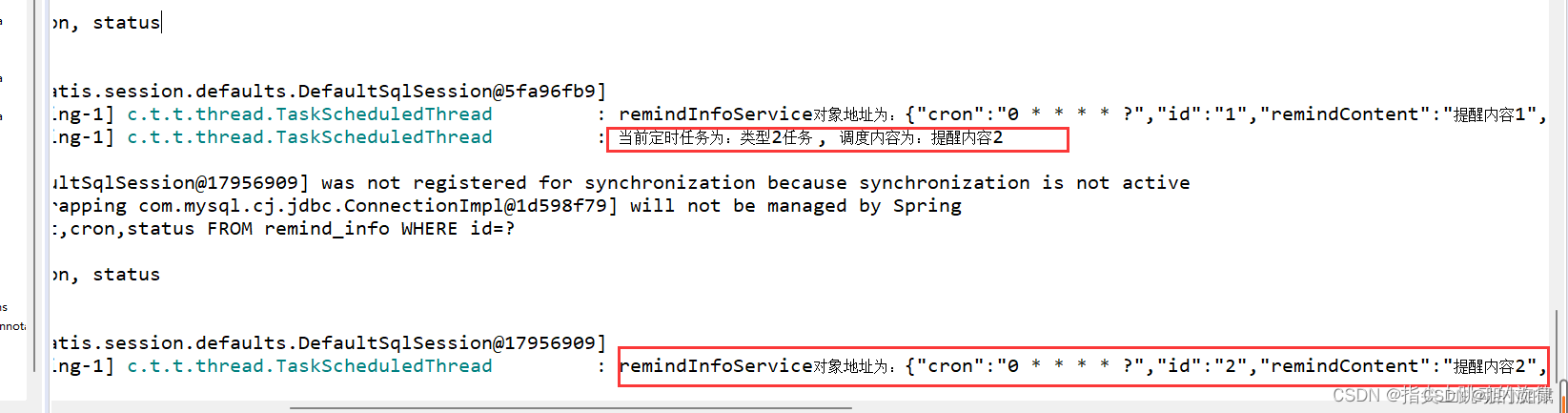
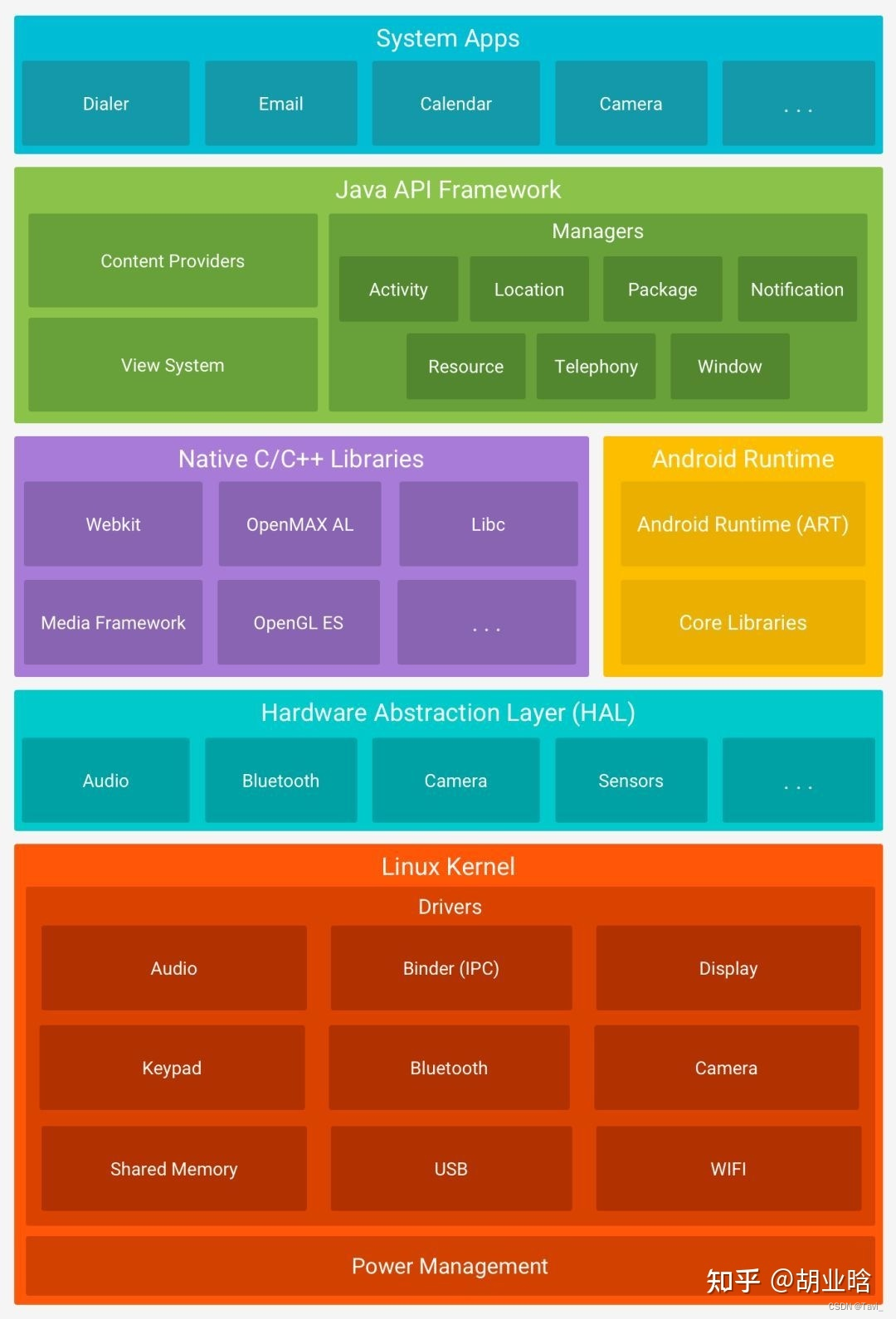
指标是 IT 服务管理的核心,可提供运营见解并帮助确定持续改进的领域。通常的服务台指标有助于展示内部运营效率。为 例如,衡量在指定时间内解决的工单数量的 SLA 是展示服务台效率的关键因素。另一方面,故障指标可帮助团队识别 IT 基础架构中的薄弱环节 并帮助评估对故障事件的响应。这有助于 IT 团队最大程度地减少故障可能对关键系统造成的级联效应。IT服务台要跟踪的关键故障指标:
- 平均无故障时间(MTBF)
- 平均故障时间(MTTF)
- 平均修复时间(MTTR)
平均无故障时间 (MTBF)
当 IT 基础架构资产(无论是网络、服务器、工作站等)频繁出现故障时,它们会对 IT 和业务服务的可用性产生级联影响。这些中断导致收入损失 和声誉。如果特定 IT 资产经常停机,通常需要维修或更换。在此之前,它有助于调查和了解资产经常下跌的原因以及在什么情况下下跌。这 帮助规划资产维护并提高系统可用性。MTBF 是帮助确定停机原因并帮助缓解它们或规划快速恢复和提高 IT 系统可用性的指标。

如果特定 IT 资产的 MTBF 较低,则意味着该资产经常停机,从而导致 IT 和业务中断。
平均无故障时间示例
在企业中,每当应用新的 Windows 固件更新时,对存储驱动器的新更新都会失败。这种情况发生了几次,MTBF变得更糟。在分析问题后,该团队确定 第三方驱动程序导致执行更新所需的 API 未实现或出现故障。计划新更新时,如果第三方驱动程序未实现必要的 API,则存在 探索两种可能的解决方案。将 API 与 SATA 和 NVMe 存储协议的 Windows 替代方案交换,或从 OEM 获取新的、更受支持的驱动程序版本,可以帮助实现更新, 修复错误,并关闭安全漏洞。监视和跟踪驱动程序升级和停机时间有助于提高存储驱动器的可用性。
如何改善平均无故障时间
