背景
笔者最近一段时间使用 Apache Pinot 比较多,发现目前国内使用 Pinot 的很少,所以跟他相关的资料也比较少,本人在扩容,升级,部署,查询等方面操作有些许经验,知道其中有很多细节需要注意和规避,所以打算开个坑来写一下这块相关的实践内容和注意事项,方便自己回溯也方便使用Pinot 的人参考。 顺便以此来回馈 Pinot 社区对我很多的帮助,依稀记得 Pinot 作者之一 fuxiang 在国外跟我用腾讯会议沟通交流为什么升级 Controller 升级不上去的原因,非常感谢。
缘分
从国外空降了一个 Linkedin 的领导,或许跟他的职业经历有关,也或许跟他的爱好有关。他列出了使用 Pinot 的好处和使用 Clickhouse 的坏处,一番不算激烈的讨论,最终还是引入了 Pinot 用来做后续底层基础。
数据比对
| 要素/用法及其易用性 | ClickHouse | Pinot |
|---|---|---|
| kafka流数据输入 | 支持 | 支持 |
| Join | 支持 | 只能LookUp |
| cluster可伸缩 | 需要手动更改权值以让数据写入新节点,均衡后,再次修改权值以维护均衡 | 每增加一个节点到cluster,在控制台配置新节点,触发rebalance,pinot会自动调节所有表的数据分布 |
| 监控 | Prometheus + Grafana | Prometheus + Grafana |
| 维护 | 随着cluster的扩容,表的定义增加,维护成本越来越重 | 维护成本基本稳定 |
概念
单表几万几十万的qps,那种需要多一点broker,不然就还是堆server
笔者在这个章节主要核心是简单介绍一下 Pinot 有哪些必要的组件。
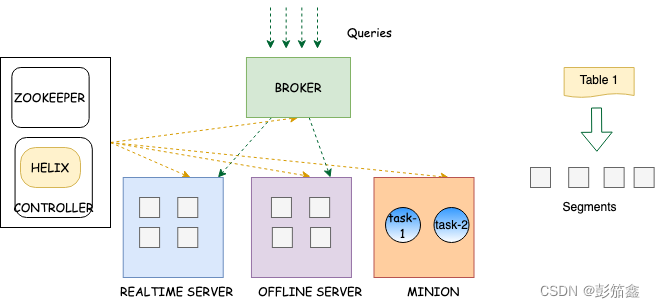
抄了一下官方的图,这里可以看到几个拆的比较开的组件,分别是 Controller,Broker 和 Server。
从图中我们可以看出 Controller 里面有一个 Helix,Broker 是接受 Queries 并且在请求到 Server, MINION 是一个比较特殊的块块,是新版本的一个功能,暂不过多介绍。然后 Server 里其实是对应的 Table,Table是有N个segments组成。
Controller
Controller 顾名思义就是控制,核心还是各种 metadata 的管理。他主要是通过 Helix 的组件来做到强一致性。 Helix 是基于 ZK 的一个 Apache 开源项目。看官方介绍,他其实一个通用集群管理框架,用于自动管理托管在节点集群上的分区、复制和分布式资源。面对节点故障和恢复、集群扩展和重新配置,Helix 会自动重新分配资源。
Broker
简单点说是接受并解析用户打过来的查询,通过某种方式定位到需要查询到 Server,并且把数据打过去。
Server
存储数据,索引等信息的地方。Server 里的 Data 目录有两个文件,一个是 index,一个是 segment,其实主要的一些信息都是在 index 里面。

工作流程
上面就简单介绍了组件,那么他们之间比较高层级的工作流程如下
- 用户通过不同的平台提交查询到 Pinot
- Broker 接收到 Query,对查询会做解析,生成对应的查询计划,他会根据 Controller 里面的配置信息知道需要查询哪些 Segment 和哪些 Server 有这些Segment。
- Broker 会生成对应 N 个查询并行去查询 Server,Server 会基于本地的 Index 等其他数据结构来读取对应的 Segment 并且把部分结果计算好了返回给Broker
- Broker 最终汇总所有 Server 返回回来的结果并且根据对应的逻辑去做后处理,包含不限于排序,聚合等行为。
总结
根据整体流程,我们大概可以知道每个节点分别的职责是什么,以及他们内部是如何工作的。后面会开内容去详细讲解一下 Controller,Server 和 Broker 内部的功能和细节。简单说的话涉及到升级,扩容,查询超时,修改表结构,修改表数据等内容。