离线元强化学习中基于对比学习的稳定表示
-
最近几年来深度强化学习在算法上有很多进展,已初步用在很多场景中。目前深度强化学习有两个重要的问题:数据利用问题,泛化能力。深度强化学习通常要与环境进行大量的交互,通常效率较低,采样不太安全。并且训练一个智能体只能完成单一任务,学到的策略并不能泛化到其他任务,也不能适应环境本身的变化。
-
对于采样效率低的问题,离线强化学习是一种通过事先采集好的数据中训练的方式。其中,离线策略的方法,怎样利用由其他策略采集的数据来评估和提升当前策略,为离线强化学习奠定了基础。近几年,batch RL(完全离线的强化学习)则是研究仅使用固定的一些数据集怎样学到最好的策略。现有的方法解决了离线训练测试当中分布偏移的问题,以及对Q函数值函数高估的问题。
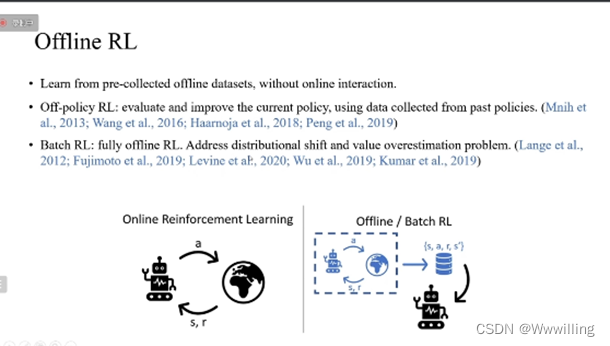
-
元强化学习是提升智能体在不同任务上泛化能力的一种方式,它通过在一个任务的分布上进行训练来学习怎样快速适应一个没有见过的新任务,元强化学习的研究主要有两类方法,第一类:基于上下文的方法。将任务的变化看作环境中隐藏的变量,对历史的信息进行编码,将历史的编码和当前的环境状态放在一起作为当前观测,从而把元强化学习问题转换为部分观测的强化学习问题。第二类基于梯度的方法,在所有任务上学习一个共享的策略参数的初始化,这个初始化使得它在每个新任务上只要做几步的梯度更新,就能够得到一个适应这个新任务的策略。
-

