文章目录
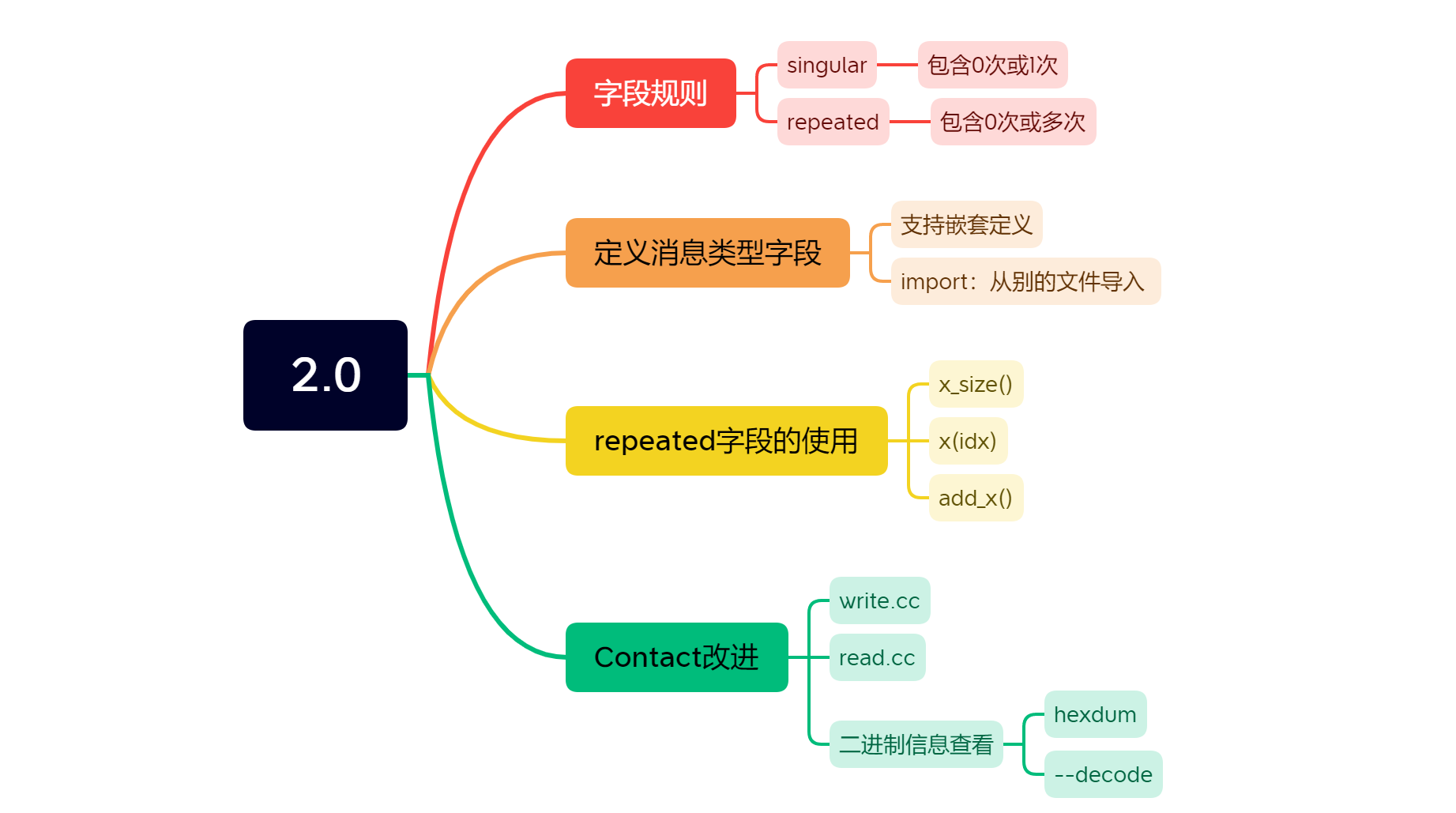
- 2.0
- 一、字段规则
- 1.1 规则
- 1.2 改进
- 1.3 消息类型作为字段类型
- 二、repeated字段使用方式
- 三、Contact2.0
- 1.write.cc
- 2.read.cc
- 3. 查看二进制信息
- ①hexdump
- ② --decode选项
2.0
本系列文章将通过对通讯录项目的不断完善,带大家由浅入深的学习Protobuf的使用。这是Contacts的2.0版本,在这篇文章中将带大家正式开始编写通讯录,并进一步学习Protobuf的语法
一、字段规则
1.1 规则
消息的每个字段可以用下面的规则进行修饰:
- singular:消息中可以包含该字段零次或一次。proto3语法中,字段默认使用该规则 (注:出现0次的字段如果没有默认值,就不会被序列化到消息中)
- repeated:消息中可以包含该字段任意多次(包括零次),并会按先顺序保存。可以理解为定义了一个数组
1.2 改进
我们现在改进1.0版的通讯录,增加一个规则为 repeated 的 phone_number字段
syntax = "proto3";
package contact2;
message PeopleInfo{
string name = 1;
int32 age = 2;
repeated string phone = 3; // 相当于一个 string 数组了
}
下面增加一点难度,将phone类型也定义为一个message
1.3 消息类型作为字段类型
-
Protobuf是支持嵌套定义message的
message PeopleInfo{ string name = 1; int32 age = 2; message Phone{ // 在不同的message中唯一编号是可以重复的 string number = 1; string tyepe = 2; } repeated Phone phone = 3; } -
import其他proto文件中定义的message类型// phone.proto中的内容 syntax = "proto3"; package phone; message Phone{ string number = 1; string tyepe = 2; } // contact2.proto syntax = "proto3"; package contact2; import "phone.proto"; message PeopleInfo{ string name = 1; int32 age = 2; // phone.xxx 表示在phonen包中 // 如果 Phone 没有定义在任何包内,则可以省略 repeated phone.Phone phone = 3; }
