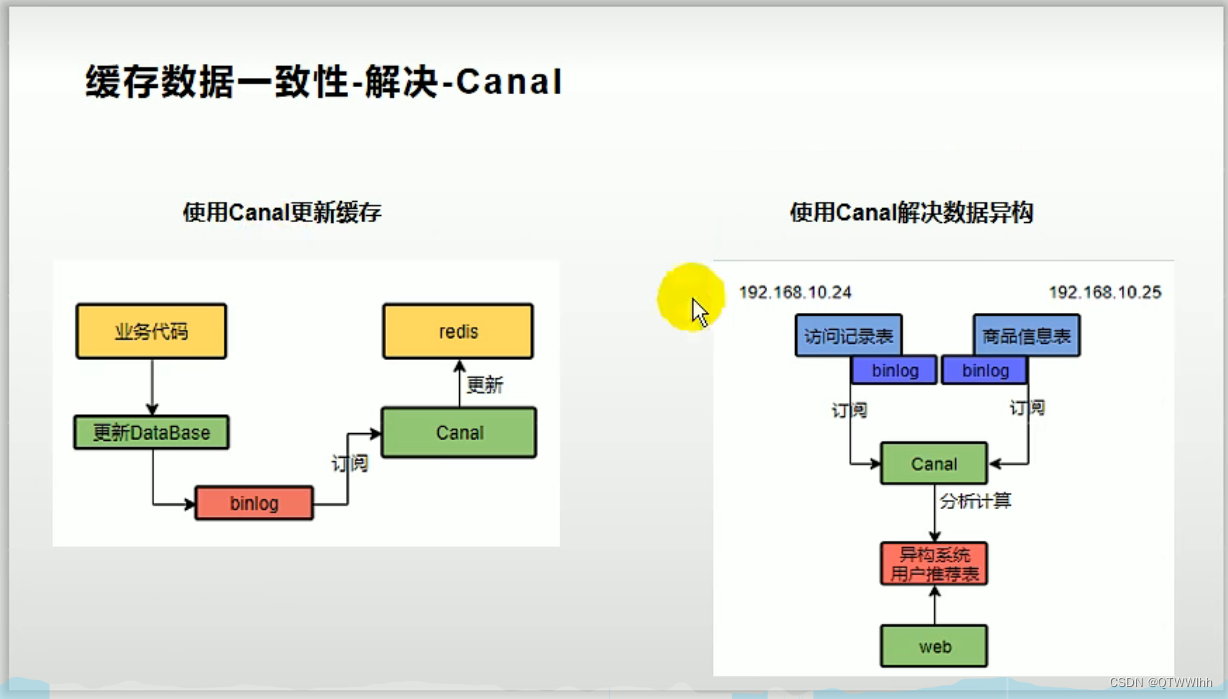
1.TF-IDF原理
tf-idf 是在词袋方法基础上的一种简单扩展,它表示词频 - 逆文档频率。tf-idf 计算的不是数据集中每个单词在每个文档中的原本计数,而是一个归一化的计数,其中每个单词的计数要除以这个单词出现在其中的文档数量。
- 词袋bow(w, d) = 单词 w 在文档 d 中出现的次数
- tf-idf(w, d) = bow(w, d) * N / ( 单词 w 出现在其中的文档数量 )
N 是数据集中的文档总数。分数 N / ( 单词 w 出现在其中的文档的数量 ) 就是所谓的逆文档频率。如果一个单词出现在很多文档中,那么它的逆文档频率就接近于 1。如果一个单词只出现在少数几个文档中,那么它的逆文档频率就会高得多。
也可以使用逆文档频率的对数变换,而不是它的原始形式,那么就可以有效地将一个几乎出现在所有单个文档中的单词的计数归零,而一个只出现在
少数几个文档中的单词的计数将会被放大。即对数变换可以将 1 转换为0,并使大的数值(那些远远大于 1 的值)变小:
- tf-idf(w, d) = bow(w, d) * log(N / 单词 w 出现在其中的文档数量 )
tf-idf 突出了罕见词,并有效地忽略了常见词。
tf-idf 通过乘以一个常数,对单词计数特征进行了转换。因此,它是一种特征缩放方法。比较一下缩放特征和未缩放特征的效果:
练习的目的是比较一下词袋、tf-idf 和 ℓ 2 归一化在线性分类问题中的效果。
1.1数据读取、拼接
import json
import numpy as np
import pandas as pd
from sklearn.feature_extraction import text
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import sklearn.preprocessing as preproc
# 加载商家数据
biz_f = open(r'..\data\yelp_academic_dataset_business.json')
biz_df = pd.DataFrame([json.loads(x) for x in biz_f.readlines()])
biz_f.close()
# 加载点评数据
review_file = open(r'..\data\yelp_academic_dataset_review.json')
review_df = pd.DataFrame([json.loads(x) for x in review_file.readlines()])
review_file.close()
# 选出夜店和餐馆
two_biz = biz_df[biz_df.apply(lambda x: 'Nightlife' in x['categories'] or 'Restaurants' in x['categories'],axis=1)]
two_biz.head(3)
# 与点评数据连接,得到两种类型商家的所有点评
twobiz_reviews = two_biz.merge(review_df, on='business_id', how='inner')
twobiz_reviews.head()
# 去除不需要的特征
twobiz_reviews = twobiz_reviews[['business_id','name','stars_y','text','categories']]
twobiz_reviews.head()
# 创建目标列——夜店类型的商家为True,否则为False
twobiz_reviews['target'] = twobiz_reviews.apply(lambda x: 'Nightlife' in x['categories'],axis=1)
twobiz_reviews.head(20)

序列化特征并保存特征到文件
