基本概念:
一)开发效率也就是我们使用这款框架开发的速度快不快,是否简单好用易上手。从这个角度思考,每当我们需要编写一个SQL需求的时候,我们需要做几步
1)Mapper接口提供一个抽象方法
2)Mapper接口对应的映射配置文件提供对应的标签和SQL语句3)在Service中依赖Mapper实例对象
4)调用Mapper实例中的方法
5)在Controller中依赖Service实例对象
6)调用Service实例中的方法
通过上面的发现,对于一个SQL需求,无论是单表还是多表,我们是需要完成如上几步,才能实现SQL需求的开发二)但是在开发中,有一些操作是通用逻辑,这些通用逻辑是可以被简化的,例如:
1)对于dao,是否可以由框架帮我们提供好单表的Mapper抽象方法,和对应的SQL实现,不需要程序员去实现这些
2)对于service,使用可以有框架直接帮我们提供好一些service的抽象方法,和对应的实现,不需要程序员去实现这些MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生
1)先进行扫描所操作的实体类;
2)然后通过反射技术来将实体类中的属性进行抽取;
3)接下来分析表和实体类之间的关系,属性和字段之间的关系,Mybatis提供了通用的mapper以及通用的service;
4)通过调用的方法来实现对应的SQL语句,最后再将生成的SQL语句注入到MyBatis-plus容器中实现最终的功能;

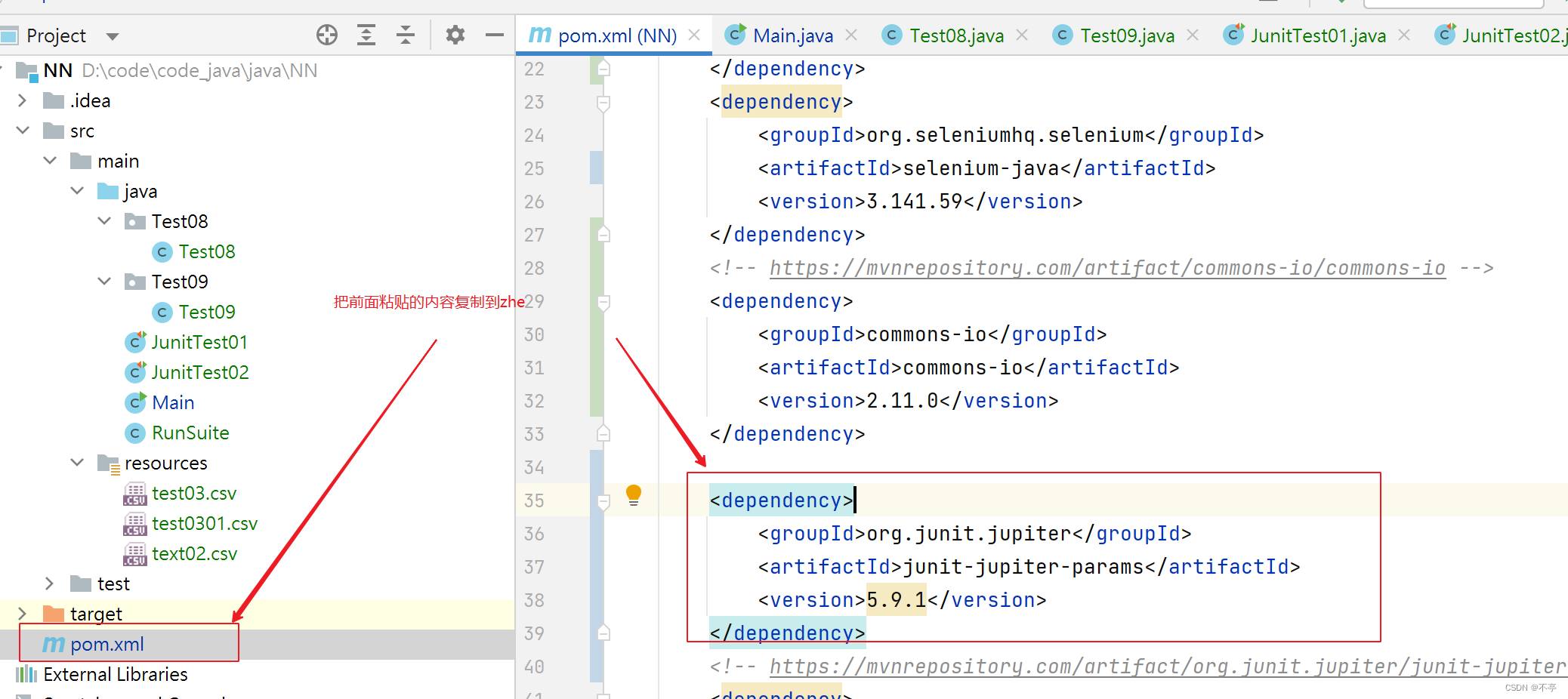
下面是引入的依赖:
<dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.3</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.2.8</version> </dependency>
编写Mapper接口和实体类:
@Mapper public interface UserMapper extends BaseMapper<User> {} mybatis-plus为我们提供了通用的mapper和通用的service@Data @TableName("user")//最终SQL语句中指定TableName进行查询 public class User { private int userID; private String username; private String password; }直接注入mapper对象实现增删改查:
