接收到从磁盘读取的字节流转换为对象,要进行反序列化。
Java 与 Hadoop 的序列化框架概述:
- Java 的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息、Header、继承体系等),不便于在网络中高效传输。所以 Hadoop 自己开发了一套序列化机制(Writable),更加精简高效
- Hadoop 中的序列化框架已经对基本类型和 null 提供了序列化的实现了,分别是:
| Java | Hadoop |
|---|---|
| byte | ByteWritable |
| short | ShortWritable |
| int | IntWritable |
| long | LongWritable |
| float | FloatWritable |
| double | DoubleWritable |
| String | Text |
| null | NullWritable |
3. 排序组件结合序列化的案例
**需求:**数据格式如下,要求第一列按照字典顺序进行排序,第一列相同时,第二列按照升序进行排序
原始数据 期望数据
a 1 a 1
a 3 a 2
b 1 a 3
a 2 b 1
c 2 c 1
c 1 c 2
思路:
- 将 Mapper 端输出的 <key, value> 中的 key 和 value 组合成一个新的 key,value 值不变,也就是新的 key 和 value 为:<(key,value), value>
- 在针对新的 key【(key, value)】排序时,如果 key 相同,就再对 value 排序
思路转换:
- 定义一个实体对象 MySortBean,把 key 和 value 都放到该对象中
- 该实体对象继承 WritableComparable:
implements WritableComparable<实体对象名>
- 该实体对象继承 WritableComparable:
- 定义 SortMapper 类
- 定义 SortReducer 类
- 主调度入口 JobMain
知识点:Job 调用 MySortBean 的排序实现的目的:快速排序、规避排序
代码:
(1)MySortBean.java 定义实体对象,把 key 和 value 放到该对象中
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class MySortBean implements WritableComparable<MySortBean> {
// 1. 定义key的key、value
private String word;
private int num;
// 2. 定义 get、set、toString 的方法(Mac用Ctrl+Enter快捷键调出)
public String getWord() {return word;}
public void setWord(String word) {this.word = word;}
public int getNum() {return num;}
public void setNum(int num) {this.num = num;}
@Override
public String toString() {
return "MySortBean{" + "word='" + word + '\'' + ", num=" + num + '}';
}
/**
* 比较器:按定义规则进行排序
* 排序规则:要求第一列按照字典顺序进行排序,第一列相同时,第二列按照升序进行排序
* @param o:MySortBean的对象
* @return result:第一列和第二列的差值
*/
@Override
public int compareTo(MySortBean o) {
// 1. 比较第一列,比较结果有3种: >0、==0、<0
int result = this.word.compareTo(o.word);
// 2. 第一列相同时比较第二列
if (result == 0) {
return this.num - o.num;
}
return result;
}
/**
* 实现序列化
* @param dataOutput:输出数据
* @throws IOException:异常捕获
*/
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(word);
dataOutput.writeInt(num);
}
/**
* 实现反序列化
* @param dataInput:输入数据
* @throws IOException:异常捕获
*/
@Override
public void readFields(DataInput dataInput) throws IOException {
this.word = dataInput.readUTF();
this.num = dataInput.readInt();
}}
(2)SortMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SortMapper extends Mapper<LongWritable, Text, MySortBean, NullWritable> {
// LongWritable:一行文本的偏移量的类型;Text:一行的文本的类型
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 拆分数据,一行文本作为一个拆分
String[] fields = value.toString().split(" ");
// 2. 将对应的值传到MySortBean的实例对象中
MySortBean mySortBean = new MySortBean();
mySortBean.setWord(fields[0]);
mySortBean.setNum(Integer.parseInt(fields[1]));
// 3. 写入到上下文
context.write(mySortBean, NullWritable.get());
}}
(3)SortReducer.java
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SortReducer extends Reducer<MySortBean, NullWritable, MySortBean, NullWritable> {
/**
* Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:MySortBean
* VALUEIN:NullWritable
* KEYOUT:MySortBean
* VALUEOUT:NullWritable
*/
@Override
protected void reduce(MySortBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// 将Map阶段拿过来的结果进行汇总
context.write(key, NullWritable.get());
}}
(4)JobMain.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 一、初始化一个Job对象
Job job = Job.getInstance(new Configuration(), "sort");
// 二、Job的相关设置
// 1. 设置输入路径
TextInputFormat.addInputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/sort.txt"));
// 2. 设置Mapper的类型,并设置 k2、v2
job.setMapperClass(SortMapper.class);
job.setMapOutputKeyClass(MySortBean.class);
job.setMapOutputValueClass(NullWritable.class);
// 3,4,5,6 shuffle 使用默认
// 7. 设置Reducer的类型,并设置k3、v3
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(MySortBean.class);
job.setOutputValueClass(NullWritable.class);
// 8. 设置输出路径
TextOutputFormat.setOutputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/sortwcout"));
// 三、等待完成,退出
boolean b = job.waitForCompletion(true);
System.out.println(b);
System.exit(b ? 0 : 1);
}}
- 执行程序返回true,在本地查看结果:(说明:
toString()方法可自行修改输出的格式)
➜ ~ ls -lrt /Users/jason93/Desktop/BigData/file/mr/sortwcout
total 8
-rw-r--r-- 1 jason93 staff 156 3 21 10:32 part-r-00000
-rw-r--r-- 1 jason93 staff 0 3 21 10:32 _SUCCESS
➜ ~ cat /Users/jason93/Desktop/BigData/file/mr/sortwcout/part-r-00000
SortWord{word='a', num=1}
SortWord{word='a', num=2}
SortWord{word='a', num=3}
SortWord{word='b', num=1}
SortWord{word='c', num=1}
SortWord{word='c', num=2}
3. 局部合并组件/合路器 Combiner
1. Combiner 概述
Combiner 是一个执行本地 Reduce 任务的迷你 Reducer,它从特定节点上的 映射器 接收输入,并将输出发送到 减速器。组合器通过减少需要发送到减速器的数据量来提高 MapReduce 的效率。Combiner 是 MapReduce 程序中 Mapper 和 Reducer 之外的一种组件,作用是在 MapTask 之后给 MapTask 的结果进行局部合并,以减轻 ReduceTask 的计算负载,减少网络传输。
使用 Combiner: Combiner 和 Reducer 一样,编写一个类,继承 Reducer,reduce() 方法中写具体的 Combiner 逻辑,然后在 Job 中设置 Combiner 组件:
job.setCombinerClass(MyCombiner.class)
知识点: 是不是可以不定义 Combiner 类,直接在 Job 里设置 Combiner 类为 Reducer 类?
