推断的准备工作
接下来我将从官方代码开始,一步一步展示如何进行图片、视频识别
首先从GitHub下载官方代码(也可以从下面链接获取):
链接:https://pan.baidu.com/s/16wzV899D90TY2Xwhx4TwhA
提取码:vzvj
将环境切换到之前配置完成的yolo环境
(你的环境名可能和我不一样)
实现图片目标检测
可以看到 '--weights' 参数(参数解读详见4.a)的默认值为'yolov5s.pt'这表明运行代码时使用yolov5s的权重参数进行推断。
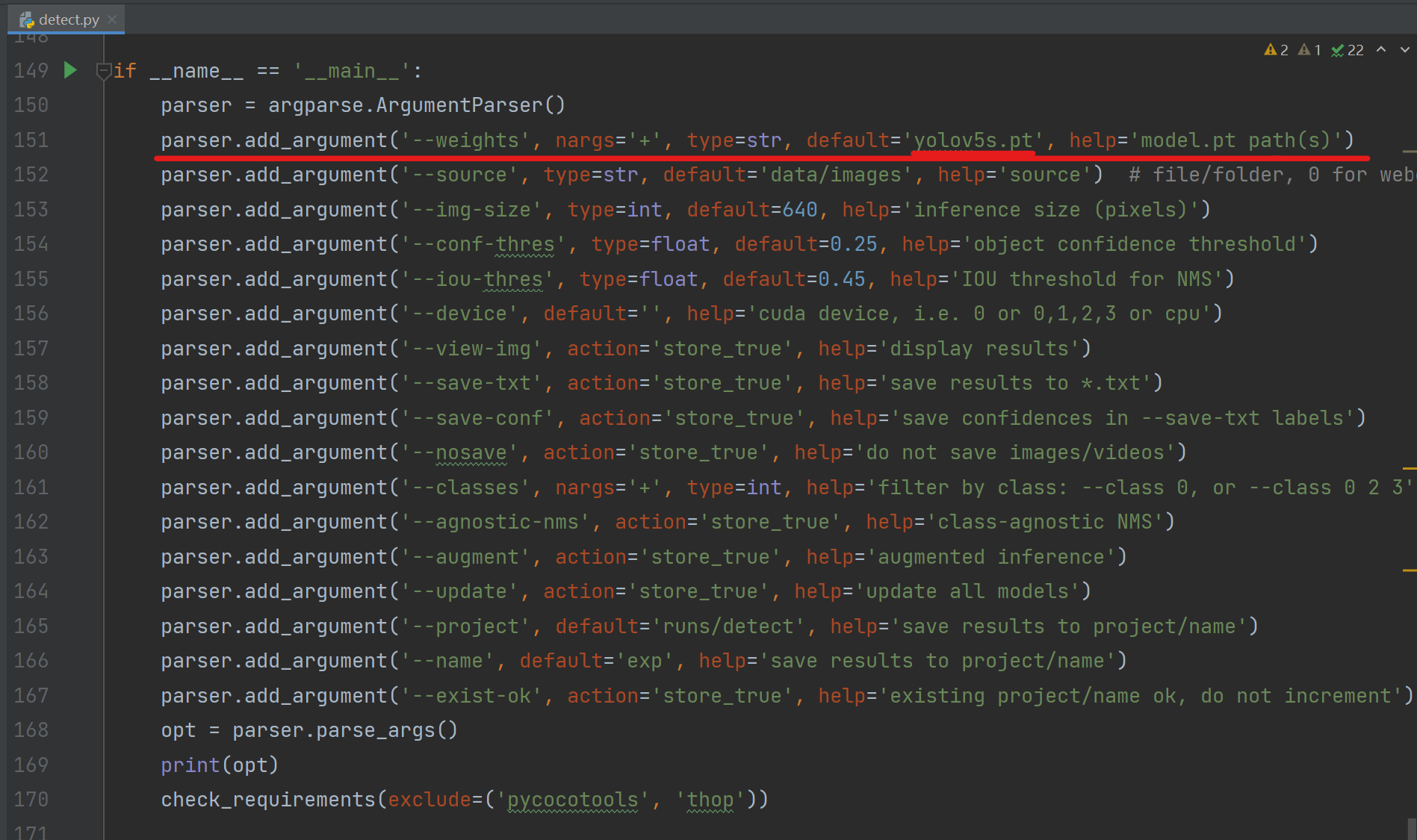