-
我们研究的叫做离线元强化学习,是结合离线强化学习和元强化学习的一类问题。首先,它能够利用在许多任务上,Behavior policies行为策略(其他的策略)采集数据,仅通过这些离线数据学习策略,它能够泛化到一些新的测试任务上。定义不同任务为:不同任务之间的奖励函数以及环境的状态转移函数有区别。
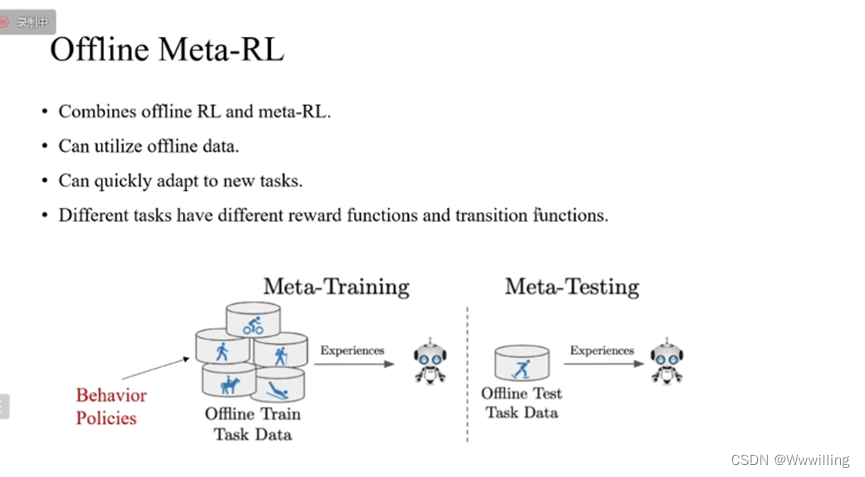
那么在训练的时候,对于每一个任务,都可以从离线的数据集中抽取一些样本来作为这个任务的上下文,然后智能体可以基于上下文在离线的数据集上进行学习。
在测试的过程中,首先,我们可以有一个探索的策略,然后从测试的新环境中采集少量的数据作为新环境的上下文,智能体要基于新环境的上下文快速得到一个适应新任务的策略去解决这个新任务。 -
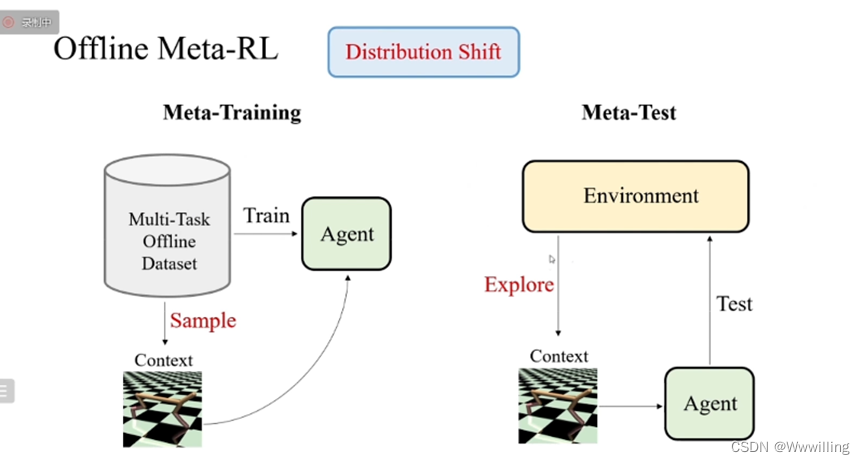
我们发现在训练和测试的过程中,上下文的分布是存在差异的,因为训练的时候上下文是从离线的数据集中采样得到的,分布是由任务本身和采集数据的行为策略来决定的。而在测试中,上下文的分布是由任务和探索策略来决定的。
-
当行为策略与探索策略不同时,任务上下文的分布从训练到测试就存在偏差,这种偏差就会使得训练的智能体在测试的时候无法准确的识别和适应新任务。
-
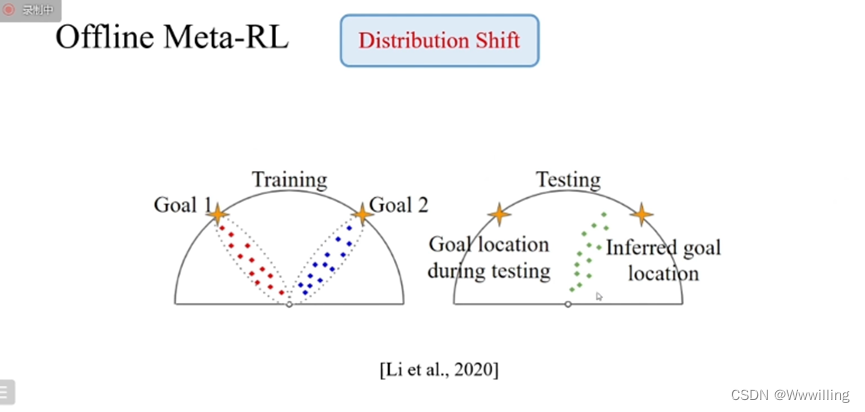
这篇2020的文章给出了一个比较直观的图片例子,每一个任务里面智能体都要从出发的起点走到一个目标的位置,不同的任务目标位置是不一样的,在左边这个训练过程中,由于每个任务对应的行为策略都不一样,最终导致了智能体把行为策略走过的路径与最终信息关联起来,并且忽视了真正和任务相关的奖励函数等的信息。学到这样的策略在测试的时候,如果探索策略走过的是这个绿色的路径,虽然这个任务真实的位置是左边的位置,但是智能体由于训练和测试的分布偏差导致了推断的任务位置在如图右边,就导致无法正确完成和测试这个测试的任务。
-
对于离线元强化学习问题近几年有些研究。
-
其中有些方法将基于上下文的元强化学习方法扩展到离线元强化学习,它们很难解决测试时上下文偏移这样的问题

-
有另一些基于上下文的方法,它们试图解决这样的分布偏移的问题,但他们有的方法需要访问所有任务上的奖励函数的信息作为监督,还有些方法需要在真实环境中做一些额外的探索来解决探索策略之间的gap.