使用Vscode的时候,你可能会看到如下的报错,这是Vscode插件的问题,我们语法没有出错,我们可以正常编译没有问题。
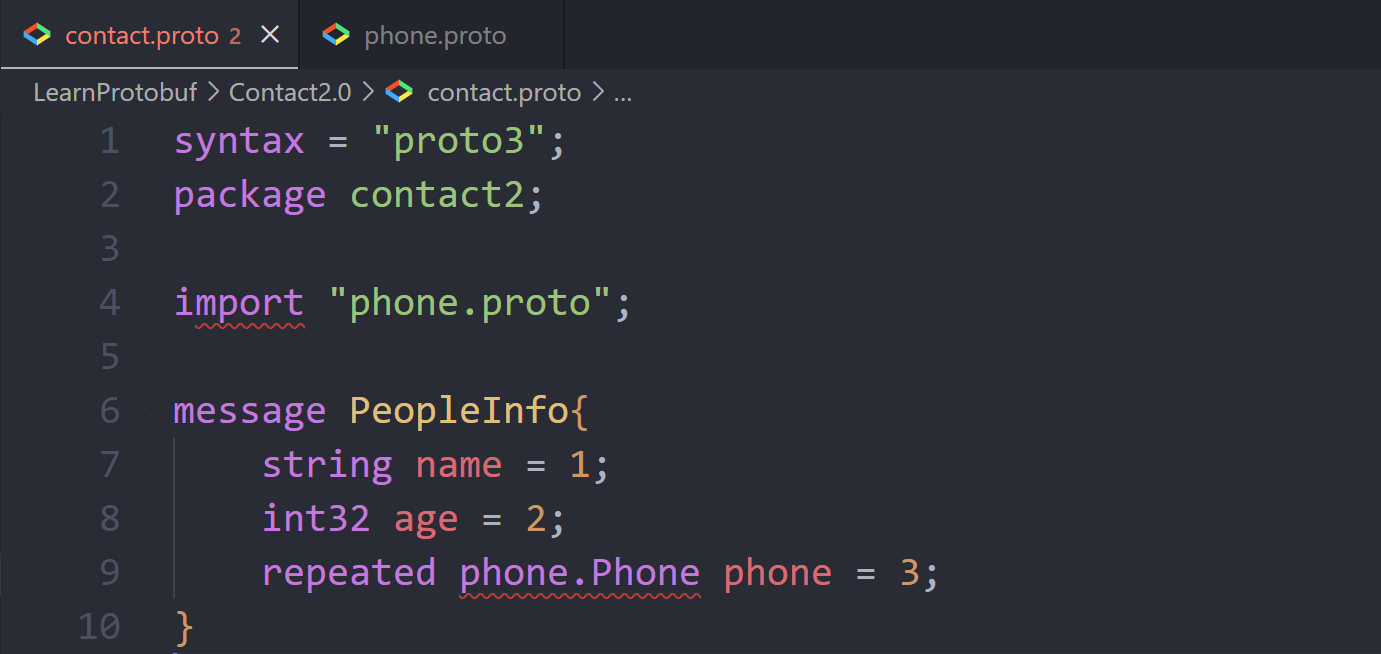
【注】:proto3可以导入proto2的消息类型并使用它,反之亦然
最终 contact.proto 文件内容如下:
syntax = "proto3";
package contact2;
message PeopleInfo{
string name = 1;
int32 age = 2;
message Phone{
string number = 1;
string tyepe = 2;
}
repeated Phone phone = 3;
}
message Contact{
repeated PeopleInfo contact = 1;
}
二、repeated字段使用方式
编译后我们发现生成了两个类,这也是符合我们预期的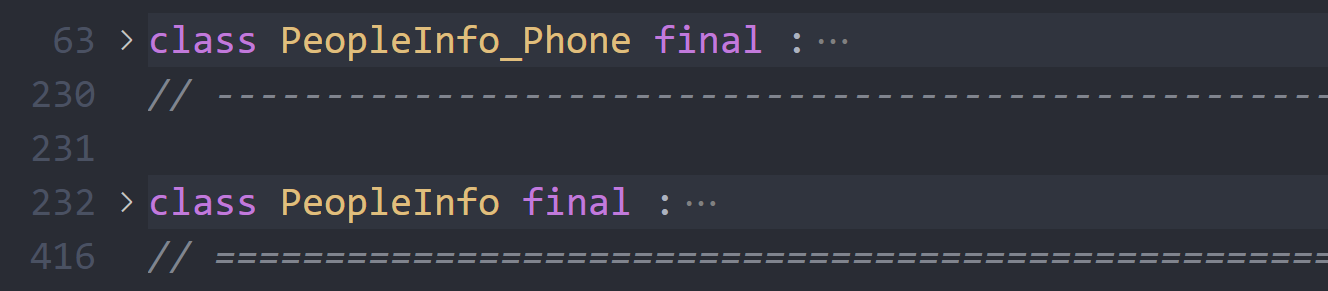
由于Phone消息是嵌套定义在PeopleInfo消息中的,因此生成的class名前面有一个PeopleInfo_
编译后,编译器为 repeated phone 额外提供了这些接口,部分如下:
inline int PeopleInfo::phone_size() const {...}; // 返回数组元素个数
inline ::contact2::PeopleInfo_Phone* PeopleInfo::mutable_phone(int index) {...} // 相当于返回 &phone[index]
inline const ::contact2::PeopleInfo_Phone& PeopleInfo::phone(int index) const {...} // 相当于 phone[index]
inline ::contact2::PeopleInfo_Phone* PeopleInfo::add_phone() {}
// 添加一个新的Phone对象到PeopleInfo中的phones数组中,并返回一个可变的(mutable)指向新添加的对象的指针。我们可以通过该指针修改该新对象的内容