这里有两种运行办法,一种是直接运行,他会自动到外网上下载模型,如果网络不好的话可能会报错;另一种是先下载把模型文件放到detect.py的同级目录下,运行即可。
yolov5s.pt模型文件链接:
链接:https://pan.baidu.com/s/1-1F_LcVKZRbbytotm9GKjw
提取码:tbby
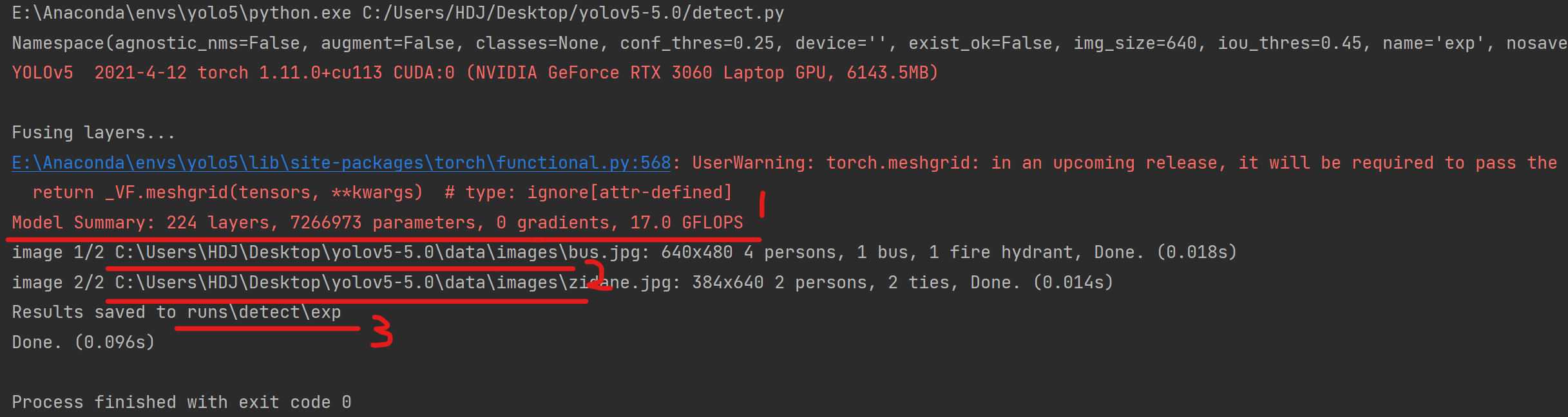
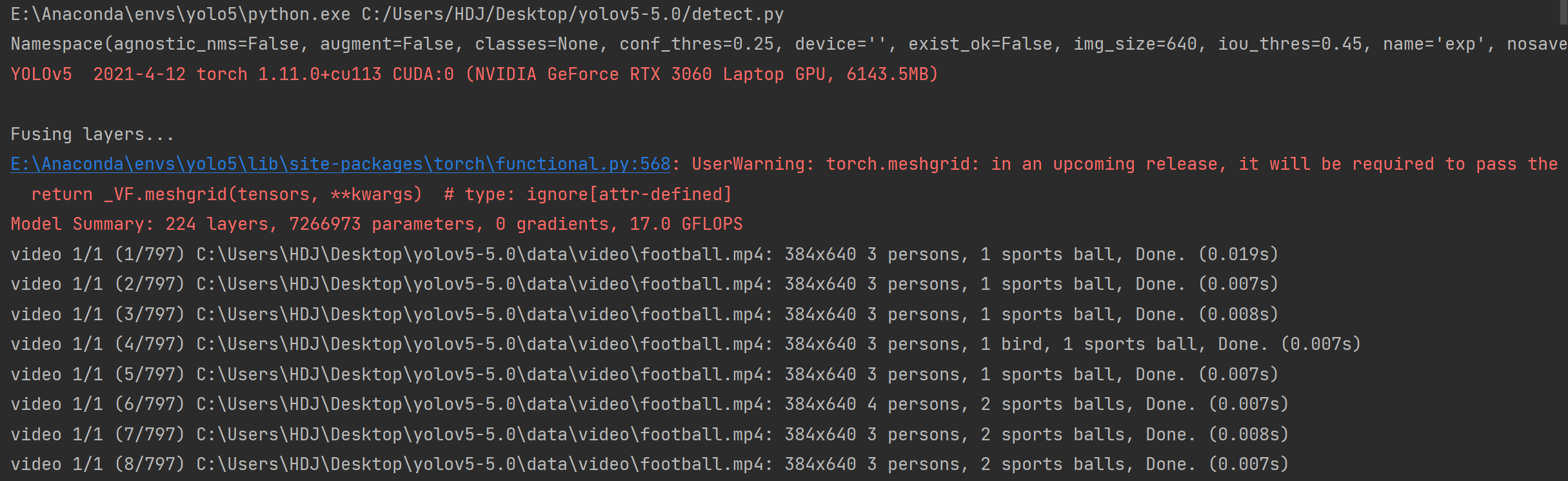
运行成功!
1是对模型的概要,可以看到模型包括224层,7266973个参数;