twobiz_reviews.to_pickle('twobiz_reviews.pkl')
从文件读取序列化特征到程序并转为二维表
twobiz_reviews = pd.read_pickle('twobiz_reviews.pkl')
twobiz_reviews.head(3)

1.2创建分类数据集(拆分数据)
看看能否通过点评数据区分出一个商家是餐馆还是夜店。为了节省训练时间,我们可以取点评数据的一个子集。在这个例子中,两类商家的点评数量相差很大,这称为类别不平衡数据集。不平衡数据集的建模有些问题,因为模型会将大部分努力用于拟合优势类别。因为在两个类别中我们都有很多数据,所以解决这个问题的一种好的做法是对优势类别(餐馆)进行下采样,使它的数量与劣势类别(夜店)基本相当。
- 对夜店点评数据进行 10% 的随机抽样,对餐馆点评数据进行 2.1% 的随机抽样(选择这样的比例可以使两个类别的抽样数据基本相当)。
- 按照 70/30 的比例将这个数据集划分为训练集和测试集。在这个例子中,训练集有 29264 条点评数据,测试集有 12 542 条点评数据。
- 训练数据包含 46 924 个唯一单词,这就是词袋表示法的特征数量。
# 创建一个类别平衡的子样本,供练习使用
nightlife = twobiz_reviews[twobiz_reviews.apply(lambda x: 'Nightlife' in x['categories'], axis=1)]
restaurants = twobiz_reviews[twobiz_reviews.apply(lambda x: 'Restaurants' in x['categories'], axis=1)]
#如下目前类别极度不平衡
print(nightlife.shape)
print(restaurants.shape)
# 进行随机取样,达到类别平衡
nightlife_subset = nightlife.sample(frac=0.1, random_state=123)
restaurant_subset = restaurants.sample(frac=0.021, random_state=123)
print(nightlife_subset.shape)
print(restaurant_subset.shape)
# 序列化:
nightlife_subset.to_pickle('nightlife_subset.pkl')
restaurant_subset.to_pickle('restaurant_subset.pkl')
nightlife_subset = pd.read_pickle('nightlife_subset.pkl')
restaurant_subset = pd.read_pickle('restaurant_subset.pkl')
# 拼接两个类型的店起来:
combined = pd.concat([nightlife_subset, restaurant_subset])
combined['target'] = combined.apply(lambda x: 'Nightlife' in x['categories'],axis=1)#添加一列作为标签
combined
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
training_data, test_data = train_test_split(combined, train_size=0.7, random_state=123)
print(training_data.shape)
print(test_data.shape)
1.3使用tf-idf变换来缩放词袋
做完 tf-idf 后再进行 ℓ 2 归一化等同于只做 ℓ2归一化。所以,我们只需要测试三组特征:词袋、tf-idf,以及词袋基础上的 ℓ 2 归一化。
# 用词袋表示点评文本
bow_transform = text.CountVectorizer()
