buffer pool
mysql数据存放在磁盘里面,如果每次查询都直接从磁盘里面查询,会影响性能,因此需要内存态缓存池。另外缓存池的淘汰机制不是基础LRU,而是是改进版LRU,防止大量临时缓存挤出热点数据。buffer pool读缓存分为老年代和新生代,当有新页面加入buffer pool时,插入的位置是老年代的头部,并且该页面在1s(可配置)内再次被访问的话,再被移动到新生代。淘汰时,从新生代尾部淘汰。
change buffer
如果是写请求,且需要修改的数据不在缓冲池,一般不会将磁盘页先加载到缓冲池,而是把写操作缓存到change buffer中,当下次访问到这条数据后,会把数据页加载到buffer pool中,并且合并change buffer里面的变更。这样保证了数据的一致性,且批量写对性能影响不大。
写缓冲既是内存缓存,也有对应的磁盘页作为持久化。一个写请求加入写缓冲(内存),然后使用WAL机制写入redo log(磁盘)。
如果索引设置了唯一(unique)属性,在进行修改操作时,InnoDB需要进行唯一性检查也就是将相应的页读入到缓存。因此不适合写缓冲。所以写缓冲在写多读少,且非唯一索引的场景下比较合适使用。将原本每次写入都需要进行磁盘IO(随机写)的SQL,优化为定期批量写磁盘。
Doublewrite Buffer双缓冲
Innodb的数据页一般是16K,磁盘的页一般是4K,所以写一次磁盘数据,会有4次写磁盘的原子操作,因此可能刷盘时写完前面4K后断电,此时4K是新数据,后面的12K是老数据,出现了数据被破坏的情况,也就是页分裂。因为redo log对于insert/update操作不是记录原页完整数据,而是仅记录diff数据,因此无法基于redo log修复这类页数据损坏异常。需要使用double write buffer来保证磁盘数据写入的成功。

如上图,脏页刷盘时写两次磁盘,一次顺序追加写入dwb磁盘页,然后才是更新数据库真实磁盘页。当然也有其他解决办法,比如将磁盘页原值完整写入redo log,或者使用16k页大小的文件系统。
总结:
(1)在异常崩溃时,如果不出现磁盘页数据损坏,能够通过redo恢复数据;
(2)如果出现磁盘页数据损坏,能够通过double write buffer再通过通过redo恢复页数据;
redo log
redo日志用于保障,已提交事务的持久性。随机写优化为顺序写。
Redo log记录数据库变化的日志,修改的数据块包括:表所在数据块(表数据块),索引所在数据块(索引数据块),以及undo段所在数据块(undo数据块)!
redo log只需要记录:(1)某个数据页中(page num);(2)某个某个偏移位置(offset);(3)某个类型的数据(type);(4)改成了什么值(value);
因此当数据库崩溃的时候,如果缓冲池中的数据没有来得及刷盘,就可以通过redo log,把第1234页,偏移量为5678处的1个字节改为1,以此来恢复数据。
redo流程大致如下:
第一步:InnoDB将记录从硬盘读入内存,或直接写change buffer; |
