文章目录
- 一、接前一天
- 二、TensorBoard
- (1). 什么是TensorBoard
- (2). TensorBoard有什么用
- (3). TensorBoard怎么安装
- 三、tf.summary模块
- (1).如何使用`tensorboard`
- (2).`tf.summary`模块的主要参数和函数
- a. `参数`
- 1.参数:name
- 2.参数:tensor
- b. `函数`
- 1.函数:`tf.summary.scalar`
- 2.函数:`tf.summary.histogram`
- 3.函数:tf.summary.image
- 4.函数:`tf.summary.merge`
- 5.函数:`tf.summary.FileWriter`
- (3). 模块中`.add_summary()`函数
- 四、可视化实践
- `使用`:
- `代码`: 用一个简单的 线性回归 使用tensorboard工具
- `结果展示`:
一、接前一天
前一天讨论了TensorFlow中的计算图,的创建和计算。至于多计算图改天讨论,今天主要讨论,可视化工具 TensorBoard
二、TensorBoard
(1). 什么是TensorBoard
TensorBoard是一个工具,用于可视化和理解TensorFlow运行的神经网络模型。其原理主要基于TensorFlow在训练神经网络时自动记录了大量有关模型性能和状态的数据,并将这些数据保存到一组日志文件中。TensorBoard读取这些日志文件并呈现以易于理解的方式可视化的信息,例如损失曲线、精度曲线、图形表示、直方图等等。TensorBoard还提供了交互式控件,可以通过调整模型参数和超参数来观察模型输出的变化。这使得深度学习研究人员可以更有效地分析和优化他们的神经网络模型。
(2). TensorBoard有什么用
-
可视化模型结构:TensorBoard 可以显示 Python 代码中定义的计算图,该图表示了模型的结构和参数,包括张量的形状、数据类型、操作等信息。这有助于理解模型的复杂度、层次结构和输入输出形状。 -
跟踪指标和摘要:TensorBoard 可以记录和显示模型的训练指标(如准确率、损失函数值等)和摘要(如直方图、概率密度函数、图像等),以便可以监控并比较不同模型或不同超参数下的性能。您还可以覆盖摘要以生成更高级别的可视化效果。 -
分析计算时间和内存消耗:TensorBoard 可以分析模型的运行时间和内存消耗,并在图表中显示结果。这有助于您找出模型的瓶颈和优化点,以提高性能和效率。 -
可视化嵌入向量:如果您正在训练嵌入向量,TensorBoard 可以将它们投影到高维空间中,并显示它们之间的关系。这有助于您理解向量的语义含义和相似性,以及在不同任务和领域中的通用性。
(3). TensorBoard怎么安装
一般 pip install TensorFlow 会自动安装
或者:pip install tensorboard
更新命令:pip install --upgrade tensorflow-tensorboard
三、tf.summary模块
(1).如何使用tensorboard
主要基于tf.summary模块,该模块是TensorFlow提供的用于可视化数据和图像等各种信息的工具包。其中包含了很多函数和参数。
(2).tf.summary模块的主要参数和函数
a. 参数
1.参数:name
tf.summary中的很多函数都有一个name参数,用于给生成的summary命名,方便在TensorBoard中查看和管理。name参数通常接收一个字符串作为输入。
2.参数:tensor
tensor参数指定了需要记录的张量(tensor)。可以是单个张量,也可以是张量列表。如果是张量列表,则会将所有张量记录到同一个summary中。
b. 函数
1.函数:tf.summary.scalar
如果要记录标量数据(如损失值、精确度等),可以使用tf.summary.scalar()函数。该函数需要提供两个参数:一个是名称,用于标识这个指标;另一个是实际的数值。在训练过程中,每次调用该函数都会记录对应的名称和数值,最终存储到日志文件中。
注意!!!!:标量数据,传入的tensor应当是标量张量(scalar tensor),也就是只包含一个数值的张量。如果传入的是非标量张量,例如:shape为[2,3]的张量,则会报错。因此,在使用tf.summary.scalar函数时,需要确保传入的tensor是标量张量。