当进行调用mapper.insert(user)方法的时候,即可以向数据库中成功的添加user对象,还可以获取到自增主键
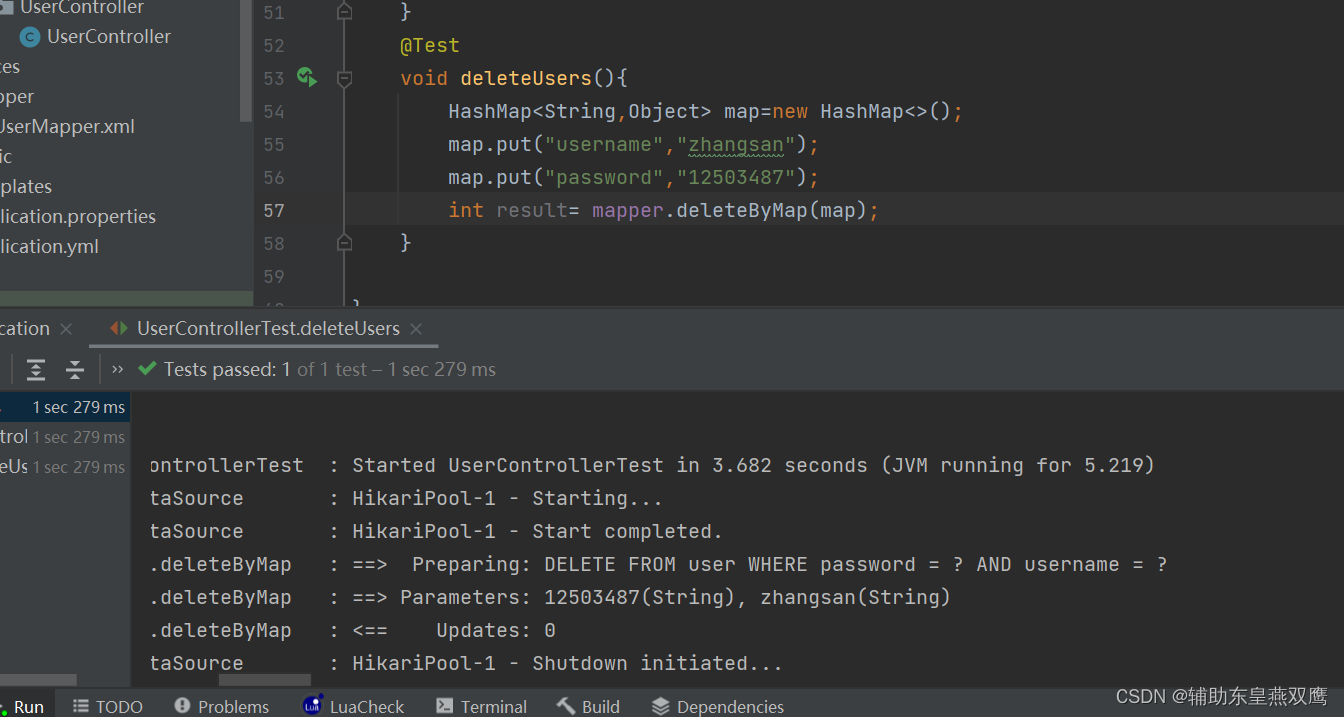
@Controller public class UserController { @Autowired private UserMapper mapper; @Autowired private UserService service; //1.直接注入mapper对象完成修改,查询所有User对象 @RequestMapping("/Java100") @ResponseBody public List<User> SelectUsers(){ return mapper.selectList(null); } //2.直接注入mapper对象完成添加功能添加user对象 @RequestMapping("/Java200") @ResponseBody public String InsertUser(@RequestBody User user){ int len= mapper.insert(user); if(len==1) { return "添加成功"; }else{ return "添加失败"; } } //3.注入mapper对象来删除user对象 @RequestMapping("/Java300") @ResponseBody public Integer DeleteUser(Integer userID){ int len=mapper.deleteById(userID); return len; } //4.直接注入mapper对象来修改user对象 @RequestMapping("/Java400") @ResponseBody public Integer UpDateUser(Integer userID,String username) { User user=new User(); //根据userID来进行删除 user.setUserID(userID); //修改哪一个字段就设置哪一个字段 user.setUsername(username); return mapper.updateById(user); } }根据map集合中的条件来删除用户信息:
根据ID来进行批量删除:
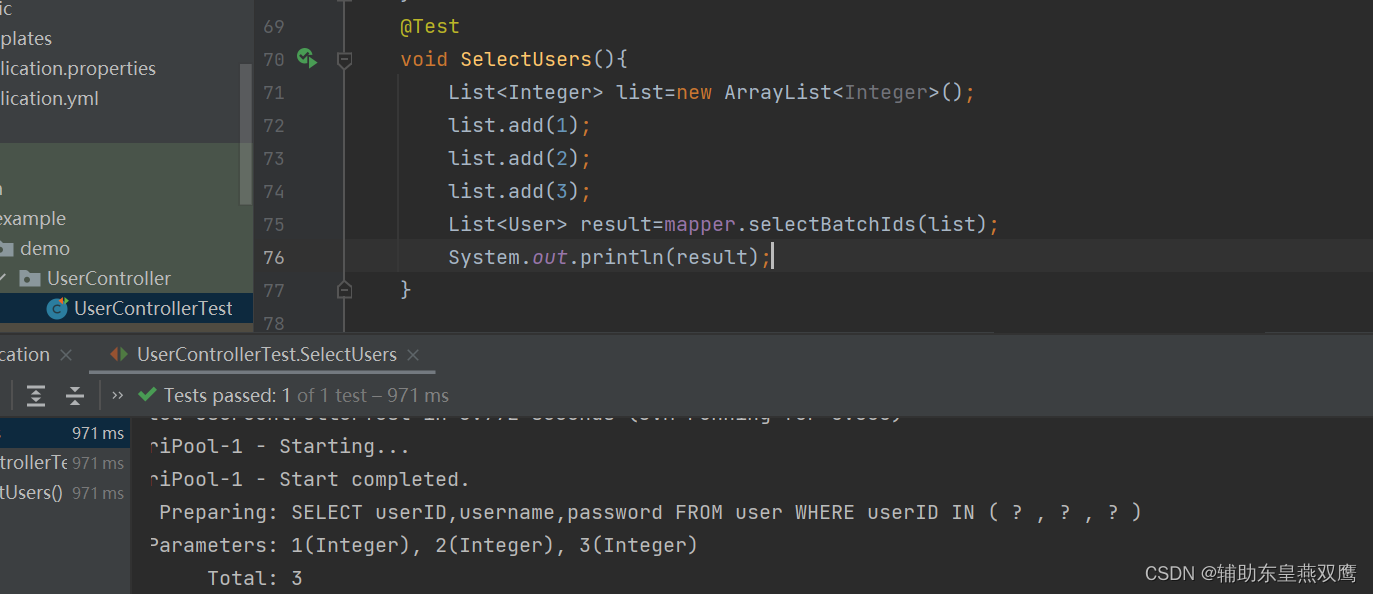
根据ID来进行批量查询用户信息:
根据map集合所设定的条件来实现查询功能:
编写properties配置文件
