文章目录
- 一,提出任务
- 二,实现思路
- 三,准备工作
- 1、在本地创建用户文件
- 2、将用户文件上传到HDFS指定位置
- 四,完成任务
- 1、在Spark Shell里完成任务
- (1)读取文件,得到RDD
- (2)倒排,互换RDD中元组的元素顺序
- (3)倒排后的RDD按键分组
- (4)取分组后的日期集合最小值,计数为1
- (5)按键计数,得到每日新增用户数
- (6)让输出结果按日期升序
- 2、在IntelliJ IDEA里完成任务
- (1)打开RDD项目
- (2)创建统计新增用户对象
- (3)运行程序,查看结果
一,提出任务
已知有以下用户访问历史数据,第一列为用户访问网站的日期,第二列为用户名。
2023-05-01,mike
2023-05-01,alice
2023-05-01,brown
2023-05-02,mike
2023-05-02,alice
2023-05-02,green
2023-05-03,alice
2023-05-03,smith
2023-05-03,brian
| - - | - - | - - | - - |
|---|---|---|---|
| 2023-05-01 | mike | alice | brown |
| 2023-05-02 | mike | alice | green |
| 2023-05-03 | alice | smith | brian |
现需要根据上述数据统计每日新增的用户数量,期望统计结果。
2023-05-01新增用户数:3
2023-05-02新增用户数:1
2023-05-03新增用户数:2
即2023-05-01新增了3个用户(分别为mike、alice、brown),2023-05-02新增了1个用户(green),2023-05-03新增了两个用户(分别为smith、brian)。
二,实现思路
使用倒排索引法,若将用户名看作关键词,访问日期看作文档ID,则用户名与访问日期的映射关系如下图所示。
| - | 2023-05-01 | 2023-05-02 | 2023-05-3 |
|---|---|---|---|
| mike | √ | √ | |
| alice | √ | √ | √ |
| brown | √ | ||
| green | √ | ||
| smith | √ | ||
| brian | √ |
若同一个用户对应多个访问日期,则最小的日期为该用户的注册日期,即新增日期,其他日期为重复访问日期,不应统计在内。因此每个用户应该只计算用户访问的最小日期即可。如下图所示,将每个用户访问的最小日期都移到第一列,第一列为有效数据,只统计第一列中每个日期的出现次数,即为对应日期的新增用户数。
| - | 列一 | 列二 | 列三 |
|---|---|---|---|
| mike | 2023-05-01 | 2023-05-02 | |
| alice | 2023-05-01 | 2022-01-02 | 2022-01-03 |
| brown | 2023-05-01 | ||
| green | 2023-05-02 | ||
| smith | 2023-05-03 | ||
| brian | 2023-05-03 |
三,准备工作
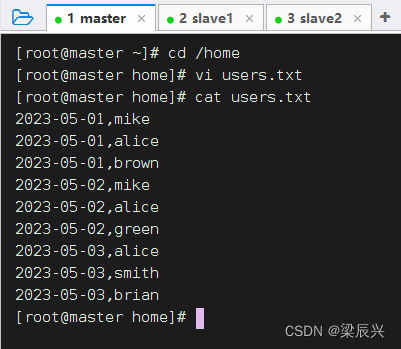
1、在本地创建用户文件
在/home目录里创建users.txt文件
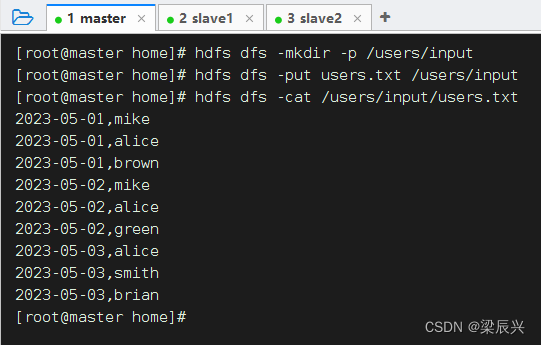
2、将用户文件上传到HDFS指定位置
先在HDFS中创建/users/input目录,再将用户文件上传到该目录
四,完成任务
1、在Spark Shell里完成任务
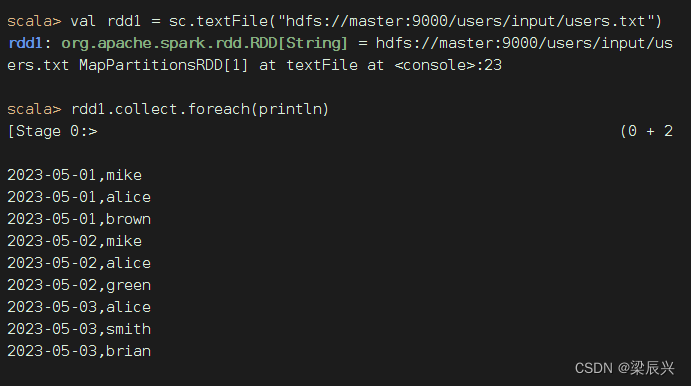
(1)读取文件,得到RDD
执行命令:val rdd1 = sc.textFile("hdfs://master:9000/users/input/users.txt")
(2)倒排,互换RDD中元组的元素顺序
val rdd2 = rdd1.map(
line => {
val fields = line.split(",")
(fields(1), fields(0))
}
)
rdd2.collect.foreach(println)
执行上述语句

