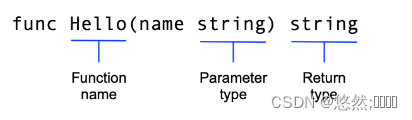
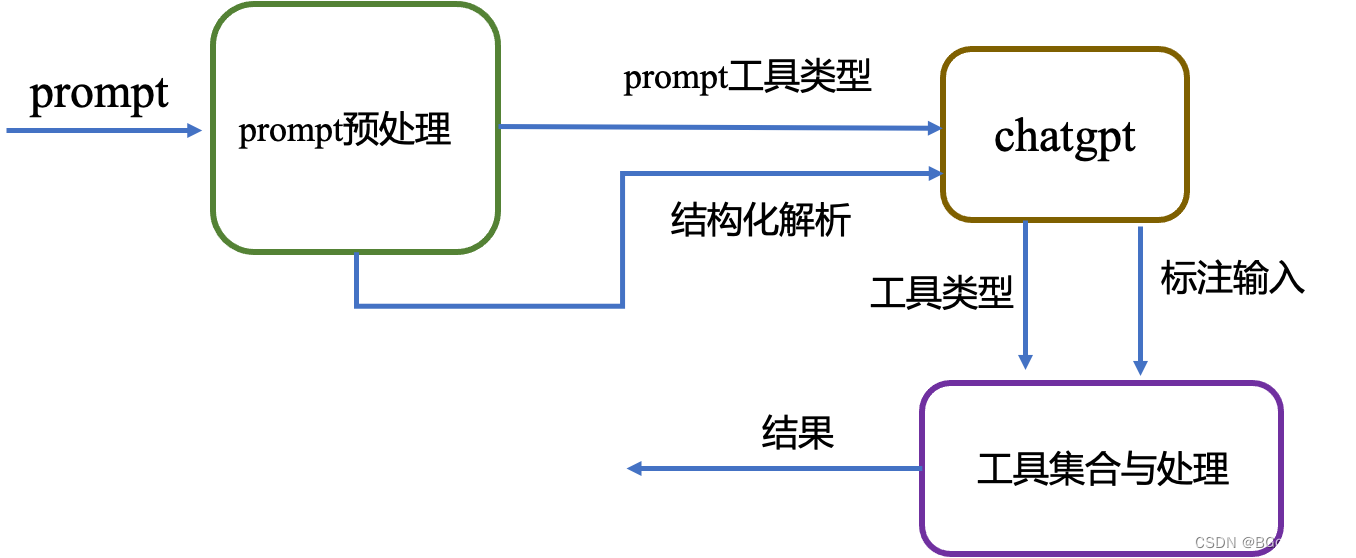
数组
基本操作
InitArray(&A, n, bound1, ..., boundn)
DestroyArray(&A)
Value(A, &e, index1, ..., indexn)
Assign(&A, e, index1, ..., indexn)
数组的顺序表示
两种顺序映象的方式:
- 以行序为主序(低下标优先);
- 以列序为主序(高下标优先)。

而
n
n
n维数组:LOC(x1, x2, ..., xn) = LOC(0, 0, ..., 0) + [(x1 × b1 + x2) × b2 + x3] × b3 + ... + xn
数据类型定义
#include <stdarg.h> // 标准头文件,提供宏 va_start、va_arg 和 va_end,用于存取变长参数表
#define MAX_ARRAY_DIM 8 // 假设数组维数的最大值为 8
typedef struct {
ElemType *base; // 数组元素地址,由 InitArray 分配
int dim; // 数组维数
int *bounds; // 数组维界基址,由 InitArray 分配
int *constants; // 数组映像函数常量基址,由 InitArray 分配
} Array;
其中:
Status InitArray(Array& A, int dim, ...) {
// 若维数 dim 不合法,则返回 ERROR
if (dim < 1 || dim > MAX_ARRAY_DIM) {
return ERROR;
}
A.dim = dim;
A.bounds = (int*)malloc(dim * sizeof(int));
if (!A.bounds) {
exit(OVERFLOW);
}
// 存储各维长度,并计算元素总数 elemtotal
int elemtotal = 1;
va_list ap; // 定义 va_list 类型变量 ap,用于存放变长参数表信息的数组
va_start(ap, dim); // 初始化 ap 数组
for (int i = 0; i < dim; ++i) {
A.bounds[i] = va_arg(ap, int);
if (A.bounds[i] < 0) {
return UNDERFLOW;
}
elemtotal *= A.bounds[i];
}
va_end(ap); // 结束 ap 数组
A.base = (ElemType*)malloc(elemtotal * sizeof(ElemType));
if (!A.base) {
exit(OVERFLOW);
}
// 求映像函数的常数 ci,并存入 A.constants[i-1],i=1,...,dim
A.constants = (int*)malloc(dim * sizeof(int));
if (!A.constants) {
exit(OVERFLOW);
}
A.constants[dim - 1] = 1;
// L=1,指针的增减以元素的大小为单位
for (int i = dim - 2; i >= 0; --i) {
A.constants[i] = A.bounds[i + 1] * A.constants[i + 1];
}
return OK; // 返回 OK
}
A.bounds是每一维可以放多少元素:a[A.bounds[0]][A.bounds[1]][A.bounds[2]]……
