SQL知识点
1、SQL语言分类
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
1. 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块:SELECT <字段名表>FROM <表或视图名>WHERE <查询条件>
2 .数据操纵语言DML
数据操纵语言DML主要有三种形式:
\1) 插入:INSERT
\2) 更新:UPDATE
\3) 删除:DELETE
3. 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象-----表、视图、索引、同义词、聚簇等如:CREATE TABLE / VIEW / INDEX / SYN / CLUSTER| 表 视图 索引 同义词 簇。DDL操作是隐性提交的!不能rollback
4. 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
\1) GRANT:授权。
\2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。回滚—ROLLBACK回滚命令使数据库状态回到上次最后提交的状态。其格式为:SQL>ROLLBACK;
\3) COMMIT [WORK]:提交。在数据库的插入、删除和修改操作时,只有当事务在提交到数据库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看到所做的事情,别人只有在最后提交完成后才可以看到。
2、COALESCE函数
COALESCE ( expression,value1,value2……)
COALESCE()函数的第一个参数expression为待检测的表达式,而其后的参数个数不定。
COALESCE()函数将会返回包括expression在内的所有参数中的第一个非空表达式。
如果expression不为空值则返回expression;否则判断value1是否是空值,
如果value1不为空值则返回value1;否则判断value2是否是空值,
如果value2不为空值则返回value2;
……
如果所有的表达式都为空值,则返回NULL
总结: coalesce函数,返回第一个非空值,如果都是空,返回空值
3、SQL注入
防止SQL注入,需要注意以下几个要点:
- 永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和**双"-"**进行转换等。
- 永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取。