- 不可以。JobMain 无法识别是 Combiner 还是 Reducer,如果在 JobMain 中设置 Reducer,只能是 Reduce 阶段做合并
2. 案例:局部合并 Map 阶段的结果
说明:通过 WordCount 案例进行继续的演示
代码: WordMapper.java 和 WordReducer.java 一样,JobMain.java 中只加入 Combiner 的类即可
- JobMain.java
// 5. 设置Combiner
job.setCombinerClass(MyCombiner.class)
// 设置输入输出路径
TextInputFormat.addInputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/data.txt"));
TextOutputFormat.setOutputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/comwcout"));
- MyCombiner.java(其实跟 Reducer 一样,只是在 Mapper 和 Reducer 之间多加了一层合并)
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
* KEYIN:map阶段传递过来的key的类型
* VALUEIN:map阶段传递过来的value的类型
* KEYOUT:局部合并的key的类型
* VALUEOUT:局部合并的value的类型
*/
public class MyCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
// 1. 定义一个变量
int count = 0;
// 2. 进行累加
for (LongWritable value : values) {
count += value.get();
}
// 3. 写入到上下文中
context.write(key, new LongWritable(count));
}}
执行结果:
➜ mr ll comwcout
total 8
-rw-r--r-- 1 jason93 staff 0B 3 21 10:44 _SUCCESS
-rw-r--r-- 1 jason93 staff 29B 3 21 10:44 part-r-00000
➜ mr cat comwcout/part-r-00000
hadoop 1
hello 2
mapreduce 1
程序运行结果说明:代码基本上复用了 WordCount 的,执行结果一样,因为测试文件内容少,若批量的话,Combiner 为了解决 Reduce 迭代时的 Reduce 的 value 就不一定是 1 了。
4. 分组组件 Group
1. 概述
Group 分组是 MapReduce Shuffle 组件中 Reduce 端的一个功能组件,主要作用是 决定哪些数据作为一组。可根据需求自定义分组实现不同的 key 作为同一个组
实现分组有固定的步骤:
- 继承 WritableComparator 类
- 调用父类的构造器
- 指定分组的规则,重写一个方法
2. 案例:求每一个订单中成交额最大的一笔交易
示例数据文件:orders.txt
订单编号 商品编号 金额
order_001 goods_001 100
order_001 goods_002 200
order_002 goods_003 300
order_002 goods_004 400
order_002 goods_005 500
order_003 goods_001 100
思路步骤:
- 定义一个订单实体类 OrderBean
- 定义 Mapper
- 定义分区(可选)OrderPartitioner
- 定义分组 OrderGroup
- 定义 Reducer
- 定义主程序入口 JobMain
代码:
(1)OrderBean.java
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId; // 订单编号
private Double price; // 订单中某个商品的价格
// getter/setter/toString 方法
public String getOrderId() {return orderId;}
public void setOrderId(String orderId) {this.orderId = orderId;}
public Double getPrice() {return price;}
public void setPrice(Double price) {this.price = price;}
@Override
public String toString() {return orderId + '\t' + price;}
/**
* 比较器
* @param o:实体参数
* @return:指定排序的规则
*/
@Override
public int compareTo(OrderBean o) {
// 1. 先比较订单id,如果订单id一样,则将订单的商品按金额排序(降序)
int i = this.orderId.compareTo(o.orderId); // compareTo() 相同返回 0
if (i == 0) {
// 因为是降序,所以用 -1
i = this.price.compareTo(o.price) * -1;
// i = this.price.compareTo(this.price); // 升序
}
return i;
}
@Override // 序列化
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(orderId);
dataOutput.writeDouble(price);
}
@Override // 反序列化
public void readFields(DataInput dataInput) throws IOException {
this.orderId = dataInput.readUTF();
this.price = dataInput.readDouble();
}}
(2)OrderMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:偏移量的类型
* VALUEIN:一行文本的类型
* KEYOUT:k2 OrderBean
* VALUEOUT:v2文本的类型
*/
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 拆分数据,得到订单id和订单金额
// 数据:order_001 goods_001 100
String[] split = value.toString().split("\t");
// 2. 封装OrderBean实体类
OrderBean orderBean = new OrderBean();
orderBean.setOrderId(split[0]);
orderBean.setPrice(Double.parseDouble(split[2]));
// 3. 写入上下文
context.write(orderBean, new Text(value));
}}
(3)OrderPartitioner.java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* Partitioner<KEY, VALUE>
* KEY:k2 的类型
* VALUE:v2 的类型
*/
public class OrderPartitioner extends Partitioner<OrderBean, Text> {
/**
* @return:返回分区的编号
* 比如说: ReduceTask的个数是3个,返回的编号是 0 1 2
* ReduceTask的个数是2个,返回的编号是 0 1
* ReduceTask的个数是1个,返回的编号是 0
*/
@Override
public int getPartition(OrderBean orderBean, Text text, int numPartitions) {
// 参考源码 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
// 按照key的hash值进行分区
return (orderBean.getOrderId().hashCode() & Integer.MAX_VALUE) % numPartitions;
}}
(4)OrderGroup.java
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderGroup extends WritableComparator {
// 1. 继承WritableComparator类
// 2. 调用父类的构造器
public OrderGroup() {
// 第一个参数是分组使用的JavaBean
// 第二个参数是布尔类型,表示是否可以创建这个类的实例
super(OrderBean.class, true);
}
// 3. 指定分组的规则,需要重写一个方法
// WritableComparable是接口,OrderBean实现了这个接口
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 1. 对形参 a b 做强制类型转换
OrderBean first = (OrderBean) a;
OrderBean second = (OrderBean) b;
// 2. 指定分组的规则
return first.getOrderId().compareTo(second.getOrderId());
}}
(5)OrderReducer.java
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
* KEYIN:k2 的类型 OrderReducer
* VALUEIN:v2 的类型 Text
* KEYOUT:k3 一行文本的类型 Text
* VALUEOUT:v3 NullWritable
*/
public class OrderReducer extends Reducer<OrderBean, Text, Text, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int i = 0;