spring.datasource.username=root spring.datasource.url=jdbc:mysql://127.0.0.1:3306/Java200?characterEncoding=utf-8&useSSL=true spring.datasource.password=123456 spring.driver-class-name=com.mysql.cj.jdbc.Driver mybatis.mapper-locations=classpath:mapper/**Mapper.xml logging.level.com.example.demo=debug mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl mybatis-plus.configuration.map-underscore-to-camel-case=false


通用Service接口设计:
IService是一个接口,ServiceIMPL是一个实现类
1)Iservice<T>中的泛型T是进行操作的实体类对象
2)ServiceImpl<M extends BaseMapper<T>,T> implents Iservice<T>,这里面M的就是当前自己所写的mapper,T就是当前所操作的实体类对象;
//ServiceImpl是实现类,Iservice是接口,不建议直接使用ServiceImpl @Service public class UserService extends ServiceImpl<UserMapper, User> implements ServiceK { } public interface ServiceK extends IService<User> { }
//ServiceImpl是实现类,Iservice是接口,不建议直接注入ServiceImpl来直接使用 @Service public class UserService extends ServiceImpl<UserMapper, User> implements IService<User> {}@SpringBootTest @Controller class UserControllerTest { @Autowired private UserService service; //1.直接注入Service对象来完成查询 @Test void Insert(){ User user=new User(); user.setUserID(9); user.setUsername("lisi"); user.setPassword("12503487"); boolean flag=service.save(user); System.out.println(flag); } //2.直接注入Service对象来完成删除 @Test void delete(){ service.removeById(9); } //3.调用UserService实现修改操作 @Test void update(){ User user=new User(); //指明要修改的字段是哪一个id user.setUserID(2); user.setUsername("李佳伟"); user.setPassword("12503487"); service.updateById(user); } //4.调用UserService实现查询操作 @Test void SelectAll(){ List<User> list=service.list(); System.out.println(list); }查询当前表中的总记录数和批量添加:
@Test void SelectCount(){ //1.测试数据库中的总记录数,select count(*) from user System.out.println(service.count()); //2.进行批量添加 List<User> userList=new ArrayList<>(); User user=new User(); //指明要修改的字段是哪一个id user.setUserID(10); user.setUsername("芜湖帮"); user.setPassword("12503487"); User user2=new User(); user2.setUserID(11); user2.setUsername("雪花算法"); user2.setPassword("adminLrq"); userList.add(user); userList.add(user2); service.saveBatch(userList); }

映射规则:
Mybatis框架之所以能够简化数据库操作,是因为他内部的映射机制,通过自动映射,进行数据的封装,我们只要符合映射规则,就可以快速高效的完成SQL操作的实现。
既然MybatisPlus是基于Mybatis的增强工具,所以也具有这样的映射规则1)区分属性名称和变量名称:
变量名称就是JAVA变量中的名字
属性名称就是对应的JAVA变量的GetSet方法后面的字段对应的小写