三、Contact2.0
🎯[2.0版升级目标]:
- 不再打印联系人的序列化结果,而是将通讯录序列化后并写入文件中。
- 从文件中将通讯录解析出来,并进行打印。
- 新增联系人属性例如:姓名、年龄、电话信息、地址、联系方式等。
1.write.cc
#include <iostream>
#include <fstream>
#include "contact.pb.h"
using namespace std;
void AddPeopleInfo(contact2::PeopleInfo* p){
cout << "----------新增联系人----------" << endl;
cout << "请输入联系人姓名: ";
string name;
getline(cin, name);
p->set_name(name);
cout << "请输入联系人年龄: ";
int age;
cin >> age;
p->set_age(age);
// 一直清空,直到读到 \n(\n也会被清除),或者清空,直到清空了256个字符
cin.ignore(256, '\n');
// 说明:cin输入后,换行符还会被留在缓冲区中,而getline读到\n就停了
// 所以需要使用 cin.ignore 清空缓冲区从而避免对之后的输入产生影响
for(int i = 0;; i++){
cout << "请输入联系人电话" << i + 1 << "(只输入回车则结束): ";
string number;
getline(cin, number);
if(number.empty()) break;
contact2::PeopleInfo_Phone* phone = p->add_phone();
phone->set_number(number);
cout << "请输入该电话类型: ";
string type;
getline(cin, type);
phone->set_tyepe(type);
}
cout << "-----------添加成功-----------" << endl;
}
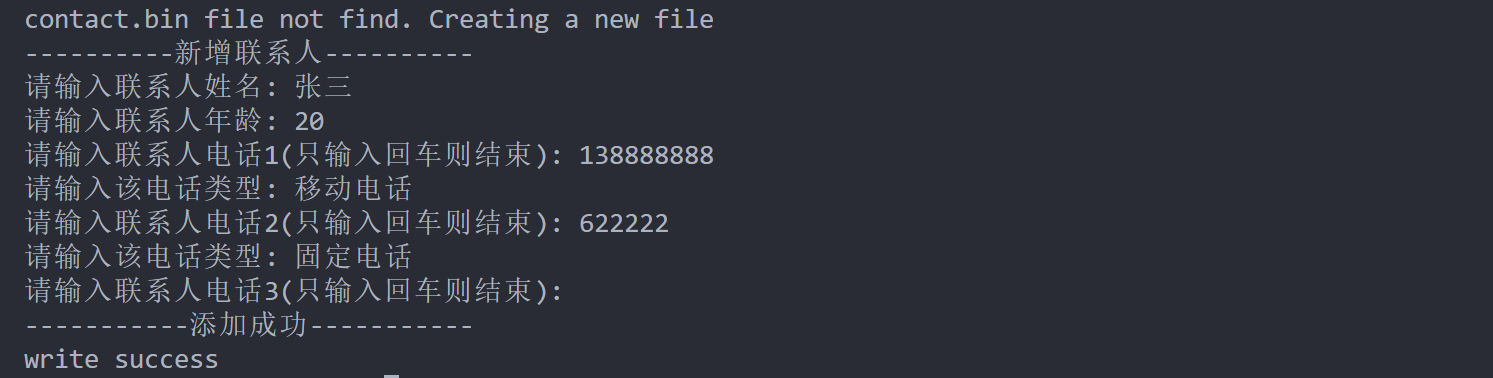
int main(int argc, char* argv[]){
if(argc != 2){
cerr << "use: ./write filename" << endl;
exit(1);
}
contact2::Contact contact;