- 实施一个流程来观察资产运行状况,以跟踪和监视故障。这有助于确定中断的原因。
- 分析问题的根本原因,以提高意识、解决长期原因并提高资产性能。
- 制定快速响应策略,以有效处理和减少影响运营的停机时间。目标是实现更少的中断间隔时间。
平均故障时间(MTTF)
资产经常发生故障可能会中断组织的 IT 运营,并导致 IT 基础架构恶化和性能不佳。MTTF 指标有助于确定资产、设备、 或组件。对于 MTTF 较低的 IT 资产和组件,更换 IT 组件而不是修复组件通常更省时,并将运营影响和成本降至最低。
这尤其适用于链接到基础架构的关键操作元素(如大型机服务器堆栈或网络接入点)的 IT 组件。

如果资产的 MTTF 不利且经常出现故障,则表明 IT 资产不可靠,需要频繁更换以避免影响 IT 运营。
平均故障时间示例
在IT软件开发公司中,当电缆与数据和网络服务器堆栈中的交换机连接或断开连接时,网络电缆会松动,断开连接或损坏。这导致文件变成 由于数据传输中断而损坏。网络团队的进一步分析显示,CAT6 RJ45跳线上的无钩塑料盖不断断裂。这是由于电缆是从制造商处采购的 谁使用廉价材料。然后,IT团队用质量更好的电缆替换了旧电缆,以确保将来移动电缆时不会出现数据丢失或损坏等问题。
如何提高平均不停产率
- 通过采购高质量资产和退役低质量和低成本资产来延长资产寿命。
- 通过安排对与关键资产相关的组件的定期检查,防止业务运营的大规模中断。
- 实施实时库存流程,估计资产的运行时间,从而降低资产存储的间接成本。
平均修复时间(MTTR)
当关键 IT 系统出现故障时,IT 团队必须尽快让系统运行。恢复 IT 系统的延迟可能导致收入损失并影响关键业务运营。组织良好的恢复和应对 系统可以帮助 IT 团队响应计划外停机并有效地恢复运营。MTTR 衡量修复或排除故障并将其恢复到运行能力所需的平均时间。

停机时间的成本随着 MTTR 的增加而增加。高 MTTR 表明您的恢复和响应操作不快速有效。系统故障是不可避免的,但 MTTR 使团队能够对资产故障做出反应 及时和战略性地进行。