但是如果代码变成这样,属性名称就是name,变量名称就是n
1)表名和实体类名映射 -> 表名user 实体类名User
2)字段名和实体类属性名映射 -> 字段名name 实体类属性名name
3)字段名下划线命名方式和实体类属性小驼峰命名方式映射 ->
字段名 user_email 实体类属性名 userEmail
4)MybatisPlus支持这种映射规则,可以通过配置来设置
map-underscore-to-camel-case: true 表示支持下划线到驼峰的映射
map-underscore-to-camel-case: false 表示不支持下划线到驼峰的映射#来进行设置实体类所对应的表的统一前缀 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl map-underscore-to-camel-case: true


一)@TableName(value="实体类对应的表名")注解:实现数据库中的表到实体类中的映射
1)默认情况下是表名user 实体类名User,但是可以通过TableName注解来实现表和实体类之间的映射
2)如果有很多实体类,对应到数据库中的很多表,我们不需要每个依次配置,只需要配置一个全局的设置,他都会给每个实体类名前面添加指定的前缀,这里演示一下全局配置的效果
mybatis-plus.global-config.db-config.table-prefix=对应的表的前缀
二)@TableId将这个属性所对应的字段作为当前的主键
mybatis_plus只能默认为ID作为主键,也就是说你的数据库中的表中的主键的名字不是ID的时候,就需要使用@TableID注解
2.1)value属性:当实体类中的主键的字段名字和数据库中的主键的字段名字不相同的时候进行使用;
2.2)type属性:指定主键生成的策略,mybatis_plus默认是使用雪花算法来进行生成主键的,也就是type=IdType.NoNE,type=type.AUTO,但是比如说在进行插入操作的时候,如果User对象中设置了userID,那么type属性就会失效;
通过全局配置主键生成策略:
mybatis-plus: global-config: db-config: #设置统一的主键生成策略 id-type: T_ #设置实体类所对应的表的统一前缀 table-prefix: auto三)@TableField(value="数据库中的字段名字"),为了解决数据库中的字段名和实体类中的字段名是不相等的
