原文链接:https://arxiv.org/pdf/2306.02245.pdf
1.引言
分割一切模型(SAM)作为视觉领域的基石模型,有强大的泛化性,能解决很多2D视觉问题。但是SAM是否可以适用于3D视觉任务,仍需要被探索。
目前几乎没有关于3D目标检测的零样本学习,如何使SAM的零样本能力适用于3D目标检测是本文的主要研究内容。
本文提出SAM3D,使用SAM分割BEV图,然后从输出的掩膜预测物体。
2.方法
2.1 准备知识
问题定义
给定一个在有标注的源数据集 D s = { X i s , Y i s } D_s=\{X_i^s,Y_i^s\} Ds={Xis,Yis}上训练的模型 F F F,以及一个3D检测无标签数据集 D t = { X i t } D_t=\{X_i^t\} Dt={Xit}(在本文中 X i t X_i^t Xit表示激光雷达点云),零样本3D目标检测任务的目标就是在不使用 D t D_t Dt标签的情况下,最大化 F F F在 D t D_t Dt上的性能。
SAM的回顾
虽然SAM的能力很强大,但模型很简单:强大的图像编码器和提示编码器分别将图像与提示转换为嵌入特征,随后轻量级的掩膜解码器用于组合信息并预测分割结果。
具体来说,图像编码器是使用MAE预训练的ViT,提示编码器使用CLIP中现成的文本编码器,利用位置编码和自由文本表达点与边界框。掩膜提示使用卷积嵌入,并与图像嵌入特征按元素求和。掩膜解码器使用Transformer解码器(含提示自注意力和两个方向的交叉注意力),并使用动态掩膜头,在图像的每个位置计算掩膜前景概率。
2.2 整体框架
由于本文使用的是3D点云,而SAM的输入是2D图像,因此本文先将激光雷达点云转换为类似2D图像的表达以减小域间隙。基于BEV,本文的使用SAM的模型如下图所示。
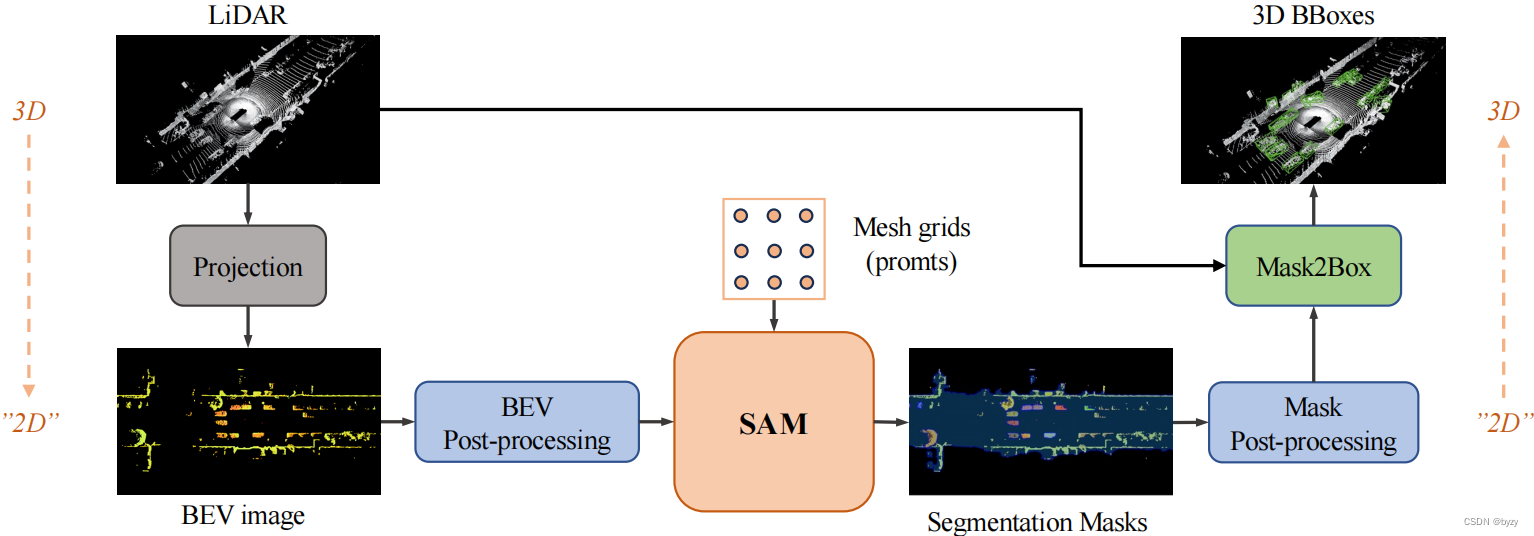
本文的方法分5个步骤:
- 激光雷达到BEV的投影:将激光雷达信号转化为BEV图像。使用投影方程决定每个点在图像平面的坐标,并预定义一组强度到RGB的映射,以得到BEV图像像素的RGB值,使处理时更具判别力。
- BEV后处理:将原始BEV图像进行一个简单的操作,以获得更稳定的SAM输入,使分割更简单、性能更好。
- SAM分割:将改进的BEV图像和网格提示输入SAM,在BEV中分割前景物体。为加速分割,还对提示进行了修剪,这不会牺牲性能。
- 掩膜后处理:使用先验推导出的规则过滤带噪声的掩膜,以减少FP。
- Mask2Box:对前景掩膜寻找最小边界框,提取BEV下的2D框,与激光雷达点云交互后,预测最终的3D边界框。
2.3 激光雷达到BEV的投影
目的是将
N
p
N_p
Np个激光雷达点
P
=
{
(
x
i
,
y
i
,
z
i
)
}
i
=
1
N
p
P=\{(x_i,y_i,z_i)\}_{i=1}^{N_p}
P={(xi,yi,zi)}i=1Np(满足
L
x
≤
x
i
≤
U
x
,
L
y
≤
y
i
≤
U
y
