目录
1. list 的基本框架
1.1 list 的结点
1.2 list 构造函数
1.3 push_back
2. list 迭代器的实现
2.1 迭代器的构造
2.2 begin() 和 end()
2.3 重载 != 和 * 和 ++
2.4 遍历测试:
2.6 operator->
2.7 operator--
2.8 const 迭代器
3. list 的增删查改
3.1 insert和头插尾插
3.2 erase和头删尾删
4. list 的深浅拷贝
4.1 clear 和析构
4.2 迭代器区间构造和交换
4.3 拷贝构造和赋值重载
5. list相关选择题
答案:
6. 完整代码
list.h
Test.c
本篇完。
上一篇说到,list 其实就是带哨兵位循环双向链表而已,这种链表虽然结构复杂,
但是实现起来反而是最简单的,我们在数据结构与算法专栏中有过详细的讲解:
数据结构与算法⑦(第二章收尾)带头双向循环链表的实现_GR C的博客-CSDN博客
当时我们是用C语言实现,这里对 list 的实现其实也是大同小异的。
当然,我们重点还是倾向于去理解它的底层实现原理,
所以我们将对其实现方式进行进一步地简化,并且按照我们自己习惯的命名风格去走。
我们之前已经模拟实现过 string 和 vector 了,这是本专栏 STL 的第三个模拟实现,
因此在讲解的时,出现重复的知识点我们就一笔带过。我们将重点去讲解迭代器的实现!
本章我们要对迭代器有一个新的认知,迭代器不一定就是一个原生指针,
也有可能是一个自定义类型。
本章我们将通过自定义类型的运算符重载去控制我们的迭代器的 "行为"。
1. list 的基本框架
我们还是参考《STL源码剖析》,既然是要实现链表,我们首先要做的应该是建构结点。
此外,为了和真正的 list 进行区分,我们这里仍然在自己的命名空间内实现。
1.1 list 的结点
C语言写的:

C++的代码:
template<class T>
struct list_node
{
T _data;
list_node* _prev;
list_node* _next;
};C++中对象里的成员如果全是共有的还是比较习惯用 struct 的
我们知道,结构体 struct 在 C++ 中升级成了类,因此它也有调用构造函数的权利。
也就是说,在创建结构体对象的时会调用构造函数。
既然如此,结点的初始化工作,可以考虑写一个构造函数去初始化:
template<class T>
struct list_node
{
T _data;
list_node* _prev;
list_node* _next;
list_node(const T& x = T())
:_data(x)
,_prev(nullptr)
,_next(nullptr)
{}
};设计成全缺省,给一个匿名对象 T() 。如此一来,如果没有指定初识值,
它就会按模板类型去给对应的初始值了。
1.2 list 构造函数
设计好结点后,我们现在可以开始实现 list 类了。
考虑到我们刚才实现的 "结点" ListNode<T> 类型比较长,为了美观我们将其 typedef 成 Node
因为是带头(哨兵位)双向循环链表,我们先要带个头。
我们先要把头结点 _pHead 给设计出来,而 _prev 和 _next 是默认指向头结点的。
到这里 list.h 就是这样:
#pragma once
#include<iostream>
#include<assert.h>
using namespace std;
namespace rtx
{
template<class T>
struct list_node // 定义结点
{
T _data;
list_node* _prev;
list_node* _next;
list_node(const T& x = T())
:_data(x)
,_prev(nullptr)
,_next(nullptr)
{}
};
template<class T>
class list // 定义list类
{
typedef list_node<T> Node;
public:
list()
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
}
private:
Node* _head; // 哨兵位头结点
};
}1.3 push_back
我们先去实现一下最经典的 push_back 尾插,好让我们的 list 先跑起来。
尾插思路和以前写过的思路一样,后面很多接口也是,不懂的回去看啊,别逼我求你,
数据结构与算法⑦(第二章收尾)带头双向循环链表的实现_GR C的博客-CSDN博客
直接放代码了:
void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* NewNode = new Node(x);
// 思路图:head tail NewNode
tail->_next = NewNode;
NewNode->_prev = tail;
_head->_prev = NewNode;
NewNode->_next = _head;
}我们想要打印的话就只能自己实现迭代器了:
2. list 迭代器的实现
list 的重点是迭代器,因为这里的迭代器的实现和我们之前讲的实现方式都不同。
我们之前讲的 string 和 vector 的迭代器都是一个原生指针,实现起来是非常简单的。
但是 list 是一个链表,你的迭代器还能这样去实现吗?在空间上不是连续的,如何往后走?
而这些所谓的 "链接" 其实都是我们想象出来的,实际上根本就不存在。
而这些链接的含义只是 "我存的就是你的地址" ,所以我可以找到你的位置。
而我要到下一个位置的重点是 —— 解引用能取到数据,++ 移动到下一位。
而自带的 解引用* 和 ++ 的功能,是没法在链表中操作的。
但是,得益于C++有运算符重载的功能,我们可以用一个类型去对结点的指针进行封装,
然后重载运算符 operator++ 和 operator* ,
是不是就可以控制其解引用并 ++ 到下一个位置了?