// 获取 topN,下面代码就是取出类 top1
for (Text value : values) {
context.write(value, NullWritable.get());
i++;
if (i >= 1) {
break;
}}}}
(6)JobMain.java(求订单最大值的主类)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 一、初始化一个Job对象
Job job = Job.getInstance(new Configuration(), "OrderGroup");
// 设置输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/orders.txt"));
// 2. 设置Mapper,并设置k2 v2的类型
job.setMapperClass(OrderMapper.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(Text.class);
// 3,4,5,6 shuffle
// 3. 设置分区和任务数
job.setPartitionerClass(OrderPartitioner.class);
// 设置numReduceTask的个数,默认是1
job.setNumReduceTasks(3);
// 6. 设置分组
job.setGroupingComparatorClass(OrderGroup.class);
// 7. 设置Reducer,并设置k3 v3的类型
job.setReducerClass(OrderReducer.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 8. 设置输出
TextOutputFormat.setOutputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/ordergroup"));
// 三、等待完成,实际上就是提交任务
boolean b = job.waitForCompletion(true);
System.out.println(b);
System.exit(b ? 0 : 1);
}}
执行结果:
- 未设置分区的
➜ ordergroup ll
total 8
-rw-r--r-- 1 jason93 staff 0B 3 21 11:10 _SUCCESS
-rw-r--r-- 1 jason93 staff 72B 3 21 11:10 part-r-00000
➜ ordergroup cat part-r-00000
order_001 goods_002 200
order_002 goods_005 500
order_003 goods_001 100
- 设置分区的(输出文件夹名字改成 ordergroup2)
➜ ordergroup2 ll
total 24
-rw-r--r-- 1 jason93 staff 0B 3 21 11:12 _SUCCESS
-rw-r--r-- 1 jason93 staff 24B 3 21 11:12 part-r-00000
-rw-r--r-- 1 jason93 staff 24B 3 21 11:12 part-r-00001
-rw-r--r-- 1 jason93 staff 24B 3 21 11:12 part-r-00002
➜ ordergroup2 cat part-r-00000
order_002 goods_005 500
➜ ordergroup2 cat part-r-00001
order_003 goods_001 100
➜ ordergroup2 cat part-r-00002
order_001 goods_002 200
3. 知识点与组件调优
1. 知识点
1. MapReduce 框架中的分布式缓存
分布式缓存可以解释为 MapReduce 框架提供的一种工具,用于缓存应用程序所需的文件。一旦你为你的工作缓存了一个文件,Hadoop 框架就会让它在你运行的 Map/Reduce 任务的每个数据节点上可用。然后,你可以在 Mapper 或 Reducer 作业中将缓存文件作为本地文件访问
2. Reducers 之间如何通信
MapReduce 编程模型不允许 Reducer 相互通信,减速器 是孤立运行的
3. SequenceFileInputFormat
SequenceFileInputFormat 是用于在序列文件中读取的输入格式。它是一种特定的压缩二进制文件格式,经过优化,可将一个 MapReduce 作业的输出之间的数据传递到其他 MapReduce 作业的输入。
序列文件可以作为其他 MapReduce 任务的输出生成,并且是从一个 MapReduce 作业传递到另一个 MapReduce 作业的数据的有效中间表示。
2. 组件的默认内存与调节建议
NodeManager 内存:默认 8G → 100G(128G)
单任务内存:默认 8G → 128MB数据对应1G内存,8G内存对应1G数据。按数据量调
MapTask/ReduceTask 内存:默认 1G → 若数据量比较大,且不支持切片,则增大 MapTask/ReduceTask 内存(4~6G)
调优参数:
Map:(Reduce 端也一样,只是map改为reduce)下边两个参数一起调
- mapreduce.map.memory.mb:控制分配给 MapTask 内存上限,如果超过会 kill 掉进程。默认内存大小为 1G,如果数据量是 128M,正常不需要调整;如果数据量大于 128M可增大,最大可以增加到 4~5G
- mapreduce.map.java.opts:控制 MapTask 堆内存大小,默认 1G(如果内存不够包:java.lang.OutOfMemoryError)
CPU 核数:增加 MapTask 和 增加 ReduceTask 的 CPU 核数
NameNode 有一个工作线程池,用来处理不同 DataNode 的并发心跳以及客户端并发的元数据操作:dfs.namenode.handler.count=20 * log2(Cluster Size), 比如集群规模为 10 台时,此参数设置为 60
3. MapReduce 项目实战
经典案例场景:流量统计
需求一:统计每个手机号的数据包和流量总和
1. 相关数据
原始数据:

所需数据:
| 上行数据包 | upFlow | int |
| 下行数据包 | downFlow | int |
| 上行流量 | upCountFlow | int |
| 下行流量 | downCountFlow | int |
2. 解题思路
- 定义实体类 BlowBean(字段太多了,定义一个实体类存字段,方便管理)
- 定义 FlowCountMapper
- 定义 FlowCountReducer
- 主程序调度入口 JobMain
3. 代码实现
(1)FlowBean.java(流量Flow的实体类)
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable {
// 定义四个字段
private int upFlow; // 上行数据包数
private int downFlow; // 下行数据包数
private int upCountFlow; // 上行流量总和
private int downCountFlow; // 下行流量总和
// 4个字段的getter、setter、toString()
public int getUpFlow() {return upFlow;}
public void setUpFlow(int upFlow) {this.upFlow = upFlow;}
public int getDownFlow() {return downFlow;}
public void setDownFlow(int downFlow) {this.downFlow = downFlow;}
public int getUpCountFlow() {return upCountFlow;}
public void setUpCountFlow(int upCountFlow) {this.upCountFlow = upCountFlow;}
public int getDownCountFlow() {return downCountFlow;}
public void setDownCountFlow(int downCountFlow) {this.downCountFlow = downCountFlow;}
@Override // 修改toString()的输出格式
public String toString() {
return upFlow + "\t" + downFlow + "\t" + upCountFlow + "\t" + downCountFlow;
}
// 实现对象的序列化(写进去)
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFlow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(upCountFlow);
dataOutput.writeInt(downCountFlow);
}
// 实现对象的反序列化(读出来)
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readInt();
this.downFlow = dataInput.readInt();
this.upCountFlow = dataInput.readInt();
this.downCountFlow = dataInput.readInt();
}}
(2)FlowCountMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:偏移量的类型
* VALUEIN:一行文本的类型
* KEYOUT:手机号的类型
* VALUEOUT:FlowBean
*/
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 拆分文本数据量,得到手机号和想要的数据
String[] split = value.toString().split("\t");
String phoneNum = split[1]; // 手机号
// 2. 创建一个FlowBean对象,把想要使用的数据封装进去
