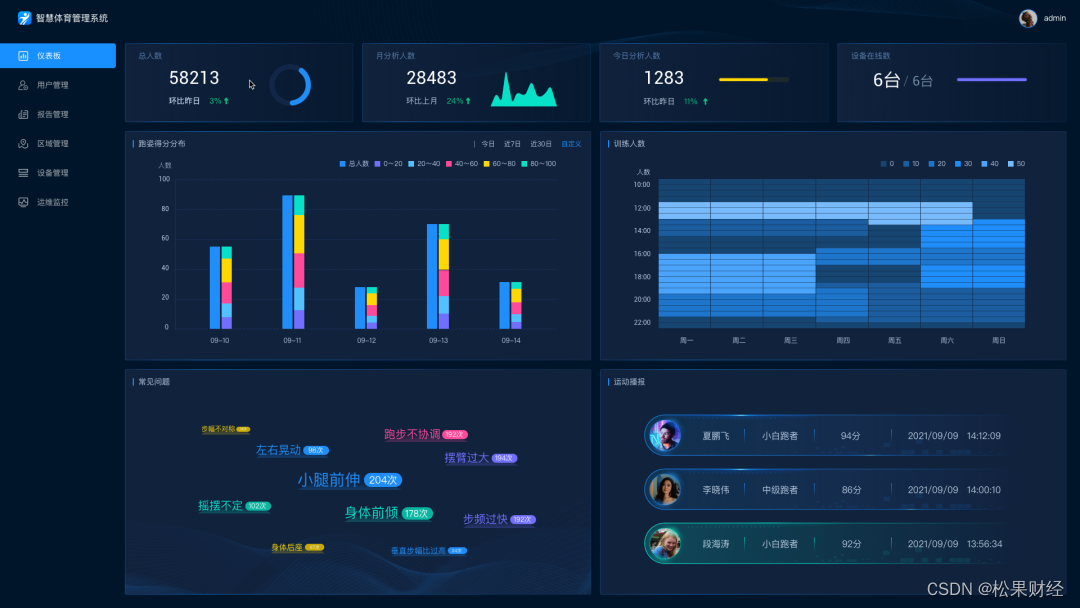
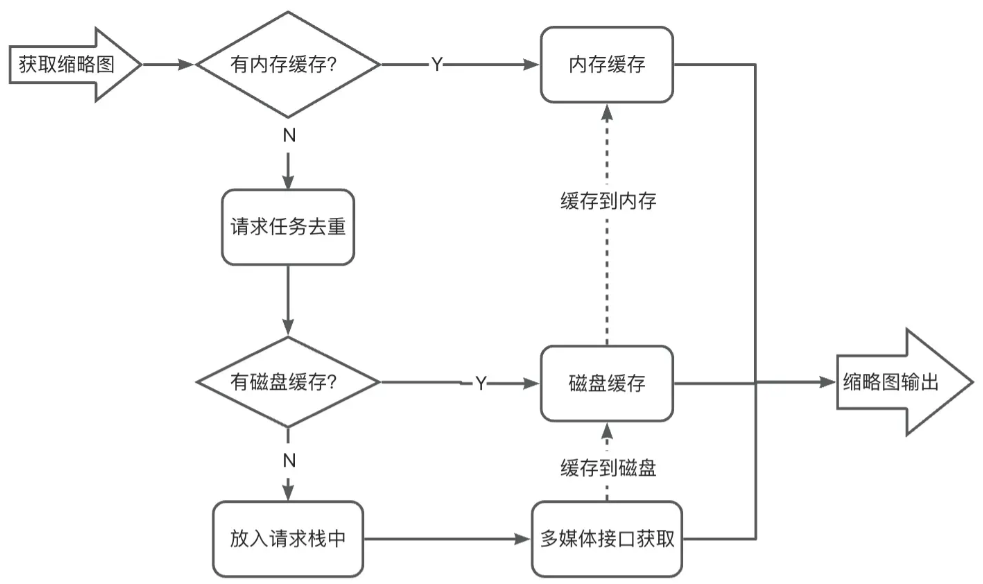
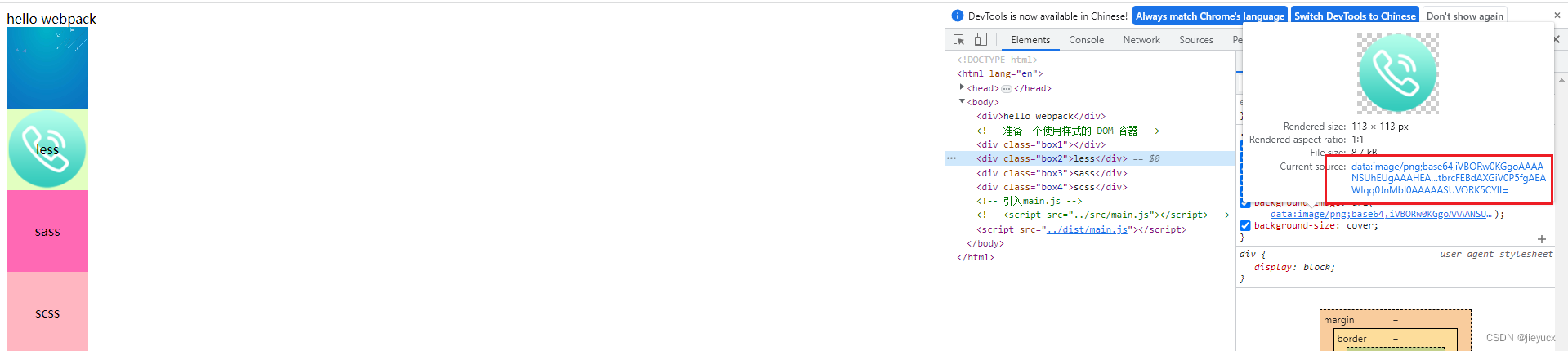
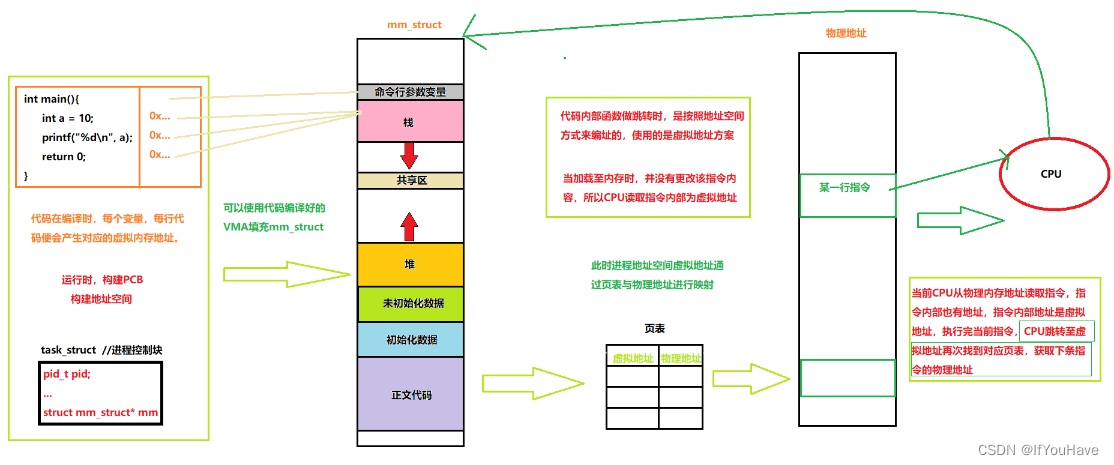
一、详情简介:
1.此文主要研究方向为:基于包含分数的情感词典实现对于各语句的情感分析;
2.情感分析主要基于文本数据,是自然语言处理(NPL)的主要内容。情感分析:又称意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。互联网(如微博、论坛、知乎、豆瓣等)上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。基于此,潜在的用户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。
3.本文采用基于情感词典的方法实现情感分析:具体步骤如下:
(1).整理词典,主要包含正面词,负面词,否定词,强调词
(2).使用网络常用的停用词词典(可参考本项目),并使用jieba进行分词
(3).通过关键词匹配算法,计算最后的得分