所以,我们首先要做的是对这两个运算符进行重载:
2.1 迭代器的构造
代码:只需要用一个结点的指针
template<class T>
struct __list_iterator // 定义迭代器
{
typedef list_node<T> Node;
typedef __list_iterator<T> iterator; // STL规定的命名,且公有
Node* _node;
iterator(Node* node)
:_node(node)
{}
};这里命名是参考源码的,__list_iterator 前面是两个下划线。
我们想要打印的话应该是这样的:
list<int>::iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
++it;
}
cout << endl;所以我们来实现这几个操作
2.2 begin() 和 end()
代码:在 list 类中设计 begin 和 end
template<class T>
class list // 定义list类
{
typedef list_node<T> Node;
public:
typedef __list_iterator<T> iterator; // STL规定的命名,且公有
iterator begin()// begin是实际数据的第一个,_head 是哨兵位头结点
{
return iterator(_head->_next);
}
iterator end()// end是实际数据的下一个
{
return iterator(_head);
}
list()
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
}
void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* NewNode = new Node(x);
// 思路图:head tail NewNode
tail->_next = NewNode;
NewNode->_prev = tail;
_head->_prev = NewNode;
NewNode->_next = _head;
}
private:
Node* _head; // 哨兵位头结点
};2.3 重载 != 和 * 和 ++
operator!=
如何判断是否相等呢?
如果两个迭代器结点的指针指向的是同一个结点,那就说明是相等的迭代器:
bool operator!=(const iterator& it)
{
return _node != it._node;
}operator*
解引用就是取结点 _node 里的数据,并且 operator* 和指针一样,不仅仅能读数据,还能写数据。
为了使 operator* 能支持修改的操作,我们这里用引用返回 & (返回 _node 中 _data 的别名)
T& operator*()
{
return _node->_data; // 返回结点的数据
}operator++
加加分为前置和后置,我们这里先实现以下前置++:
iterator& operator++()
{
_node = _node->_next;
return *this; // 返回加加后的值
}因为前置是直接改变本体,我们直接 return *this 即可。
因为除了作用域还在,所以可以用引用返回, __list_iterator<T>&
对应的,后置++ 我们可以拷贝构造出一个 tmp 存储原来的值,这样虽然改变本体了,
但是返回的还是之前的值,这就实现了后置++。此外,因为前置++后置++都是 operator++,
区分方式是后置++用占位符 (int) 占位,这些知识点我们在之前讲解日期类的时候都说过。
后置++的实现:(注意后置++不能用引用返回)
iterator operator++(int)
{
__list_iterator<T> tmp(*this); // 拷贝构造一个tmp存储原来的值
_node = _node->next;
return tmp; // 返回加加前的值
}2.4 遍历测试:
至此,我们可以遍历打印我们的代码了,而且范围for也能用了:
list.h
#pragma once
#include<iostream>
#include<assert.h>
using namespace std;
namespace rtx
{
template<class T>
struct list_node // 定义结点
{
T _data;
list_node* _prev;
list_node* _next;
list_node(const T& x = T())
:_data(x)
,_prev(nullptr)
,_next(nullptr)
{}
};
template<class T>
struct __list_iterator // 定义迭代器
{
typedef list_node<T> Node;
typedef __list_iterator<T> iterator; // STL规定的命名,且公有
Node* _node;
__list_iterator(Node* node)
:_node(node)
{}
bool operator!=(const iterator& it)
{
return _node != it._node;
}
T& operator*()
{
return _node->_data; // 返回结点的数据
}
iterator& operator++()
{
_node = _node->_next;
return *this; // 返回加加后的值
}
iterator& operator++(int)
{