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(Integer.parseInt(split[6]));
flowBean.setDownFlow(Integer.parseInt(split[7]));
flowBean.setUpCountFlow(Integer.parseInt(split[8]));
flowBean.setDownCountFlow(Integer.parseInt(split[9]));
// 3. 写入上下文
context.write(new Text(phoneNum), flowBean);
}}
(3)FlowCountReducer.java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:phoneNum的类型
* VALUEIN:实体类对象FlowBean
* KEYOUT:手机号类型Text
* VALUEOUT: FlowBean
*/
public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
// 1. 遍历values,将4个变量进行累加
int upFlow = 0;
int downFlow = 0;
int upCountFlow = 0;
int downCountFlow = 0;
for (FlowBean value : values) {
upFlow += value.getUpFlow();
downFlow += value.getDownFlow();
upCountFlow += value.getUpCountFlow();
downCountFlow += value.getDownCountFlow();
}
// 2. 创建一个FlowBean对象,存放累加后的结果
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(upFlow);
flowBean.setDownFlow(downFlow);
flowBean.setUpCountFlow(upCountFlow);
flowBean.setDownCountFlow(downCountFlow);
// 3. 写入上下文
context.write(key, flowBean);
}}
(4)JobMain.java(需求一:统计每个手机号的数据包总和)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 一、初始化一个Job对象
Job job = Job.getInstance(new Configuration(), "FlowCount");
// 二、 设置Job对象的相关信息,里面包含8个小步骤
// 1. 设置输入路径
TextInputFormat.addInputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/flow.log"));
// 设置Mapper的类型,并设置 k2 v2
job.setMapperClass(FlowCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 3,4,5,6 四个步骤,都是Shuffle阶段,暂不修改
// 设置Reducer的类型,并设置 k3 v3
job.setReducerClass(FlowCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输出路径,让程序把结果放到一个地方去
TextOutputFormat.setOutputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/flowcount"));
// 等待程序完成,退出
boolean b = job.waitForCompletion(true);
System.out.println(b);
System.exit(b ? 0 : 1);
}}
pom.xml 文件同上即可,执行结果:
➜ flowcount ll
total 8
-rw-r--r-- 1 jason93 staff 0B 3 21 11:53 _SUCCESS
-rw-r--r-- 1 jason93 staff 873B 3 21 11:53 part-r-00000
➜ flowcount vi part-r-00000
13480253104 41580 41580 2494800 2494800
13502468823 790020 1413720 101663100 1529437140
13560436666 249480 207900 15467760 13222440
13560439658 457380 332640 28191240 81663120
...
需求二:将需求一中结果按照 upFlow 流量倒排
注意: 输入文件是需求一的输出的结果
方法: 将需求一输出的结果的 key-value 互换身份,排序 value,最后再转换回来
代码:
(1)FlowBean.java(排序的实例化的对象。代码相比需求一的,继承的接口不同,该需求继承的接口中有比较器的方法,其他都一样)
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean> {
...
// 实现结果的排序,指定排序的规则:倒序排列
@Override
public int compareTo(FlowBean o) {
// 从大到小
return o.upFlow - this.upFlow;
// 从小到大
// return this.upFlow - o.upFlow;
}}
(2)FlowSortMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN: 偏移量
* VALUEIN: 文本 13480253104 41580 41580 2494800 2494800
* KEYOUT: FlowBean
* VALUEOUT: 手机号
*/
public class FlowSortMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 拆分一行文本 13480253104 41580 41580 2494800 2494800
String[] split = value.toString().split("\t");
// 2. 创建实例类对象,将数据写入到实体类
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(Integer.parseInt(split[1]));
flowBean.setDownFlow(Integer.parseInt(split[2]));
flowBean.setUpCountFlow(Integer.parseInt(split[3]));
flowBean.setDownCountFlow(Integer.parseInt(split[4]));
String phoneNum = split[0];
// 3. 写入上下文
context.write(flowBean, new Text(phoneNum));
}}
(3)FlowSortReducer.java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN: FlowBean
* VALUEIN: Text
* KEYOUT: Text
* VALUEOUT: FlowBean
*/
public class FlowSortReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 遍历集合,将 k3 v3 写入到上下文
for (Text value : values) {
context.write(value, key);
}}}
(4)JobMain.java(需求二:将需求一种结果按照upFlow流量倒排)
- 注意:输入文件是需求一的输出的结果
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 一、初始化一个Job对象
Job job = Job.getInstance(new Configuration(), "FlowSort");
// 二、设置Job对象的相关的信息 ,里面包含了8个小步骤
// 1、设置输入的路径,让程序能找到输入文件的位置
TextInputFormat.addInputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/flowcount"));
// 2. 设置Mapper类型,并设置 k2 v2
job.setMapperClass(FlowSortMapper.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
// 3 4 5 6 四个步骤都是Shuffle阶段,暂时不做处理
// 7. 设置Reducer的类型,并设置 k3 v3
job.setReducerClass(FlowSortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 8. 设置输出的路径,让程序给结果放到一个地方去
TextOutputFormat.setOutputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/flowreverse"));
// 三、等待程序完成
boolean b = job.waitForCompletion(true);
System.out.println(b);
System.exit(b ? 0 : 1);
}}
执行结果:
➜ FlowSort ll
total 8
-rw-r--r-- 1 jason93 staff 0B 12 7 14:09 _SUCCESS
-rw-r--r-- 1 jason93 staff 873B 12 7 14:09 part-r-00000
➜ FlowSort cat part-r-00000
13925057413 956340 873180 153263880 668647980
13502468823 790020 1413720 101663100 1529437140
13560439658 457380 332640 28191240 81663120
15013685858 388080 374220 50713740 49036680
...
