最近项目进入胶着状态。
混合场景在有些项目组里已经可以开始了,但还是有两三个项目组现在是完全没办法混合起来的。
本周计划是把基准测试、容量测试跑完,稳定性测试每个项目组至少能跑一遍。
但是从进度上来看,容量测试至少有四个系统不能跑完了。
直到现在,还有问题。这周的问题感觉每个系统每天都会出现新问题。
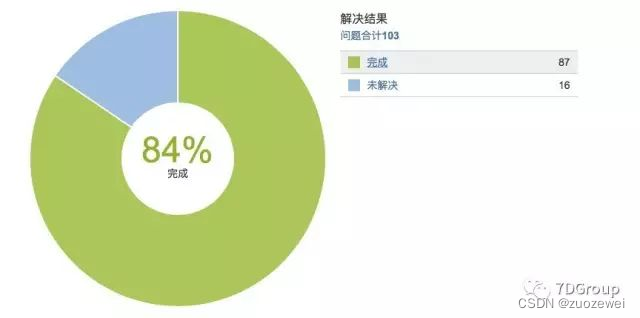
从统计的问题来看,加上没有放到 Jira 上的问题,已经近两百个了。
按8个系统平均来算,一个系统已经出现了20多个。
据我的感觉,还有一些琐碎的问题没有提的,像这个表缺个索引,那个参数又配置错了。修改起来很快的。估计要超过每个系统 30 个性能问题。
这在一个项目中已经非常难得见了。
互联网架构用来做金融,本身带来的问题,也非常明确地体现出来了。业务逻辑的复杂性和互联网架构的耦合带来的分析问题的复杂度,也非常明显。
从技术上来说,真没有多少新东西。只是从架构和分析的思路上,逻辑要重新画一下。

以上只是支付系统的一部分逻辑。
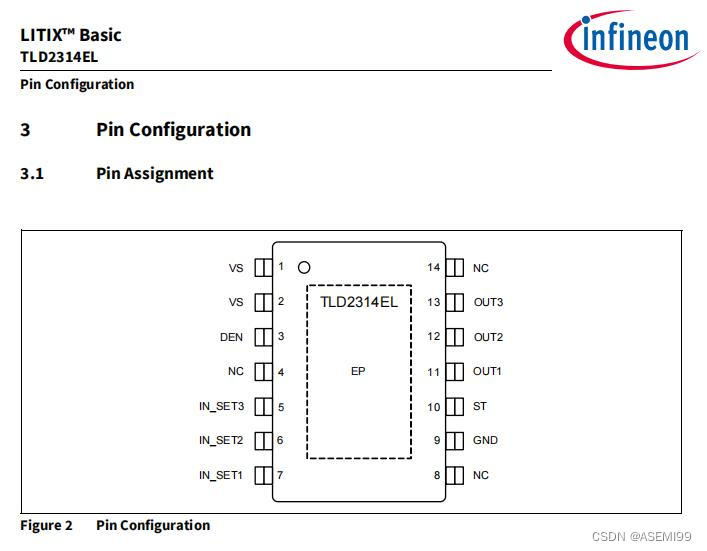
再简化一下拓扑图就像下面这样。
这上面我已经把挡板都不画了。数据流转的逻辑上大概就是这样了。而这里面光渠道总线就已经有五个模块。每个模块中又有三个机器左右,又有主从,或者读写分离等等。所以在分析的时候逻辑就变得非常重要了。
面对一个系统,先画逻辑图对理解分析的思路很有帮助。
昨天有一个项目的 TPS 死活上不去,CPU 消耗只能到 30 %左右,几个同事分析了老半天。最后的时候也打了threaddump,也看到了阻塞在log写的时候。但是翻了下代码,觉得写法是没有问题的呀。
他们做了一个动作是把tomcat的线程数加大,我正好上楼说另一个事情,他们跟我说了一下。我听说他们的前面的分析思路觉得挺靠谱的,但是提到增加线程数,我就不能理解了。
于是我就停下来看了一眼他们的 thread 状态。看到有大量的是在 waiting on monitor 的状态。我就问他们为什么增加线程数?他们觉得这样也许可以把CPU用上去。可是我说你们这等待的就这么多了,还加线程数,不是等得更多了吗?