iterator tmp(*this); // 拷贝构造一个tmp存储原来的值
_node = _node->next;
return tmp; // 返回加加后的值
}
};
template<class T>
class list // 定义list类
{
typedef list_node<T> Node;
public:
typedef __list_iterator<T> iterator; // STL规定的命名,且公有
iterator begin()// begin是实际数据的第一个,_head 是哨兵位头结点
{
return iterator(_head->_next);
}
iterator end()// end是实际数据的下一个
{
return iterator(_head);
}
list()
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
}
void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* NewNode = new Node(x);
// 思路图:head tail NewNode
tail->_next = NewNode;
NewNode->_prev = tail;
_head->_prev = NewNode;
NewNode->_next = _head;
}
private:
Node* _head; // 哨兵位头结点
};
}Test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "list.h"
namespace rtx
{
void Test_push_back()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (const auto& e : lt)
{
cout << e << " ";
}
cout << endl;
}
}
int main()
{
rtx::Test_push_back();
return 0;
}
2.6 operator->
迭代器是像指针一样的,所以要重载两个解引用。
为什么?指针如果指向的类型是原生的普通类型,要取对象是可以用解引用,
但是如果指向而是一个结构,并且我们又要取它的每一个成员变量,
比如我们想打印坐标:
void Test_arrow()
{
struct Pos
{
int _a1;
int _a2;
Pos(int a1 = 0, int a2 = 0)
:_a1(a1)
, _a2(a2)
{}
};
Pos aa;
Pos* p2 = &aa;
p2->_a1;
p2->_a2;
list<Pos> lt;
lt.push_back(Pos(10, 20));
lt.push_back(Pos(10, 21));
list<Pos>::iterator it = lt.begin();
while (it != lt.end())
{
cout << (*it)._a1 << "," << (*it)._a2 << endl;
//cout << it->_a1 << "," << it->_a2 << endl;
++it;
}
cout << endl;
}虽然能用解引用+点,但用箭头还是方便的,而且你模拟实现总不能不给别人用吧,
所以我们这里可以去实现一下箭头操作符 operator->,如果不是很熟练应该是不会的。
我们直接看一下源代码是怎么实现的,抄下来用用然后思考下:
T& operator*()
{
return _node->_data; // 返回结点的数据
}
T* operator->()
{
return &(operator*());
//即 return &(_node->_data);
} void Test_arrow()
{
struct Pos
{
int _a1;
int _a2;
Pos(int a1 = 0, int a2 = 0)
:_a1(a1)
, _a2(a2)
{}
};
Pos aa;
Pos* p2 = &aa;
p2->_a1;
p2->_a2;
list<Pos> lt;
lt.push_back(Pos(10, 20));
lt.push_back(Pos(10, 21));
list<Pos>::iterator it = lt.begin();
while (it != lt.end())
{
//cout << (*it)._a1 << "," << (*it)._a2 << endl;
cout << it->_a1 << "," << it->_a2 << endl;
//实际要写,it->->_a1,但是编译器优化了一个箭头
++it;
}
cout << endl;
}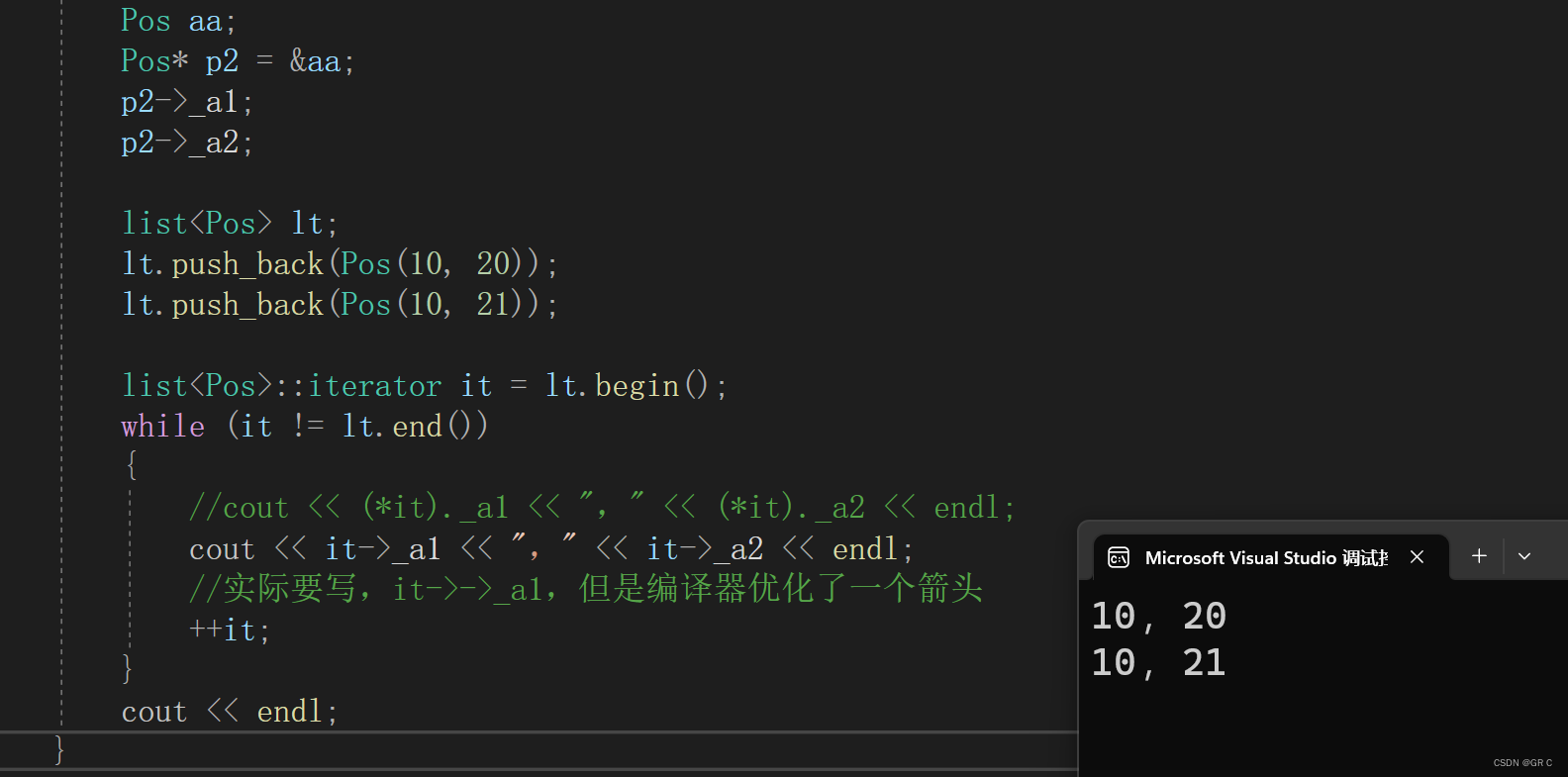
第一个指针是operator->,第二个指针是原生指针的箭头,但是编译器为了可读性:
所有类型重载 operator-> 时都会省略一个箭头。(后期讲智能指针还会再提)
2.7 operator--
前面实现了operator++,现在实现下operator--,把++的_next换成_prev就行:
iterator& operator--()
{
_node = _node->_prev;
return *this; // 返回减减后的值
}
iterator operator--(int)
{
iterator tmp(*this); // 拷贝构造一个tmp存储原来的值
_node = _node->prev;
return tmp; // 返回减减前的值
}2.8 const 迭代器
不用范围 for 的前提下 去用迭代器遍历打印似乎挺麻烦的,我们可以把它放到一个函数里,
