1.什么时候重写equals和hashCode方法?
/*因为Object中默认的equals方法,内部还是使用==来比较对象在内存中的地址,所以结果位false*/
/*如果重写了equals方法,那么如果两个对象的属性值相同,那么程序会在第三步判断中返回true,
* hashCode()方法,它是一个本地方法,底层是运用对象的内存地址通过哈希函数来计算的。
* 问题:为什么重写equals时,一定需要重写hashCode()方法?
* 因为重写了equals()之后,判断两个属性值相同的对象时,会返回true,如果没有重写hashCode(),
* 那么程序还是按照默认的使用内存地址的方法去计算,那么一定会返回false,
* java中规定:两个对象的equals()相同,hashCode一定相同。hashCode相同,但equals不一定相同
* 所以在重写equals时,一定需要重写hashCode。
*/
/*什么时候需要重写类的equals()和hashCode()方法?
* 1.当我们需要重新定义两个对象是否相等的条件时,需要进行重写。比如通常情况下,我们认为两个不同对象的某些属性值相同时,
* 就认为这两个对象是相同的。
* 例如:我们在HashMap中添加元素时,我们认为当key相同时,两个元素就相同,但是默认的Object中的equals(),只是单纯的比较两个元素 的内存地址是否相同,不能满足我们的要求,所以需要重写。
* 2.当我们自定义一个类时,想要把它的实例保存在集合时,就需要重写equals()和hashCode()方法。*/2.java集合继承结构,for和iterator遍历中删除元素有什么问题?

for循环删除ArrayList中的某个值:
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(1);
arrayList.add(1);
arrayList.add(2);
arrayList.add(2);
arrayList.add(3);
arrayList.add(4);
/**
* 正序搜索删除
*/
for (int i = 0; i <arrayList.size()-1;i++) {
if(arrayList.get(i).equals(1)){
arrayList.remove(i);
}
}
System.out.println("正序"+arrayList);
/**
* 反序搜索删除
*/
for (int i = arrayList.size()-1; i >=0; i--) {
if(arrayList.get(i).equals(2)){
arrayList.remove(i);
}
}
System.out.println("反序"+arrayList);
}
执行结果如下:
正序:[1,2,2,3,4]
反序:[1,3,4]可以发现正序删除并没能删除所有的1,而反序则可以完全删除所有的2。
因为ArrayList删除一个元素后,所有的元素都会向前移动,所以就会导致连续的1,并没能完全删掉。而后序遍历,删除,并不会影响前一个节点的值,所以可以完全删除。
Iterator删除ArrayList中的某个值:
package com;
import java.util.ArrayList;
import java.util.Iterator;
public class remove {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(1);
arrayList.add(1);
arrayList.add(2);
arrayList.add(2);
arrayList.add(3);
arrayList.add(4);
/**
* arrayList删除
*/
Iterator<Integer> iterator = arrayList.iterator();
try {
while(iterator.hasNext()){
Integer next = iterator.next();
if(next.equals(1)){
arrayList.remove(next);
}