-
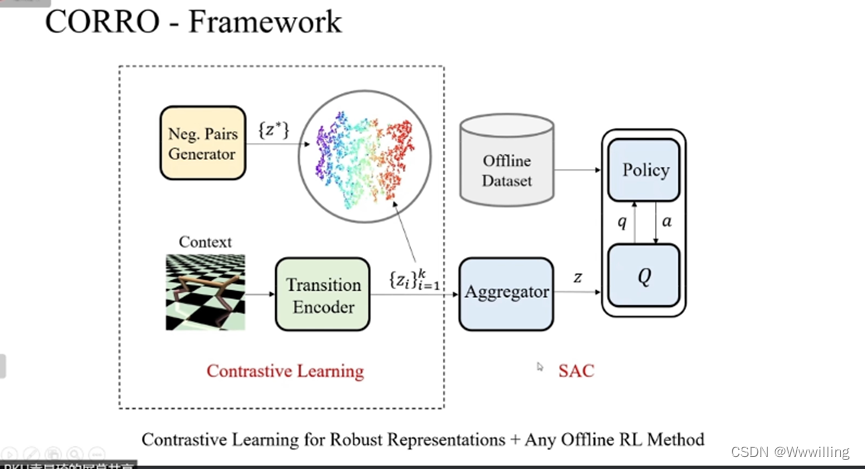
我们提出CORRO来解决分布偏移的问题,首先这个框架是一个基于上下文的框架,所谓的上下文即从环境中采集的一条轨迹,轨迹中包含了从1到k时间步的环境的状态转移的信息。然后有一个转移样本的编码器,它把上下文中每一个转移的样本编码成一个向量 Z t Z_t Zt。然后有一个聚合模块将上下文中所有的编码聚合为一个向量Z作为从上下文中抽取的任务的表示,智能体中的策略和Q函数这些模块会将提取的任务表示Z和环境当前的状态共同作为输入来进行决策。这些模块都可以在离线数据集上通过离线强化学习算法进行训练。为了使任务编码器对上下文之间的任务编码更加稳定,我们提出用对比学习的方法来训练这个转移编码器,还提出了一些方法来解决对比学习中生成负样本的问题。这个是我们最终整个模型的框架,转移编码器是通过对比学习进行预训练来得到一个稳定的编码表示,之后的聚合模块和训练模块合在一起可以通过任意的离线强化学习算法进行训练,实验中我们统一使用SAC算法。
-
对于这个转移编码器,我们通过最大化互信息来定义编码器的优化目标。转移样本的编码和任务之间的互信息定义为如下公式:
-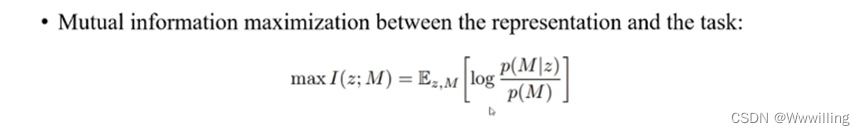
-
为什么要用最大化互信息这样一个目标呢?因为这个目标要求了学习出的表示z能够尽可能多的包这个任务M相关的信息,最小化和任务M无关的信息,这个无关信息就包括行为策略和采集上下文的探索策略对样本造成的影响。但问题是直接算这个互信息的值它是不可解的目标。

-
我们通过推导一个下界来给出具体的优化方法,在推导的表达上做了一些数学上的定义。首先把转移编码器定义成一个概率编码器,对于输入一个转移记为x,基于x得到一个任务表示的条件概率分布,记h(x,z)这个函数表示基于z基于x的条件概率分布与z的先验概率分布的比值。最终推导出的互信息的目标的下界是如下公式。左边是任务表示和任务之间的互信息减去一个常数,右边是推出的下界。下界中log里面的分子项是h(x,z),其中x表示的是我们在服从一个任务分布的任务集合中取第一个任务,然后在第一个任务采集的离线数据集上采样的样本。在分母中,有许多 x ∗ x^* x∗, x ∗ x^* x∗表示在其他的某一个任务 M ∗ M^* M∗上,所计算出的状态转移的样本。其中 x ∗ x^* x∗和分子的 x x x是共享同样的上一步的状态和动作对的。

