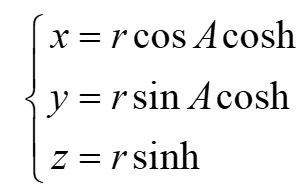Paper地址:https://arxiv.org/abs/2208.07339
GitHub链接:GitHub - TimDettmers/bitsandbytes: 8-bit CUDA functions for PyTorch
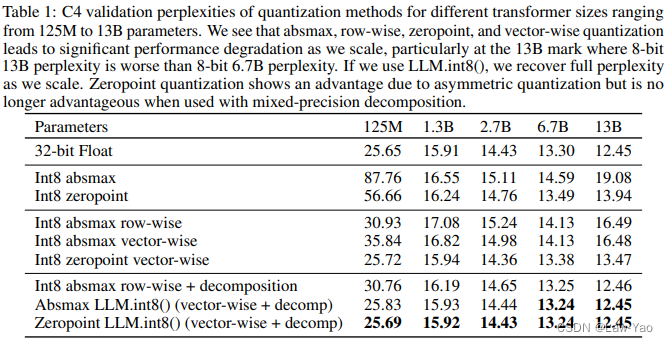
随着模型参数规模的增加,大模型(如GPT-3,OPT-175B等NLP稠密大模型)的实际部署应用,需要消耗一定的计算/存储资源,且推理响应延迟存在限制,例如:基于Triton的分布式并行推理,OPT-175B部署在8张A100设备上时,推理延迟约400ms(Batch size=1)。
模型量化是实现模型压缩与推理加速的常用技术手段,但由于大模型本身巨大的参数规模,首先权重矩阵与特征张量的维度都很高,对权重与特征都直接采用Per-tensor量化会造成较大的估计失偏,无法较好还原实际的数据分布。其次,异常值(Outliers)对模型量化后的预测精度也会造成很大影响,当NLP稠密大模型的参数规模在6.7B时,尽管异常值的占比仅占0.1%,但将这些异常值都置零,会直接导致预测精度劣化20%。
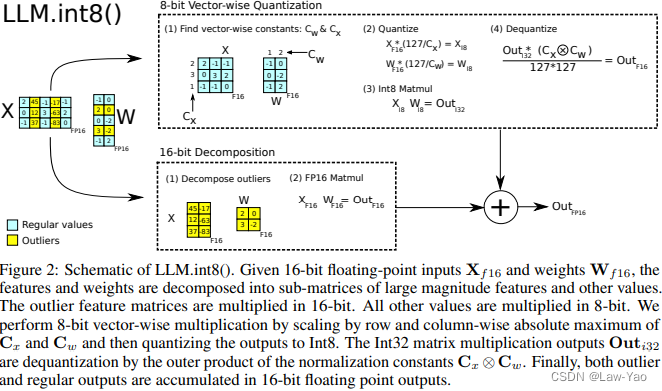
如上图所示,本文提出的自适应混合精度量化方法(命名为LLM.int8,是一种训练后量化方法),通过将Vector-wise量化与混合精度分解(Mixed-precision Decomposition Scheme)相结合,能够有效的分区域设置量化分辨率,并消除异常值对模型量化带来的负面影响:
- Vector-wise量化:将特征与权重分别按行与列,划分为不同的Vector区域,各自计算量化参数。将特征与权重转换为INT8整数后,量化计算过程执行Inner-product,输出INT32乘累加结果(INT8->INT32);反量化计算过程执行Outer-product,将INT32结果还原为FP16精度(INT32->FP16)。具体如下(采用对称量化形式):
![]()
- 混合精度分解:对于异常值所在区域(Vector-wise area),按FP16数值精度执行Inner-product,计算结果累加到Vector-wise量化结果:
![]()
通过自适应混合精度量化,能有效提升大模型的量化精度保持效果,并减少推理部署的资源成本:

![[LeetCode周赛复盘] 第 322 场周赛20221204](https://img-blog.csdnimg.cn/13704aaa394e4710b5355955dff685a5.png)


![[附源码]Python计算机毕业设计Django汽车美容店管理系统](https://img-blog.csdnimg.cn/07ab0e30abf14c7496e562d0ca8a2715.png)