这里考虑到减少拷贝,我们使用引用返回,我们之前也说过这种情况能用 const 就用 const。
所以这里就成 const_iterator 了,而我们刚才实现的是普通迭代器,会导致没法遍历:

普通迭代器访问普通对象,可读可写;const 迭代器访问 const 对象,可读但不可写。
所以我们这里自然是 需要实现 const 迭代器,即实现一个 "可读但不可写" 的迭代器。
(可以 ++ 可以解引用,但解引用的时候不能修改)
所以直接在 __list_iterator 里面重载一个 const 类型的 operator* 解决不了问题,
我们得重新实现一个 __const_list_iterator 出来。(更好的方法后面讲)
传统的方法是把 list_iterator 这个类CV一下,然后把名称改成 __const_list_iterator
这种实现方式可以是可以,但是这么实现好像有点搓啊!代码是很冗余的,
这个 const 迭代器和普通迭代器也就是类型名称和返回值不一样而已……
有没有办法可以优化一下呢?
通过加一个额外的模板参数去控制 operator 的返回值,你能想到吗?
我们来看看巨佬是怎么做的 —— 在定义 template 模板的时增加两个参数:
template<class T, class Ref, class Ptr>
struct __list_iterator // 定义迭代器
{
typedef list_node<T> Node;
typedef __list_iterator<T, Ref, Ptr> iterator;
// 在list类里面:
// typedef __list_iterator<T, T&, T*> iterator;
// typedef __list_iterator<T, const T&, const T*> const_iterator;再加上const begin和const end我们的遍历打印函数就能跑出来了:
list.h
#pragma once
#include<iostream>
#include<assert.h>
using namespace std;
namespace rtx
{
template<class T>
struct list_node // 定义结点
{
T _data;
list_node* _prev;
list_node* _next;
list_node(const T& x = T())
:_data(x)
,_prev(nullptr)
,_next(nullptr)
{}
};
template<class T, class Ref, class Ptr>
struct __list_iterator // 定义迭代器
{
typedef list_node<T> Node;
typedef __list_iterator<T, Ref, Ptr> iterator;
// 在list类里面:
// typedef __list_iterator<T, T&, T*> iterator;
// typedef __list_iterator<T, const T&, const T*> const_iterator;
Node* _node;
__list_iterator(Node* node)
:_node(node)
{}
bool operator!=(const iterator& it)
{
return _node != it._node;
}
//T& operator*()
Ref operator*()
{
return _node->_data; // 返回结点的数据
}
//T* operator->()
Ptr operator->()
{
return &(operator*());
//即 return &(_node->_data);
}
iterator& operator++()
{
_node = _node->_next;
return *this; // 返回加加后的值
}
iterator operator++(int)
{
iterator tmp(*this); // 拷贝构造一个tmp存储原来的值
_node = _node->_next;
return tmp; // 返回加加前的值
}
iterator& operator--()
{
_node = _node->_prev;
return *this; // 返回减减后的值
}
iterator operator--(int)
{
iterator tmp(*this); // 拷贝构造一个tmp存储原来的值
_node = _node->prev;
return tmp; // 返回减减前的值
}
};
template<class T>
class list // 定义list类
{
typedef list_node<T> Node;
public:
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
iterator begin()// begin是实际数据的第一个,_head 是哨兵位头结点
{
return iterator(_head->_next);
}
iterator end()// end是实际数据的下一个
{
return iterator(_head);
}
list()
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
}
void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* NewNode = new Node(x);
// 思路图:head tail NewNode
tail->_next = NewNode;
