管道数据库
class SpiderBookPipeline:
def __init__(self):
host = 'localhost'
user = 'root'
password = '@hdp020820'
db = '警察大学信息检索'
self.conn = pymysql.connect(host=host, user=user, password=password, db=db)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
if isinstance(item, SpiderBookItem):
# Define your SQL query
query = """
INSERT INTO my_table
(big_category, big_category_link, book_author, book_name, book_price, small_category, small_category_link)
VALUES
(%s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(query, (
item['big_category'],
item['big_category_link'],
item['book_author'],
item['book_name'],
item['book_price'],
item['small_category'],
item['small_category_link']
))
if isinstance(item, NewItems):
sql = 'insert into news (id, title, link, date) VALUES (null, %s, %s, %s)'
self.cursor.execute(sql, [item['title'], item['link'], item['date'], ])
# Commit the transaction
self.conn.commit()
return item
要定义SpiderBookPipeline的数据库表结构,你可以创建两个表:my_table和news。
my_table表结构:您可以使用以下SQL语句创建my_table表:
列:
big_category(VARCHAR):书籍的大类别。
big_category_link(VARCHAR):与大类别相关联的链接。
book_author(VARCHAR):书籍的作者。
book_name(VARCHAR):书籍的名称。
book_price(VARCHAR):书籍的价格。
small_category(VARCHAR):书籍的小类别。
small_category_link(VARCHAR):与小类别相关联的链接。
CREATE TABLE my_table (
id INT AUTO_INCREMENT PRIMARY KEY,
big_category VARCHAR(255),
big_category_link VARCHAR(255),
book_author VARCHAR(255),
book_name VARCHAR(255),
book_price VARCHAR(255),
small_category VARCHAR(255),
small_category_link VARCHAR(255)
);
news表结构:您可以使用以下SQL语句创建news表:
列:
id(INT):每个新闻项的自增ID。
title(VARCHAR):新闻的标题。
link(VARCHAR):与新闻相关联的链接。
date(VARCHAR):新闻的日期。
CREATE TABLE news (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
link VARCHAR(255),
date VARCHAR(255)
);
根据您的需求,确保调整列的数据类型和长度。上述示例假设使用VARCHAR(255)进行简化,但您可以根据需要进行修改。
注意:在执行SQL语句之前,请确保您具有必要的权限,并在MySQL服务器中创建了数据库警察大学信息检索。
redies数据库
服务器的redies数据库配置https://www.jianshu.com/p/990cdf530a58
Redis是什么
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库,其具备如下特性:
- 基于内存运行,性能高效
- 支持分布式,理论上可以无限扩展
- key-value存储系统