3.1)当数据库的字段名是desc,类中的字段名也是desc, 此时字段名和SQL的关键字冲突,所以要使用此时也要使用@TableField("`desc`")进行分割符的标注
select * from user from desc=`desc`
3.2)当实体类中的字段在数据库中不存在的时候,假设实体类中有isLogin属性,但是在数据库中并没有这个isLogin属性,那么就需要加上这个注解@TableField(exit=false)
3.3)字段失效:当数据库中有字段不希望被查询出来,我们就可以通过@TableField(select=false)来隐藏这个字段,那么在进行拼接SQL的时候,就不会拼接上这个字段;
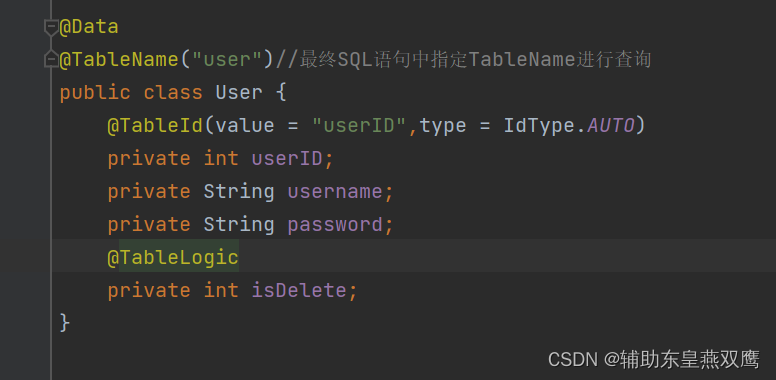
四)@TableLogic
1)物理删除:真实删除,将对应的数据从数据库中移除,之后无法查询此条被删除的记录
2)逻辑删除:假删除,将对应的数据中代表删除的字段标记成被删除状态,之后仍然可以在数据库中看到此条记录
应用场景:可以进行数据恢复
下面来演示一下:
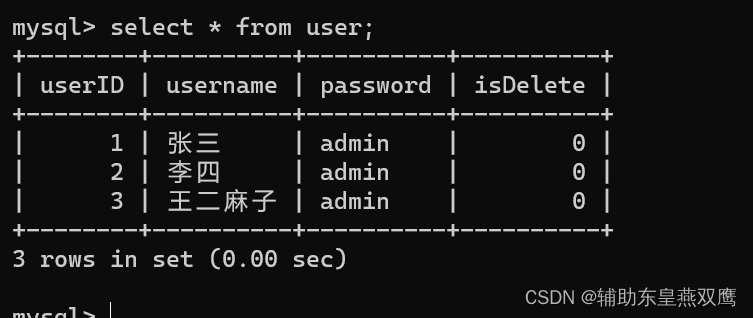
如果此时再来进行查询操作:数据库中存在着记录,但是无法进行查询,因为已经被逻辑删除


雪花算法:
背景:需要选择合适的方案去应对数据规模的增长,来应对长时间的访问压力和数据量
数据库的扩展方式包括业务分库,主从复制,数据库分表
一)数据库分表:将不同的业务数据分散在不同的数据库服务器中,能够支撑成百上千的的业务,如果业务继续发展,那么同一业务的单达到单台数据库服务器的数据也会打到数据库服务器的处理瓶颈,例如说淘宝的几亿用户量,如果全部存放到一张表里面肯定是无法满足性能要求的,此时就需要对表单数据进行拆分;
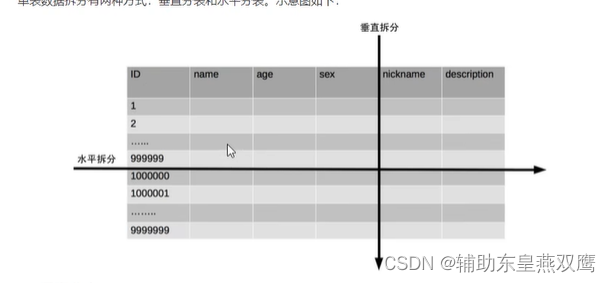
但比送数据的拆分有两种方式:垂直分表和水平分表
假设下面是一个婚恋网站表:
垂直分表:垂直分表适用于将表中不常用的字段且占用了大量空间的列拆分出去
水平分表:是将一张表中的数据分到多张表中
1)自增主键:
2)取模:
3)雪花算法:雪花算法是分布式主键生成算法,它能够保证不同的表中主键的不重复性,以及相同的表中的主键的有序性;
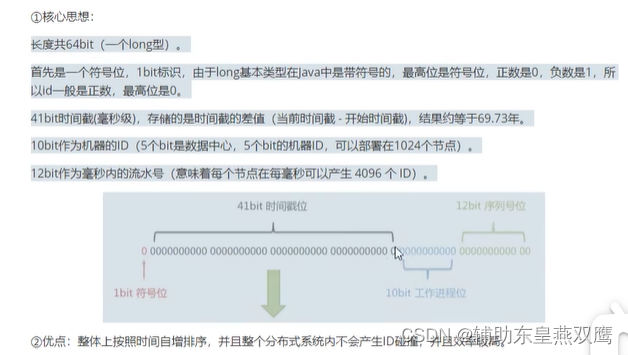
雪花算法是 64 位 的二进制,一共包含了四部分:
- 1位是符号位,也就是最高位,始终是0,没有任何意义,因为要是唯一计算机二进制补码中就是负数,0才是正数。
- 41位是时间戳,具体到毫秒,41位的二进制可以使用69年,因为时间理论上永恒递增,所以根据这个排序是可以的。