需求三:手机号码分区
要求:
- 135 开头的放一个文件
- 136 开头的放一个文件
- 137 开头的放一个文件
- 其他开头的放一个文件
代码:
(1)PhoneBean.java
import org.apache.hadoop.io.Writable;
// 实体类
public class PhoneBean implements Writable {
// 定义4个流量变量,实现 get、set、toString方法和序列化与反序列化
(2)PhoneMapper.java 和 PhoneReducer.java 代码同需求一
(3)PhonePart.java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class PhonePart extends Partitioner<Text, PhoneBean> {
@Override
public int getPartition(Text text, PhoneBean phoneBean, int numPartitions) {
String s = text.toString();
if (s.startsWith("135"))
return 0;
else if (s.startsWith("136"))
return 1;
else if (s.startsWith("137"))
return 2;
else return 3;
(4)JobMain.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration(), "PhonePart");
TextInputFormat.addInputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/flow.log"));
job.setMapperClass(PhoneMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PhoneBean.class);
// 3. 分区设置
job.setPartitionerClass(PhonePart.class);
// 设置最终的ReduceTasks个数
job.setNumReduceTasks(4);
job.setReducerClass(PhoneReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
TextOutputFormat.setOutputPath(job, new Path("/Users/jason93/Desktop/BigData/file/mr/phonepart"));
boolean b = job.waitForCompletion(true);
System.out.println(b);
System.exit(b ? 0 : 1);
}}
注意:分区和 ReduceTask 要同时设置,否则无效果
job.setPartitionerClass(FlowPartitioner.class); // 分区设置
job.setNumReduceTasks(4); // 设置最终的ReduceTask个数
执行结果:
➜ phonepart ll
total 32
-rw-r--r-- 1 jason93 staff 0B 3 21 14:00 _SUCCESS
-rw-r--r-- 1 jason93 staff 136B 3 21 14:00 part-r-00000
-rw-r--r-- 1 jason93 staff 87B 3 21 14:00 part-r-00001
-rw-r--r-- 1 jason93 staff 160B 3 21 14:00 part-r-00002
-rw-r--r-- 1 jason93 staff 490B 3 21 14:00 part-r-00003
➜ phonepart cat part-r-00000
13502468823 790020 1413720 101663100 1529437140
13560436666 249480 207900 15467760 13222440
13560439658 457380 332640 28191240 81663120
➜ phonepart cat part-r-00001
13602846565 207900 166320 26860680 40332600
13660577991 332640 124740 96465600 9563400
➜ phonepart cat part-r-00002
13719199419 55440 0 3326400 0
13726230503 332640 374220 34386660 342078660
13726238888 332640 374220 34386660 342078660
13760778710 27720 27720 1663200 1663200
➜ phonepart cat part-r-00003
13480253104 41580 41580 2494800 2494800
13826544101 55440 0 3659040 0
13922314466 166320 166320 41690880 51559200
13925057413 956340 873180 153263880 668647980
13926251106 55440 0 3326400 0
13926435656 27720 55440 1829520 20956320
15013685858 388080 374220 50713740 49036680
15920133257 277200 277200 43742160 40692960
15989002119 41580 41580 26860680 2494800
18211575961 207900 166320 21164220 29189160
18320173382 291060 249480 132099660 33430320
84138413 277200 221760 57047760 19847520
4. MapReduce 的 Shuffle 和 YARN
1. Shuffle 原理详解
1. Shuffle 概述
Shuffle(数据汇洗):Mapper 阶段输出数据到 Reducer 阶段接收到数据的中间的数据分发的过程【MapReduce 框架中最关键的一个流程】
Shuffle:将 MapTask 输出的处理结果数据,分发给 ReduceTask
Shuffle 分两个阶段:Mapper Shuffle 和 Reducer Shuffle
2. Shuffle 机制
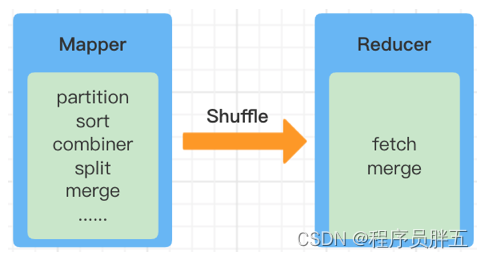
3. Shuffle 图解优化版
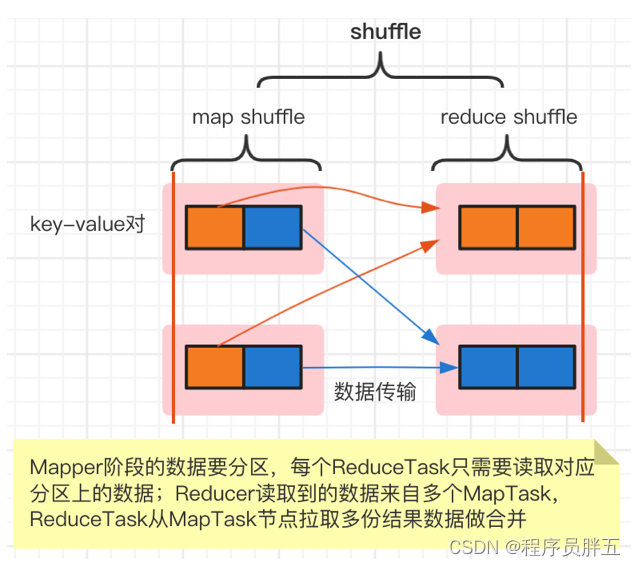
4. Shuffle 核心执行流程图
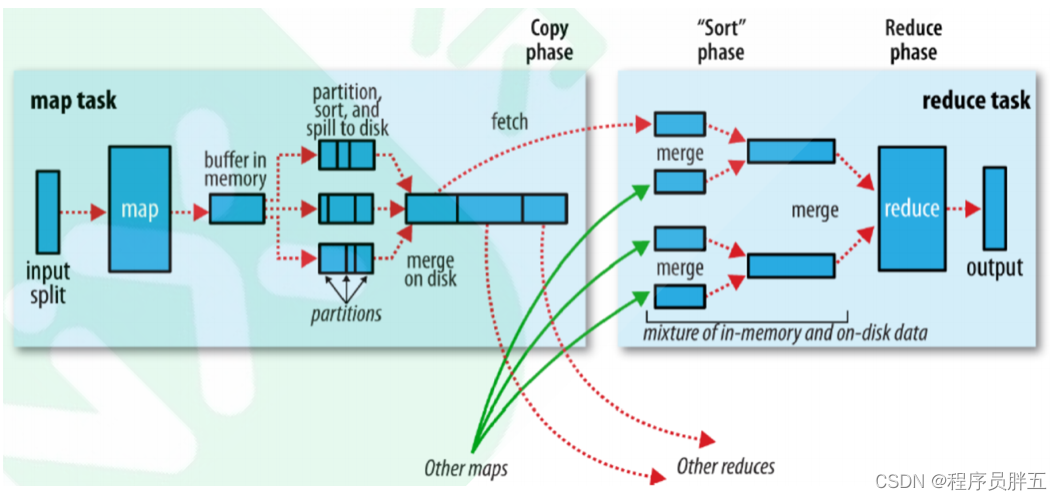
Shuffle 是 MapReduce 处理流程中的一个过程,它的每一个处理步骤都分散在各个 MapTask 和 ReduceTask 节点上完成的。整体来看,分为四个步骤:
- Partition 分区
- Sort 根据 key 排序(MapReduce 编程中的 Sort 是一定会做的,一定仅按照 key 排序)
- Combiner 进行局部 value 的合并(Combiner 是可选的组件)
- Group 分组
5. Shuffle 详细图解
环形缓冲区(kv buffer):内存中一种首尾相连的数据结构(就是一块内存区域,大小为 100MB)。一个 MapTask 任务初始化一个环形缓冲区。
当环形缓冲区(100MB)装不下时,可对内存中的数据溢写,即内存中的数据持久化到磁盘中:
- 溢出前就已经给所有的数据进行了分区操作
- 每个分区的数据进行排序,使用排序算法
QuickSort - 如果设置
Combiner,就会调用 Combiner 进行局部合并
说明:
- 溢出之前分区起作用
- 溢出之后排序起作用
- Combiner 在此过程中起作用

流程概述: 数据经 Map 方法多次写入到环形缓冲区后,当达到 0.8 的阈值后就会溢出,溢出的数据都传输到磁盘中进行排序,再经过 Combiner 阶段到某个文件,此时再归并合并成文件,再经过压缩使文件变小,之后写入磁盘,最后由 Reduce 方法拉取磁盘中的文件用于后续操作。
压缩说明:
- 压缩使文件体积变小,可节省存储空间,便于传输,但下游用户需要对压缩后的数据进行解码,这样计算就会有资源消耗的压力
- 不压缩的话下游用户直接获取到原始的数据而无需解压缩,提高效率
案例:在溢出时,Mapper 线程需不需要继续往环形缓冲区里写入数据?