第二步:生成一条undo log并写入redo log buffer,记录的是数据被修改后的值; |
第三步:当事务commit时,将redo log buffer中的内容刷新到redo log file磁盘,对 redo log file采用追加写的方式; |
第四步:定期将内存中修改的数据刷新到磁盘中。这里不是指从redo log file刷入磁盘,而是从内存缓存刷入磁盘,redo log file只在崩溃恢复数据时才用。如果数据库崩溃,则依据redo log buffer、redo log file进行重做,否则是数据页正常刷盘流程。 |
Wal机制
redo log刷盘先于数据页中数据修改,即redo_log_on_disk_lsn高于data_in_buffer_lsn。当事务commit提交时,innodb先将redo log buffer 顺序写入到redo log file进行持久化,事务的commit操作完成时才算整个过程完成。在持久化一个数据页之前,先将内存中相应的redo日志页持久化。
Redo log不能完全保证数据不丢失,需要将innodb_flush_log_at_trx_commit设置为2,及每次写到系统缓存,每隔1s刷到磁盘。
Undo log
undo日志用于保障未提交事务不会对数据库的ACID特性产生影响,即一致性。
undo段分为:
insert undo log
update undo log对于insert操作,undo日志记录新数据的PK(ROW_ID),回滚时直接删除;
对于delete/update操作,undo日志记录旧数据row,回滚时直接恢复;
因为对其他事务的可见性不同,这两种log分别存放在不同的buffer里。
insert undo log是指在insert 操作中产生的undo log,因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log可以在事务提交后直接删除,不需要进行purge操作。
而update undo log记录的是对delete 和update操作产生的undo log,该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。
redo & undo关系
前滚:当实例崩溃时,可以使用redo从以前正常的点前滚到崩溃点。(前滚从一致性检查点,“即当时检查过所有的SCN是全部一致的时间点”,一直往前滚到崩溃的时间点)。当数据库回到一致性检查点时,相当于之后什么都没有发生过,数据全被清空了。数据库只好根据redo模拟还原之前的数据变更操作,使用redo里的信息重做(use redo log to redo),构造undo块,表块,索引块等。然后再根据undo log恢复磁盘数据。
回滚:构造的表数据块中,有已修改的脏数据但未提交,就需要利用前滚中构造的undo数据块里的信息来undo撤销还原,覆盖回滚rollback(保持一致性,每种块里的scn号都一样,那么数据库就可以打开了)。