NewNode->_prev = tail;
_head->_prev = NewNode;
NewNode->_next = _head;
}
private:
Node* _head; // 哨兵位头结点
};
}Test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "list.h"
namespace rtx
{
void Test_arrow()
{
struct Pos
{
int _a1;
int _a2;
Pos(int a1 = 0, int a2 = 0)
:_a1(a1)
, _a2(a2)
{}
};
Pos aa;
Pos* p2 = &aa;
p2->_a1;
p2->_a2;
list<Pos> lt;
lt.push_back(Pos(10, 20));
lt.push_back(Pos(10, 21));
list<Pos>::iterator it = lt.begin();
while (it != lt.end())
{
//cout << (*it)._a1 << "," << (*it)._a2 << endl;
cout << it->_a1 << "," << it->_a2 << endl;
//实际要写,it->->_a1,但是编译器优化了一个箭头
++it;
}
cout << endl;
}
//cout << it->_a1 << ":" << it->_a2 << endl;
void print_list(const list<int>& lt)
{
list<int>::const_iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
void Test_push_back()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator it = lt.begin();
print_list(lt);
for (const auto& e : lt)
{
cout << e << " ";
}
cout << endl;
}
}
int main()
{
rtx::Test_push_back();
//rtx::Test_arrow();
return 0;
}
前面实现的迭代器都是原生指针。,写到 list 这才是涉及到了迭代器的精华。
3. list 的增删查改
在以前数据结构实现的时候说过,双向带头循环链表,
这个结构的优势就是只要实现insert和erase其它大多函数都能复用了
3.1 insert和头插尾插
在 pos 位置插入,我们通过 pos 去找到前驱 prev,之后创建新结点,再进行 "缝合" 操作,
这个我们也学过了,这里不在细说
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* NewNode = new Node(x);
prev->_next = NewNode;
NewNode->_prev = prev;
NewNode->_next = cur;
cur->_prev = NewNode;
return iterator(NewNode);
}
void push_back(const T& x)
{
//Node* tail = _head->_prev;
//Node* NewNode = new Node(x);
思路图:head tail NewNode
//tail->_next = NewNode;
//NewNode->_prev = tail;
//_head->_prev = NewNode;
//NewNode->_next = _head;
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}测试:
void Test_insert()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
//list<int>::iterator pos = find(lt.begin(), lt.end(), 2);// 涉及其它问题,先不这样写
//if (pos != lt.end())
//{
// lt.insert(pos, 20);
//}
lt.insert(++lt.begin(), 20);
lt.push_front(0);
lt.push_front(-1);
print_list(lt);
}
3.2 erase和头删尾删
只需注意别删掉哨兵位头结点:
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node; // 删cur
Node* prev = cur->_prev;
prev->_next = cur->_next; // cur前一个指向cur后一个
cur->_next->_prev = prev; // cur后一个指回cur前一个
delete cur;
return iterator(prev->_next); // 返回删除位置下一个
}
void pop_back()
{
erase(begin());
}
void pop_front()
{
erase(--end());
}测试:
void Test_erase()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.erase(++++lt.begin());//发现个好玩的,(删除3)
lt.pop_back();
lt.pop_front();
print_list(lt);
}4. list 的深浅拷贝
list 的同样涉及深浅拷贝问题,下面的拷贝构造是深拷贝还是浅拷贝?
