水善利万物而不争,处众人之所恶,故几于道💦
目录
一、拦截器(Interceptor)和选择器(Selector)
拦截器(Interceptor)
选择器(Selector)
二、自定义拦截器实现步骤:
三、编程实现:
ETL拦截器
分类拦截器
一、拦截器(Interceptor)和选择器(Selector)
拦截器(Interceptor)
位于Source和Channel之间
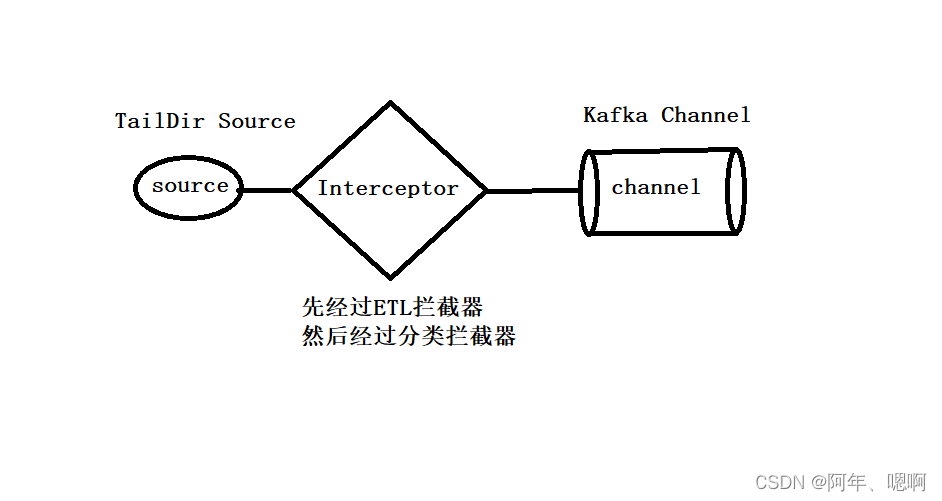 我们这里配置的第一个拦截器是ETL拦截器,先对数据进行轻度过滤,然后是分类拦截器,将不同类型的数据向header中添加不同的Value。
我们这里配置的第一个拦截器是ETL拦截器,先对数据进行轻度过滤,然后是分类拦截器,将不同类型的数据向header中添加不同的Value。
然后配置Source Selector将数据分别发送到不同的Kafka Channel中(也就是指定的Kafka topic中),因为Kafka Channel中的数据是直接存到Kafka中,省去了Sink,所以效率更高。
选择器(Selector)的类型:
replicating:默认这种类型,会将source发过来的events发往所有的channel
multiplexing:可以发送到不同的channel
Selector加深理解:
在Flume中,Selectors是组件之间的接口,用于确定应该将事件从哪个组件移动到哪个组件。通常有Source Selector、Channel Selector和Sink Selector。其中,Source Selector与Event Driven Source一起使用来选择源发送给Channel事件的方式;Channel Selector与Multiple Sink等组件一起使用,根据内部策略选择将事件路由到哪个Sink组件。Sink Selector可用于多种模式,例如Load Balancing Sink Processor,它可以将事件均匀地分配到不同的Sinks,或者Backup Sink Processor,它可以实现容错处理,在主Sink失败时自动切换到备份Sink。
在源头(Source)中使用的Selector被称为Source Selector,是用来决定哪些事件应该被发送到Channel中的。通常情况下,Source对象向其分配的所有Channel发送相同的事件流。然而,当您有多个Channel并且需要区分出仅适用于其中某一个Channel时,就需要使用Source Selector了。例如,Kafka Channel时就会用到Source Selector,以便将事件流按照特定方式路由到指定的Kafka topic。
与此不同,通道(Channel)中使用的Selectors称为Channel Selector,用于选择会被传输到单个或多个配置的下游组件的事件。在Channel Selector中,根据预定义的规则和算法确定将事件发送到哪个Sink, 来优化 Flume 的性能。
二、自定义拦截器实现步骤:
- 实现
Interceptor接口 - 重写四个方法:
● 初始化
● 单event,多event
● 关闭
● 创建静态内部类 - Builder - 打包上传
将打包后的jar包上传到Flume的lib目录下
三、编程实现:
新建maven工程,向pom.xml文件添加如下依赖:
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<!--用于编译Java代码,将源代码编译成目标字节码,并生成class文件。这里使用的版本是2.3.2,指定了编译器的源版本和目标版本都是1.8。-->
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<!--用于将当前模块及其所有依赖打包成一个可执行的JAR文件,
其中使用了descriptorRef为"jar-with-dependencies"的描述符来实现依赖包的合并,它在Maven打包期间会自动将相关的依赖项打包进去。-->
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
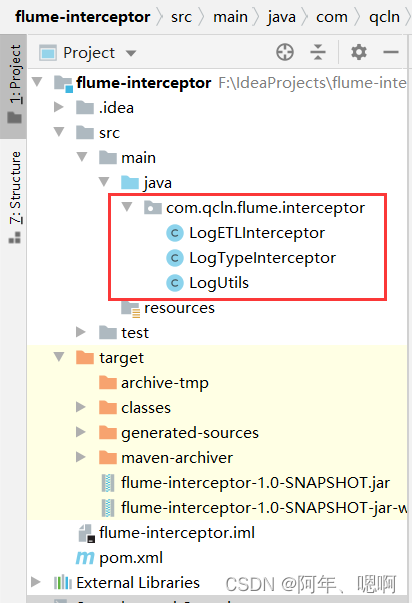
项目目录结构如下:
ETL拦截器:
对日志进行轻度的过滤,先将event转换为String,然后利用LogUtils类中的验证逻辑进行验证。
LogETLInterceptor
public class LogETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 将event 转换为string 方便处理
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
if(log.contains("start")){
// 清洗启动日志
