前言
MMPretrain是一款基于pytorch的开源深度学习预训练工具箱,是OenMMLab的项目成员之一。它是一个全新升级的预训练开源算法框架,旨在提供各种强大的预训练主干网络,并支持了不同的预训练策略。
一、MMPretrain算法库介绍
MMPretrain 源自 MMClassification 和 MMSelfSup,并开发了许多令人兴奋的新功能。目前,预训练阶段对于视觉识别至关重要,凭借丰富而强大的预训练模型,我们能够改进各种下游视觉任务。我们的代码库旨在成为一个易于使用和用户友好的代码库,并简化学术研究活动和工程任务。
算法库与任务组成

Python推理API
支持开箱即用的推理 API 和模型,包含丰富的相关任务:
- 图像分类(Image Classification)
- 图像描述(lmage Caption)
- 视觉问答(Visual Question Answering)
- 视觉定位 (Visual Grounding)
- 检索(Retrieval, Image-To-lmage, Text-To-lmage, Image-To-Text)

环境搭建
# 基础安装
conda create -n open-mmlab python=3.8
pytorch==1.10.1 torchvision==0.11.2 cudatoolkit=11.3 -c -y
conda activate open-mmlab
pip install openmim
git clone http://github.com/open-mmlab/mmpretrain.git
cd mmpretrain
mim install -e.
# 多模态依赖
mim install -e".[multimodal]"代码框架

二、经典主干网络
- AlexNet (2012)
- VGG (2014)
- GoogLeNet (2014)
- ResNet(2016)
- Vision Transformer(2020)
Vision Transformer
- 将图像切分成若干 16x16 的小块,所有块排列成"词向量",先经过线性层映射,一张 [H,W,C] 维度的图片变为[LC],再经多层 Transformer Encoder 的计算产生相应的特征向量
- 图块之外加入额外的 token,用于 query 其他 patch 的特征并给出最后分类
- 注意力模块基于全局感受野,复杂度为尺寸的 4 次方

注意力机制
实现层次化特征:后层特征是空间邻域内的前层特征的加权求和权重越大,对应位置的特征就越重要

三、自监督学习
自监督学习常见学习类型

SimCLR(ICML2020)
基本假设:如果模型能很好地提取图片内容的本质,那么无论图片经过什么样的数据增强操作,提取出来的特征都应该极为相似。
即:对于某种图片x,对它进行两次数据增强,得到x1和x2,x1和x2互为正样本,其他图片的增强结果都是x,和x的负样本
MAE(CVPR2022)
基本假设: 模型只有理解图片内容、掌握图片的上下文信息,才能恢复出图片中被随机遮挡的内容。
将遮蔽的图像块 (只包含位置信息)按原来的位置插入特征向量中

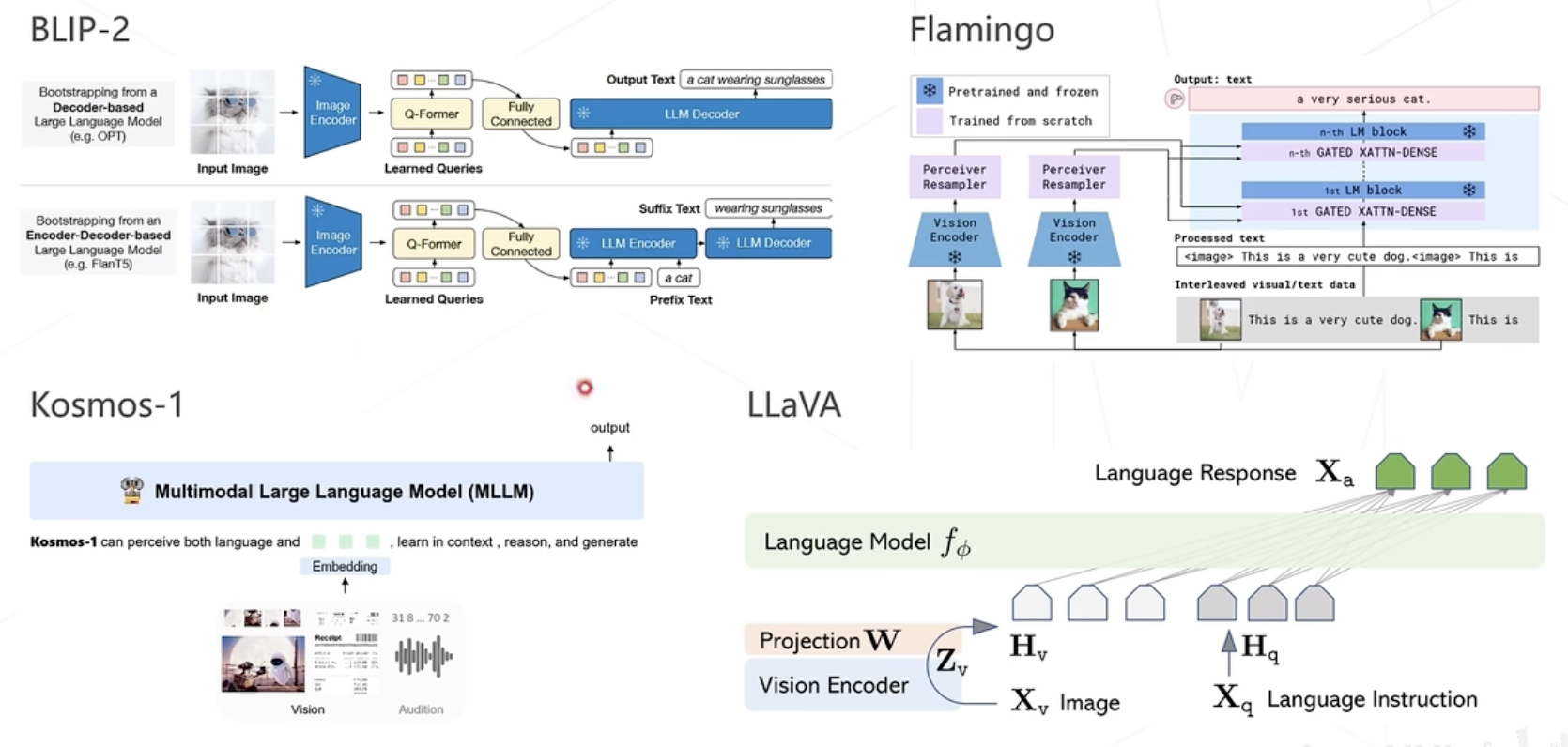
四、多模态算法
CLIP(ICML 2021)