A.constants是指向每一维开始的元素的指针(因为是顺序存放,所以没有在计算机中没有明显的维数的区分,需要自己计算出指向每一维第一个元素的指针)
关于va_list的解释
/**
* 在数组 A 中定位指定下标的元素,并计算出该元素的相对地址。
*
* @param A 要定位的多维数组
* @param ap 指示要定位的下标列表的可变参数
* @param off 返回该元素在数组 A 中的相对地址
* @return 如果下标合法,返回 OK;否则返回 OVREFLOW
*/
Status Locate(Array A, va_list ap, int& off) {
// 初始化偏移量为 0
off = 0;
// 循环遍历所有维度
for (int i = 0; i < A.dim; ++i) {
// 获取当前维度的下标值
int ind = va_arg(ap, int);
// 检查下标值是否超出边界
if (ind < 0 || ind >= A.bounds[i]) {
return OVREFLOW;
}
// 计算该维度下标对应的偏移量,并累加到总偏移量中
off += A.constants[i] * ind;
}
// 如果下标合法,则返回 OK
return OK;
}
矩阵的压缩存储

#define MAXSIZE 12500
typedef union {
Triple data[MAXSIZE + 1]; // 用于存储稀疏矩阵中的非零元素
int mu, nu, tu; // 分别表示稀疏矩阵的行数、列数和非零元素个数
} TSMatrix; // 稀疏矩阵类型
有2类稀疏矩阵:
- 非零元在矩阵中的分布有一定规则
例如: 三角矩阵, 对角矩阵 - 随机稀疏矩阵
非零元在矩阵中随机出现
随机稀疏矩阵的压缩存储方法:
- 三元组顺序表
这个结构体一般用于表示稀疏矩阵中的非零元素。对于一个 m 行 n 列的稀疏矩阵,如果其非零元素个数为 k,则可以用一个长度为 k 的 Triple 数组来存储这些非零元素。
#define MAXSIZE 12500
typedef struct {
int i, j; // 该非零元的行下标和列下标
ElemType e; // 该非零元的值
} Triple; // 三元组类型
- 行逻辑联接的顺序表
- 十字链表
求转置矩阵
三元组作转置
Status FastTransposeSMatrix(TSMatrix M, TSMatrix &T){
T.mu = M.nu;
T.nu = M.mu;
T.tu = M.tu;
if (T.tu) {
int col, t, p;
int num[MAXSIZE + 1] = {0}; // 列计数器,用于记录每列非零元素的个数
int cpot[MAXSIZE + 1] = {0}; // 行指针数组,用于记录每列第一个非零元素在转置矩阵中的位置
// 统计每列非零元素的个数
for (col = 1; col <= M.nu; ++col) {
num[col] = 0;
}
for (t = 1; t <= M.tu; ++t) {
++num[M.data[t].j];
}
// 计算每列第一个非零元素在转置矩阵中的位置
cpot[1] = 1;
for (col = 2; col <= M.nu; ++col) {
cpot[col] = cpot[col - 1] + num[col - 1];
}
// 执行转置操作
for (p = 1; p <= M.tu; ++p) {
col = M.data[p].j;
int q = cpot[col]; // 该元素在转置矩阵中的位置
T.data[q].i = M.data[p].j;