tf.summary.scalar函数用于记录标量值。需要传入两个参数:name和tensor。例如:
loss_summary = tf.summary.scalar(name='loss', tensor=loss)
这行代码会生成一个名为"loss"的summary,其中记录了当前的损失值。
2.函数:tf.summary.histogram
记录张量数据(如权重、偏置项等),可以使用tf.summary.histogram()函数。该函数也需要提供一个名称和实际的张量数据。类似地,在训练过程中每次调用该函数都会记录对应的名称和张量数据,并将它们转换成直方图形式存储到日志文件中。
tf.summary.histogram函数用于记录张量的分布情况。需要传入两个参数:name和tensor。例如:
weights_summary = tf.summary.histogram(name='weights', tensor=weights)
这行代码会生成一个名为"weights"的summary,其中记录了权重张量的分布情况。
3.函数:tf.summary.image
tf.summary.image函数用于记录图像信息。需要传入三个参数:name、tensor和max_outputs。其中name和tensor与前面的函数相同,max_outputs指定了要记录的图像数量。例如:
image_summary = tf.summary.image(name='image', tensor=image, max_outputs=10)
这行代码会生成一个名为"image"的summary,其中记录了前10个图像的信息。
4.函数:tf.summary.merge
比如在我们模型中使用了多个 函数展示时候,使用这个函数将他们合并。
tf.summary.merge函数用于将多个summary合并成一个。通常在训练过程中,需要记录多个信息,比如损失值、权重分布等等。这些信息可以通过不同的summary进行记录,最后使用tf.summary.merge函数将它们合并起来。例如:
summaries = [loss_summary, weights_summary, image_summary]
merged_summary = tf.summary.merge(summaries)
这行代码将之前生成的三个summary合并成一个merged_summary。
5.函数:tf.summary.FileWriter
tf.summary.FileWriter函数用于将summary写入磁盘,以便在TensorBoard中查看。需要传入两个参数:logdir和graph。其中logdir指定了保存summary的目录,而graph指定了当前的计算图(可选)。例如:
with tf.summary.FileWriter(logdir='logs', graph=tf.get_default_graph()) as writer:
writer.add_summary(merged_summary, global_step=step)
'''
一般使用tensorboard工具前先执行代码生成摘要日志
'''
这段代码将之前生成的merged_summary写入logs目录,并指定了当前的计算图。同时,还通过global_step参数指定了当前的步数,方便在TensorBoard中进行对比和分析
(3). 模块中.add_summary()函数
writer.add_summary()函数是用于将summary写入磁盘的函数,可以将生成的summary记录到指定的目录中,以便在TensorBoard中进行可视化分析。
这个函数需要传入两个参数:summary和global_step。其中,summary是通过tf.summary模块生成的summary对象,可以是一个单独的summary,也可以是多个summary合并后的结果;global_step表示当前的训练步数,用于在TensorBoard中进行对比和分析。
在使用writer.add_summary()函数时,通常会将它放在训练循环中,每当执行一次训练迭代时就调用一次该函数,以实时记录训练过程中的各种信息。例如:
with tf.summary.FileWriter(logdir) as writer:
for step in range(num_steps):
# 执行训练操作,得到loss值和其他参数
loss, acc, summary = sess.run([train_op, accuracy, merged_summary])