平均修复时间示例
一家软件公司由于代码中的漏洞而面临对其正在开发的视频游戏的零日攻击,这次攻击扰乱了Wi-Fi和监控系统等操作,这导致攻击者访问组织的 网络域和机密业务文件。网络安全团队向员工通报了零日攻击以及他们可以在哪里报告这些攻击。组织中的每个 IT 资产都配备了下一代防病毒软件(NGAV)。该攻击禁用了LAN和员工自助服务门户,削弱了组织的运营。在攻击发生后的一个小时内,网络安全团队得到了NGAV能力的通知和帮助,该能力利用了威胁分析和用户的行为模式,并识别可疑活动。网络安全团队立即运行补丁管理脚本来纠正代码中的漏洞,并锁定其本地网络,以避免进一步影响操作和数据盗窃。
如何降低平均修复时间
- 高效的资产管理策略通过识别瓶颈并指定维修或更换资产来帮助推动更好的决策。这样可以节省资金和存储空间。
- 定义技术人员的职责和角色,以简化事件检测和解决流程。
- 为技术人员提供详细的标准操作程序,以减少停机期间的沟通不畅和混乱。
- 使用企业资产管理解决方案测量 MTTR,该解决方案集中了资产维护和监控信息。这也有助于优化资产利用率、收集资产数据并预测可能的停机时间。
追踪的关键故障指标的好处
这些故障指标可帮助团队识别运营瓶颈及其对事件的响应能力。它们使 IT 团队能够通过查明持续事件的根本原因来实现更高的运营效率。 IT 团队可以通过清楚地了解 IT 运营受到影响的领域来改进其事件响应策略。这些指标可以通过将它们用作 KPI 而不仅仅是绩效来在组织中实施 目标。这些指标指出了流程简化和运营改进的领域,而不仅仅是要达到的目标。
- MTBF :可以更好地了解服务台在防止未来中断方面的有效性。
- MTTF :可帮助管理员了解资产的生命周期及其可靠性。
- MTTR :表示修复所花费的时间以及 IT 团队诊断中断的速度。
ServiceDesk Plus 是一种服务管理解决方案,它将 IT 服务管理、IT 资产管理和 CMDB 与人力资源、设施和财务等部门的企业服务管理功能相结合。