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(arrayList);
/**
* iterator删除
*/
Iterator<Integer> iterator2 = arrayList.iterator();
while (iterator2.hasNext()) {
Integer next = iterator2.next();
if(next.equals(2)){
iterator2.remove();
}
}
System.out.println(arrayList);
}
}
执行结果如下:

可以发现上面的iterator使用ArrayList删除第一个元素1的时候,删除成功了,但是在删除第二之前时候(不是其没能力删除),好像就报了ConcurrentModificationException的错误。
而下面的iterator删除集合元素的方法就成功了,并不会报错。
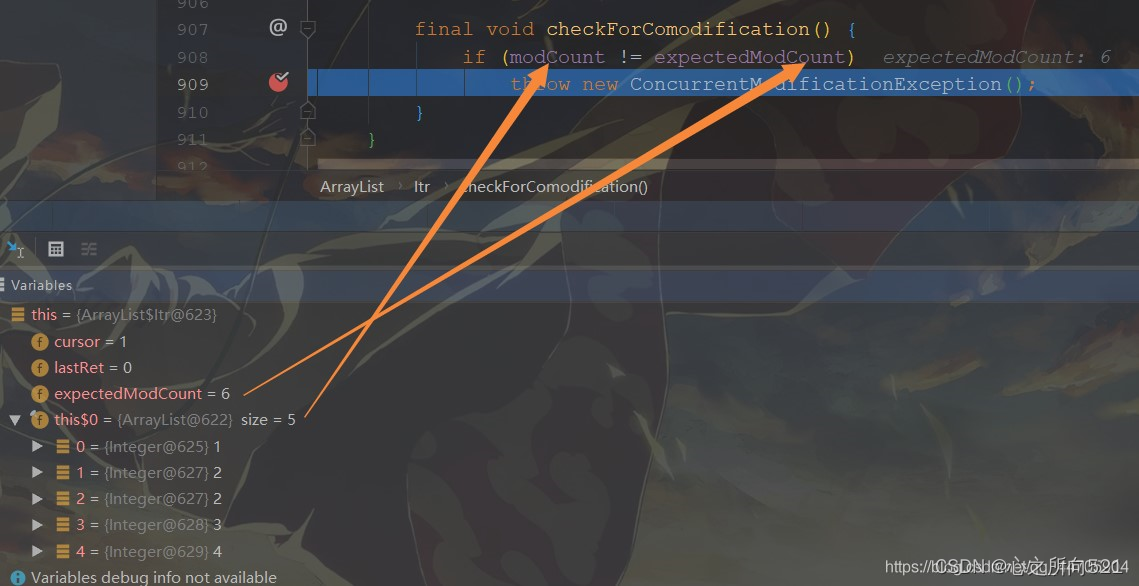
可以发现,当在使用ArrayList删除后,modCount就会发生改变,期待的值不是6了,于是这里产生了异常,故抛出异常
而对于iterator的remove方法:

可以发现,其调用的虽然是ArrayList的删除方法,但它在后面更新了新的expectedModCount,使得每次两个都能相等,这样就不会抛出异常了。能正常执行下去。
3.线程有哪几种状态?阻塞(BLOCK)?如何终止线程?
线程的五种状态: 1.新建(new) 创建了一个新的线程对象 2.就绪(runnable) 调用线程的start()方法,处于就绪状态 3.运行(running) 获得了CPU时间片,执行程序代码 就绪状态是进入到运行状态的唯一入口 4.阻塞(block) 因为某种原因,线程放弃对CPU的使用权,停止执行,直到进入就绪状态在有可能再次被CPU调度 阻塞又分为三种: 1)等待阻塞:运行状态的线程执行wait方法,JVM会把线程放在等待队列中,使本线程进入阻塞状态。 2)同步阻塞:线程在获得synchronized同步锁失败,JVM会把线程放入锁池中,线程进入同步阻塞。 3)其他阻塞:调用线程的sleep()或者join()后,线程会进入道阻塞状态,当sleep超时或者join终止或超时,线程重新转入就绪状态 5.死亡(dead) 线程run()、main()方法执行结束,或者因为异常退出了run()方法,则该线程结束生命周期 死亡的线程不可再次复生
join方法详解:
前面几篇文章讲解了wait()方法之后,我们再来讲讲join()方法,因为join()方法就是通过wait()方法实现的。
join()方法的作用:让主线程等待(WAITING状态),一直等到其他线程不再活动为止。
join在英语中是“加入”的意思,join()方法要做的事就是,当有新的线程加入时,主线程会进入等待状态,一直到调用join()方法的线程执行结束为止。
4.如何面对缓存穿透,缓存击穿,缓存雪崩,怎么解决?
5.在一个分布式系统场景下面,如何设置唯一主键
如何在分布式场景下生成全局唯一 ID ? - 腾讯云开发者社区-腾讯云 (tencent.com)
6.如何避免下单接口重复接单
【干货】如何防止接口重复提交?(中) - 腾讯云开发者社区-腾讯云 (tencent.com)
即如何实现接口幂等性:阿里面试官:接口的幂等性怎么设计? - 知乎 (zhihu.com)
方案一:
下面我们以防止重复提交订单为例,向大家介绍最简单的、成本最低的解决办法。
我们先来看一张图,这张图就是本次方案的核心流程图。

实现的逻辑,流程如下:
-
1.当用户进入订单提交界面的时候,调用后端获取请求唯一ID,并将唯一ID值埋点在页面里面
-
2.当用户点击提交按钮时,后端检查这个唯一ID是否用过,如果没有用过,继续后续逻辑;如果用过,就提示重复提交
-
3.最关键的一步操作,就是把这个唯一ID 存入业务表中,同时设置这个字段为唯一索引类型,从数据库层面做防止重复提交
方案二:
随着业务的快速增长,每一秒的下单请求次数,可能从几十上升到几百甚至几千。
面对这种下单流量越来越高的场景,此时数据库的访问压力会急剧上升,上面这套方案全靠数据库来解决,会特别吃力!