所以分析之后的优化还是要往合理的方向上去。我说你们都看到了log写导致了等待出现。那就把log写的逻辑分析一下。我让他们把代码翻来看看,结果看到了配置的同步log。也没有配置写buffer。我让他们先把log写降下来,那最快的验证的方式就是把log级别调高。原来是info,我说调到error,先验证下方向是不是对的。
结果一调到error,同样的场景,TPS就增加了4倍,CPU消耗高达70%。然后优化的方向就很明确了,就是让log写更快。异步是一种方式,如果云平台的IO不行,可以考虑换存储,也可以考虑加buffer。也可以这些步骤一起来做。
总之现在TPS是在单实例就可以达到要求了,从业务上说没有了风险,后面怎么做得更细致,那就看对技术的执着程度了。
昨天跟团队里的人讨论了分析思路要清晰地事情,我再三强调,分析思路就清晰明确,不要因为怀疑而做动作。性能分析绝不是几个人讨论能出结果的,而是数据的一层层剥开。
今天下午,说到核心系统有个交易要 300ms 完成。我一看,怎么这么长?核心系统要是这么长,那前面的渠道怎么办?经过四五层之后,随便加加也会超过1秒2秒的了。而他们给自己定的目标是1秒以内。我觉得完全没有从架构上考虑前端的感受。借着讨论其他sql的机会,我把那个核心库的慢 SQL 也拿下来看了一眼(现在慢 SQL我让数据中心配置到 100ms 以上就打)。发现了核心业务系统中有好多慢的 SQL。我跟他们说了一下,他们现在开始考虑分析慢sql的逻辑去了。
再说沟通,性能组的沟通往往是矩阵式的。而不是单线的沟通,所以就要求做性能的人有足够的耐心、丰富的技巧、扎实的技术。在我现在的团队中,大概的组织结构是这样。
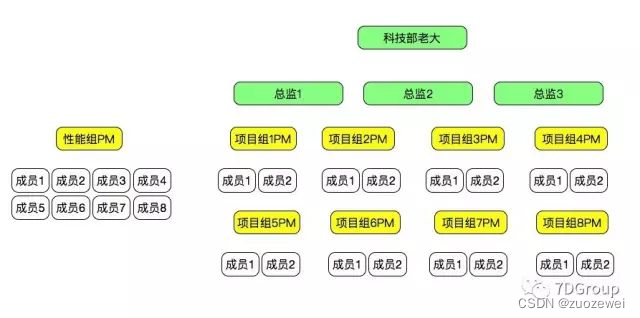
性能组成员跟其他组成员都会直接地沟通。可怕的不是性能组成员1<-〉项目组1成员1这样的沟通模式。而是链路式的沟通。
因为项目组之间是有依赖关系的,所以沟通关系有可能是这样的。
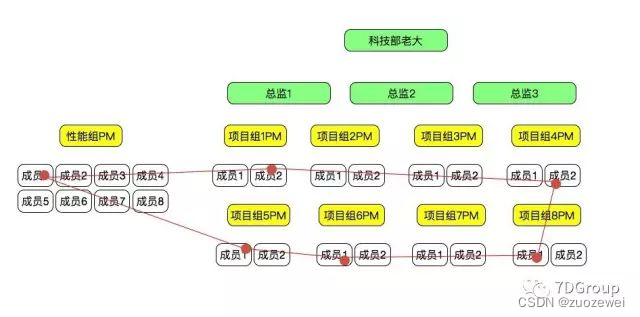
单个人的沟通看起来还能接受。但是当每个人都沟通的时候,可能就会乱了。
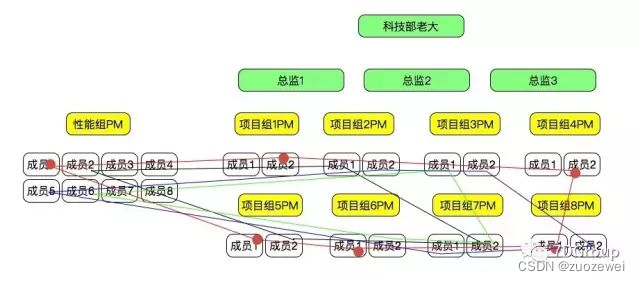
在项目中,项目组之间的沟通耗费的精力和时间往往比项目本身更多。
在这时候,PM 就要出马了,减少沟通中出现的技术误差和情绪误解。
性能组的 PM 要干的不只是沟通各项目组的 PM,往往有些决策还要依赖总监或者科技部老大,所以这些沟通都要性能组 PM 来做。
所以 PM 的职责,不仅是把握技术方向,还要做沟通,而沟通将占去性能组PM大部分的精力。
今天先写到这里吧。