L_x\leq x_i\leq U_x,L_y\leq y_i\leq U_y
Lx≤xi≤Ux,Ly≤yi≤Uy)转化为一张BEV图像
I
∈
R
H
×
W
×
3
I\in\mathbb{R}^{H\times W\times 3}
I∈RH×W×3。
每个点都会落入BEV图像上的一个网格,网格的坐标
(
c
x
,
c
y
)
(cx,cy)
(cx,cy)按下式计算:
c
x
i
=
⌊
(
U
x
−
x
i
)
/
s
x
⌋
c
y
i
=
⌊
(
U
y
−
y
i
)
/
s
y
⌋
cx_i=\left \lfloor (U_x-x_i)/s_x\right \rfloor\\cy_i=\left \lfloor (U_y-y_i)/s_y\right \rfloor
cxi=⌊(Ux−xi)/sx⌋cyi=⌊(Uy−yi)/sy⌋其中
s
x
,
s
y
s_x,s_y
sx,sy为
x
,
y
x,y
x,y方向的柱体大小。
此后,需要得到填入BEV图像中的像素值,使BEV图像更具判别力。点的反射强度
R
=
{
r
i
}
i
=
1
N
p
R=\{r_i\}_{i=1}^{N_p}
R={ri}i=1Np可以用于形成BEV图像的特征向量。首先将反射强度归一化到
[
0
,
1
]
[0,1]
[0,1]内,并用其从预定义的调色板上选择色彩向量:
c
i
=
Pallete
(
Norm
(
r
i
)
)
∈
R
3
I
[
c
x
i
,
c
y
i
,
:
]
=
c
i
c_i=\text{Pallete}(\text{Norm}(r_i))\in \mathbb{R}^3\\I[cx_i,cy_i,:]=c_i
ci=Pallete(Norm(ri))∈R3I[cxi,cyi,:]=ci其中
Pallete
:
R
→
R
3
\text{Pallete}:\mathbb{R}\rightarrow\mathbb{R}^3
Pallete:R→R3是将强度标量转化为RGB向量的调色板。
无对应点的BEV像素,使用零向量填充。最后得到有判别力的BEV图像
I
∈
R
H
×
W
×
3
I\in\mathbb{R}^{H\times W\times 3}
I∈RH×W×3。
2.4 BEV后处理
SAM的图像是在“密集”的自然图像上训练的,而BEV图像是“稀疏”的。为减小间隙,本文使用形态扩张(即最大池化): I ′ = MaxPool2D ( I ) I'=\text{MaxPool2D}(I) I′=MaxPool2D(I)
2.5 使用SAM分割
SAM支持使用各种提示,如点、框和掩膜。这一步的目标是分割处尽可能多的前景目标,因此本文使用网格提示覆盖整张图像。具体来说,创建
32
×
32
32\times32
32×32的、在图像平面均匀分布的网格,将它们视作SAM的点提示。
但是由于稀疏BEV图像有很多空的区域,本文还对提示进行了修剪。将提示投影到BEV图像上,检查每个提示的邻域,将周围无激活像素的提示丢弃掉。该步骤使得整个流程被极大地加速。
该步骤完成后,得到
N
m
N_m