void Test_copy()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int> lt2(lt);
print_list(lt);
print_list(lt2);
}
程序没有崩,是深拷贝吗?不是的,这里默认生成的拷贝构造还是浅拷贝,
有童鞋就会问了:难道是没有写数据?也不是,这里没崩仅仅是因为我们还没设计析构。
我们这里依然要自己去实现一个拷贝构造,去完成 "深拷贝" 。
我们下面先实现一下析构:
4.1 clear 和析构
写析构之前为了方便清空,我们先实现一下 clear ,然后复用一下,clear又可以复用erase,
实现了 clear 后,我们再去实现 list 的析构函数就很简单了。
我们只需要把哨兵位头结点 _head 给干掉就行了,并且记得要置成空指针。
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it); // 返回删除位置的下一个结点
}
}再运行一下程序就崩溃了,虽然没报错,但是调试一下就报错了:

自动生成的拷贝构造是浅拷贝,为了解决这个问题,我们需要手动实现一个深拷贝的拷贝构造:
4.2 迭代器区间构造和交换
我们直接写现代写法,因为list本来就是提供迭代器区间初始化和交换函数的,
现在我们实现一下,并且拷贝构造的话至少保证有个头结点把,
所以我们把构造函数拎出来复用一下,写成一个empty_init 函数 (源码里也是这样写的),
这几个函数我们很熟了,直接放代码:
void empty_init()// 创建并初始化哨兵位头结点(即构造函数)
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
template <class InputIterator>
list(InputIterator first, InputIterator last)
{
empty_init();
while (first != last)
{
push_back(*first);
++first;
}
}
list()
{
empty_init();
}
void swap(list<T>& x)//提一嘴:void swap(list& x)也行(类里面可以省略<T>,类外不行>
{
std::swap(_head, x._head); // 换哨兵位头结点就行
}4.3 拷贝构造和赋值重载
在上面的基础上我们直接实现现代写法:
list(const list<T>& lt)//lt2(lt1)
{
empty_init();
list<T> tmp(lt.begin(), lt.end()); // 迭代器区间构造一个(lt1)
swap(tmp); // 直接和lt2换哨兵位头结点
}
list<T>& operator=(list<T> lt)//lt3 = lt1 这里lt1直接深拷贝给lt,lt是局部对象,出来作用域直接调析构
{
swap(lt);// 把深拷贝出来的lt和lt3交换
return *this; // 把lt3返回
}测试一下:
void Test_copy()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
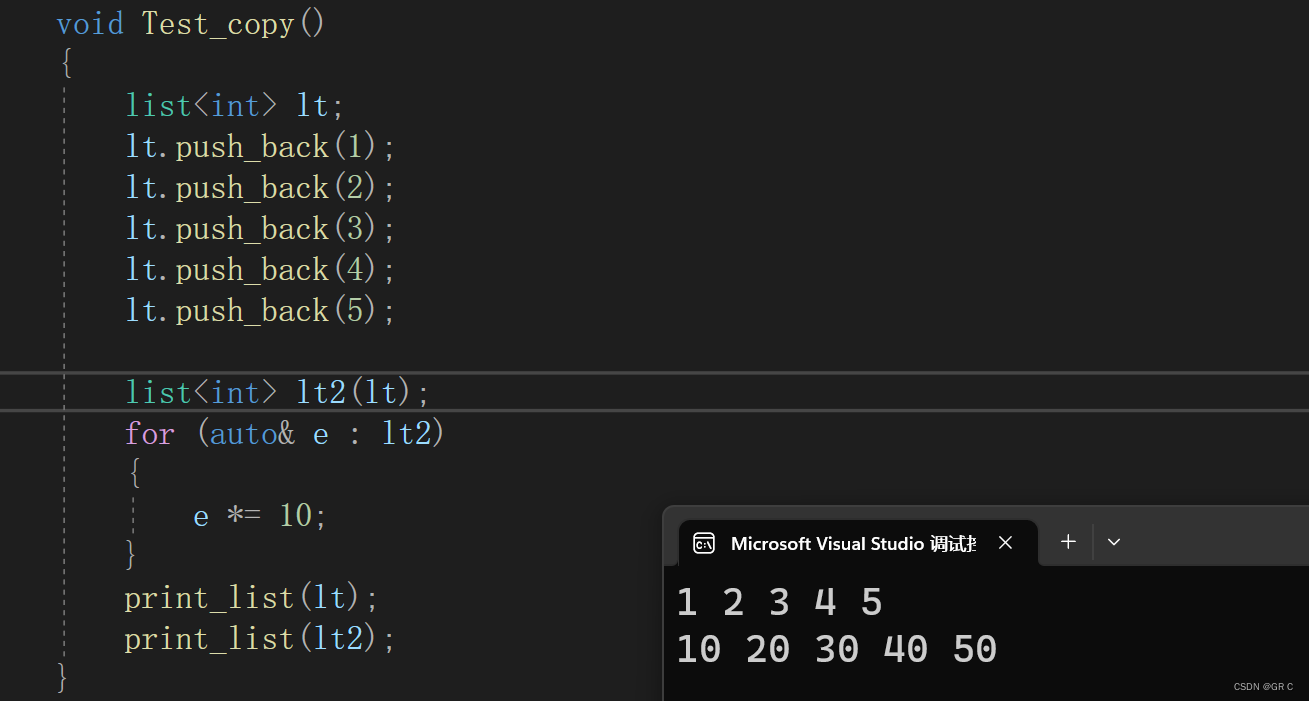
list<int> lt2(lt);
for (auto& e : lt2)
{
e *= 10;
}
print_list(lt);
print_list(lt2);
}
5. list相关选择题
1. 以下程序输出结果为( )
int main()
{
int ar[] = { 0,1, 2, 3, 4, 5, 6, 7, 8, 9 };
int n = sizeof(ar) / sizeof(int);
list<int> mylist(ar, ar + n);
list<int>::iterator pos = find(mylist.begin(), mylist.end(), 5);
reverse(mylist.begin(), pos);
reverse(pos, mylist.end());
list<int>::const_reverse_iterator crit = mylist.crbegin();
while (crit != mylist.crend())
{
cout << *crit << " ";
++crit;
}
cout << endl;
}A.4 3 2 1 0 5 6 7 8 9
B.0 1 2 3 4 9 8 7 6 5
C.5 6 7 8 9 0 1 2 3 4
D.5 6 7 8 9 4 3 2 1 0
2. 下面程序的输出结果正确的是( )
int main()
{
int array[] = { 1, 2, 3, 4, 0, 5, 6, 7, 8, 9 };
int n = sizeof(array) / sizeof(int);
list<int> mylist(array, array + n);
auto it = mylist.begin();
while (it != mylist.end())
{
if (*it != 0)
cout << *it << " ";
else
it = mylist.erase(it);
++it;
}
return 0;
}A.1 2 3 4 5 6 7 8 9
B. 1 2 3 4 6 7 8 9
C.程序运行崩溃
D.1 2 3 4 0 5 6 7 8 9
3. 对于list有迭代器it, 当erase(it)后,说法错误的是( )
A.当前迭代器it失效
B.it前面的迭代器仍然有效
C.it后面的迭代器失效
D.it后面的迭代器仍然有效
4. 下面有关vector和list的区别,描述错误的是( )
A.vector拥有一段连续的内存空间,因此支持随机存取,如果需要高效的随机读取,应该使用vector
B.list拥有一段不连续的内存空间,如果需要大量的插入和删除,应该使用list
C.vector<int>::iterator支持“+”、“+=”、“<”等操作符
D.list<int>::iterator则不支持“+”、“+=”、“<”等操作符运算,但是支持了[]运算符
5. 下面有关vector和list的区别,描述正确的是( )
A.两者在尾部插入的效率一样高
B.两者在头部插入的效率一样高
C.两者都提供了push_back和push_front方法
D.两者都提供了迭代器,且迭代器都支持随机访问
6. 以下代码实现了从表中删除重复项的功能,请选择其中空白行应填入的正确代码( )