T.data[q].j = M.data[p].i;
T.data[q].e = M.data[p].e;
++cpot[col]; // 该列的行指针加1
}
}
return OK;
} // FastTransposeSMatrix
行逻辑连接的顺序表
#define MAXMN 500
typedef struct {
Triple data[MAXSIZE + 1]; // 非零元三元组表
int rpos[MAXRC + 1]; // 各行第一个非零元的位置表
int mu, nu, tu; // 矩阵的行数、列数和非零元个数
} RLSMatrix; // 行逻辑链接顺序表类型
ElemType value(RLSMatrix M, int r, int c) {
int p = M.rpos[r];
while (M.data[p].i == r && M.data[p].j < c) {
p++;
}
if (M.data[p].i == r && M.data[p].j == c) {
return M.data[p].e;
} else {
return 0;
}
} // value
矩阵乘法:
// 稀疏矩阵相乘
Status MultSMatrix(RLSMatrix M, RLSMatrix N, RLSMatrix &Q) {
// 如果两个稀疏矩阵的列数不等,则无法相乘,返回错误状态
if (M.nu != N.mu) {
return ERROR;
}
// 计算结果矩阵Q的行数,列数以及非零元素个数
Q.mu = M.mu;
Q.nu = N.nu;
Q.tu = 0;
// 如果M、N之间存在非零元素,则进行矩阵相乘的处理
if (M.tu * N.tu != 0) {
// 遍历M的每一行
for (int arow = 1; arow <= M.mu; ++arow) {
// M矩阵中第arow行在三元组表中的起始位置
int mp = M.rpos[arow];
// 遍历N的每一列
for (int bcol = 1; bcol <= N.nu; ++bcol) {
// 初始化N矩阵中第bcol列在三元组表中的起始位置
int np = N.rpos[bcol];
// 累加M矩阵第arow行和N矩阵第bcol列的乘积
ElemType temp = 0;
while (mp < M.tu && np < N.tu) {
// 如果M矩阵和N矩阵中的当前位置元素在同一列,则累加乘积
if (M.data[mp].j == N.data[np].i) {
temp += M.data[mp].e * N.data[np].e;
mp++;
np++;
} else if (M.data[mp].j < N.data[np].i) {
mp++;
} else {
np++;
}
} // while
// 如果累加的乘积不为0,则添加到结果矩阵Q中
if (temp != 0) {
Q.tu++;
// 将非零元素添加到Q三元组表的末尾
Q.data[Q.tu].i = arow;
Q.data[Q.tu].j = bcol;
Q.data[Q.tu].e = temp;
}
} // for bcol
} // for arow
} // if
return OK;
} // MultSMatrix
十字链表

结构体定义
typedef struct OLNode {
int i, j; // 该非零元的行和列下标
ElemType e; // 该非零元的值
struct OLNode *right, *down; // 该非零元所在行表和列表的后继指针
} OLNode, *OLink;