2路径是'--source'参数(参数解读详见4.b)的默认值,在该路径下存放待识别图片(可以添加自己的图片,常见的图片格式均可进行识别)
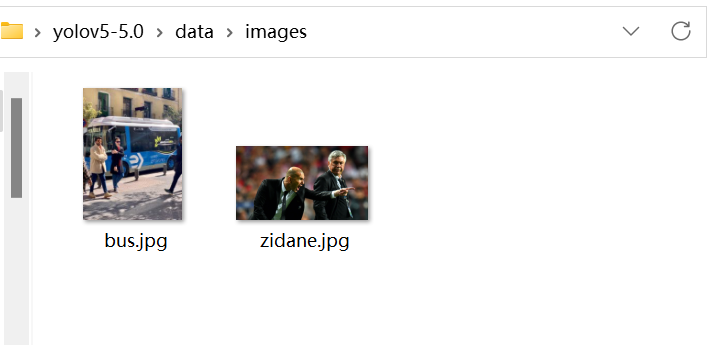
3是推断结果存放路径,在代码运行后可以看到结果
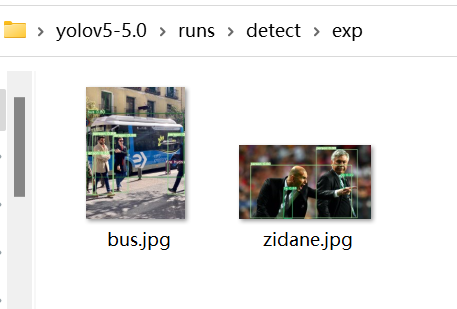
效果如下:


恭喜你,成功啦!(≧∇≦)/
这是一个值得庆祝的时刻,就像是学习C、python时的“hello world!”,学习单片机时的流水灯,这表明我们已经进入yolo目标识别的大门。我认为,这样阶段性的正反馈,是求学路上最迷人风景之一