- 永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
- 不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
- 应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
- sql注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用sql注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。MDCSOFT SCAN等。采用MDCSOFT-IPS可以有效的防御SQL注入,XSS攻击等。
4、数据库
-
数据定义(SQL DDL)用于定义SQL模式、基本表、视图和索引的创建和撤消操作。
-
数据操纵(SQL DML)数据操纵分成数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。
-
数据控制(DCL)包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。
-
嵌入式SQL的使用规定(TCL)涉及到SQL语句嵌入在宿主语言程序中使用的规则。
5、数据库备份类型
1、完全备份
这可能是大多数人常用的方式,它可以备份整个数据库,包含用户表、系统表、索引、视图和存储过程等所有数据库对象。但是呢,它也需要花费更多的时间和空间,所以,一般推荐一周做一次完全备份。
2、事务日志备份
事务日志是一个单独的文件,它记录数据库的改变,备份的时候只需要复制自上次备份以来对数据库所做的改变,所以只需要很少的时间。为了使数据库具有鲁棒性,推荐每小时甚至更频繁的备份事务日志。
3、差异备份
也叫增量备份。它是只备份数据库一部分的另一种方法,它不使用事务日志,相反,它使用整个数据库的一种新映象。它比最初的完全备份小,因为它只包含自上次完全备份以来所改变的数据库。它的优点是存储和恢复速度快。推荐每天做一次差异备份。
4、文件备份
数据库可以由硬盘上的许多文件构成。如果这个数据库非常大,并且一个晚上也不能将它备份完,那么可以使用文件备份每晚备份数据库的一部分。由于一般情况下数据库不会大到必须使用多个文件存储,所以这种备份不是很常用
6、@@
@@ERROR:返回执行的上一个 Transact-SQLTransact-SQL 语句的错误号。
@@IDENTITY:返回自增id。
@@ROWCOUNT:返回受上一个SQL语句影响的行数。
@@MAX_CONNECTIONS:返回最大用户连接数。
7、关于删除
- delete 可以精确删除,只删除表的数据,不会删除结构。