X_tr_bow = bow_transform.fit_transform(training_data['text'])
X_te_bow = bow_transform.transform(test_data['text'])
y_tr = training_data['target']
y_te = test_data['target']
# 使用词袋矩阵创建tf-idf表示
tfidf_trfm = text.TfidfTransformer(norm=None)
X_tr_tfidf = tfidf_trfm.fit_transform(X_tr_bow)
X_te_tfidf = tfidf_trfm.transform(X_te_bow)
# 对词袋表示进行l2归一化
X_tr_l2 = preproc.normalize(X_tr_bow, axis=0)
X_te_l2 = preproc.normalize(X_te_bow, axis=0)
特征缩放的微妙之处在于,它要求我们知道一些实际中我们很可能不知道的特征统计量,比如均值、方差、文档频率、ℓ 2 范数,等等。为了计算出 tf-idf表示,我们必须基于训练数据计算出逆文档频率,并用这些统计量既缩放训练数据也缩放测试数据。
在 scikit-learn 中,在训练数据上拟合特征转换器相当于收集相关统计量。然后可以将拟合好的特征转换器应用到测试数据上。特征缩放的微妙之处在于,它要求我们知道一些实际中我们很可能不知道的特征统计量,比如均值、方差、文档频率、ℓ 2 范数,等等。
为了计算出 tf-idf表示,我们必须基于训练数据计算出逆文档频率,并用这些统计量既缩放训练数据也缩放测试数据。在 scikit-learn 中,在训练数据上拟合特征转换器相当于收集相关统计量。然后可以将拟合好的特征转换器应用到测试数据上。
1.4使用逻辑回归进行分类
# 使用不同的特征(上面那三种)进行逻辑回归分类:
def simple_logistic_classify(X_tr, y_tr, X_test, y_test, description, _C=1.0):
## 函数训练一个逻辑分类器,并对测试数据进行评分
m = LogisticRegression(C=_C).fit(X_tr, y_tr)
s = m.score(X_test, y_test)
print ('Test score with', description, 'features:', s)
return m
m1 = simple_logistic_classify(X_tr_bow, y_tr, X_te_bow, y_te, 'bow')
m2 = simple_logistic_classify(X_tr_l2, y_tr, X_te_l2, y_te, 'l2-normalized')
m3 = simple_logistic_classify(X_tr_tfidf, y_tr, X_te_tfidf, y_te, 'tf-idf')
1.5使用正则化对逻辑回归进行调参优化
当特征数量大于数据点数量时,找出最佳模型这个问题就变得不确定了。解决这个问题的一种方法是在训练过程中加入额外的限制条件,这就是正则化。
种基本的超参数调优方法称为网格搜索:先确定一个超参数网格,然后使用调优程序自动搜索,找到网格中的最优超参数设置。找到最优超参数设置之后,你可以使用该设置在整个训练集上训练一个模型,然后使用它在测试集上的表现作为这类模型的最终评价。(这里要调正则化参数)
tf-idf 和词袋之间的准确度差别是否是由噪声造成的。为此,我们使用k-折交叉验证来模拟多个统计独立的数据集,把数据集分成 k 折。交叉验证过程会在这些
数据子集中迭代进行,使用除一折数据之外的所有数据进行训练,而用保留的那一折数据来验证结果。
# 使用网格搜索对逻辑回归进行调优
import sklearn.model_selection as modsel
param_grid_ = {'C': [1e-5, 1e-3, 1e-1, 1e0, 1e1, 1e2]}
