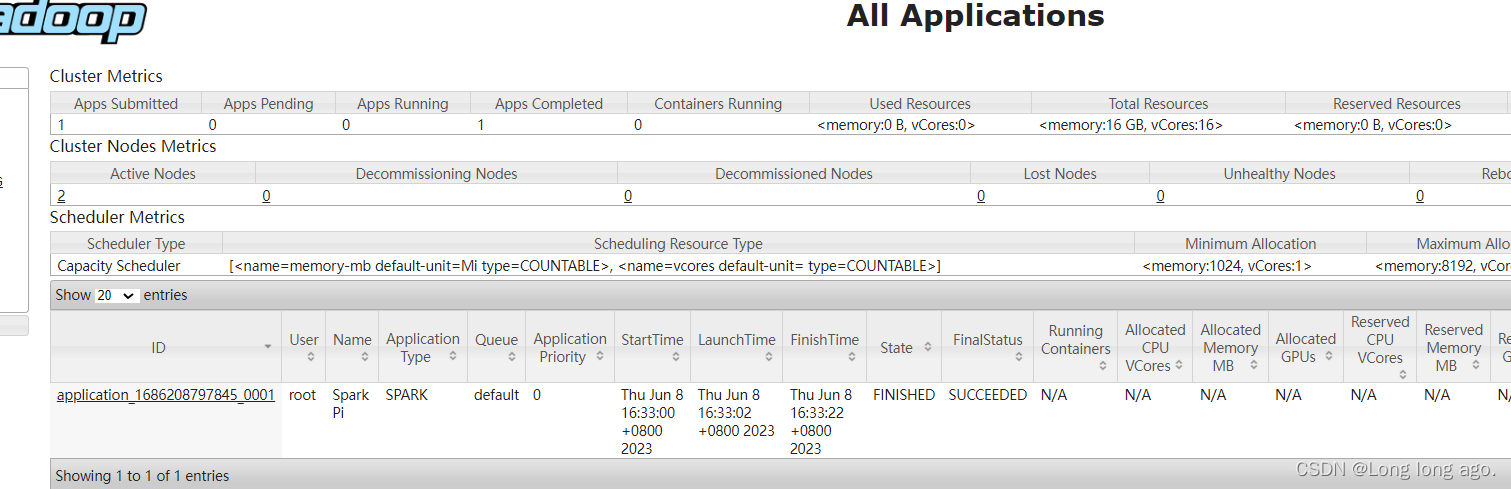
说明
鲁迅说:我家门前门前有两棵树,一棵是枣树,另一棵也是枣树。
从编程语言的角度,可以分为两大类(面向过程或面向对象),可以参考这篇文章
文章的内容其实不多,我贴一下:

对于两者的比较,文章这么说:

我觉得首先从形态上看,最早的语言都是流程式的,例如PASCAL这些。后来,无论是C++, Java还是Python这些主流语言都走向了对象的方式。
所以从形态上,对象是更高级的。
之所以写这篇文章,是因为我发现我总是喜欢流程化的方式(用Python也一样可以流程化),所以我想稍微剖析一下原因,给一个结论,以及未来的调整方法。
内容
1 流程化
我的最核心工作是建模,这项工作本身就非常强调流程
从数据的获取、探索、清洗、变换、衍生、选择、建模、验证、部署以及迭代这些步骤来看,工作本身就是非常强调流程的,甚至可以抽象为流水线模式(Pipeline)。
而且每一个步骤,其实有很多的地方都需要调整。这些调整会占据很多的精力和时间,所以注意力就会完全被流程占据。很多复杂的算法,其实就只是处理一道流程。
所以从工作的分解上,流程级是合适的。
我喜欢尽量在可靠的底层上全部自主实现全部功能
我发现所遇到的工具限制都比较大,所以一直以「矩阵之上」作为算法的起点,而架构上基本就是以Docker、数据库这样的产品作为起点,其他的都会自主实现。
基于这样的技术定位,那么大部分的功能都要反复的开发和调试,所以也很自然的的走向流程化的路子。
2 架构
在数据的传输和处理上,都走微服务的方法。注意力也就集中在了每一个API上,这样就更加不会想到对象化上。但是在几个月前,其实也已经开始了新一波的对象化工作。
例如,数据库的一整套API交互功能都有,但是在使用的时候往往会很麻烦。我的机器是按照分布式连起来的,那么对于不同的主机,在访问不同服务的时候就应该根据自身所处的位置进行适当的连接:Local、Lan或者Wan。所以这就需要每个发起的请求的Worker根据主机的信息,选择一个合适的连接方法,这时候就很适合对象来做。
通过API进行的功能的分离与持久化(服务化),然后又通过对象把一些常用的操作整合起来。
通过微服务 --> 对象化的过程,抽象上是完成了分–> 合的过程。Devide & Conquer ,有分也有治,这才是全部。
所以,我想在算法、模型、程序设计等方面,还是需要再次对象化。
3 需求
从我自己的设计与开发进展来看,的确需要进行对象化转换
只有通过对象化,才能实现进一步的集成与应用。当然,进行对象化其实会对执行性能略有损耗,但那些都是小事了。
3.1 程序设计需求
有的时候程序出错了,调试起来很麻烦。
本质上,这是流程化思路的问题。因为所有的逻辑串成一条,每一个细节都要保证正确,有点像是一口气背一长段课文。
如果通过对象化来做,首先就要抽象化。把一个任务的相关属性先抽出来,然后再把若干长段分为若干小段,每个小段的结果也保存到一个属性中。
这样如果出错,至少知道流程走到哪错了,要调试也很容易。
还有就是类似之前自动找合适连接方式的问题,避免每一次都要重新走一遍逻辑。在改版的时候只要重写方法就可以了。
3.2 算法的要求
流程式的写法只适应”一部头“的任务,更多的是验证,而不是生产
从强化、迭代的角度考虑,一个任务可能不是单步的,需要游走;任务可能也不是单个空间下的,而是要遍历多个空间。任务甚至不是一个人,不是一个月的,要持久和通用。
很明显,我现在已经开始进入强化的研究和实现。
3.3 高度定制化的产品设计
我希望产品可以随着用户的不同,甚至使用场景或者习惯不同而自动适应
我选择Flask作为构造Web服务的基础就是希望有一天可以通过Jinja来实现动态的页面返回。很显然,这只有通过对象化的方式才可能实现。
4 计划
现在没有特别明确的计划,但接下来,会强迫自己尽可能将各种工程结果使用对象来实现,有意识的注意:
- 1 通用属性、方法的抽象
- 2 状态的定义与转换方法
- 3 使用重写方式迭代