if(LogUtils.vaildateStart(log)){
return event;
}
}else{
// 清洗事件日志
if(LogUtils.vaildateEvent(log)){
return event;
}
}
return null;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> interceptors = new ArrayList<>();
// 遍历event
for (Event event : events) {
// 调用上面的单event方法进行清洗
Event intercept1 = intercept(event);
if(intercept1 != null){ //因为单event返回的结果有null,所以这里要判空一下
interceptors.add(intercept1);
}
}
return interceptors;
}
@Override
public void close() {
}
// 静态内部类 Builder 这个静态内部类的类名不要变,也就是说,这个类的定义是死的,重写方法后new一个实体返回就行了
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
// new 一个自己
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
分类拦截器:
是为了将启动日志和事件日志发往不同的topic,所以将拦截到的event判断是否含有start(也就是是否为启动日志)然后往headers里面添加K-V,这个K-V不是随便写的,是你flume配置文件里面interceptor那块定义的

LogTypeInterceptor
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 去除body数据
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 取出header
Map<String, String> headers = event.getHeaders();
if(log.contains("start")){
headers.put("topic","topic_start");
}else{
headers.put("topic","topic_event");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> resultEvents = new ArrayList<>();
for (Event event : events) {
Event intercept1 = intercept(event);
// 不用判断因为只是添加了一个标记
resultEvents.add(intercept1);
}
return resultEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
日志工具类:
首先对传过来的日志进行判空,然后判断是否以大括号开头和结尾(json完整性判断);事件日志也一样,先进行判空,然后根据分隔符分割,判断长度是否为2,然后判断服务器时间是否全为数字以及json的完整性。
LogUtils
public class LogUtils {
public static boolean vaildateStart(String log) {
if(log == null){
return false;
}
// 是否是大括号开头和结尾,不是的话就干掉
if(!log.trim().startsWith("{") || !log.trim().endsWith("}")){
return false;
}
return true;
}
public static boolean vaildateEvent(String log) {
if(log == null){
return false;
}
// 时间 | json
// 切割
String[] logConents = log.split("\\|"); //正则表达式中 \| 表示 | ,所以要以|分隔的话就转义一下 \\|
// 判断长度
if(logConents.length != 2){
return false;
}
// 判断服务器时间 长度和都是数字,工具类,不等于13位和不全是数字就干掉
if(logConents[0].length() != 13 || !NumberUtils.isDigits(logConents[0])){
return false;
}
// 判断json完整性
if(!logConents[1].trim().startsWith("{") || !logConents[1].trim().endsWith("}")){
return false;
}
return true;
}
}