typedef struct {
OLink *rhead, *chead; // 行和列链表头,指向 rhead 与 chead 数组
// 指针向量基址由 CreateSMatrix 函数分配
int mu, nu, tu; // 稀疏矩阵的行数、列数和非零元个数
} CrossList;
广义表

结构特点:
- 广义表的长度定义为最外层包含元素个数;
- 广义表的深度定义为所含括弧的重数;
注意:“原子”的深度为 0 ;“空表”的深度为 1
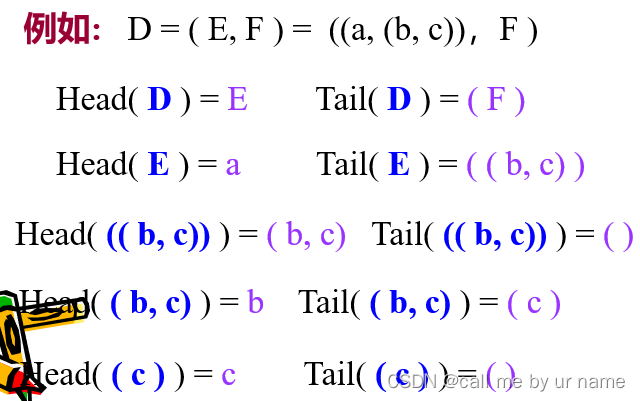
表头要去掉一次括号,表尾直接拿并且包含原来的括号
广义表的存储结构
表头、表尾法
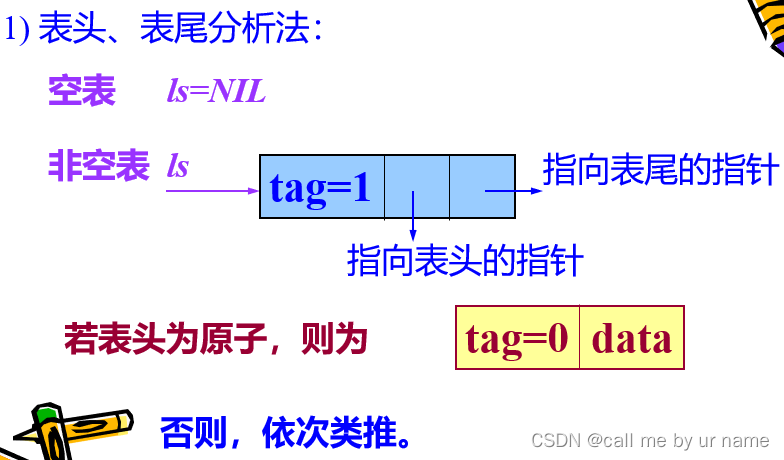
其中,NIL表示空表
子表表示
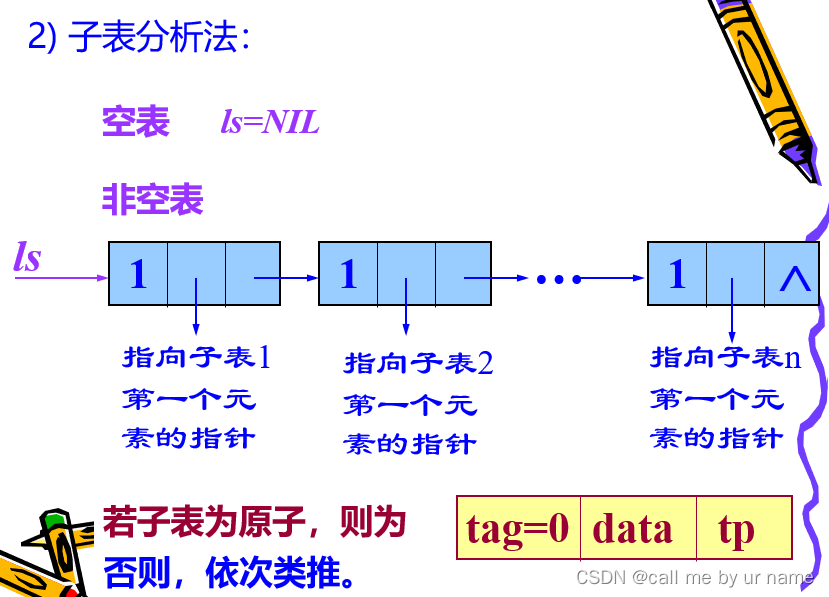
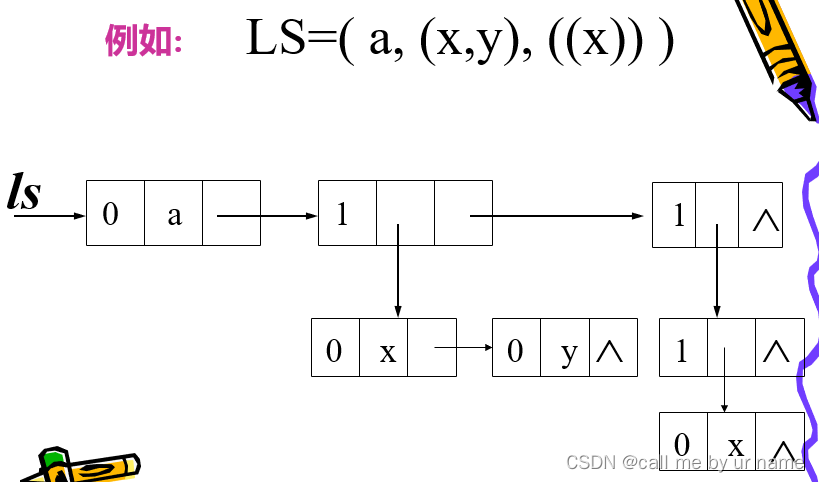
搭配这个例子才比较好理解一些
求深度
int GlistDepth(Glist L) {
// 返回指针L所指的广义表的深度
int max = 0;
Glist pp;
int dep;
if(!L) return 1;
if(L->tag==ATOM) return 0;
for (pp = L; pp; pp = pp->ptr.tp) {
dep = GlistDepth(pp->ptr.hp);
if (dep > max) {
max = dep;
}
}
return max + 1;
} // GlistDepth
遇到求深度的一些填空题,可能要自己画一下了,不是用眼睛能看出来的
复制广义表
void CopyGList_GL_E(GList* T, GList L) {
if (L == NULL) {
*T = NULL;
return;
}
*T = (GLNode*)malloc(sizeof(GLNode));
(*T)->tag = L->tag;
if (L->tag == 0) {
(*T)->a.atom = L->a.atom;
} else {
CopyGList_GL_E(&((*T)->a.ptr.hp), L->a.ptr.hp);
CopyGList_GL_E(&((*T)->a.ptr.tp), L->a.ptr.tp);
}
}
习题
5.19 马鞍点
5.19若矩阵 A A A中的某个元素 a是第行中的最小值同时又是第列中的最大值,则称此元素为该矩中的一个马鞍点。假设以二维数组存储矩阵 A m ∗ n A_{m*n} Am∗n,试编写求出矩阵中所有马鞍点的算法,并分析你的算法在最坏情况下的时间复杂度
void saddle(int a[m][n]) {
int flag = 0, min, col;
for (int i = 0; i < m; ++i) {
min = a[i][0];
for (int j = 0; j < n; ++j) {
if (a[i][j] < min) {
min = a[i][j];
col = j;
}
}
int flag1 = 1;
for (int k = 0; k < m; ++k) {
if (min < a[k][col]){
flag1 = 0;
break;
}
}
if (flag1) {
printf("%d行%d列是马鞍点,值为%d\n", i, col, min);
flag = 1;
}
}
if (!flag) {
printf("无马鞍点\n");
}
}
时间复杂度: O ( m 2 + m ∗ n ) O(m^2+m*n) O(m2+m∗n)