方案:
- 如果每次都给环形缓冲区装满的话,先溢出,此时 Map 写数据的线程堵塞,等到数据溢出完毕后再往里写
- 如果每次不装满环形缓冲区就开始溢出数据,那部分空白的内存区域就可以接收新数据的写入
分析:
- 第二种合理一点,并且是默认的实现方式:100MB,装满 80MB 的数据时就溢写,即装满 80MB 时就不再装了,剩余 20MB 的内存空间让 Mapper 进行数据写入
- 第二种的极端情况:80MB 的数据还未溢写完,20MB 的写数据就已经写满了,就跟第一种情况一样了。此时 Map 写入数据的线程就会堵塞,只能等 80MB 刷满。但这种情况很少
说明:
- 现阶段使用 MapReduce 不多,因为它运行的慢。原因在于环形缓冲区溢出后多次与磁盘进行数据传输,针对磁盘的数据会进行多次合并操作,从而有多次落盘操作,导致耗时较严重
- 数据写到磁盘上要进行一些合并操作,由于有顺序速度快,所以使用归并排序
- 设置环形缓冲区的原因是想充分利用内存,因为内存运行快
6. 环形缓冲区内部图解
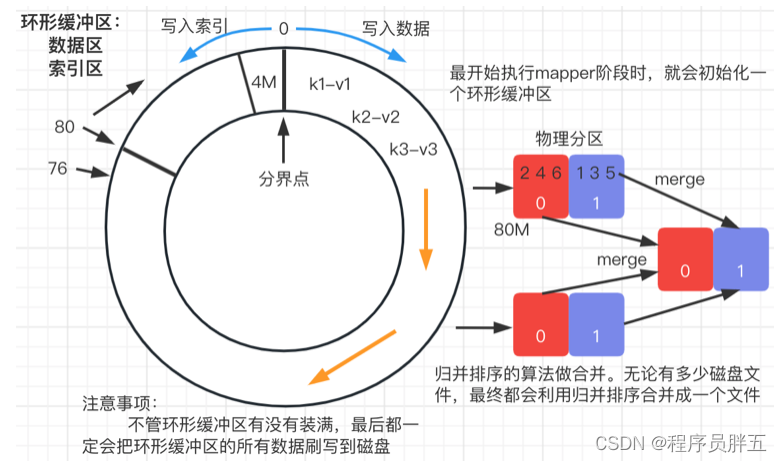
- 最开始执行 Mapper 阶段的逻辑时,就会初始化一个环形缓冲区
context.write()写入 80% 的数据(即 80MB),但这 80MB中包含数据和数据对应的编号(索引),所以当数据存到76MB时就不再写入而是溢出了- 不管环形缓冲区有没有装满,最后都一定会把环形缓冲区的所有数据刷写到磁盘
- 归并排序的算法算合并。不管有多少磁盘文件,最终都会利用归并排序合并成一个文件
7. Shuffle 优化
-
getpartition()中:自定义分区(把一些 Key 加随机数后打散) -
环形缓冲区:100MB → 200MB,80% → 90% / 95%
- 原因:减少了溢写文件的数量
-
在不影响最终业务逻辑(比如求和不影响,但求平均值不行)前提下,对大量溢写文件提前进行 Combiner(提前合并)。默认一次归并 10 个,若服务器性能好,可设置归并多个,比如 20 个
-
为了减少磁盘 IO,可采用压缩(压缩快):Snappy、LZO
-
压缩需要考虑的点:
-
Map 输入端:先看文件大小
-
文件比较小:考虑速度(Snappy)
-
文件比较大:考虑切片(bzip2、LZO)
- bzip2:压缩方式简单,但压缩速度不如 LZO 快
- LZO:压缩需要创建索引,压缩速度比 bzip2 快
-
-
Map 输出端:
- 考虑速度 快,用 Snappy、LZO
-
Reduce 输出端:(看需求)
- 永久保存:压缩比越大越好,压缩文件越小越好
- 作为下一个MapReduce的输入:考虑数据量大小和切片
- 数据量大考虑切片
- 数据量小考虑速度
-
-
-
Reduce 拉取文件默认一次拉取 5 个 Map 端的文件
- 服务器性能好可以适量增多拉取的数量
- 增大内存提高效率
2. 资源调度框架 YARN
1. YARN概述
YARN(Yet Another Resource Negotiator):是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行在操作系统之上的应用程序。
每次运行 MapReduce 程序时都会启动 主控程序:MRAppMaster: MapReduce Application Master
主控程序用来掌握任务的运行,分为 任务划分、监控、任务容错 这三个方面
资源:CPU(核、线程)、内存、带宽、磁盘 等等
MRAppMaster:向资源调度器申请执行任务的资源容器:JVM 重用
Docker 虚拟化:把一个大的集群看做一个整体,然后按需虚拟出来很多的服务器
注意点:
- Yarn 并不清楚用户提交的程序的运行机制
- Yarn 只提供运行资源的调度(用户程序向 Yarn 申请资源,Yarn 就负责分配资源)
- Yarn 中的主管角色叫 ResourceManager
- Yarn 中提供运算资源的角色叫 NodeManager
- Yarn 与运行的用户程序解耦
- Spark、Storm 等运算框架都可以整合在Yarn上运行