- 在大规模数据集上使用NLP监督预训练图像分类器,证明了简单的预训练任务,即预测图像和文本描述是否相匹配是一种有效的、可扩展的方法
- 用4亿对来自网络的图文数据对,将文本作为图像标签,进行训练。进行下游任务时,只需要提供和图像对应的文本描述,就可以进行 zero-shot transfer,并取得可观的结果
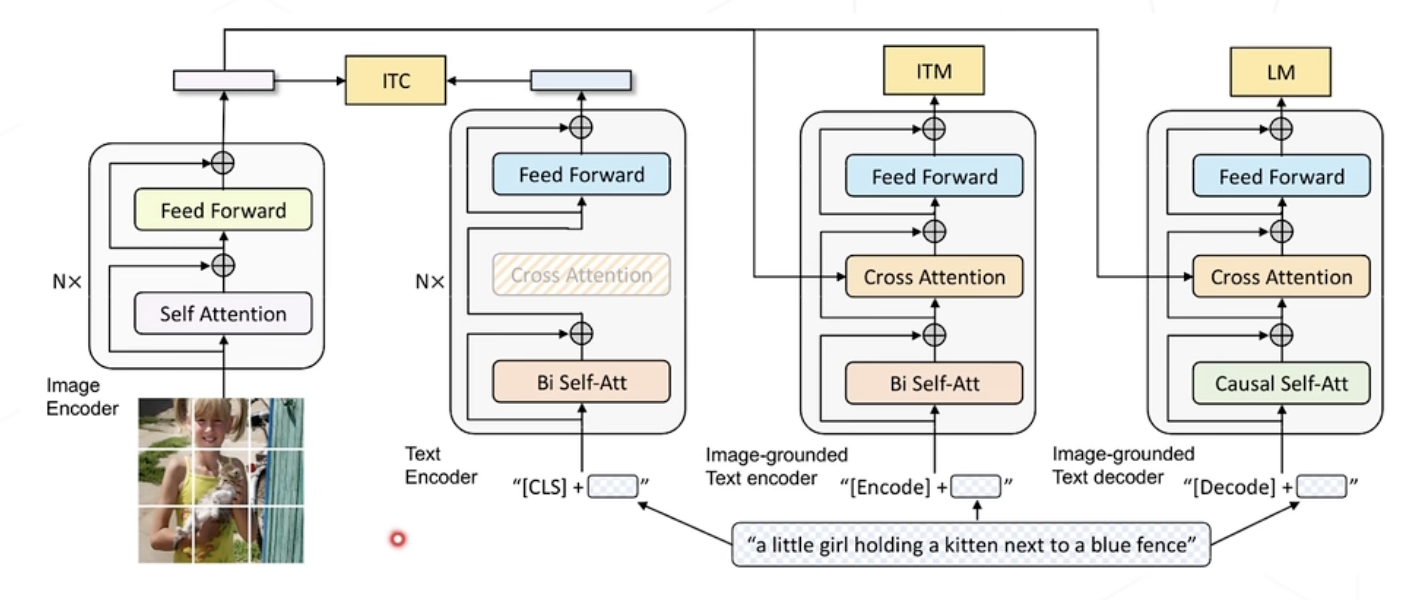
BLIP(ICML 2022)