-
在对比学习的框架下,我们用一个score function S S S来估算前面提到的这个概率的比值 h h h。并且我们通过采样的方法来从任务的方法上采样所有的任务,以及在数据中采样本,得到的这样的基于对比学习的优化目标,
-
-
在最终这个可解的目标当中,S score function我们用的是余弦相似度,分子项z和z’表示从同一个任务Mi中采样的两个样本得到的两个样本的编码。分母项当中的z表示其他的任务M上采样的样本,这个样本和前面的z一样共享同样的上一步状态动作对。对这个最终的目标做一个直观的理解:为了去最大化对比学习的目标函数,转移编码器必须对同一个任务的两个样本提取更加接近的特征,对来自不同任务但是上一步具有同样状态动作对的样本,要从它们中抽取尽量多样的特征来反映出任务的不同。这样的话由于z 和z* 和z’,它们拥有同样的上一步状态动作对,那么编码器为了区分不同任务的样本,并且把同样任务靠近,它就必须捕获这个样本中与任务最相关的奖励和状态转移的差异。
-

-
有了这样的优化目标后,还存在一个问题即怎样生成负样本z*?因为计算z时需要在其他任务M上计算上一步状态动作下的转移结果。因为我们任务是离线的,在离线下所有任务的奖励函数和状态转移函数都是未知的。

-
设计了两种方法来生成负样本,让生成的负样本的分布尽可能接近优化目标当中从其他任务中采样得到的真实的目标分布。第一个方法是生成模型的方法。我们用在所有训练数据集上取并集,然后在所有数据上学习数据的分布,用这个数据的分布来近似目标的负样本的分布。然后我们在所有的数据上训练了一个CVAE,用它来作为生成负样本近似分布的模型。

-
采用生成模型的方法的好处是当我们的不同任务上的状态动作对的分布比较接近时,我们学习的数据分布其实是跟优化目标中负样本分布很接近的。它在不同任务上状态动作对分布差异大或者甚至没有交集的时候,生成模型就会直接退化成在每一个任务上确定性的预测的模型,在这种情况下,是不能生成足够多样的样本,会使得对比学习无法优化。

-
然后为了解决后面这种比较极端的问题,我们提出了第二种叫做奖励随机化的方法。这种方法只能在不同任务只是区别于有不同奖励函数这样的假设下的。对于这种情况直接对样本中的奖励函数加上一个噪声的扰动,然后用扰动之后的奖励来模拟从其他某些任务中采出的样本,尽管这种奖励随机化的方法并不能近似目标的负样本的分布,但好处能够生成更多多样化的样本来进行更好地对比表示学习。实验证明可以work.

-
最后是对于整个算法的实现,转移编码器是个多层的MLP,共享参数。聚合模块因为和策略模块一起训练,采用轻量化少参数的设计,来更加高效聚集不同时间步样本表示的关键信息,采用的是一种attention的做法,对所有探索的表示来学习一组权重,最后做一个带权的求和得到最终聚合的任务表示。在训练中,转移编码器是预训练的,聚合模块策略Q函数通过SAC离线训练。

-
最后在测试过程中,有一个任意的探索的策略,从新的任务中采样一条轨迹作为上下文,然后任务编码器将新任务的上下文进行编码,最后得到适应后的策略。

- 我们在实验的部分主要验证在不同分布上学到的策略,对测试任务的泛化能力,第二是对测试任务的稳定性,对上下文分布偏移的适应能力,最后研究了怎样生成负样本的方法的问题。

- 基线:















![html+css鼠标悬停发光按钮![HTML鼠标悬停的代码]使用HTML + CSS实现鼠标悬停的一些奇幻效果!](https://img-blog.csdnimg.cn/fae3dc6f6d724013a0fc0e5b7bc82939.png)