本篇文章简要阐述MMU的概念,以及以段地址的转换过程为例,简单说明MMU将虚拟地址转换成物理地址的过程。更多详细内容请查看《ARM-MMU(中文手册).pdf》。
1、MMU概述
在ARM存储系统中,使用MMU实现虚拟地址到实际物理地址的映射。为何要实现这种映射?
首先就要从一个嵌入式系统的基本构成和运行方式着手。系统上电时,处理器的程序指针从0x0(或者是由0Xffff_0000处高端启动)处启动,顺序执行程序,在程序指针(PC)启动地址,属于非易失性存储器空间范围,如ROM、FLASH等。然而与上百兆的嵌入式处理器相比,FLASH、ROM等存储器响应速度慢,已成为提高系统性能的一个瓶颈。而SDRAM具有很高的响应速度,为何不使用SDRAM来执行程序呢?为了提高系统整体速度,可以这样设想,利用FLASH、ROM对系统进行配置,把真正的应用程序下载到SDRAM中运行,这样就可以提高系统的性能。然而这种想法又遇到了另外一个问题,当ARM处理器响应异常事件时,程序指针将要跳转到一个确定的位置,假设发生了IRQ中断,PC将指向0x18(如果为高端启动,则相应指向0vxffff_0018处),而此时0x18处仍为非易失性存储器所占据的位置,则程序的执行还是有一部分要在FLASH或者ROM中来执行的。那么我们可不可以使程序完全都SDRAM中运行那?答案是肯定的,这就引入了MMU,利用MMU,可把SDRAM的地址完全映射到0x0起始的一片连续地址空间,而把原来占据这片空间的FLASH或者ROM映射到其它不相冲突的存储空间位置。例如,FLASH的地址从0x0000_0000-0x00ff_ffff,而SDRAM的地址范围是0x3000_0000-0x31ff_ffff,则可把SDRAM地址映射为0x0000_0000-0x1fff_ffff而FLASH的地址可以映射到0x9000_0000-0x90ff_ffff(此处地址空间为空闲,未被占用)。映射完成后,如果处理器发生异常,假设依然为IRQ中断,PC指针指向0x18处的地址,而这个时候PC实际上是从位于物理地址的0x3000_0018处读取指令。通过MMU的映射,则可实现程序完全运行在SDRAM之中。
在实际的应用中,可能会把两片不连续的物理地址空间分配给SDRAM。而在操作系统中,习惯于把SDRAM的空间连续起来,方便内存管理,且应用程序申请大块的内存时,操作系统内核也可方便地分配。通过MMU可实现不连续的物理地址空间映射为连续的虚拟地址空间。
操作系统内核或者一些比较关键的代码,一般是不希望被用户应用程序所访问的。通过MMU可以控制地址空间的访问权限,从而保护这些代码不被破坏。
2、MMU地址映射的实现
MMU的实现过程,实际上就是一个查表映射的过程。建立页表(translate table)是实现MMU功能不可缺少的一步。页表是位于系统的内存中,页表的每一项对应于一个虚拟地址到物理地址的映射。每一项的长度即是一个字的长度(在ARM中,一个字的长度被定义为4字节)。页表项除完成虚拟地址到物理地址的映射功能之外,还定义了访问权限和缓冲特性等。
2.1 映射存储块的分类
MMU 支持基于节或页的存储器访问, MMU 可以用下面四种大小进行映射:
节 ( Section ) 构成 1MB 的存储器块。
微页 ( Tiny page ) 构成 1KB 的存储器块。
小页 ( Small page ) 构成 4KB 的存储器块。
大页 ( Large page ) 构成 64KB 的存储器块。
其中对于节映射使用一级转换表就可以了,而对于微页、小页、大页则需要使用两级转换表。