// 1. 读取通讯录中的原始数据
// 二进制的方式读取
fstream input(argv[1], ios::in | ios::binary);
if(!input){
cerr << argv[1] << " file not find. Creating a new file" << endl;
} // 从输出流中反序列化
else if(!contact.ParseFromIstream(&input)){
cerr << "parser original file error" << endl;
exit(2);
}
// 2. 新增联系人
AddPeopleInfo(contact.add_contact());
// 3. 写入文件中
fstream output(argv[1], ios::out | ios::trunc | ios::binary);
if(!output || !contact.SerializePartialToOstream(&output)){
cerr << "write error" << endl;
exit(3);
}
cout << "write success" << endl;
input.close();
output.close();
}
2.read.cc
#include <iostream>
#include <fstream>
#include "contact.pb.h"
using namespace std;
void PrintContact(contact2::Contact& contact){
for(int i = 0; i < contact.contact_size(); i++){
const contact2::PeopleInfo people = contact.contact(i);
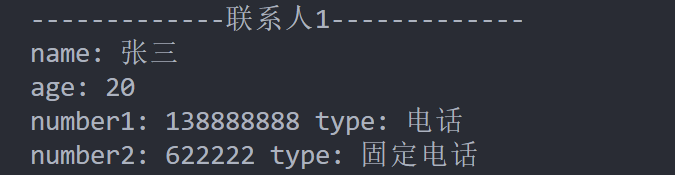
cout << "-------------联系人" << i + 1 << "-------------" << endl;
cout << "name: " << people.name() << endl;
cout << "age: " << people.age() << endl;;
int j = 1;
for(const auto& phone : people.phone()){
cout << "number" << j++ << ": " << phone.number()