template<typename T>
void removeDuplicates(list<T>& aList)
{
T curValue;
list<T>::iterator cur, p;
cur = aList.begin();
while (cur != aList.end())
{
curValue = *cur;
//空白行 1
while (p != aList.end())
{
if (*p == curValue)
{
//空白行 2
}
else
{
p++;
}
}
}
}A. p=cur+1;aList.erase(p++);
B.p=++cur; p == cur ? cur = p = aList.erase(p) : p = aList.erase(p);
C.p=cur+1;aList.erase(p);
D.p=++cur;aList.erase(p);
答案:
1. C
分析:list<int>::iterator pos = find(mylist.begin(), mylist.end(), 5); //找到5的位置
reverse(mylist.begin(), pos);//逆置0 1 2 3 4 为 4 3 2 1 0
reverse(pos, mylist.end()); //逆置5 6 7 8 9 为 9 8 7 6 5
逆置完成之后其数据为:4 3 2 1 0 9 8 7 6 5
list<int>::const_reverse_iterator crit = mylist.crbegin(); //反向迭代器进行反向访问
while(crit != mylist.crend()){}
所以答案为:5 6 7 8 9 0 1 2 3 4
2. B
分析:程序在使用迭代器取值时,如果不等于0就进行打印,为0时不打印并删除当前节点,
3. C
分析:删除节点后,只有指向当前节点的迭代器失效了,其前后的迭代器仍然有效,因为底层为不连续空间,只有被删除的 节点才会失效。
4. D
A.如果想大量随机读取数据操作,vector是首选的容器
B.如果想大量的插入和删除数据,list效率较高,是首选
C.由于vector底层是连续空间,其迭代器就是相应类型的指针,所以支持对应的操作
D.list迭代器不支持[]运算符
5. A
A.vector在尾部插入数据不需要移动数据,list为双向循环链表也很容易找到尾部,因此两者在尾部插入数据效率相同
B.vector头部插入效率极其低,需要移动大量数据
C.vector由于在头部插入数据效率很低,所以没有提供push_front方法
D.list不支持随机访问
6. B
分析:迭代p需要迭代不重复节点的下一节点,重要的是cur迭代器需要往下迭代,因此cur需要往前移动,二答案A C的cur都不会改变,空白行2是当需要找到重复值时进行节点删除,当删除时当前迭代器会失效,因此需要将迭代器p往后迭代。
6. 完整代码
list.h
#pragma once
#include<iostream>
#include<assert.h>
using namespace std;
namespace rtx
{
template<class T>
struct list_node // 定义结点
{
T _data;
list_node* _prev;
list_node* _next;
list_node(const T& x = T())
:_data(x)
,_prev(nullptr)
,_next(nullptr)
{}
};
template<class T, class Ref, class Ptr>
struct __list_iterator // 定义迭代器
{
typedef list_node<T> Node;
typedef __list_iterator<T, Ref, Ptr> iterator;
// 在list类里面:
// typedef __list_iterator<T, T&, T*> iterator;
// typedef __list_iterator<T, const T&, const T*> const_iterator;
Node* _node;
__list_iterator(Node* node)
:_node(node)
{}
bool operator!=(const iterator& it)
{
return _node != it._node;
}
//T& operator*()
Ref operator*()
{
return _node->_data; // 返回结点的数据
}
//T* operator->()
Ptr operator->()
{
return &(operator*());
//即 return &(_node->_data);
}
iterator& operator++()
{
_node = _node->_next;
return *this; // 返回加加后的值
}
iterator operator++(int)
{
iterator tmp(*this); // 拷贝构造一个tmp存储原来的值
_node = _node->_next;
return tmp; // 返回加加前的值
}
iterator& operator--()
{
_node = _node->_prev;
return *this; // 返回减减后的值
}
iterator operator--(int)
{
iterator tmp(*this); // 拷贝构造一个tmp存储原来的值
_node = _node->prev;
return tmp; // 返回减减前的值
}
};
template<class T>
class list // 定义list类
{
typedef list_node<T> Node;
public:
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
iterator begin()// begin是实际数据的第一个,_head 是哨兵位头结点
{
return iterator(_head->_next);
}
iterator end()// end是实际数据的下一个
{
return iterator(_head);
}
void empty_init()// 创建并初始化哨兵位头结点(即构造函数)
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
template <class InputIterator>
list(InputIterator first, InputIterator last)