(๑•̀ㅂ•́)و✧
实现视频目标检测
完成图片目标检测后,视频检测基本不会有什么问题。在工程的data文件夹下新建video文件夹,在里面存放要识别的视频(也可以放在其他位置,注意修改路径即可)
在代码中更改'--source'参数的默认值运行即可。
parser.add_argument('--source', type=str, default='data/video', help='source') # file/folder, 0 for webcam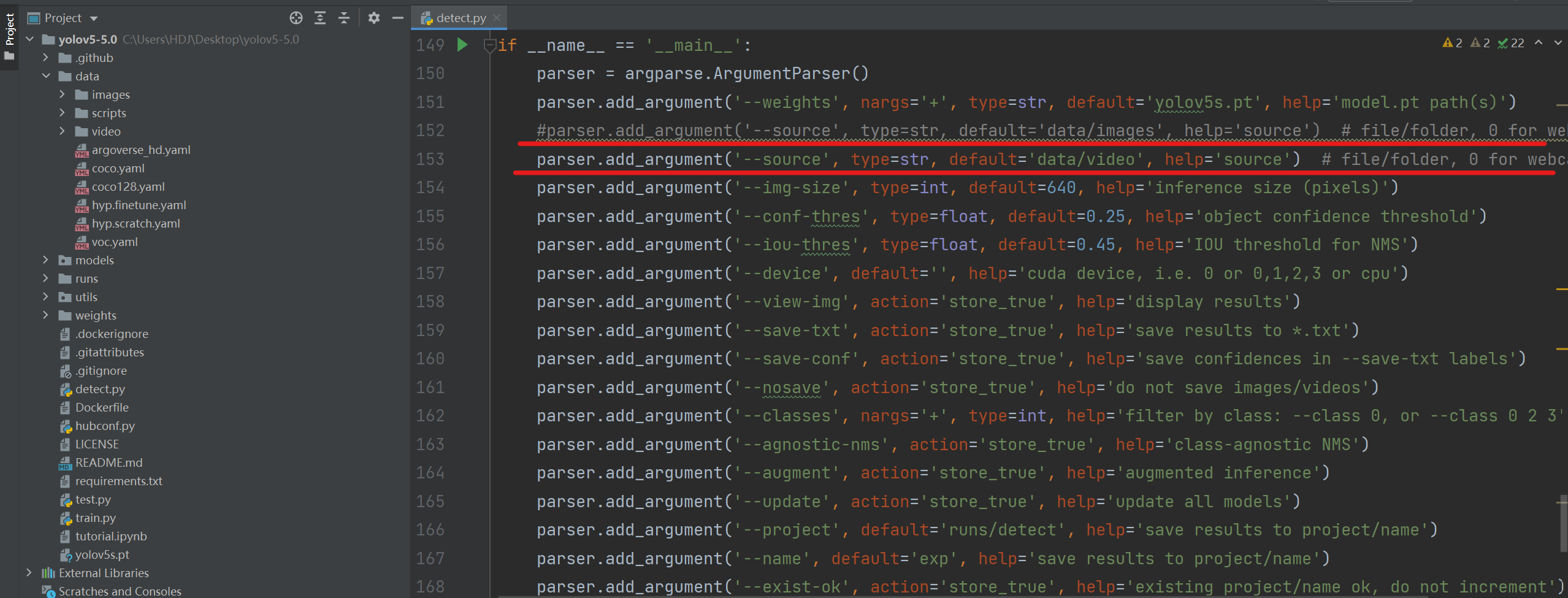
运行成功!
...