# 将summary写入磁盘
writer.add_summary(summary, global_step=step)
四、可视化实践
使用:
在项目文件夹下:
执行 tensorboard --logdir='logss' ,logss是summary写入磁盘的地址:
会生成 TensorBoard 1.14.0 at http://ubuntu:6006/ (Press CTRL+C to quit)点击网址即可。
例如:
代码: 用一个简单的 线性回归 使用tensorboard工具
import tensorflow as tf
from tensorflow.python.client import device_lib
import os
print(device_lib.list_local_devices())
tf.reset_default_graph()
with tf.device("/device:cpu:0"):
# create w and b init 0.0
w = tf.Variable(0.0, name='weight')
b = tf.Variable(0.0, name='bias')
# create input and out
x = tf.placeholder(dtype=tf.float32, shape=[None])
out = tf.placeholder(dtype=tf.float32, shape=[None])
# create loss and opt
y = w * x + b
loss = tf.reduce_mean(tf.square(y - out))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(loss)
config = tf.ConfigProto()
config.log_device_placement=True
output_scalar = tf.reduce_mean(y) # 将 y 变量转换为标量
loss_scalar = tf.reduce_mean(loss)
# 记录标量数据(输出结果和损失值) 注意:此处应该是标量
tf.summary.scalar('output', output_scalar)
tf.summary.scalar('loss', loss_scalar)
# 记录张量数据(权重和偏置项)
tf.summary.histogram('weight', w)
tf.summary.histogram('bias', b)
# 记录网络结构
with tf.name_scope('hidden'):
h = tf.nn.sigmoid(y)
tf.summary.histogram('activation', h)
# train model
with tf.Session(config=config) as sess:
# # 设置 XLA_CPU 环境变量
# os.environ['TF_XLA_FLAGS'] = '--tf_xla_cpu_global_jit'
# 合并所有的摘要操作
merged = tf.summary.merge_all()
# 创建摘要写入器 将`summary`写入磁盘的函数
writer = tf.summary.FileWriter('./logss', sess.graph)
tf.global_variables_initializer().run(session=sess)
for i in range(100000):
summary,_, loss_val, w_val, b_val = sess.run(
[merged,train_op, loss, w, b],
feed_dict={x: [1, 23, 4, 5, 7, 5, 7], out: [3, 5, 7, 9, 11, 13, 15]}
) #注意 输入的数据 形状要一致,避免输出与预测值得形状不一致问题
if i % 100 == 0:
print('Step {}: loss = {}, w = {}, b = {}'.format(i, loss_val, w_val, b_val))
# 将生成的summary记录到指定的目录中
writer.add_summary(summary, i)
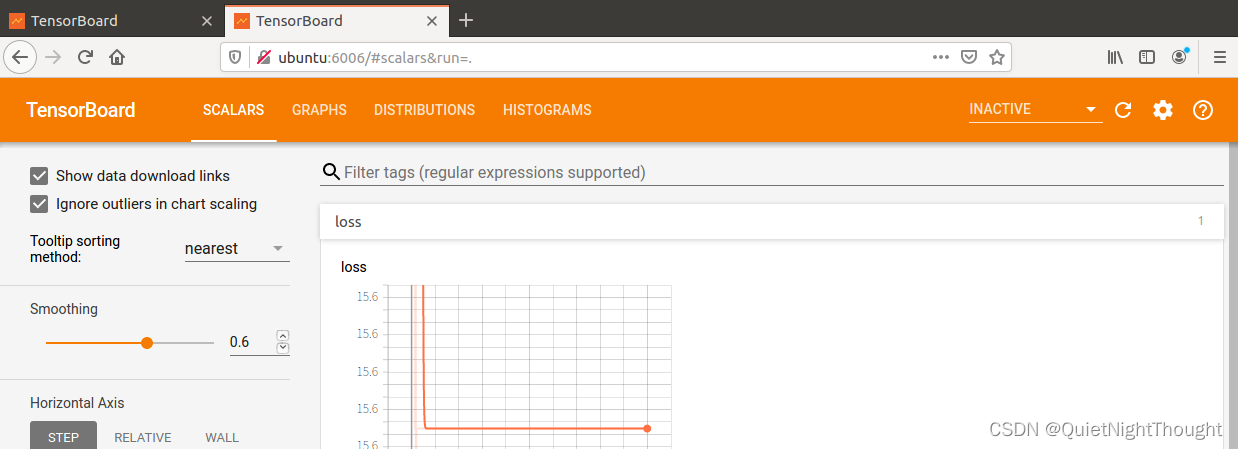
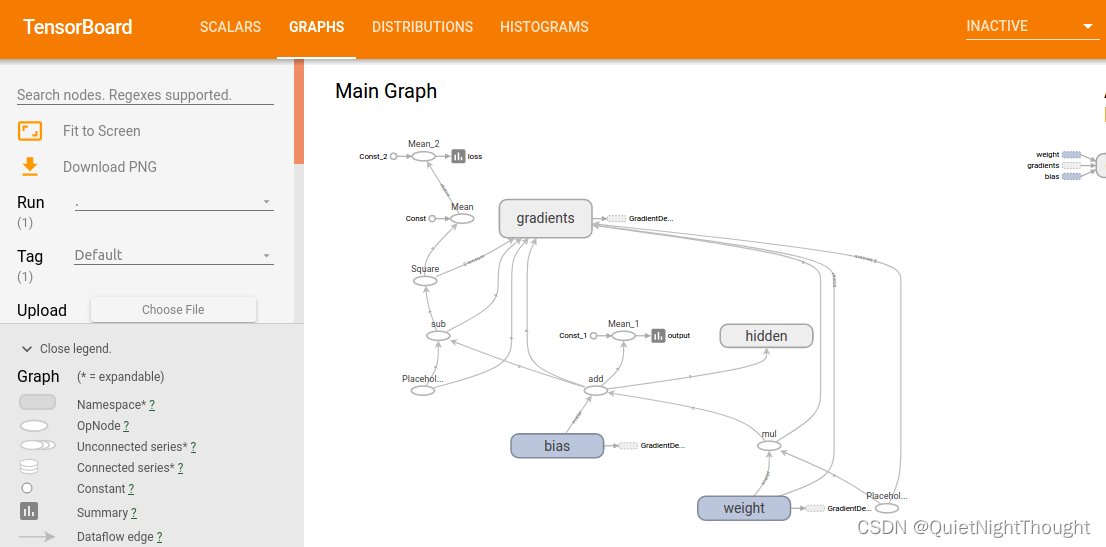
结果展示:
不同的字段下代表着不同的可视化信息