在我之前的文章中,关于手写文字、手写数字、手写字母的检测识别相关的项目都有了不少的实践了,这里就不在赘述了,感兴趣的话可以自行移步阅读即可。
《基于轻量级目标检测模型实现手写汉字检测识别计数》
《python开发构建基于机器学习模型的手写数字识别系统》
《Yolov3目标检测实战【实现图像中随机出现手写数字的检测】》
《Python 手写数字识别实战分享》
《超轻量级目标检测模型Yolo-FastestV2基于自建数据集【手写汉字检测】构建模型训练、推理完整流程超详细教程》
《python开发构建轻量级卷积神经网络模型实现手写甲骨文识别系统》
本文主要是在前文手写甲骨文识别项目的基础上更进一步开发构建的手写甲骨文检测识别系统,将目标检测模型yolov7融合集成进来,同时实现了图像中甲骨文的定位和识别,系统效果如下所示:

如果关于如何基于yolov7开发构建自己的个性化系统不熟悉的可以查看我的超详细教程,包会。
《YOLOv7基于自己的数据集从零构建模型完整训练、推理计算超详细教程》
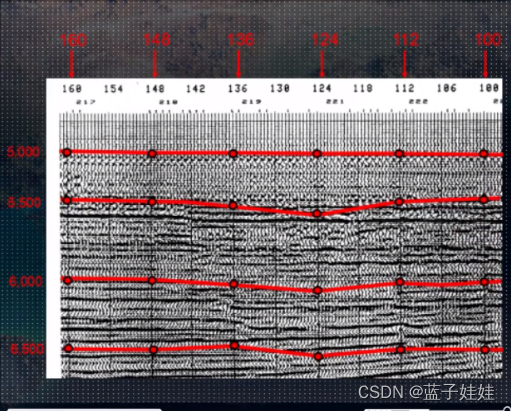
简单看下本文中为了实现甲骨文检测识别仿真生成的数据集,如下所示:

VOC格式标注文件如下:
YOLO格式标注文件如下所示:

可以看到:一共包含40000的样本数据集,对于模型训练开发来说应该是足够的了。
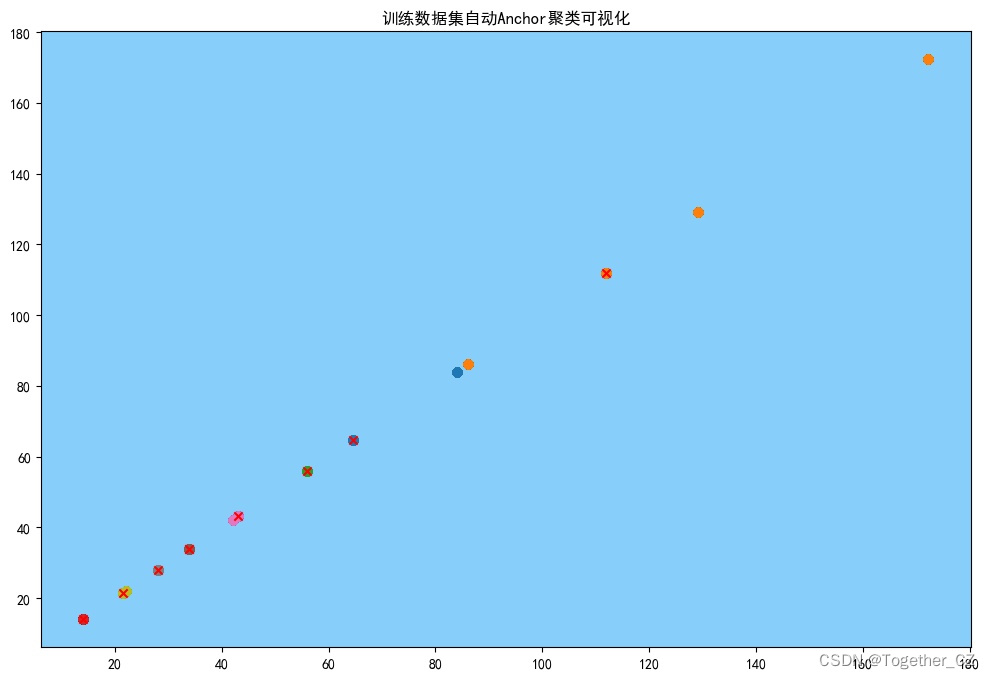
这里对数据集进行了自动锚框计算,结果如下:
13,13, 21,21, 28,28, 33,33, 33,33, 43,43, 56,56, 64,64, 112,112结果可视化如下:
默认设定的是100次epoch的迭代计算。
接下来简单看下实例推理效果:

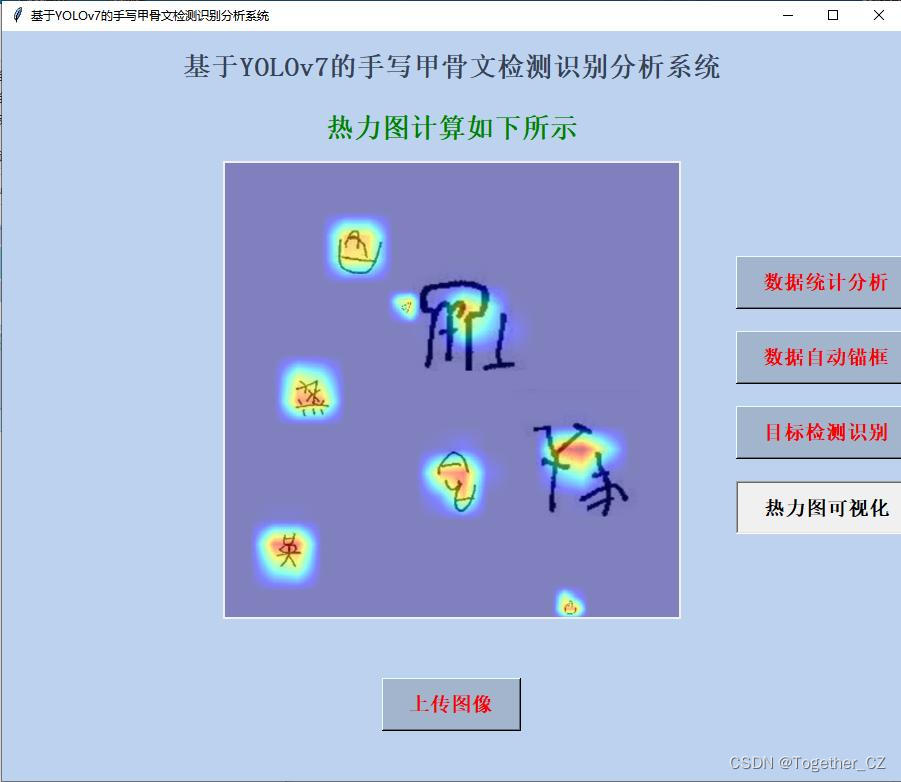
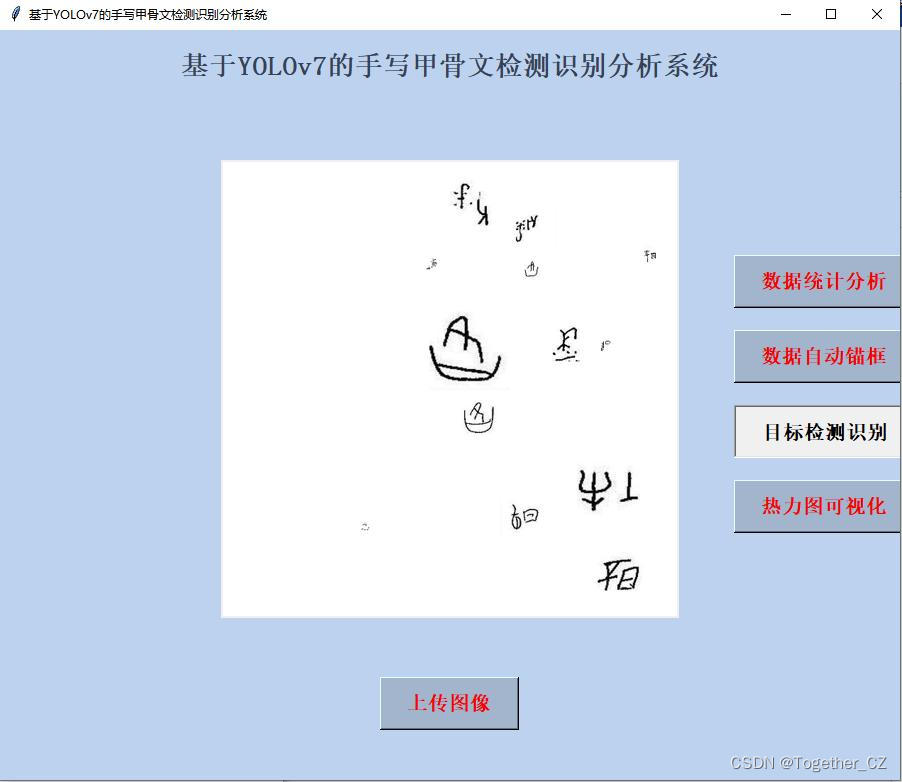

这里我同时集成了热力图可视化计算,能够帮助理解和分析模型的工作原理,感兴趣的话都是可以自己试试的。
z