(3)倒排后的RDD按键分组
执行命令:val rdd3 = rdd2.groupByKey()
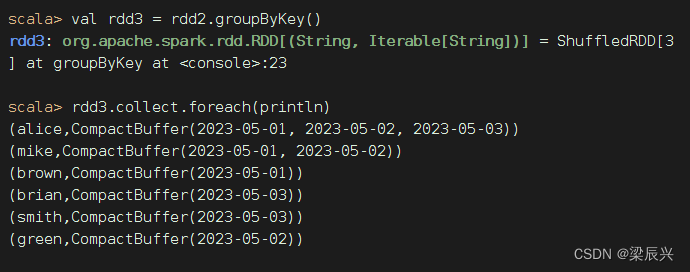
(4)取分组后的日期集合最小值,计数为1
执行命令:val rdd4 = rdd3.map(line => (line._2.min, 1))
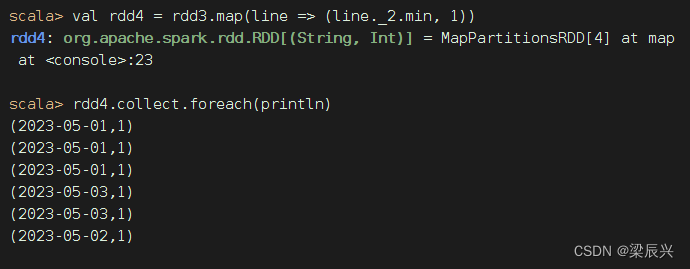
(5)按键计数,得到每日新增用户数
执行命令:val result = rdd4.countByKey()

执行命令:result.keys.foreach(key => println(key + "新增用户:" + result(key)))
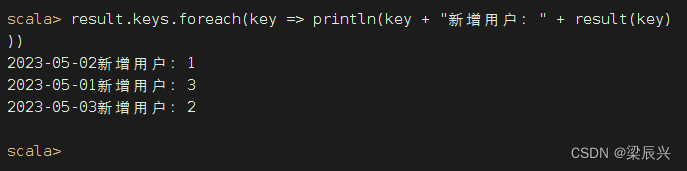
(6)让输出结果按日期升序
映射不能直接排序,只能让键集转成列表之后先排序,再遍历键集输出映射
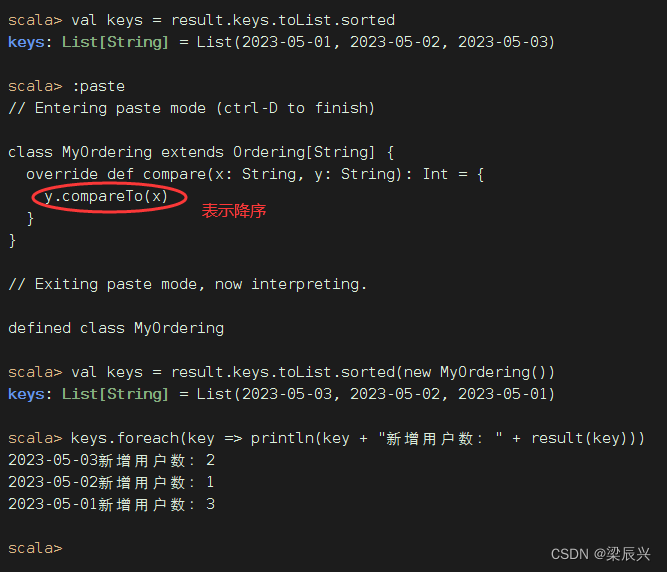
执行命令:val keys = result.keys.toList.sorted,让键集升序排列
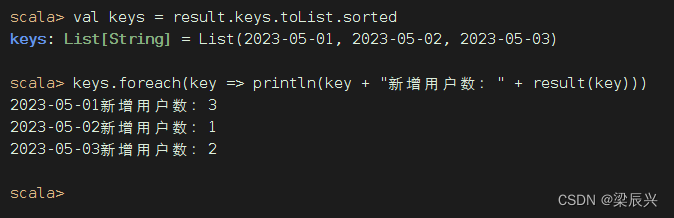 按日期降序
按日期降序
2、在IntelliJ IDEA里完成任务
(1)打开RDD项目
SparkRDDDemo
(2)创建统计新增用户对象
在net.army.day07包里创建CountNewUsers对象
package net.army.rdd.day07
import org.apache.spark.{SparkConf, SparkContext}
/**
* 作者:梁辰兴
* 日期:2023/6/6
* 功能:统计新增用户
*/
object CountNewUsers {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CountNewUsers") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取文件,得到RDD
val rdd1 = sc.textFile("hdfs://master:9000/users/input/users.txt")
// 倒排,互换RDD中元组的元素顺序
val rdd2 = rdd1.map(
line => {
val fields = line.split(",")
(fields(1), fields(0))
}
)
// 倒排后的RDD按键分组
val rdd3 = rdd2.groupByKey()
// 取分组后的日期集合最小值,计数为1
val rdd4 = rdd3.map(line => (line._2.min, 1))
// 按键计数,得到每日新增用户数
val result = rdd4.countByKey()
// 让统计结果按日期升序
val keys = result.keys.toList.sorted
keys.foreach(key => println(key + "新增用户:" + result(key)))
// 停止Spark容器
sc.stop()
}
}
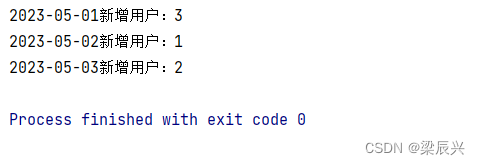
(3)运行程序,查看结果
运行程序CountNewUsers,控制台结果




![[BUUOJ] [RE] [ACTF新生赛2020] rome1](https://img-blog.csdnimg.cn/cbc76794d3094d46b6052ce3c7eccfd1.png)