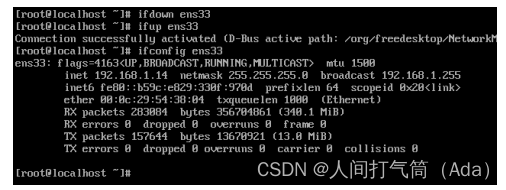
1、概率和统计是一个东西吗?
概率(probabilty)和统计(statistics)看似两个相近的概念,其实研究的问题刚好相反。
一句话总结:概率是已知模型和参数,推数据。统计是已知数据,推模型和参数。
显然,本文解释的MLE和MAP都是统计领域的问题。它们都是用来推测参数的方法。为什么会存在着两种不同方法呢?这需要理解贝叶斯思想。我们来看看贝叶斯公式。
2、贝叶斯公式到底在说什么?
有时候,我们想要知道在给定事件B的基础上,计算事件A发生的概率,即 P ( A ∣ B ) P(A|B) P(A∣B) 。但是,我们可能只能计算P(B|A)。这种问题经常出现在如下场景:在某些证据下,某个事件发生的可能性有多大,比如我们想知道一个人的血液检查结果为阳性,那么他得病的概率有多大?但是,我们只能知道在得病的条件下,血液检查结果呈阳性的概率为95%,即在给定事件下,知道证据发生的概率。
贝叶斯公式可以在知道
P
(
B
∣
A
)
P(B|A)
P(B∣A)的情况下,计算出
P
(
A
∣
B
)
P(A|B)
P(A∣B),具体公式为 :
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
)
P(A|B)=\frac{P(B|A)P(A)}{P(B)}
P(A∣B)=P(B)P(B∣A)P(A)
如上贝叶斯公式实现了概率反转,即由
P
(
B
∣
A
)
P(B|A)
P(B∣A) 得到
P
(
A
∣
B
)
P(A|B)
P(A∣B)。
几点理解:
- 很多时候是因为直接的P(B|A)无法观察到,只能观察到P(A|B),所以可以通过概率反转的方式达到求解P(B|A)的目的。
- 待补充
相关术语:
- P(A|B)称为后验概率(posterior),这是我们需要结合先验概率和证据计算之后才能知道的。
- P(B|A)称为似然(likelihood),在事件A发生的情况下,事件B(或evidence)的概率有多大
- P(A)称为先验概率(prior), 事件A发生的概率有多大
- P(B)称为证据(evidence),即无论事件如何,事件B(或evidence)的可能性有多大
先验后验的概念,可以参考笔者文章如何理解先验概率与后验概率
贝叶斯规则给出了一个规则,即将一些先验的信念(贝叶斯认为概率是对某种信念的度量)与观察到的数据结合起来,来更新信念,这个过程也称为“学习”。或者说,我们的信念随着获得的信息增多而发生改变。比如说,我们认为在年终的时候有50%的可能会得到升职;如果我们从老板那里得到了正面且积极的反馈,我们可能会上调这个概率值,反之会下调。随着我们获得信息的增多,我们不断调整我们的估计值,直到它接近真正的答案。
贝叶斯估计例题练习:

3、似然函数
似然(likelihood)这个词其实和概率(probability)是差不多的意思,Colins字典这么解释:The likelihood of something happening is how likely it is to happen. 你把likelihood换成probability,这解释也读得通。但是在统计里面,似然函数和概率函数却是两个不同的概念(其实也很相近就是了)。
对于这个函数: P ( x ∣ θ ) P(x|\theta) P(x∣θ),如果 θ \theta θ 是已知确定的, x x x 是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点 x x x,其出现概率是多少。
如果 x x x 是已知确定的, θ \theta θ 是变量,这个函数叫做似然函数(likelihood function),它描述对于不同的模型参数,出现x这个样本点的概率是多少。
4、最大似然估计(MLE)
假设有一个造币厂生产某种硬币,现在我们拿到了一枚这种硬币,想试试这硬币是不是均匀的。这是一个统计问题,回想一下,解决统计问题需要什么?数据!
于是我们拿这枚硬币抛了10次,得到的数据是:反正正正正反正正正反。我们想求的正面概率 是模型参数,而抛硬币模型我们可以假设是二项分布。
那么,出现实验结果 (即反正正正正反正正正反)的似然函数是多少呢?
f
(
x
,
θ
)
=
(
1
−
θ
)
×
θ
.
.
.
×
θ
×
(
1
−
θ
)
=
θ
7
(
1
−
θ
)
3
f(x,\theta) = (1-\theta)\times\theta ...\times \theta \times (1-\theta)=\theta^7(1-\theta)^3
f(x,θ)=(1−θ)×θ...×θ×(1−θ)=θ7(1−θ)3
注意,这是个只关于 θ \theta θ 的函数。而最大似然估计,顾名思义,就是要最大化这个函数。
对似然函数取对数,不会影响该函数的单调性,从而不会影响最后的计算的极值,也可以在一定程度上减少因计算而带来的误差,还可以极大的简化计算。
如果未知参数有多个,则需要用取对数的似然函数对每个参数进行求偏导,使得所有偏导均为0的值,即为该函数的极值点,一般也是其最大似然估计值。
我们可以画出图像:

可以看出,在
θ
=
0.7
\theta=0.7
θ=0.7,似然函数取得最大值。
我们已经完成了对 θ \theta θ 的最大似然估计。
即,抛10次硬币,发现7次硬币正面向上,最大似然估计认为正面向上的概率是0.7。
5、最大后验概率估计(MAP)
最大后验(Maximum A Posteriori,MAP)估计可以利用经验数据获得对未观测量的点态估计。它与Fisher的最(极)大似然估计(Maximum Likelihood,ML)方法相近,不同的是它扩充了优化的目标函数,其中融合了预估计量的先验分布信息,所以最大后验估计可以看作是正则化(regularized)的最大似然估计。 最大后验概率就是把他们的假设都进行计算(验算),然后选择其中假设最好的一个,当作最大后验概率。由于 θ \theta θ 的取值范围在0到1之间,有无数种假设,但我们不可能每种假设都进行计算,这个时候,就需要利用一些简单的数学方法,求出最大的那一个,即为最大后验概率。
最大似然估计是求参数 θ \theta θ ,使似然函数 P ( x ∣ θ ) P(x|\theta) P(x∣θ) 最大。最大后验概率估计则是想求 θ \theta θ 使 P ( x ∣ θ ) P ( θ ) P(x|\theta)P(\theta) P(x∣θ)P(θ) 最大。求得的 θ \theta θ 不单单让似然函数大, θ \theta θ 自己出现的先验概率也得大。(点像正则化里加惩罚项的思想,不过正则化里是利用加法,而MAP里是利用乘法)
P ( θ ∣ x ) = P ( x ∣ θ ) P ( θ ) P ( x ) P(\theta|x) = \frac{P(x|\theta)P(\theta)}{P(x)} P(θ∣x)=P(x)P(x∣θ)P(θ)
是一个已知值(实验观察到的数据)假设“投10次硬币”是一次实验,实验做了1000次,“反反正正正反正正正反”出现了 n n n 次,则 P ( x ) = n / 1000 P(x) = n/1000 P(x)=n/1000。总之,这是一个可以由数据集得到的值。
P ( θ ∣ x ) P(\theta|x) P(θ∣x) 即后验概率,这就是“最大后验概率估计”名字的由来。
计算过程示例:将
θ
\theta
θ 的概率分布假设为均值为0.5,方差为1的正态分布:
f
(
θ
)
=
θ
6
(
1
−
θ
)
4
f(\theta)=\theta^6(1-\theta)^4
f(θ)=θ6(1−θ)4
则有:
a
r
g
m
a
x
θ
P
(
θ
∣
x
0
,
x
1
,
.
.
.
,
x
n
)
=
a
r
g
m
a
x
θ
P
(
θ
∣
x
0
,
x
1
,
.
.
.
,
x
n
∣
θ
)
×
P
(
θ
)
argmax_{\theta} \ P(\theta|x_0,x_1,...,x_n)=argmax_\theta P(\theta|x_0,x_1,...,x_n|\theta)\times P(\theta)
argmaxθ P(θ∣x0,x1,...,xn)=argmaxθP(θ∣x0,x1,...,xn∣θ)×P(θ)
由于MAP有:
a
r
g
m
a
x
θ
P
(
θ
∣
x
0
,
x
1
,
.
.
.
,
x
n
)
∼
a
r
g
m
a
x
θ
l
n
[
P
(
θ
∣
x
0
,
x
1
,
.
.
.
,
x
n
∣
θ
)
×
P
(
θ
)
]
argmax_{\theta} \ P(\theta|x_0,x_1,...,x_n) \sim argmax_\theta ln[P(\theta|x_0,x_1,...,x_n|\theta)\times P(\theta)]
argmaxθ P(θ∣x0,x1,...,xn)∼argmaxθln[P(θ∣x0,x1,...,xn∣θ)×P(θ)]
带入 θ \theta θ 的正太分布概率密度函数 P ( θ ) P(\theta) P(θ),有