Nm个分割掩膜
M
=
{
m
i
∈
R
H
×
W
}
i
=
1
N
m
M=\{m_i\in\mathbb{R}^{H\times W}\}_{i=1}^{N_m}
M={mi∈RH×W}i=1Nm。
2.6 掩膜后处理
尽管SAM有强大的零样本能力,这里仍然存在不可忽视的域间隙。因此SAM输出的掩膜是有噪声的,需要进一步处理。
在自动驾驶领域中,汽车是有大概的面积和长宽比的,可以用于滤除
M
M
M中的某些FP。具体来说,本文使用面积阈值
[
T
l
a
,
T
h
a
]
[T_l^a,T_h^a]
[Tla,Tha]和长宽比阈值
[
T
l
r
,
T
h
r
]
[T_l^r,T_h^r]
[Tlr,Thr]来过滤掩膜。
最终,得到
N
o
N_o
No个相对高质量的前景掩膜
M
′
=
{
m
i
∈
R
H
×
W
}
i
=
1
N
o
M'=\{m_i\in\mathbb{R}^{H\times W}\}_{i=1}^{N_o}
M′={mi∈RH×W}i=1No,每个掩膜对应一个前景物体。
2.7 Mask2Box
可以直接从2D掩膜估计3D边界框的水平属性(水平位置
(
x
3
D
,
y
3
D
)
(x^{3D},y^{3D})
(x3D,y3D)、长宽
(
d
x
2
D
,
d
y
3
D
)
(dx^{2D},dy^{3D})
(dx2D,dy3D)、朝向
θ
3
D
\theta^{3D}
θ3D),但对于垂直属性(垂直位置
z
3
D
z^{3D}
z3D和高
d
z
3
D
dz^{3D}
dz3D),需要使用激光雷达点进行信息补偿。
首先从掩膜提取最小边界框:
B
2
D
=
{
(
x
i
2
D
,
y
i
2
D
,
d
x
i
2
D
,
d
y
i
2
D
,
θ
i
2
D
)
}
i
=
1
N
o
B^{2D}=\{(x^{2D}_i,y^{2D}_i,dx^{2D}_i,dy^{2D}_i,\theta^{2D}_i)\}_{i=1}^{N_o}
B2D={(xi2D,yi2D,dxi2D,dyi2D,θi2D)}i=1No 然后将2D属性投影为对应的3D属性:
x
i
3
D
=
U
x
−
(
x
i
2
D
+
0.5
)
×
s
x
y
i
3
D
=
U
y
−
(
y
i
2
D
+
0.5
)
×
s
y
d
x
i
3
D
=
d
x
i
2
D
×
s
x
d
y
i
3
D
=
d
y
i
2
D
×
s
y
θ
i
3
D
=
θ
i
2
D
x^{3D}_i=U_x-(x_i^{2D}+0.5)\times s_x\\y^{3D}_i=U_y-(y_i^{2D}+0.5)\times s_y\\dx^{3D}_i=dx^{2D}_i\times s_x\\dy^{3D}_i=dy^{2D}_i\times s_y\\\theta^{3D}_i=\theta^{2D}_i
xi3D=Ux−(xi2D+0.5)×sxyi3D=Uy−(yi2D+0.5)×sydxi3D=dxi2D×sxdyi3D=dyi2D×syθi3D=θi2D 最后选择落在2D边界框内的激光雷达点,使用垂直坐标计算边界框的垂直属性:
Z
i
=
{
z
j
∣
(
x
j
,
y
j
,
z
j
)
在
B
E
V
上的投影位于
B
i
2
D
中
}
d
z
i
3
D
=
max
(
Z
i
)
−
min
(
Z
i
)
z
i
3
D
=
min
(
Z
i
)
+
d
z
i
3
D
2
Z_i=\{z_j|(x_j,y_j,z_j)在BEV上的投影位于B_i^{2D}中\}\\dz_i^{3D}=\max(Z_i)-\min(Z_i)\\z_i^{3D}=\min(Z_i)+\frac{dz_i^{3D}}{2}
Zi={zj∣(xj,yj,zj)在BEV上的投影位于Bi2D中}dzi3D=max(Zi)−min(Zi)zi3D=min(Zi)+2dzi3D
3.实验
3.1 设置
本文在Waymo Open的验证集上对汽车类别进行评估,且只考虑最多30m内的物体。
3.2 定性结果
可视化表明,SAM能在不接触3D标注的情况下生成高质量的2D边界框,且能进一步得到高质量的3D边界框。
但也存在一些明显的失效情况:当物体距离较近时,SAM会重复生成掩膜;与汽车外观类似的物体会被SAM错误分割为前景;由于激光雷达点云的稀疏性以及截断或遮挡等,部分汽车在BEV图像中被部分激活,因此SAM会忽略这些物体,导致很多FN。
3.3 消融研究
柱体大小的影响
当柱体大小较大,量化误差增大,且难以区分近距离的物体;当柱体大小较小同样会损害性能,因为激光雷达点云的稀疏性使得来自同一物体的点难以形成连通区域,SAM倾向于将一个物体分割为多个部分。
反射强度的影响
将本文的预定义的强度到RGB的映射方法与二值法(生成黑白双色的二值图像)、强度法(生成灰度图像)比较,实验表明本文的方法在性能上能大幅超过二值法与强度法,因为彩色图像更具判别力,SAM更容易分割。
SAM结构的影响
实验表明,使用小容量模型会导致性能下降,但使用大容量模型也仅能带来微小的性能提升。这说明模型容量不是性能瓶颈,且SAM的能力仍需被充分释放。
BEV后处理的影响
实验表明,去除BEV后处理会带来显著的性能下降,这表明BEV后处理能缩减BEV图像和自然图像的间隙。
掩膜后处理的影响
面积与长宽比的后处理均对性能提升有帮助,因为仍然存在不可忽视的域间隙。
4.讨论
本文的实验表明,使用SAM进行零样本3D目标检测任务是可行的。
但仍存在一些需改进的重要方面:
- 使用BEV图像表达,可能无法进行室内的3D目标检测,需要寻找更好的场景表达。
- 由于遮挡和截断,以及激光雷达点云的稀疏性,本文的方法会产生许多FN,特别是对于远距离物体。结合其余模态的信息可能有帮助。
- 虽然通过提示修剪大幅减小了推断时间,推断速度仍受限于SAM的复杂性。模型压缩和蒸馏可能可以解决此问题。
- 本文的方法还不支持多类别物体检测,因为SAM缺乏语义标签的输出。可以使用视觉-语言模型(如CLIP Goes 3D)进行零样本分类。
使用少样本学习和提示工程等技术,可以更有效地利用视觉基石模型解决3D任务。