2.2 转换过程
要知道虚拟内存机制必须了解ARM9中的3种地址:VA(虚地址),MVA(修正后虚地址),PA(物理地址)
1)VA,是程序中的逻辑地址,0x00000000~0xFFFFFFFF。
2)MVA,是修改后的虚拟地址。在ARM9里面,如果VA<32M,利用进程标识号PID转换得到MVA。过程如下:
if(VA < 32M)
MVA = VA | ( PID<<25 )
else
MVA = VA
只是上面的过程是由硬件实现的。这样为VA进行了一级映射,为什么呢?在linux系统里,每个进程的地址空间0-4G,0-3G是进程独有的,称为用户空间,3G-4G是系统的,称为内核空间,所有进程共享。如果两个进程所用的VA有重叠,在切换进程时,为了把重叠的VA映射到不同的PA上,需要重建页表、使无效caches和TLBS。使用了MVA,使进程在VA相同的情况下,使用不同的MVA,进而PA也不同。这就是在VA与PA之间加上一次到MVA的映射的意义。
3)PA,物理地址,MVA通过MMU转换后的地址。
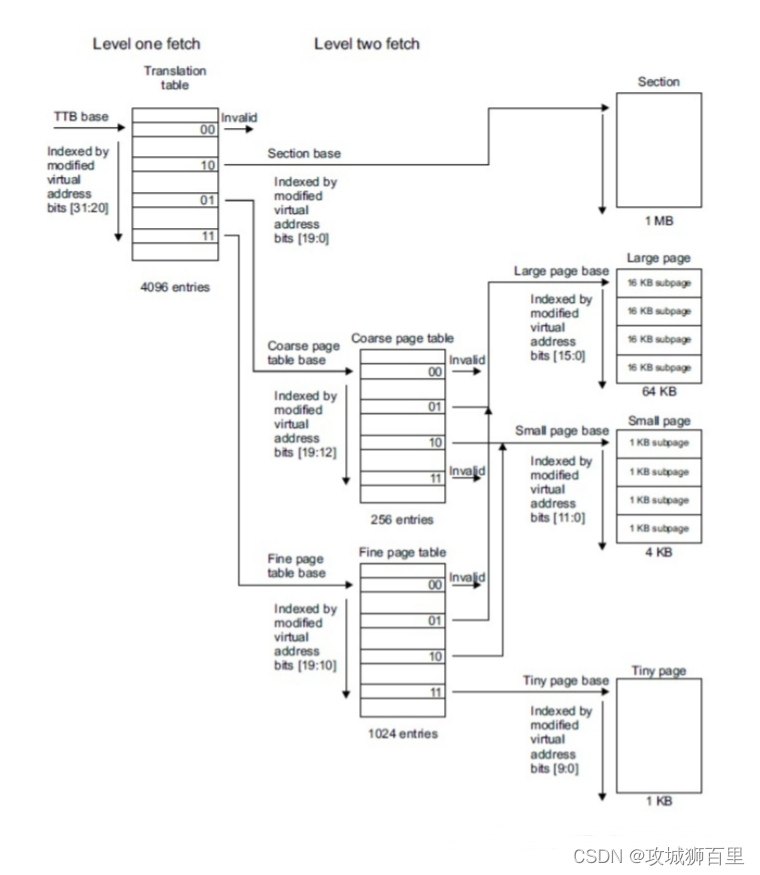
一级页表使用 4096 个描述符来表示 4GB 空间,每个描述符对应 1MB 的虚拟地址,存储它对应的 1MB 物理空间的起始地址,或者存储下一级页表的地址。每个描述符占 4 个字节,格式如下:
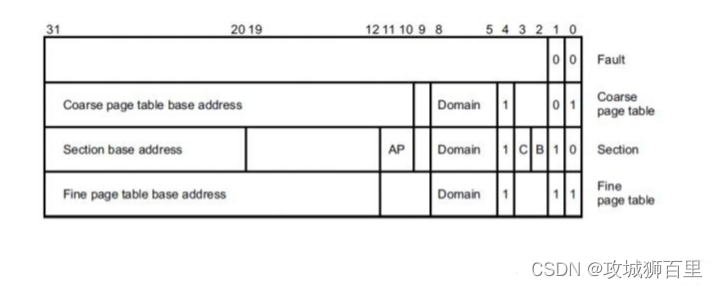
使用 MVA[31:20]来索引一级页表(20-31 一共 12 位,2^12=4096,所以是4096 个描述符)。其中段地址的转换流程如下图所示:
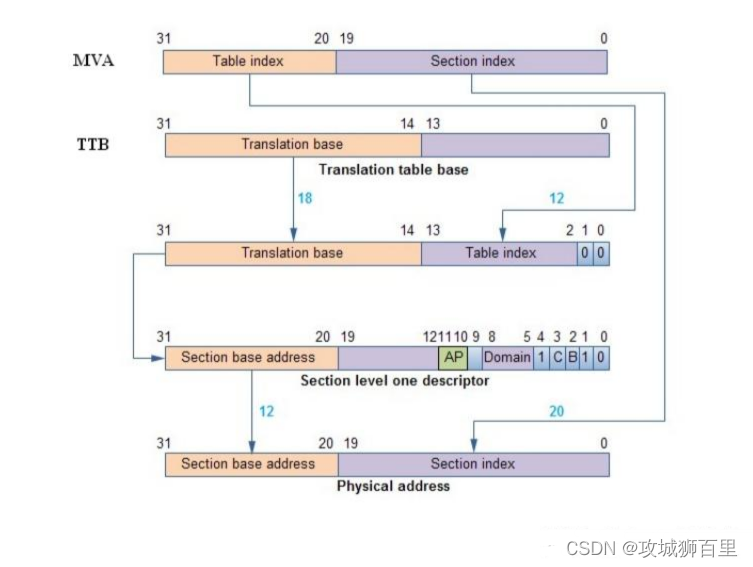
①页表基址寄存器位[31:14]和 MVA[31:20]组成一个低两位为 0 的 32 位地址, MMU 利用这个地址找到段描述符。
②取出段描述符的位[31:20](段基址,section base address),它和 MVA[19:0]组成一个 32 位的物理地址(这就是 MVA 对应的 PA)
2.3 TLB
从MVA 到 PA 的转换需要访问多次内存,大大降低了 CPU 的性能,有没有办法改进呢?
程序执行过程中,用到的指令和数据的地址往往集中在一个很小的范围内,其中的地址、数据经常使用,这是程序访问的局部性。由此,通过使用一个高速、容量相对较小的存储器来存储近期用到的页表条目(段、大页、小页、极小页描述符),避免每次地址转换都到主存中查找,这样就大幅提高性能。这个存储器用来帮助快速地进行地址转换,成为转译查找缓存(Translation Lookaside Buffers, TLB)。
当 CPU 发出一个虚拟地址时,MMU 首先访问 TLB。如果 TLB 中含有能转换这个虚拟地址的描述符,则直接利用此描述符进行地址转换和权限检查,否则 MMU 访问页表找到描述符后再进行地址转换和权限检查,并将这个描述符填入TLB 中,下次再使用这个虚拟地址时就直接使用 TLB 用的描述符。
若转换成功,则称为”命中”。Linux 系统中,目前的”命中”率高达 90%以上,使分页机制带来的性能损失降低到了可接收的程度。若在 TLB 中进行查表转换失败,则退缩为一般的地址变换,概率小于 10%。
Linux内核 学习教程:https://ke.qq.com/course/4032547?flowToken=1040348
Linux内核 学习资料 面试题、学习资料、教学视频和学习路线图,免费分享有需要的可以自行添加学习交流群: 739729163 领取