- truncate 能删除表的数据,也能删除表的结构
- drop 完全删除表
1、处理效率:drop>trustcate>delete
2、drop删除整个表;trustcate删除全部记录,但不删除表;delete删除部分记录
3、delete不影响所用extent,高水线保持原位置不动;trustcate会将高水线复位。
-
TRUNCATE TABLE :删除内容、释放空间但不删除定义。
-
DELETE TABLE: 删除内容不删除定义,不释放空间。
-
DROP TABLE :删除内容和定义,释放空间。
8、事物读脏数据
隔离级别中,
读已授权解决脏读问题,在数据读取时添加共享锁,执行完语句后释放锁,数据写入时添加排它锁,事务提交后释放锁
可重复读解决不可重复读问题,在数据读取时添加共享锁,事务提交后释放锁,数据写入时添加排它锁,事务提交后释放锁
9、正则表达式
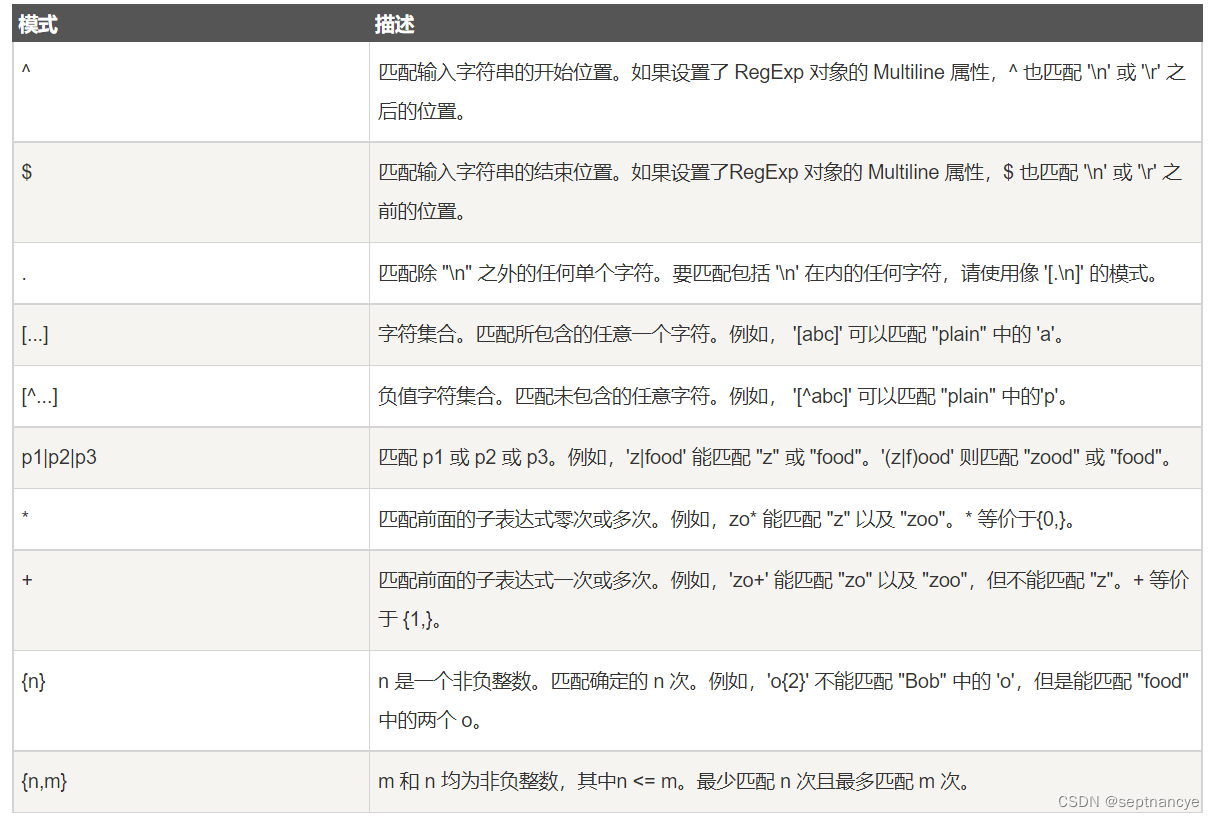
实例
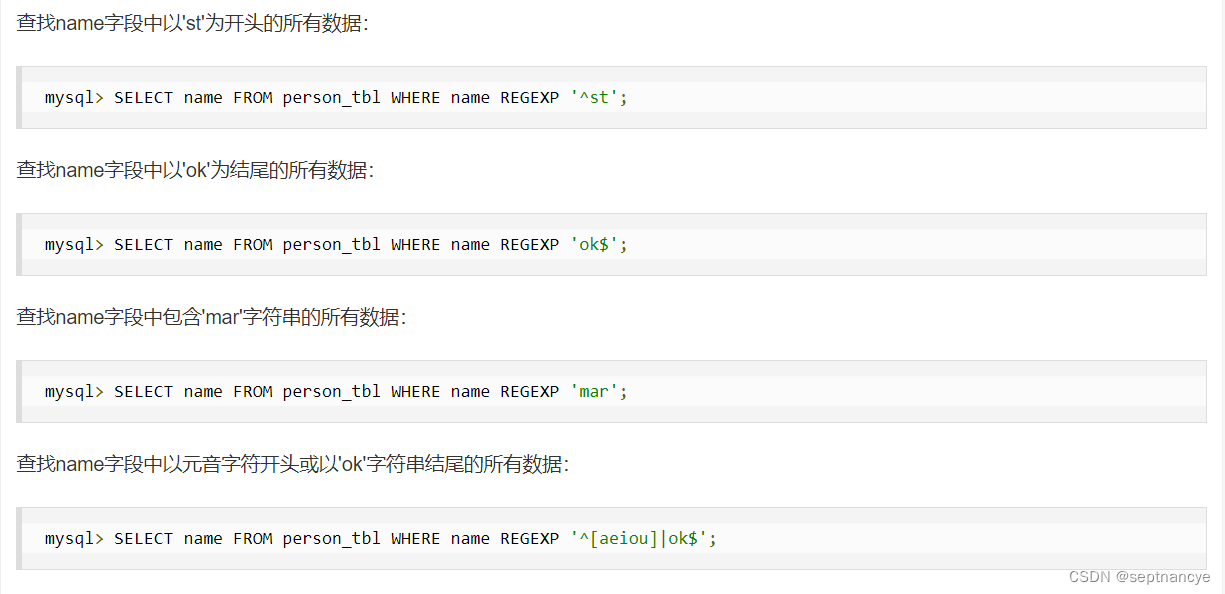
10、stuff
stuff(原字符,开始位置,删除长度,插入字符)。从指定的起点处开始删除指定长度的字符,并在此处插入另一组字符。
实例
查询语句select stuff(‘lo ina’,3, 1, ‘ve ch’)结果为 love china
11、触发器
SQL server 三种常用的触发器
1.insert触发器
2.update触发器
3.delete触发器
12、MySQL查询语句的执行顺序
正确的执行顺序应该是
- 先找到要查询表格或连接要查询的表格,因此FROM才是第一步;
- 接下来是进行条件筛选,所以是WHERE紧随其后;
- 然后如果遇到表格有分组的需要,则需要先GROUP BY;
- 分组时如果也存在筛选条件,这里就要用HAVING进行分组筛选;
- 这些执行过后才是查询操作SELECT;
- SELECT的时候如果遇到重复数据,就需要去重,即使用DISTINCT;
- 接下来如果要对查询后的数据进行排序,会用到ORDER BY;
- 最后如果要指定返回的查询数据范围、条数则要用LIMIT/OFFSET函数。
FROM(including JOINs) —> WHERE —> GROUP BY —> HAVING —> SELECT —> DISTINCT —> ORDER BY —> LIMIT/OFFSET
范围、条数则要用LIMIT/OFFSET函数。
FROM(including JOINs) —> WHERE —> GROUP BY —> HAVING —> SELECT —> DISTINCT —> ORDER BY —> LIMIT/OFFSET