LSN
Redo log、磁盘页都有LSN参数,用于实现innodb的事务性中的原子性与持久性。
应用层的一个事务,可能对应修改多个物理页。比如下面这个事务:
start transaction
update 表1某行记录
delete 表1某行记录
insert 表2某行记录
Commit应用层面,事务是三条SQL语句,涉及两张表;而物理层面,可能是修改了四个或多个Page。所以,一个逻辑事务对应的物理日志不是连续的,但一个物理事务对应的日志一定是连续的,即使横跨多个redo log Block。
因为所有应用事务共享redo log buffer,因此一个应用事务对应的物理事务在redo log的block里可能是不连续的,中间穿插其他事务的日志,两个逻辑事务的Redo Log在磁盘上排列如下所示:
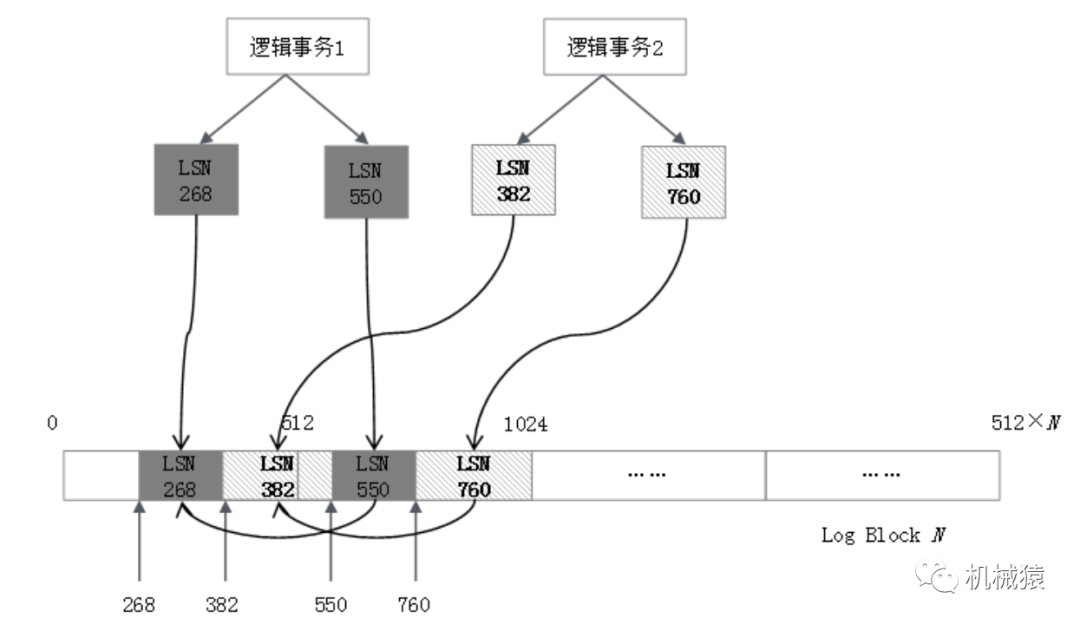
物理事务:innodb引擎保证物理页面写入操作完整性及持久性的机制。
同一个事务的多条LSN日志通过链表串联,最终形成的redo block块如下表所示。TxID是InnoDB为每个事务分配的隐式字段,是一个单调自增id。

因为不同事务的redo log日志是交叉存在的,因此redo日志刷盘时不管buffer里面的事务有没有提交,都会刷入磁盘。那么数据库崩溃恢复后,redo log会全部重放,那么如何将未提交的事务找到并使用undo log回滚呢?这个就是ARIES恢复算法。
ARIES恢复算法
假定有T0~T5共6个事务,每个事务所在的线段区间表示在Redo Log中的起始和终止位置。数据库宕机时,T0、T1、T2已经完成,T3、T4、T5还在进行中,所以回滚的时候,要回滚T3、T4、T5三个事务。
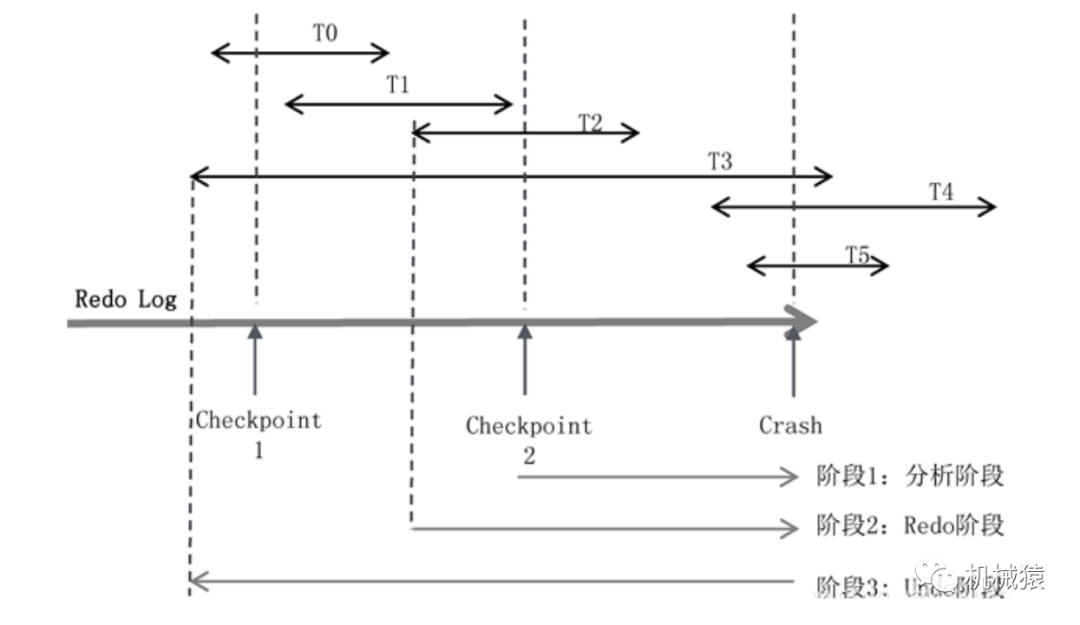
崩溃恢复流程如下:
(1)分析阶段
分析阶段要解决两个核心问题:
第一,确定哪些数据页是脏页,为阶段2的redo做准备。发生宕机时,虽然T0、T1、T2事务已经提交了,但只能保证对应的Redo Log已经刷盘,其对应的数据页不一定从buffer刷到磁盘上了。所以需要找到从上一次checkpoint到宕机这段时间内未刷盘的数据脏页。
第二,确定哪些事务未提交,为阶段3的undo做准备。未提交事务的日志也写入了Redo Log。对应到此图,就是T3、T4、T5的部分日志也在Redo Log中。需要基于checkpoint判断出T3、T4、T5事务未提交,然后对其进行回滚。
Checkpoint机制
Checkpoint是每隔一段时间对内存中的数据进行刷盘,有如下两种方式:
Fuzzy checkpoint:进行部分脏页的刷新,有效循环利用Redo日志。
Sharp checkpoint:发生在关闭数据库时,将所有脏页刷回磁盘。因为内存缓存数据量比较大,实际使用中使用Fuzzy checkpoint机制。
Fuzzy checkpoint机制用到了两张表:活跃事务表和数据脏页表。