对于这样的场景,我们可以选择引入缓存中间件来解决,可选的组件有 redis、memcache 等。
下面,我们以引入redis缓存数据库服务器,向大家介绍具体的解决方案!
实现的逻辑,流程如下:
-
1.当用户进入订单提交界面的时候,调用后端获取请求唯一 ID,同时后端将请求唯一ID存储到
redis中再返回给前端,前端将唯一 ID 值埋点在页面里面 -
2.当用户点击提交按钮时,后端检查这个请求唯一 ID 是否存在,如果不存在,提示错误信息;如果存在,继续后续检查流程
-
3.使用
redis的分布式锁服务,对请求 ID 在限定的时间内进行加锁,如果加锁成功,继续后续流程;如果加锁失败,说明服务正在处理,请勿重复提交 -
4.最后一步,如果加锁成功后,需要将锁手动释放掉,以免再次请求时,提示同样的信息;同时如果任务执行成功,需要将
redis中的请求唯一 ID 清理掉 -
5.至于数据库是否需要增加字段唯一索引,理论上可以不用加,如果加了更保险
方案三:
每次提交的时候,需要先调用后端服务获取请求唯一ID,然后才能提交。
对于这样的流程,不少的同学可能会感觉到非常鸡肋,尤其是单元测试,需要每次先获取submitToken值,然后才能提交!
能不能不用这么麻烦,直接服务端通过一些规则组合,生成本次请求唯一ID呢?
答案是可以的!
今天我们就一起来看看,如何通过服务端来完成请求唯一 ID 的生成?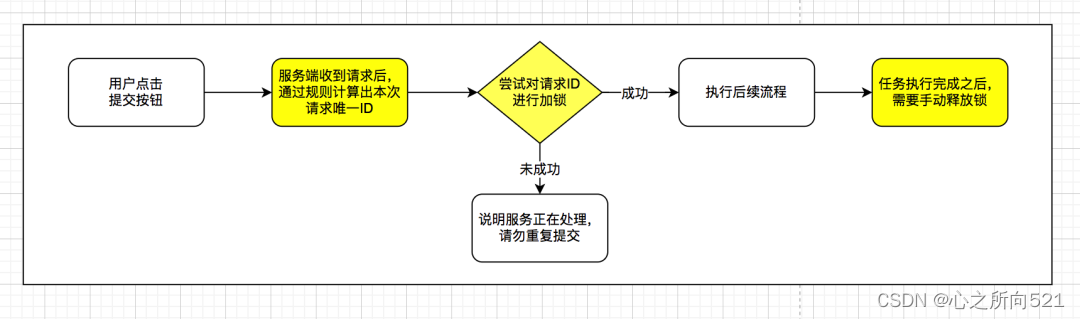
实现的逻辑,流程如下:
-
1.用户点击提交按钮,服务端接受到请求后,通过规则计算出本次请求唯一ID值
-
2.使用
redis的分布式锁服务,对请求 ID 在限定的时间内尝试进行加锁,如果加锁成功,继续后续流程;如果加锁失败,说明服务正在处理,请勿重复提交 -
3.最后一步,如果加锁成功后,需要将锁手动释放掉,以免再次请求时,提示同样的信息
7.Redis 过期键的的删除策略?
