我们来聊一聊java代码是如何运行的。大家都知道java是运行在JVM上的,那它是怎么结合操作系统去控制那些硬件设备的呢?
其实想要知道这个问题我们可以跟踪一行代码的整个生命周期来解释,我把它抽象为这么五个步骤。
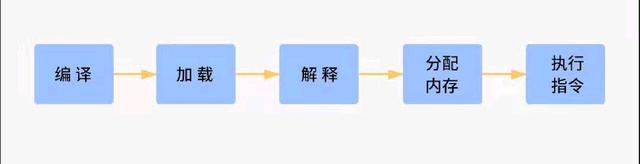
首先这行代码会被编译成字节码,然后被JVM通过类加载器进行加载,接着再被解释器解释成机器码,然后分配执行这段指令需要的资源---主要是内存。然后就是CPU执行指令把结果写回内存了。
接下来我们一个步骤一个步骤地来具体分析。
首先java是一门高级语言,这类语言并不能直接运行在硬件上,它必须运行在能够识别java语言特性的虚拟机上,而java代码必须通过java编译器将其转换为虚拟机能识别的指令序列,也称为java字节码。

那么System.out.println("Hello world")编译后的字节码是怎样的呢?最左列是偏移量,中间列是给虚拟机读的字节码,最右列是高级语言的翻译。
有了字节码,java虚拟机通过类加载器进行加载,加载完之后,我们通过解释器解释成汇编指令,最终再转译成CPU可以识别的机器指令,那么通过汇编语言转换成的机器指令具体是怎样的呢?
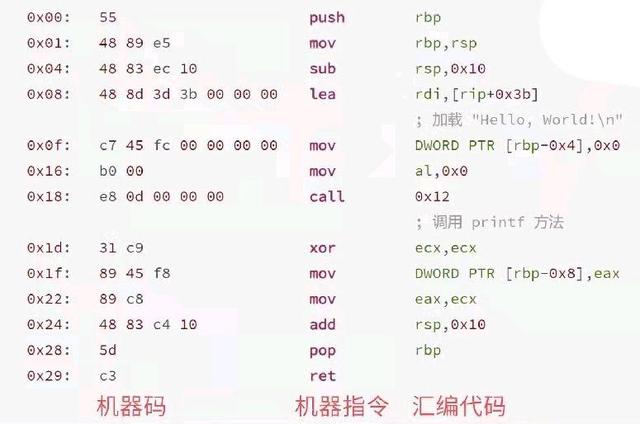
我们可以看到中间是机器码,第三列为对应的机器指令,最后一列为对应的汇编代码。
解释器是通过软件来实现的,它将字节码转换成汇编指令,可以实现同一份java字节码在不同的硬件设备上运行,而将汇编指令转换成机器指令由硬件直接实现,所以它的速度会更快。
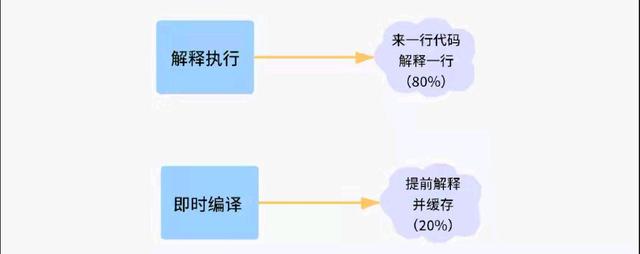
JVM为了提高运行效率会将某些热点代码一次全部编译成机器指令再执行,也就是和解释执行对应的即使编译,即使编译的机器码存放在一个叫codecache的缓存的地方,这块内存属于堆外内存。如果这块内存不够了,那么即使编译器将不会再进行编译,可能导致程序运行变慢,这也是我们排查性能问题变慢的一个点。
代码转换成了指令,指令要执行就必须要有上下文的环境,这些环境包括指令寄存器、数据寄存器、栈空间等内存资源。