- 10位是机器标识,可以全部用作机器ID,也可以用来标识机房ID + 机器ID,10位最多可以表示1024台机器。
- 12位是计数序列号,也就是同一台机器上同一时间,理论上还可以同时生成不同的ID,12位的序列号能够区分出4096个ID



条件构造器:

一)等值条件查询:
1)eq("数据库的字段值","实际的值"):
1.1)等值条件查询,eq中的传递的字符串要和数据库中的名字要相同
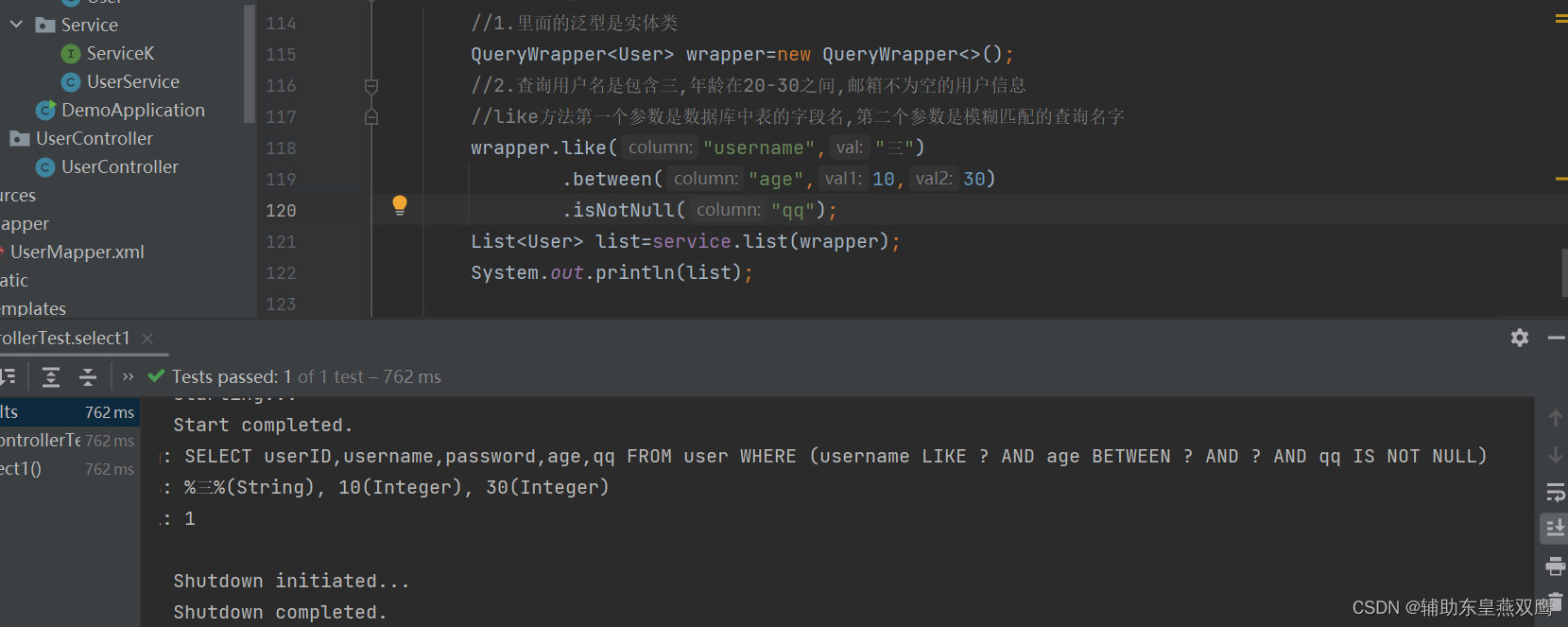
// SELECT userID,username,password,age,qq FROM user WHERE (username = ? AND password = ?) @Test void eq(){ //1.创建条件查询对象 QueryWrapper<User> wrapper=new QueryWrapper<>(); //2.封装条件,更具这个查询对象来指定查询条件 wrapper.eq("username","张三") .eq("password","12503487"); //3.将wrapper对象封装到service的查询方法中 List<User> list=mapper.selectList(wrapper); System.out.println(list); }

@Test void eq2(){ LambdaQueryWrapper<User> wrapper=new LambdaQueryWrapper<>(); wrapper.eq(User::getUsername,"张三") .eq(User::getAge,10); List<User> list=mapper.selectList(wrapper); System.out.println(list); }1.2)我们这个时候还需要考虑一种情况,我们进行构建的条件是从哪里来的,当然是从客户端通过请求发送过来的由服务端进行接受的,在网站中一般都会有多个条件入口,用户可以选择一个或者多个来进行查询,那么这个时候在进行请求的时候,并不能保证所有的条件都是有值的,可能前端压根没有进行传递,那现在直接将该条件设置成空;
但是这样做是不合理的,条件为空,查询出来的数据就是为空了吗?我们可不可以做到实现将username既然为空,那么就不要将username作为查询的条件了,如果字段值不为空,那么该字段将作为有效的查询条件,所以说,作为null的条件,我们是不需要进行条件拼接的,否则就会出现以下情况,将null的条件进行拼接,导致最后无法查询到结果;