- Yarn 就成为一个通用的资源调度平台
2. Hadoop 版本间对比
1. Hadoop1.x 和 Hadoop2.x 的版本对比
- Hadoop2.x 以后,把原来的 MapReduce 集群分裂成了 MapReduce 编程 API 和 Yarn 集群
- Hadoop1.x:主从架构,主节点 JobTractor,从节点 TaskTractor。所有分布式计算的主控程序 MRAppMaster 都运行在 JobTractor,如果主节点宕机或任务过多导致主节点负载过大从而宕机,则所有任务都无法执行
- Hadoop2.x:Yarn 集群,主从架构,主节点 ResourceManager,从节点 NodeManager。Yarn 把 MRAppMaster 分散的启动在各个 NodeManager 上,分散了主节点的负载压力,避免宕机
- 把原来的 MapReduce 集群中关于资源调度的代码抽象出来,形成独立的组件
- 形成独立组件的原因:
- 各个组件(Yarn、Mesos)可以各司其职
- 让 Yarn 集群也能运行除了 MapReduce 之外的其他分布式计算程序
- 形成独立组件的原因:
- 在Hadoop2.x 之后 HDFS 和 Yarn 都有高可用的机制
2. Hadoop2.x 和 Hadoop3.x 的版本对比
- Hadoop2.x 系统中存在的问题:
- Common 组件:暂无问题
- HDFS 存储文件
- 多个副本,保证数据安全,消耗大量磁盘
- Hadoop3.x 中提供了新特性:纠删码(Erasure Coding),使用矩阵的逆运算解决 HDFS 冗余存储问题
- 纠删码:消耗磁盘少,但消耗计算资源
- 冗余备份:消耗磁盘多,但节省计算资源
- MapReduce
- 计算慢
- Hadoop3.x 中的 MapReduce 计算速度大幅度提升
- Yarn:暂无问题
3. YARN 的重要概念
1. 主节点 ResourceManager
-
ResourceManager 是基于应用程序对集群资源的需求进行调度的 Yarn 集群主控节点,负责协调和管理整个集群的资源,响应用户提交的不同类型应用程序的解析、调度、监控等工作
-
ResourceManager 会为每一个 Application 启动一个 MRAppMaster,并且 MRAppMaster 分散在各个 NodeManager 节点
-
ResourceManager 由两个组件构成:调度器(Scheduler)和 应用程序管理器(ApplicationsManager, ASM)
- 调度器:调度每个节点中的 Container(容器),调度容器和资源
- 应用程序管理器:管理应用服务,每个应用程序提交上来时都会向应用程序管理器注册信息
-
ResourceManager 最重要的作用是提供 Container,Container 是抽象出来的容器单位
-
调度器的调度算法:
-
FIFO(First in, First out):先进先出,排队处理任务。不管先进还是后进的任务所需资源多少,都按顺序执行(并发低,企业中不用)
- 好处:只需要配置,不用时刻关注
- 弊处:不合理
-
Fair Scheduler(公平调度器,CDH默认):每个任务所占用资源相同。比如第一个任务上送上来会占用所有的运算资源;则第二个任务来了会分一半资源;第三个任务来了会占用三分之一的资源,以此类推
- 好处:只需要配置,不用时刻关注
- 弊处:小任务占用资源过多,大任务所分配资源紧张,导致耗时验证,最终的结果是运算时间过长
-
Capacity Scheduler(容器调度器,Apache默认):按需分配资源,根据任务大小程序分配不同的资源
- 好处:资源分配合理
- 弊处:需手动配置资源分配。配置文件位置:
${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml -
企业如何选择:
- 若服务器性能比较好,对并发度要求比较高,则选择公平调度器(大厂、上市公司)
- 若服务器性能比较差,对并发度要求不是特别高,则选择容量调度器(中小型公司)
-
-
开发时如何创建队列?