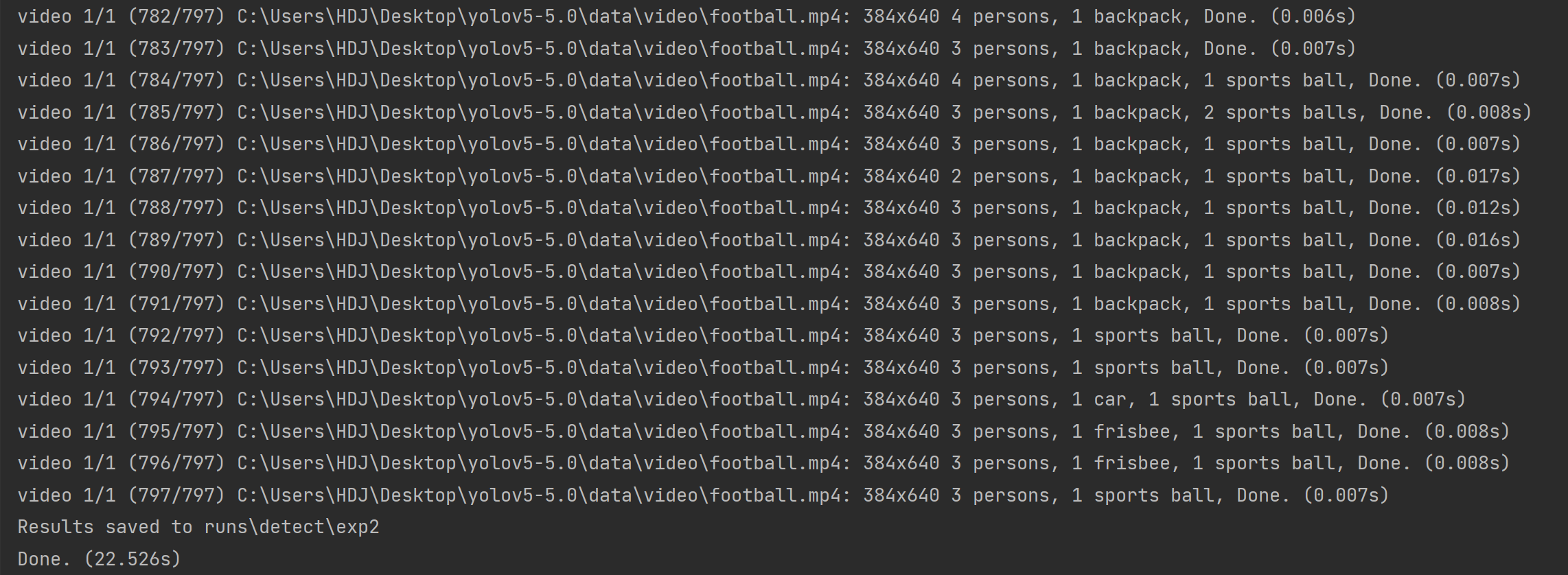
视频被切成797张图片,在全部识别后重新合成一个视频,并存在runs\detect\exp2目录下
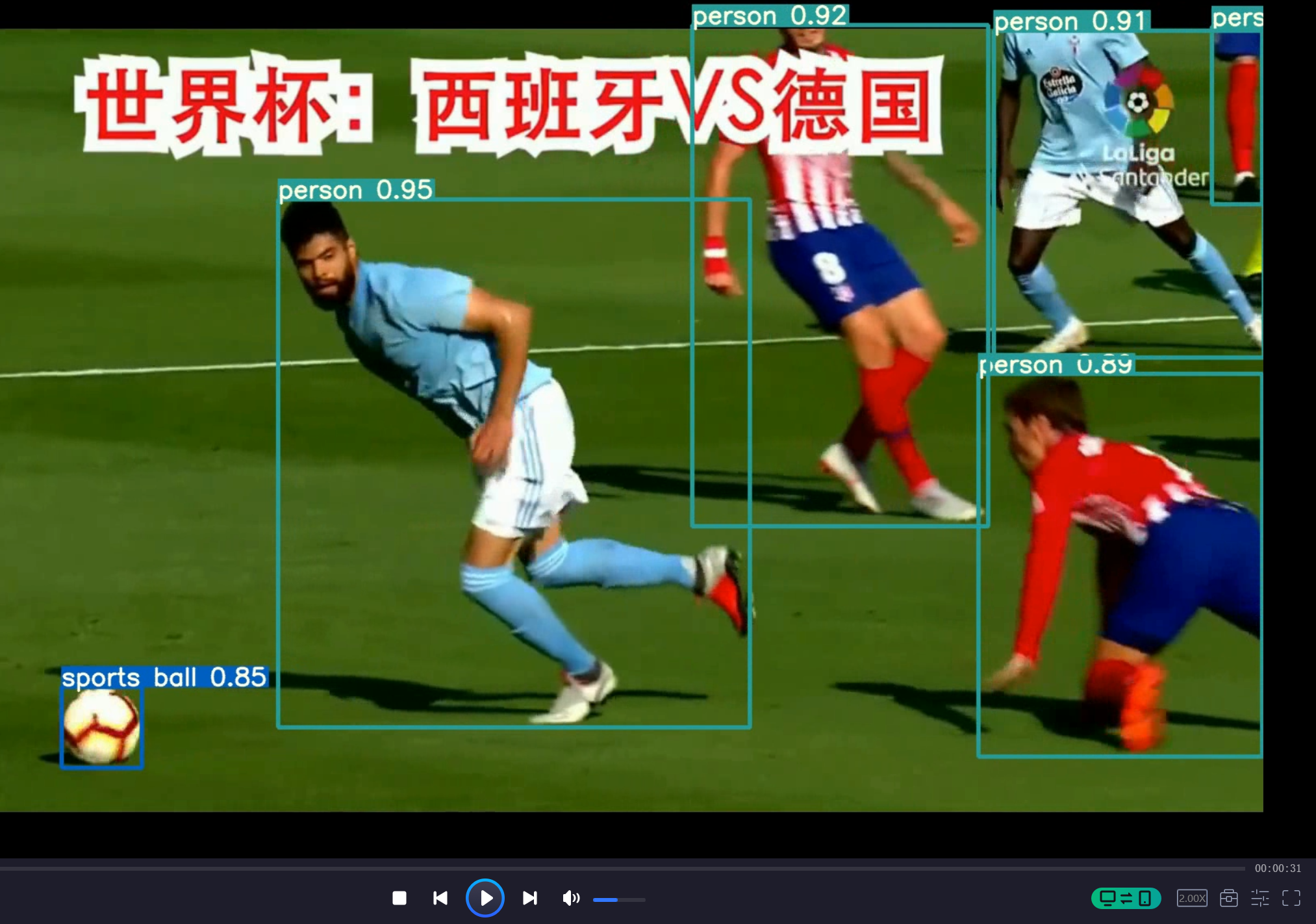
可以看到效果还是非常好的。
对detect.py中常用参数的解读
'--weights'

这个就是指定网络权重的路径,默认是官方的yolov5s.pt(官方还提供了很多其他的权重模型,例如yolov5m.pt,yolov5n.pt...如果想详细了解,可以看GitHub官方工程Pretrained Checkpoints那一栏
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite)
如果想用其他的官方模型,由于运行代码自动下载比较慢,所以建议先从官网下载好模型放到detect.py同级目录下,然后将'--weights'默认值改成对应模型的名称,直接运行即可。
注意,这里有个细节,如果从非官网途径下载模型,一定要注意.pt文件的名称,有些文件名末尾会多一个空格,记得去掉他,否则因为代码中默认值名称和模型文件名称不匹配(差一个空格),还是会自动去外网下模型。

表面看上去没问题

实际多了一个空格

要把这个空格去掉
如果要使用自己训练的模型,更改默认值为模型路径即可(之后的文章会讲)。
'--source'参数

这个参数的默认值是网络输入的路径,默认指定的是文件夹,也可以指定具体的文件,如直接锁定到某个图片 'data/images/bus.jpg' 那么运行时只会识别这一张图片,images文件夹下的其他图片/视频不会参与识别。
'--conf-thres'参数

这个参数我通常理解为,目标可能性阈值,低于默认值(如上图是0.25)的目标不会被框出来。我通常将其作为避免误识别的一种手段,因为只要数据集采集合理,经过训练,假目标的可能性通常低于真目标,只要将阈值设在两者之间,就能滤去假目标的识别框,这比 重新采集数据集、调网络参数、重新训练 要容易的多。
'--conf-thres'默认值为0.25

'--conf-thres'默认值为0.65
求学路上,你我共勉(๑•̀ㅂ•́)و✧