# 为词袋表示法进行分类器调优
bow_search = modsel.GridSearchCV(LogisticRegression(), cv=5, param_grid=param_grid_)
# 为L2-归一化词向量进行分类器调优
l2_search = modsel.GridSearchCV(LogisticRegression(), cv=5,param_grid=param_grid_)
# 为tf-idf进行分类器调优
tfidf_search = modsel.GridSearchCV(LogisticRegression(), cv=5,param_grid=param_grid_)
1.5.1为词袋表示法进行分类器调优
bow_search.fit(X_tr_bow, y_tr)
print(bow_search.best_score_)
bow_search.best_params_
1.5.2为L2-归一化词向量进行分类器调优
l2_search.fit(X_tr_bow, y_tr)
print(l2_search.best_score_)
l2_search.best_params_
1.5.3为tf-idf进行分类器调优
tfidf_search.fit(X_tr_bow, y_tr)
print(tfidf_search.best_score_)
tfidf_search.best_params_
1.5.4可以查看网格所受的cv结果看看它的过程
bow_search.cv_results_
l2_search.cv_results_
tfidf_search.cv_results_
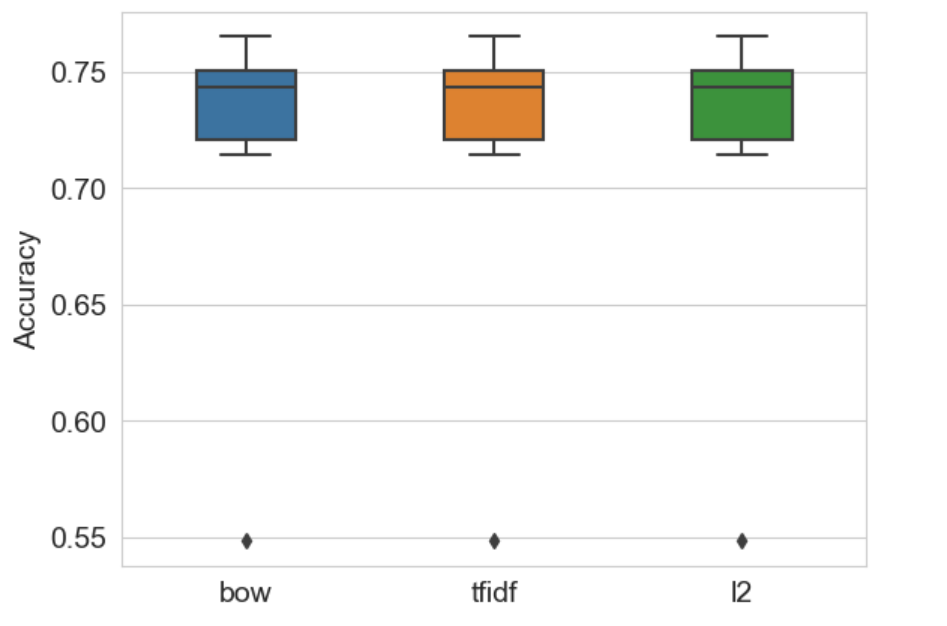
1.5.5对三个分类器性能进行可视化比较
# 对三个分类器性能进行可视化比较
search_results = pd.DataFrame.from_dict({'bow': bow_search.cv_results_['mean_test_score'],
'tfidf': tfidf_search.cv_results_['mean_test_score'],
'l2': l2_search.cv_results_['mean_test_score']})
search_results

%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("whitegrid")
ax = sns.boxplot(data=search_results, width=0.4)
ax.set_ylabel('Accuracy', size=14)
ax.tick_params(labelsize=14)
plt.savefig('tfidf_gridcv_results.png')
# 如下
1.5.6使用最佳参数去拟合模型
# 使用最佳参数去拟合模型
m1 = simple_logistic_classify(X_tr_bow, y_tr, X_te_bow, y_te, 'bow',
_C=bow_search.best_params_['C'])
m2 = simple_logistic_classify(X_tr_l2, y_tr, X_te_l2, y_te, 'l2-normalized',
_C=l2_search.best_params_['C'])
m3 = simple_logistic_classify(X_tr_tfidf, y_tr, X_te_tfidf, y_te, 'tf-idf',
_C=tfidf_search.best_params_['C'])
Test score with bow features: 0.7682606410930111
Test score with l2-normalized features: 0.6784025223331581
Test score with tf-idf features: 0.766684182869154