- 容量调度器默认就一个 default 队列
- 按照执行任务的框架创建:Hive、Spark、Flink
- 按照业务模块创建(用的比较多):登录注册模块、订单、物流
- 618/双十一 等场景:降级使用,舍弃一些任务,比如把物流队列关掉,优先保证登录注册和订单队列的计算
2. 从节点 NodeManager
- NodeManager 是 Yarn 集群中真正资源的提供者,是真正执行应用程序的容器的提供者,监控应用程序的资源使用情况,并通过心跳向集群资源调度器 ResourceManager 进行汇报
3. 容器 Container
- Container 是一个抽象出来的逻辑资源单位。它封装了一个节点上的 CPU、内存、磁盘、网络等信息,MapReduce 程序的所有 Task 都是在一个容器里执行完成的,容器大小可以动态调整
- Hadoop2.x 中叫 Container;Hadoop1.x 中不叫 Container,叫 Slot 槽,分为 MapTaskSlot 和 ReduceTaskSlot
4. YARN 架构图
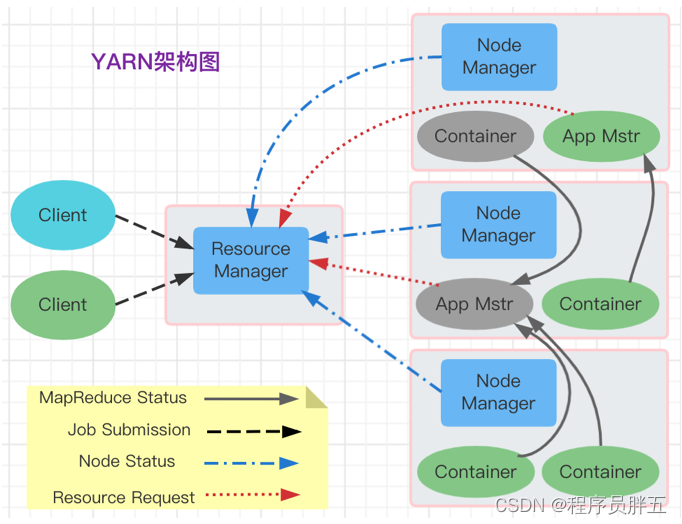
说明:
- NodeManager 管理了很多的资源,资源层被抽象成了一个个的 Container
- MRAppMaster 向 ResourceManager 申请资源,返回资源在哪些 NodeManager 中,以及这些资源到底是哪些 Container
- 每个 Container 都有一个全局独一无二的编号
- ResourceManager 返回的是
(host, containerID) - MRAppMaster 发送请求给对应的 NodeManager,请求 NodeManager 在 ResourceManager 分配给你的 Container 中启动 task
- 一主三从,Client 将 Job 任务提交给 ResourceManager,ResourceManager 接收请求,由调度器申请资源运行 AppMaster,AppMaster 调度内部程序运行
5. 作业提交流程
- 用户向 Yarn 提交应用程序,其中包括 ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等
- ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求它在这个 Container 中启动应用程序 ApplicationMaster,主控程序 AppMaster 解析 MapReduce 任务需要多少个 MapTask 和多少个 ReduceTask,以便后续注册后向 ResourceManager 申请资源
- ApplicationMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后为各个任务申请资源,并监控它的运行状态,直到运行结束,重复 4~7 的步骤
- ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源
- 一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务
- NodeManager 为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
- 各个任务通过 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态
- 应用程序运行完成后,AM 向 RM 注销并关闭自己
说明:Hadoop 的 NodeManager 进行启动最好放到 DataNode 节点上,因为移动计算优于移动数据。把当前的 NodeManager 和 NodeManager 放在一起,直接从本地获取数据,速度更快。如果计算和数据不在同一节点,就无法从当前节点获取数据,跨节点去存储和获取数据会有网络传输,造成一定延迟。
5. hadoop 宕机
情况一:如果 MR 造成系统宕机,此时要控制 Yarn 同时运行的任务数和每个任务申请的最大内存
- 调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是 8192MB)
情况二:如果写入文件过快造成 NameNode 宕机,则调高 Kafka 的存储大小,控制从 Kafka 到 HDFS 的写入速度
- 例如:可以调整 Flume 每批次拉取数据量的大小参数 batchsize