- 开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
相比于其他数据库类型,Redis具备的特点是:
- C/S通讯模型
- 单进程单线程模型
- 丰富的数据类型
- 操作具有原子性
- 持久化
- 高并发读写
- 支持lua脚本
哪些大厂在使用Redis?
- github
- 微博
- Stack Overflow
- 阿里巴巴
- 百度
- 美团
- 搜狐
Redis的应用场景有哪些?
Redis 的应用场景包括:缓存系统(“热点”数据:高频读、低频写)、计数器、消息队列系统、排行榜、社交网络和实时系统。

Redis的数据类型及主要特性
Redis提供的数据类型主要分为5种自有类型和一种自定义类型,这5种自有类型包括:String类型、哈希类型、列表类型、集合类型和顺序集合类型。

String类型:
它是一个二进制安全的字符串,意味着它不仅能够存储字符串、还能存储图片、视频等多种类型, 最大长度支持512M。
对每种数据类型,Redis都提供了丰富的操作命令,如:
- GET/MGET
- SET/SETEX/MSET/MSETNX
- INCR/DECR
- GETSET
- DEL
哈希类型:
该类型是由field和关联的value组成的map。其中,field和value都是字符串类型的。
Hash的操作命令如下:
- HGET/HMGET/HGETALL
- HSET/HMSET/HSETNX
- HEXISTS/HLEN
- HKEYS/HDEL
- HVALS
列表类型:
该类型是一个插入顺序排序的字符串元素集合, 基于双链表实现。
List的操作命令如下:
- LPUSH/LPUSHX/LPOP/RPUSH/RPUSHX/RPOP/LINSERT/LSET
- LINDEX/LRANGE
- LLEN/LTRIM
集合类型:
Set类型是一种无顺序集合, 它和List类型最大的区别是:集合中的元素没有顺序, 且元素是唯一的。
Set类型的底层是通过哈希表实现的,其操作命令为:
- SADD/SPOP/SMOVE/SCARD
- SINTER/SDIFF/SDIFFSTORE/SUNION
Set类型主要应用于:在某些场景,如社交场景中,通过交集、并集和差集运算,通过Set类型可以非常方便地查找共同好友、共同关注和共同偏好等社交关系。
顺序集合类型:
ZSet是一种有序集合类型,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序。与Set类型一样,其底层也是通过哈希表实现的。
ZSet命令:
- ZADD/ZPOP/ZMOVE/ZCARD/ZCOUNT
- ZINTER/ZDIFF/ZDIFFSTORE/ZUNION
Redis的数据结构
Redis的数据结构如下图所示:
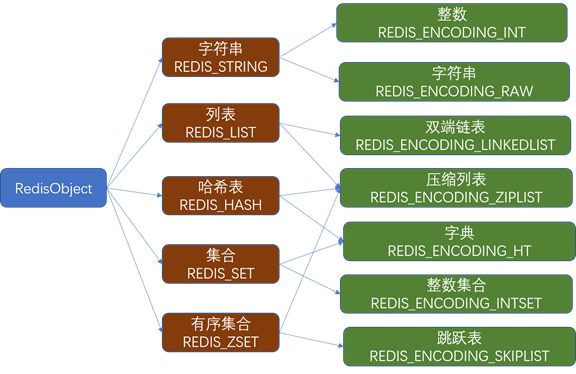
关于上表中的部分释义:
- 压缩列表是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数,要么就是长度比较短的字符串,Redis就会使用压缩列表来做列表键的底层实现
- 整数集合是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现
如下是定义一个Struct数据结构的例子:
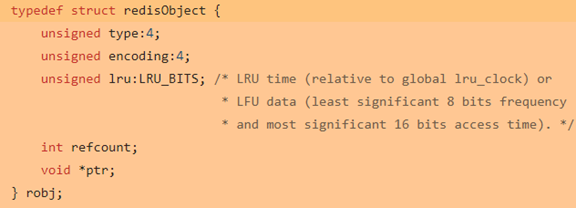
简单动态字符串SDS (Simple Dynamic String)
基于C语言中传统字符串的缺陷,Redis自己构建了一种名为简单动态字符串的抽象类型,简称SDS,其结构如下:
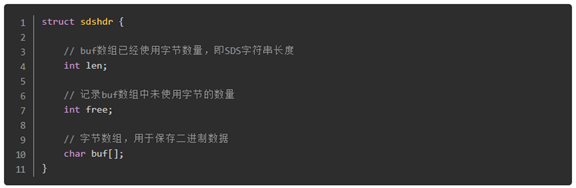
SDS几乎贯穿了Redis的所有数据结构,应用十分广泛。
SDS的特点
和C字符串相比,SDS的特点如下:
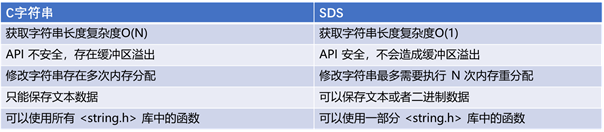
1. 常数复杂度获取字符串长度
Redis中利用SDS字符串的len属性可以直接获取到所保存的字符串的长
度,直接将获取字符串长度所需的复杂度从C字符串的O(N)降低到了O(1)。
2. 减少修改字符串时导致的内存重新分配次数
通过C字符串的特性,我们知道对于一个包含了N个字符的C字符串来说,其底层实现总是N+1个字符长的数组(额外一个空字符结尾)
那么如果这个时候需要对字符串进行修改,程序就需要提前对这个C字符串数组进行一次内存重分配(可能是扩展或者释放)
而内存重分配就意味着是一个耗时的操作。
Redis巧妙的使用了SDS避免了C字符串的缺陷。在SDS中,buf数组的长度不一定就是字符串的字符数量加一,buf数组里面可以包含未使用的字节,而这些未使用的字节由free属性记录。