{
empty_init();
while (first != last)
{
push_back(*first);
++first;
}
}
list()
{
empty_init();
}
void swap(list<T>& x)//提一嘴:void swap(list& x)也行(类里面可以省略<T>,类外不行>
{
std::swap(_head, x._head); // 换哨兵位头结点就行
}
list(const list<T>& lt)//lt2(lt1)
{
empty_init();
list<T> tmp(lt.begin(), lt.end()); // 迭代器区间构造一个(lt1)
swap(tmp); // 直接和lt2换哨兵位头结点
}
list<T>& operator=(list<T> lt)//lt3 = lt1 这里lt1直接深拷贝给lt,lt是局部对象,出来作用域直接调析构
{
swap(lt);// 把深拷贝出来的lt和lt3交换
return *this; // 把lt3返回
}
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it); // 返回删除位置的下一个结点
}
}
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* NewNode = new Node(x);
prev->_next = NewNode;
NewNode->_prev = prev;
NewNode->_next = cur;
cur->_prev = NewNode;
return iterator(NewNode);
}
void push_back(const T& x)
{
//Node* tail = _head->_prev;
//Node* NewNode = new Node(x);
思路图:head tail NewNode
//tail->_next = NewNode;
//NewNode->_prev = tail;
//_head->_prev = NewNode;
//NewNode->_next = _head;
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node; // 删cur
Node* prev = cur->_prev;
prev->_next = cur->_next; // cur前一个指向cur后一个
cur->_next->_prev = prev; // cur后一个指回cur前一个
delete cur;
return iterator(prev->_next); // 返回删除位置下一个
}
void pop_back()
{
erase(begin());
}
void pop_front()
{
erase(--end());
}
private:
Node* _head; // 哨兵位头结点
};
}Test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "list.h"
namespace rtx
{
void Test_arrow()
{
struct Pos
{
int _a1;
int _a2;
Pos(int a1 = 0, int a2 = 0)
:_a1(a1)
, _a2(a2)
{}
};
Pos aa;
Pos* p2 = &aa;
p2->_a1;
p2->_a2;
list<Pos> lt;
lt.push_back(Pos(10, 20));
lt.push_back(Pos(10, 21));
list<Pos>::iterator it = lt.begin();
while (it != lt.end())
{
//cout << (*it)._a1 << "," << (*it)._a2 << endl;
cout << it->_a1 << "," << it->_a2 << endl;
//实际要写,it->->_a1,但是编译器优化了一个箭头
++it;
}
cout << endl;
}
void print_list(const list<int>& lt)
{
list<int>::const_iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
void Test_push_back()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator it = lt.begin();
print_list(lt);
for (const auto& e : lt)
{
cout << e << " ";
}
cout << endl;
}
void Test_insert()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
//list<int>::iterator pos = find(lt.begin(), lt.end(), 2);// 涉及其它问题,先不这样写
//if (pos != lt.end())
//{
// lt.insert(pos, 20);
//}
lt.insert(++lt.begin(), 20);
lt.push_front(0);
lt.push_front(-1);
print_list(lt);
}
void Test_erase()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.erase(++++lt.begin());//发现个好玩的,(删除3)
lt.pop_back();
lt.pop_front();
print_list(lt);
}
void Test_copy()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int> lt2(lt);
for (auto& e : lt2)
{
e *= 10;
}
print_list(lt);
print_list(lt2);
}
}
int main()
{
//rtx::Test_push_back();
//rtx::Test_arrow();
//rtx::Test_insert();
//rtx::Test_erase();
rtx::Test_copy();
return 0;
}本篇完。
list 的反向迭代器放在后面栈和队列期间讲,下一部分:栈和队列:使用,OJ,模拟实现。