目前项目属于算法构建环节,仅整理部分词典,可能出现很多句子无法计算分数的问题,我们将不断进行更新
文案参考资料:https://blog.csdn.net/weixin_41961559/article/details/105237852
二、词典分析和源码分析
词典分为三个部分,如下文所示,text:词语,score:得分,sort为词语的分类
text=极好,score=4.73,sort=positive text=礼品,score=4.33,sort=positive text=礼物,score=4.33,sort=positive源码分析下周...没完成弄完
三.环境部署:
1.需要安装jieba库进行分词
2.下载sws.ini和type.ini词典放在源码目录,然后运行就完事了
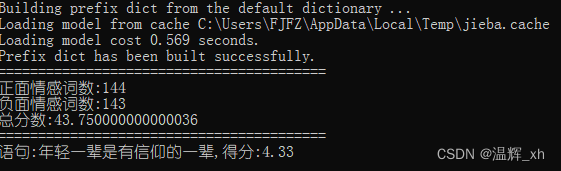
3.项目演示:
源码地址:keyxh/sentiment_analysis: python中文情感分析---基于包含分数的情感词典实现对于各语句的情感分析的方案 (github.com)
Developed by 福州机电工程职业技术学校 wh
邮箱联系方式:xiaohui032901@foxmail.com
qq联系方式:2151335401、3135144152