<< " type: " << phone.type() << endl;
}
}
}
int main(int argc, char* argv[])
{
if(argc != 2){
cerr << "use: ./read file" << endl;
exit(1);
}
contact2::Contact contact;
// 1. 读取通讯录中的原始数据
fstream input(argv[1], ios::in | ios::binary); // 二进制的方式读取
if(!input){
cerr << argv[1] << " file not find. exit" << endl;
exit(2);
} else if(!contact.ParseFromIstream(&input)){ // 从输出流中反序列化
cerr << "parser original file error" << endl;
exit(2);
}
PrintContact(contact);
input.close();
return 0;
}
3. 查看二进制信息
①hexdump
hexdump是一种命令行工具,它可以将二进制数据的十六进制表示以及对应的 ASCII 码字符显示出来,使您可以更容易地理解和分析这些数据。
-C:同时显示二进制数据的十六进制表示和 ASCII 码字符。-b参数表示显示八进制数而非十六进制数-n参数表示指定要显示的字节数
② --decode选项
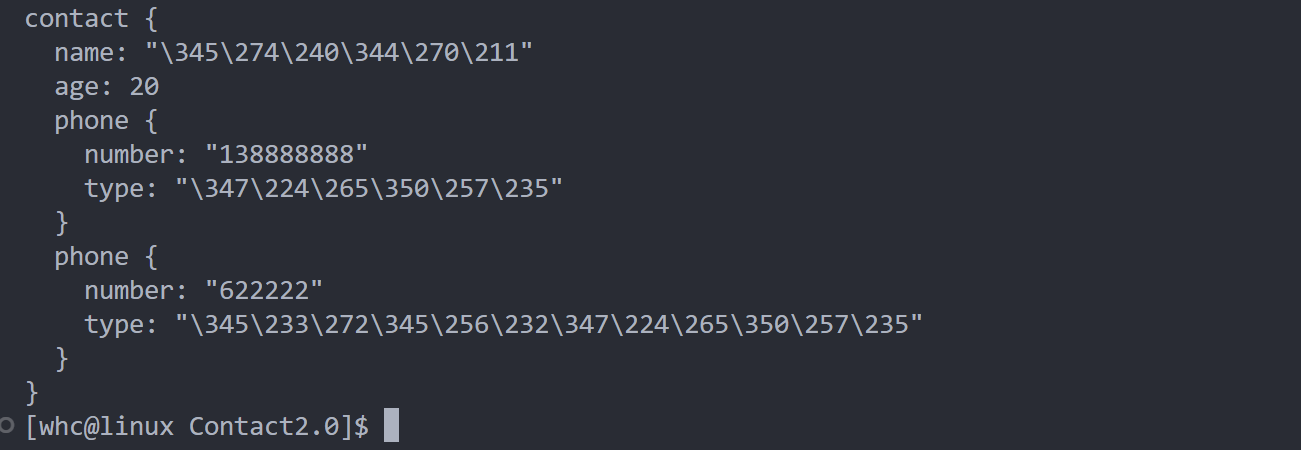
在命令行中输入 protoc -h 便可以看到protoc支持的各种选项,我们现在重点研究 --decode 选项的使用:

这个选项的作用是从标准输入中读取给定类型的二进制消息,并将其以文本的格式写入到标准输出。需要注意的时,消息类型必须在 .proto 文件中定义。下面给出例子:
[whc@linux Contact2.0]$ protoc --decode=contact2.Contact contact.proto < contact.bin
contact2.Contact:指定将字符串解码为 contact2.Contact 消息(contact2是package名)contact.proto:指定包含 contact2.Contact 消息的 .proto 文件为contact.proto< contact.bin:因此–decode是从标准输入中读取二进制消息,因此需要将contact.bin文件中的内容重定向到 protoc 中