求导得到
θ
\theta
θ 的估计值:

显然在这道题中
θ
=
0.5977
\theta = 0.5977
θ=0.5977 ,也就是说,当
θ
\theta
θ 的密度函数为均值为 0.5,方差为 1 的正态分布时,投该硬币出现正面的概率为0.5977时是可能性最大的。
这里我们回到MLE的数据案例——反正正正正反正正正反,作为对比。
对于投硬币的例子来看,我们认为(”先验地知道“) θ \theta θ 取 0.5 的概率很大,取其他值的概率小一些。我们用一个高斯分布来具体描述我们掌握的这个先验知识,例如假设 P ( θ ) P(\theta) P(θ) 为均值0.5,方差0.1的高斯函数,如下图:

P
(
x
∣
θ
)
P
(
θ
)
P(x|\theta)P(\theta)
P(x∣θ)P(θ)的函数图像为:

注意,此时函数取最大值时,
θ
\theta
θ 取值已向左偏移,不再是 0.7。实际上,在
θ
=
0.558
\theta=0.558
θ=0.558时函数取得了最大值。即用最大后验概率估计,得到
θ
=
0.558
\theta = 0.558
θ=0.558。
最后,那要怎样才能说服一个贝叶斯派相信 θ = 0.7 \theta = 0.7 θ=0.7 呢?你得多做点实验…
如果做了 1000 次实验,其中 700 次都是正面向上,这时似然函数为:

P
(
x
∣
θ
)
P
(
θ
)
P(x|\theta)P(\theta)
P(x∣θ)P(θ)的函数图像为:

在
θ
=
0.696
\theta =0.696
θ=0.696 时函数取得了最大值
这样,就算一个考虑了先验概率的贝叶斯派,也不得不承认得把 θ \theta θ 估计在 0.7 附近了。
一个合理的先验概率假设是很重要的。(通常,先验概率能从数据中直接分析得到)
最大后验的实质就是对参数的每一个可能的取值,都进行极大似然估计,并根据这个取值可能性的大小,设置极大似然估计的权重,然后选择其中最大的一个,作为最大后验估计的结果。
6、最大似然估计和最大后验概率估计的区别
MAP 就是多个作为因子的先验概率 P ( θ ) P(\theta) P(θ)【贝叶斯派】。或者,也可以反过来,认为 MLE 是把先验概率 P ( θ ) P(\theta) P(θ) 等于1做计算,即认为 P ( θ ) P(\theta) P(θ) 是均匀分布【频率派】。
Ref:
[1].最大似然估计(MLE)VS 最大后验概率估计(MAP)
[2].贝叶斯公式简介及示例讲解
[3].如何理解先验概率与后验概率