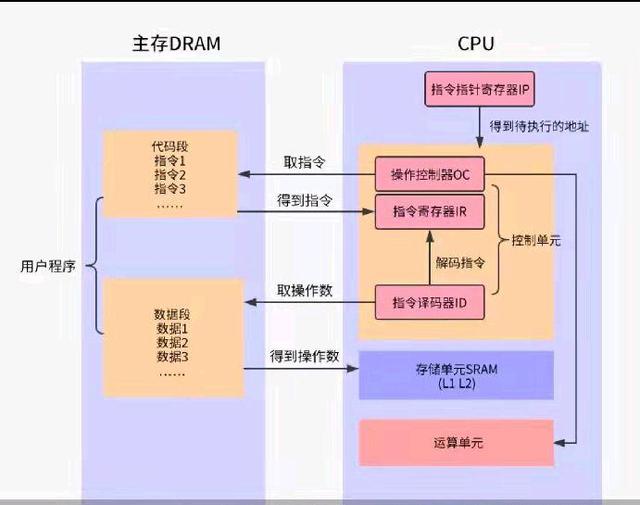
程序加载进内存后指令就在内存中了,指令的指针寄存器IP指向内存中的下一条待执行指令的地址,CPU的控制单元根据IP寄存器的指向将主存中的指令装载到指令寄存器,这个指令寄存器也是一个存储设备,不过它集成在CPU内部,指令从主存到达CPU后只是一串010101的二进制串,还需要通过译码器进行解码。解码后根据运算类型再从主存中获取操作数,并调用运算单元进行计算。
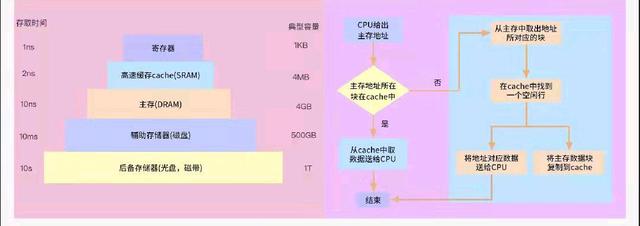
实际上,我们的数据主要是存放在内存上,然而CPU的计算速度比主存的存取速度快很多倍,所以在两者之间会有多级高速缓存。例如当CPU有个指令是取主存上某一个值,CPU会先根据这个值在主存上的位置去判断是否已经在高速缓存中,如果没有就会去主存取,取完再放在高速缓存中。
这个地方会涉及到一个知识点,就是去主存上读取的时候并不会仅仅去读取一个值,而是把一段长度的值都拿出来并缓存,因为它会假设你既然读了某个位置的值而这个位置相邻的值也会被读取。就像我们用SQL去查询id=800这行记录的时候,虽然它返回了id=800这行记录,实际上它去读这行记录的时候把这行记录所在的数据页上的所有数据都放内存里面了。可能下次你去查询id=801行的那条记录的时候直接就命中缓存就不用去磁盘去查了。
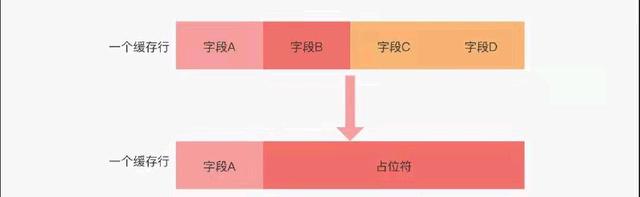
所以我们知道一个缓存行可能缓存了多个字段的值,如果某个进程改了其中的一个值就会导致一整个缓存都会失效,那么这个缓存行上的其他值也会重新从内存读取,所以一些对内存要求比较高的应用就想规避掉这种情况。比如它们会用对象填充的方式让某个字段的值可以独占一整个缓存行。
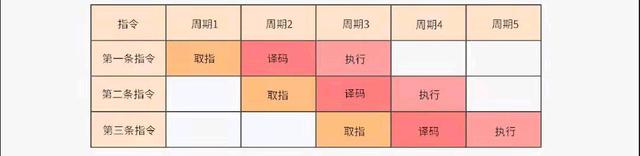
好,有了执行环境我们这段代码什么时候执行呢?我们知道CPU一通电就会不停地取指令、运算,周而复始,那你可能就会问了,什么时候才会执行到我这段代码呢?