活跃事务表是当前所有未提交事务的集合,每个事务维护了一个关键变量lastLSN,是该事务产生的日志中最后一条日志的LSN。

脏页表是当前所有未刷到磁盘上的Page的集合(包括已提交的事务和未提交的事务),其中recoveryLSN是导致该Page为脏页的最早的LSN,也就是最后一次刷盘后最早开始的事务产生的日志的LSN。

Fuzzy Checkpoint机制会把这两个表的数据生成一个快照,形成一条checkponit日志,记入Redo Log中。
基于这两张表可以解决下面的问题:
问题(1):得到宕机时所有未提交的事务。
如上图,在最近的一次Checkpoint 2时候,未提交事务集合是{T2,T3},此时还没有T4、T5。从此处开始,遍历Redo Log到末尾。
在遍历的过程中,首先遇到了T2的结束标识,把T2从集合中移除,剩下{T3};
之后遇到了事务T4的开始标识,把T4加入集合,集合变为{T3,T4};
之后遇到了事务T5的开始标识,把T5加入集合,集合变为{T3,T4,T5}。
最终直到末尾,没有遇到{T3,T4,T5}的结束标识,所以未提交事务是{T3,T4,T5}。

事务的开始标识、结束标识以及Checkpoint在Redo Log中的位置如上图。其中的S表示Start transaction,事务开始的日志记录;C表示Commit,事务结束的日志记录。每隔一段时间,做一次Checkpoint,会插入一条Checkpoint日志。Checkpoint日志记录了Checkpoint时所对应的活跃事务的列表和脏页列表。
问题(2):得到宕机时所有未刷盘的脏页。
假设在Checkpoint2的时候,脏页的集合是{P1,P2}。从Checkpoint开始,一直遍历到Redo Log末尾,一旦遇到Redo Log操作的是新的磁盘页,就把它加入脏页集合,最终结果可能是{P1,P2,P3,P4}。因为redo log在磁盘页上的操作是幂等的,因此对已经刷了变更数据的磁盘页重复执行redo操作是没有影响的。
阶段2:进行Redo操作
假定得到的脏页集合是{P1,P2,P3,P4,P5}。取集合中所有脏页的recoveryLSN的最小值,得到firstLSN,也就是最后一次刷盘后最早活跃的事务id。从firstLSN遍历Redo Log到末尾,把每条Redo Log对应的数据页全部重刷一次磁盘。重放redo日志时,如果redo日志的LSN <= pageLSN,则不修改redo日志对应的数据页,丢弃该条日志。
阶段3:进行Undo操作
在阶段1,已经找出了所有的未提交事务{T3,T4,T5}。因为undo日志是数据链,所以可以沿着T3、T4、T5各自的日志链一直回溯,直到回溯到第一条日志。
基于redo log的持久性,在undo回滚时遇到宕机,我们可以在崩溃恢复后继续回滚。

![Leetcode 1687. 从仓库到码头运输箱子 [四种解法] 动态规划 从朴素出发详细剖析优化步骤](https://img-blog.csdnimg.cn/b9898ac88fb8438da1284d8913fb7e49.png)