其实有三种不同的删除策略: (1):立即删除。在设置键的过期时间时,创建一个回调事件,当过期时间达到时,由时间处理器自动执行键的删除操作。 (2):惰性删除。键过期了就过期了,不管。每次从dict字典中按key取值时,先检查此key是否已经过期,如果过期了就删除它,并返回nil,如果没过期,就返回键值。 (3):定时删除。每隔一段时间,对expires字典进行检查,删除里面的过期键。 可以看到,第二种为被动删除,第一种和第三种为主动删除,且第一种实时性更高。下面对这三种删除策略进行具体分析。
具体介绍:
立即删除
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力。
而且目前redis事件处理器对时间事件的处理方式–无序链表,查找一个key的时间复杂度为O(n),所以并不适合用来处理大量的时间事件。
惰性删除
惰性删除是指,某个键值过期后,此键值不会马上被删除,而是等到下次被使用的时候,才会被检查到过期,此时才能得到删除。所以惰性删除的缺点很明显:浪费内存。dict字典和expires字典都要保存这个键值的信息。
举个例子,对于一些按时间点来更新的数据,比如log日志,过期后在很长的一段时间内可能都得不到访问,这样在这段时间内就要拜拜浪费这么多内存来存log。这对于性能非常依赖于内存大小的redis来说,是比较致命的。
定时删除
从上面分析来看,立即删除会短时间内占用大量cpu,惰性删除会在一段时间内浪费内存,所以定时删除是一个折中的办法。 定时删除是:每隔一段时间执行一次删除操作,并通过限制删除操作执行的时长和频率,来减少删除操作对cpu的影响。另一方面定时删除也有效的减少了因惰性删除带来的内存浪费。
8.SQL语句,A、B两表,找出ID字段中,存在 EA表,但是不存在B表的数据
-
使用 not in ,容易理解,效率低 执行时间为:1.395秒
select distinct A.ID from A where A.ID not in (select ID from B)
-
使用 left join…on… , “B.ID isnull” 表示左连接之后在B.ID 字段为 null的记录 执行时间:0.739秒
select A.ID from A left join B on A.ID=B.ID where B.ID is null
-
逻辑相对复杂,但是速度最快 ~执行时间: 0.570秒~
select * from B where (select count(1) as num from A where A.ID = B.ID) = 0
(说实话,没太理解最后一种方法~)
注意:
COUNT函数的用法,主要用于统计表行数。主要用法有COUNT(*)、COUNT(字段)和COUNT(1)。因为
COUNT(*)是SQL92定义的标准统计行数的语法,所以MySQL对他进行了很多优化,MyISAM中会直接把表的总行数单独记录下来供COUNT(*)查询,而InnoDB则会在扫表的时候选择最小的索引来降低成本。当然,这些优化的前提都是没有进行where和group的条件查询。在InnoDB中
COUNT(*)和COUNT(1)实现上没有区别,而且效率一样,但是COUNT(字段)需要进行字段的非NULL判断,所以效率会低一些。因为
COUNT(*)是SQL92定义的标准统计行数的语法,并且效率高,所以请直接使用COUNT(*)查询表的行数!
9.MySQL索引类型有哪些?联合索引的应用?
-
PRIMARY KEY 主键索引
-
INDEX 普通索引
-
UNIQUE 唯一索引
-
FULLTEXT 全文索引
-
组合/联合索引(较特殊)
具体介绍:
主键索引:主键是一种唯一性索引,每个表只能有一个主键,在单表查询中,PRIMARY主键索引与UNIQUE唯一索引的检索效率并没有多大的区别,
但在关联查询中,PRIMARY主键索引的检索速度要高于UNIQUE唯一索引。
普通索引:这是最基本的索引类型,而且它没有唯一性之类的限制。
唯一索引:这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一。
全文索引:MySql从3.23版开始支持全文索引和全文检索。全文索引只可以在VARCHAR或者TEXT类型的列上创建。
联合索引 (也叫组合索引、复合索引、多列索引)是指对表上的多个列进行索引。
联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
联合索引的应用:
应用场景一:SQL查询列很少,建立查询列的联合索引可以有效消除回表,但一般超过3个字段的联合索引都是不合适的.
应用场景二:在字段A返回记录多,在字段B返回记录多,在字段A,B同时查询返回记录少,比如执行下面的查询,结果c1,c2都很多,c3却很少。
select count(1) c1 from t where A = 1; select count(1) c2 from t where B = 2; select count(1) c3 from t where A = 1 and B = 2;
其他应用:
(1) select * from mytable where a=3 and b=5 and c=4; # abc 三列都使用索引,而且都有效 (2) select * from mytable where c=4 and b=6 and a=3; # mysql没有那么笨,不会因为书写顺序而无法识辨索引。 # where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样。 (3) select * from mytable where a=3 and c=7; # a 用到索引,sql中没有使用 b列,b列中断,c没有用到索引 (4) select * from mytable where a=3 and b>7 and c=3; # a 用到索引,b也用到索引,c没有用到。 # 因为 b是范围索引,所以b处断点,复合索引中后序的列即使出现,索引也是无效的。 (5) select * from mytable where b=3 and c=4; # sql中没有使用a列, 所以b,c 就无法使用到索引 (6) select * from mytable where a>4 and b=7 and c=9; # a 用到索引, a是范围索引,索引在a处中断, b、c没有使用索引 (7) select * from mytable where a=3 order by b; # a用到了索引,b在结果排序中也用到了索引的效果。前面说过,a下面任意一段的b是排好序的 (8) select * from mytable where a=3 order by c; # a 用到了索引,sql中没有使用 b列,索引中断,c处没有使用索引,在 Extra列 可以看到 filesort (9) select * from mytable where b=3 order by a; # 此sql中,先b,后a,导致 b=3 索引无效,排序a也索引无效。
索引的危害
表上有过多索引主要会严重影响插入性能;
-
对delete操作,删除少量数据索引可以有效快速定位,提升删除效率,但是如果删除大量数据就会有负面影响;
-
对update操作类似delete,而且如果更新的是非索引列则无影响。
10.Http的请求调用过程、协议?