与此同时,SDS采用了空间预分配的策略,避免C字符串每一次修改时都需要进行内存重分配的耗时操作,将内存重分配从原来的每修改N次就分配N次——>降低到了修改N次最多分配N次。
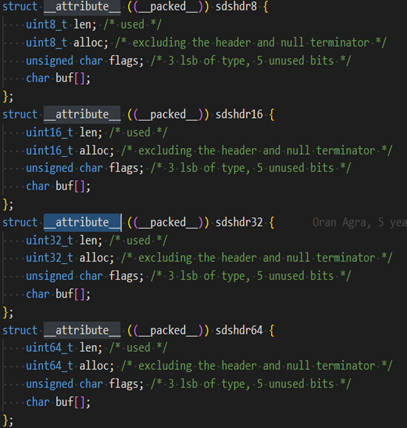
如下是Redis对SDS的简单定义:

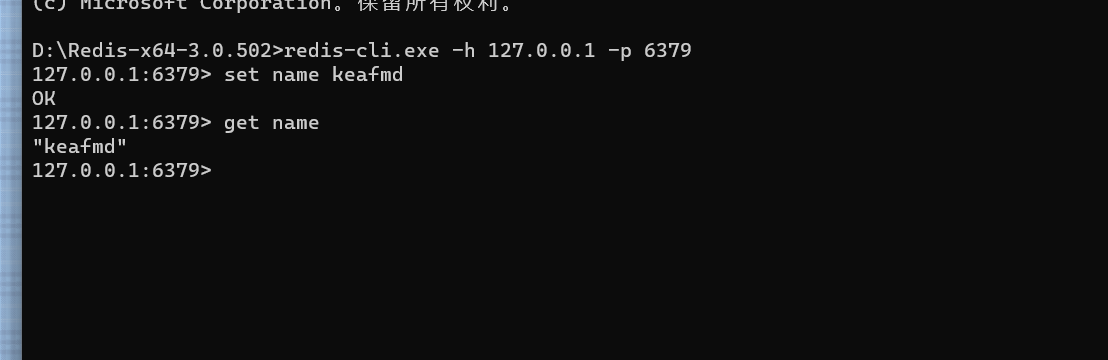
要设置Redis数据库,您需要按照以下步骤进行操作:
安装Redis:首先,您需要安装Redis数据库。您可以从Redis官方网站(https://redis.io/)下载适合您操作系统的安装程序或者通过包管理器进行安装。
启动Redis服务器:安装完成后,您需要启动Redis服务器。在命令行中,输入以下命令来启动Redis服务器:
redis-server
默认情况下,Redis将在本地主机上的默认端口6379上运行。
- 连接到Redis服务器:在您的应用程序中,您需要使用Redis客户端库来连接到Redis服务器。根据您选择的编程语言和Redis客户端库,您可以使用相应的方法来建立连接。下面是Python中使用redis-py库连接到Redis服务器的示例:
import redis
# 创建Redis连接
r = redis.Redis(host='localhost', port=6379)
# 测试连接
try:
r.ping()
print("成功连接到Redis服务器")
except redis.ConnectionError:
print("无法连接到Redis服务器")
在上述示例中,host和port参数指定了Redis服务器的地址和端口。根据您的实际情况进行修改。
- 使用Redis数据库:连接到Redis服务器后,您可以使用Redis提供的各种命令和功能来操作数据。以下是一些常用的Redis命令示例:根据您的具体需求,您可以使用适当的Redis命令和功能来操作数据。
-
- 存储和检索数据:
- 设置过期时间:
- 设置哈希数据:
- 发布与订阅消息:
# 存储数据
r.set('key', 'value')
# 检索数据
value = r.get('key')
print(value)
# 存储带有过期时间的数据(10秒后过期)
r.setex('key', 10, 'value')
# 存储哈希数据
r.hset('hash_key', 'field', 'value')
# 获取哈希数据
value = r.hget('hash_key', 'field')
print(value)
# 发布消息
r.publish('channel', 'message')
# 订阅消息
pubsub = r.pubsub()
pubsub.subscribe('channel')
for message in pubsub.listen():
print(message)
这些是Redis设置的基本步骤。根据您的应用程序需求,您还可以配置更高级的功能,例如设置密码、配置持久化、设置主从复制等。有关更多详细信息,请参阅Redis官方文档或适用于您所使用的Redis版本的文档。
环境安装教程
redies可视化管理工具
Redis Desktop Manager(Redis可视化工具)安装及使用教程_redisdesk_南风孤梦晓辰星的博客-CSDN博客
demo
fake_useragent是一个Python库,用于生成随机的用户代理(User-Agent)字符串。用户代理是一个HTTP请求头部的一部分,用于标识发起请求的客户端(通常是Web浏览器)的类型、版本和操作系统等信息。
fake_useragent库的主要功能是生成随机的用户代理字符串,以模拟不同类型的浏览器、设备和操作系统的请求。它可以用于以下情况:
- 网络爬虫:在编写网络爬虫时,使用不同的用户代理字符串可以使爬虫看起来更像真实的用户请求。通过随机选择用户代理,可以降低被目标网站识别和阻止的风险。
- 数据采集和测试:在进行数据采集、API测试或模拟用户行为时,使用随机的用户代理可以提高请求的多样性,模拟不同类型的客户端访问。
- 匿名性和隐私保护:有时候,您可能希望隐藏自己的真实身份或IP地址。通过使用随机的用户代理,您可以增加一定程度的匿名性,使请求更难被追踪。
fake_useragent库提供了一个简单的API,使您可以轻松地生成随机的用户代理字符串。您可以使用它来获取随机的浏览器、操作系统和设备类型等信息,或者从预定义的用户代理池中选择特定类型的用户代理。
请注意,尽管使用随机的用户代理可以提高匿名性和请求多样性,但某些网站可能仍然能够检测到并限制此类行为。在使用fake_useragent或任何用户代理相关技术时,请始终遵守目标网站的规则和法律法规,并确保遵循适当的爬取道德准则。