实际上CPU给每一个进程都分配了一个时间片,在这个时间片内执行对应的进程指令,过了这个时间片就执行别的进程,一个进程内的指令执行顺序靠每个指令执行完再去指向下一个指令的位置。当然一个进程内的某些操作也会主动放弃CPU的执行权限,比如等待IO操作。

所以为了让一个进程内的指令可以更高效地执行,我们可以让某个线程在等待IO的时候其他线程能够获取到CPU的执行权限并继续执行。如果你的任务都是计算性的任务,基本不会主动释放CPU的情况,那么在单核机器上就没必要开多线程,如果有大量的IO操作,那么多线程的效果就会比较好。
接下来我们分析下代码执行的时候内存是怎么分配的。一个JVM启动就会产生一个进程,虽然多个进程会共享一个物理内存,但是每个进程都会拥有自己独立的内存空间。

当我们同时启动多个JVM并执行System.out.println(new Object()),将会打印这个对象的hashcode,hashcode默认为内存的地址,最后我们发现它打印的都是java.lang.Object@4fca772d。
也就是说多个JVM进程返回的内存地址是一样的,这说明每个进程都有单独的地址空间。
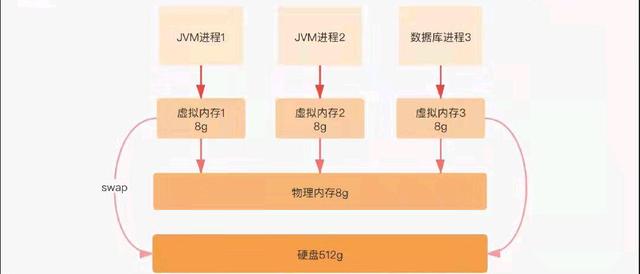
实际上,每个进程自己都会维护一个虚拟的内存,虚拟存储让每个进程以为自己独占整个内存空间,这样的好处是每个进程都拥有一致的虚拟地址空间。简化了内存管理,进程不需要和其他进程竞争内存空间,因为它是独占的,这也保护了各自进程不会被其他进程破坏。
每个进程在申请内存的时候会维护虚拟内存和物理内存的映射关系,避免其他进程占用自己的内存,而这个虚拟内存空间可能会超过物理内存,当超过物理内存的时候可能会发生数据溢出从而存储到磁盘上。
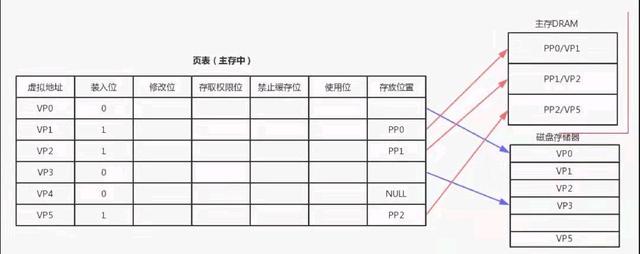
页表保存了虚拟地址和物理地址的映射,页表是一个数组,每一个元素为一个页的映射关系,这个映射关系可能是和主存的也可能和磁盘的,页表存储在主存中也可以存储在缓冲区。
我们将存储在高速缓冲区中的页表称为TLAB。好,我们现在知道了JVM进程内的内存地址是怎么和物理内存关联的了,那么一行具体的java代码无非就是读取某个属性的值,将这个值做运算再将新的值写回某个属性,那么我们怎么样才能读取到某个属性的值呢?

我们可以参考下JDK中反射的实现,也就是说当我们获取到一个Field对象就可以通过set()方法或者get()方法设置和读取某个属性的值,它首先要获取这个属性相对对象初始位置的偏移量,如果你持有这个对象的引用,你就能获取到这个对象在虚拟内存中的起始地址,然后我们根据属性的偏移量就可以获取这个属性的虚拟的内存地址,之后再查询页表就可以获取物理的内存的起始地址,接着再根据这个属性的类型取对应长度的数据。
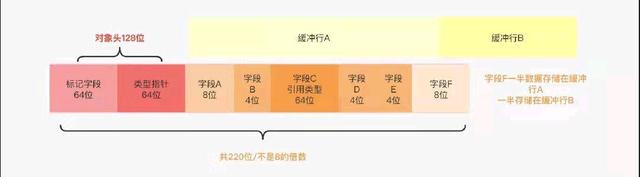
写入也是一样的道理,属性相对对象初始位置的偏移量在加载这个class的时候就确认好了,它是和class绑定的,那么如果一个对象就一个属性,如果不压缩的话那么除了对象头占128位,这个属性的偏移量可能就是128,如果有多个属性,JVM会对属性进行重排序和内存对齐,保证对象占用的大小是8的倍数,另一个作用就是保证一个属性的值都在一个CPU的缓存行中,不然一个属性的值会一部分在缓存行A中一部分在缓存行B中。
这期的分享到这里就结束了,希望这期的分享能帮助到你。