链接:一次完整的HTTP请求过程是怎么样的呢?【图文详解】 - 知乎 (zhihu.com)
具体步骤:
-
浏览器进行DNS域名解析,得到对应的IP地址
-
根据这个IP,找到对应的服务器建立连接(三次握手)
-
建立TCP连接后发起HTTP请求(一个完整的http请求报文)
-
服务器响应HTTP请求,浏览器得到html代码(服务器如何响应)
-
浏览器解析html代码,并请求html代码中的资源(如js、css、图片等)
-
浏览器对页面进行渲染呈现给用户
-
服务器关闭TCP连接(四次挥手)
11.fullGC问题如何排查、程序OOM是否还能继续执行
排查:
1.首先我们可以使用top命令查看系统CPU的占用情况
2.接下来我们可以通过jstack命令查看线程id为X的线程为什么耗费CPU最高
3.如果发现full gc数量不断增长,进一步证实了是由于内存溢出导致的系统缓慢。那么这里确认了内存溢出,但是如何查看你是哪些对象导致的内存溢出呢,这个可以dump出内存日志,然后通过eclipse的mat工具进行查看
4.经过mat工具分析之后,我们基本上就能确定内存中主要是哪个对象比较消耗内存,然后找到该对象的创建位置,进行处理即可
OOM后是否运行?
-
OutOfMemoryError是可以catch的。 catch之后吞掉的话程序还能试着继续运行。
-
-
OOM的机制决定了这不一个单进程的状态,系统会选择一些可能占用了巨大资源(不一定是内存)且不是那么重要的进程来释放资源。
-
OOM发生时如果程序能正常处理这个异常情况,比如不再申请更多的内存或其它资源,或者放弃那个子任务或子线程,系统OOM状态是可以回到正常情况,事实上系统也期望你这么做。
-
12.JVM类加载机制别?自写java.lang.String能加载吗?
当自己定义了一个 String类 ,且包名也是java.lang,为什么不会被加载,因为双亲委派机制,当加载String类时,会一层一层的往上委托,直到在启动类加载器Bootstrap ClassLoader,而启动类加载器能够加载String类,因为在java包下有,所以加载的是Java中的String,而不是自定义的。
13.Thread Local底层原理?怎么避免内存泄漏
《提升能力,涨薪可待》-ThreadLocal的内存泄露的原因分析以及如何避免 - 掘金 (juejin.cn)
现在,我们可以看出ThreadLocal的设计思想了:
(1) ThreadLocal仅仅是个变量访问的入口;
(2) 每一个Thread对象都有一个ThreadLocalMap对象,这个ThreadLocalMap持有对象的引用;
(3) ThreadLocalMap以当前的threadLocal对象为key,以真正的存储对象为value。get()方法时通过threadLocal实例就可以找到绑定在当前线程上的副本对象。

ThreadLocal底层实现原理详解 - 掘金 (juejin.cn)
内存泄漏问题:--定时去remove操作!
key 使用强引用
当hreadLocalMap的key为强引用回收ThreadLocal时,因为ThreadLocalMap还持有ThreadLocal的强引用,如果没有手动删除,ThreadLocal不会被回收,导致Entry内存泄漏。
key 使用弱引用
当ThreadLocalMap的key为弱引用回收ThreadLocal时,由于ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被回收。当key为null,在下一次ThreadLocalMap调用set(),get(),remove()方法的时候会被清除value值。
15.synchronized和 Lock区别,实现原理?
还有很多口头说的问题,没有记录····
算法题:直接手撕一个大数相加的代码
总结:
问的其实比较常规,但是自己八股这一块背的还不行,基本的原理没有理解深入,或者深入透彻!
算法刷的远远不够···
项目自己一定好好深入理解每一部分原理,同时寻求新的好的项目!