所以我们就需要使用eq的重载方法:
1)如果第一个参数是false,那么说明传递的参数是空就不会被作为条件拼接
2)如果第一个参数是true,那么说明传递的参数是空也会被拼接
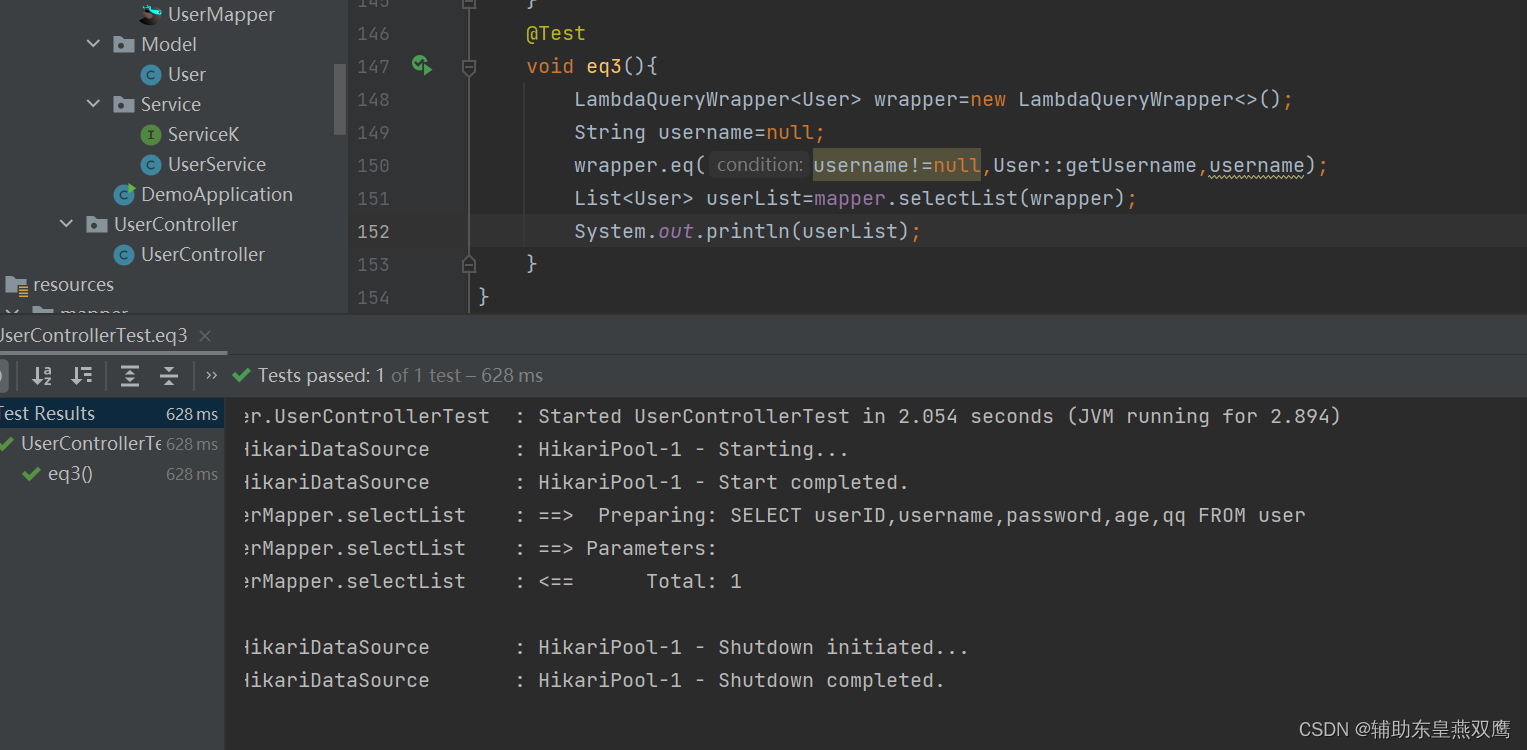
下面代码可以看出,username为空的时候并没有将username作为查询条件,此时传递的username为空,此时查询的是所有
@Test void eq3(){ LambdaQueryWrapper<User> wrapper=new LambdaQueryWrapper<>(); String username=null; wrapper.eq(username!=null,User::getUsername,username); List<User> userList=mapper.selectList(wrapper); System.out.println(userList); }
1.3)多条件查询:
实现方式1:通过多次调用eq方法来进行实现:
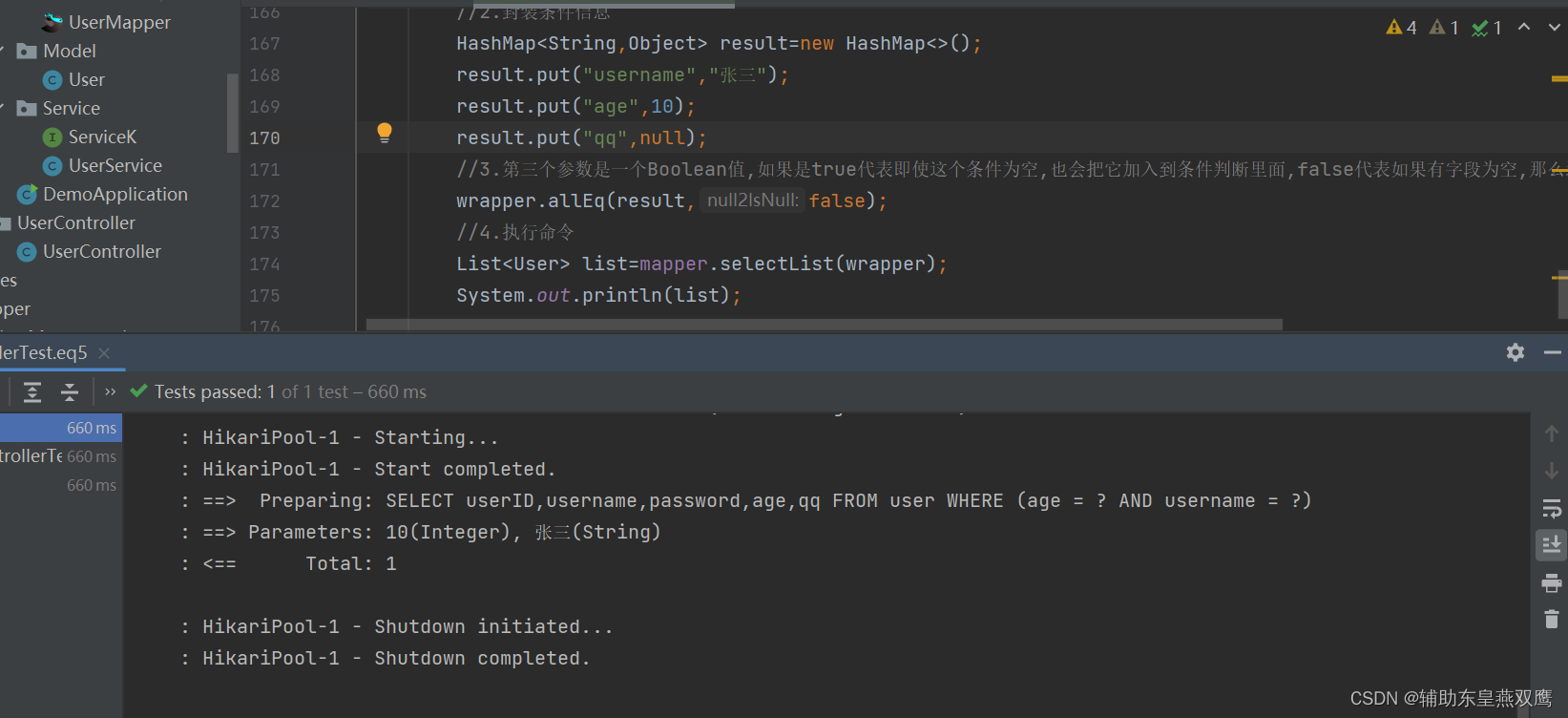
实现方式2:使用QueryWrapper对象包装HashMap通过alleq方法进行实现多条件查询
@Test void eq5(){ //1.创建一个QueryWrapper对象 QueryWrapper<User> wrapper=new QueryWrapper<>(); //2.封装条件信息 HashMap<String,Object> result=new HashMap<>(); result.put("username","张三"); result.put("age",10); result.put("qq",null); //3.第三个参数是一个Boolean值,如果是true代表即使这个条件为空,也会把它加入到条件判断里面,false代表如果有字段为空,那么这个空字段将不会作为条件进行判断 wrapper.allEq(result,false); //4.执行命令 List<User> list=mapper.selectList(wrapper); System.out.println(list); }
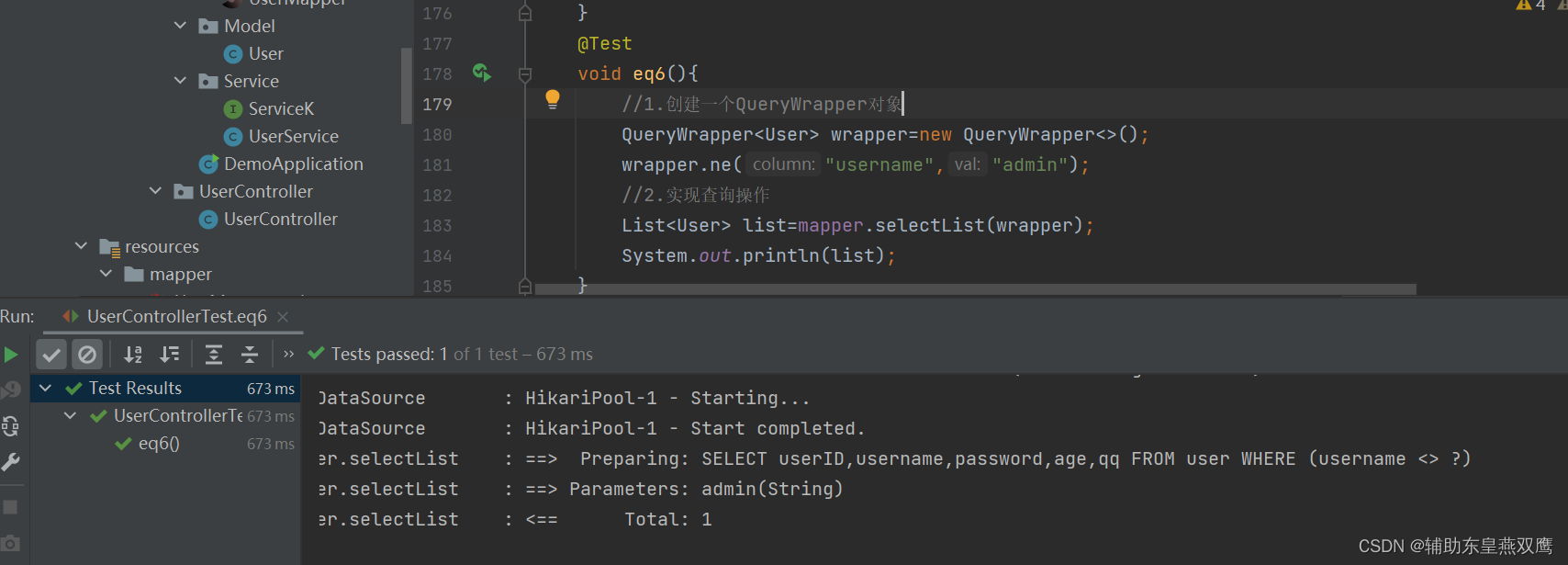
2)ne:不等于

二)范围条件查询:
gt:大于
ge:大于等于
lt:小于
le:小于等于
between:在某段范围区间之内
not between:不在某一段区间范围之内