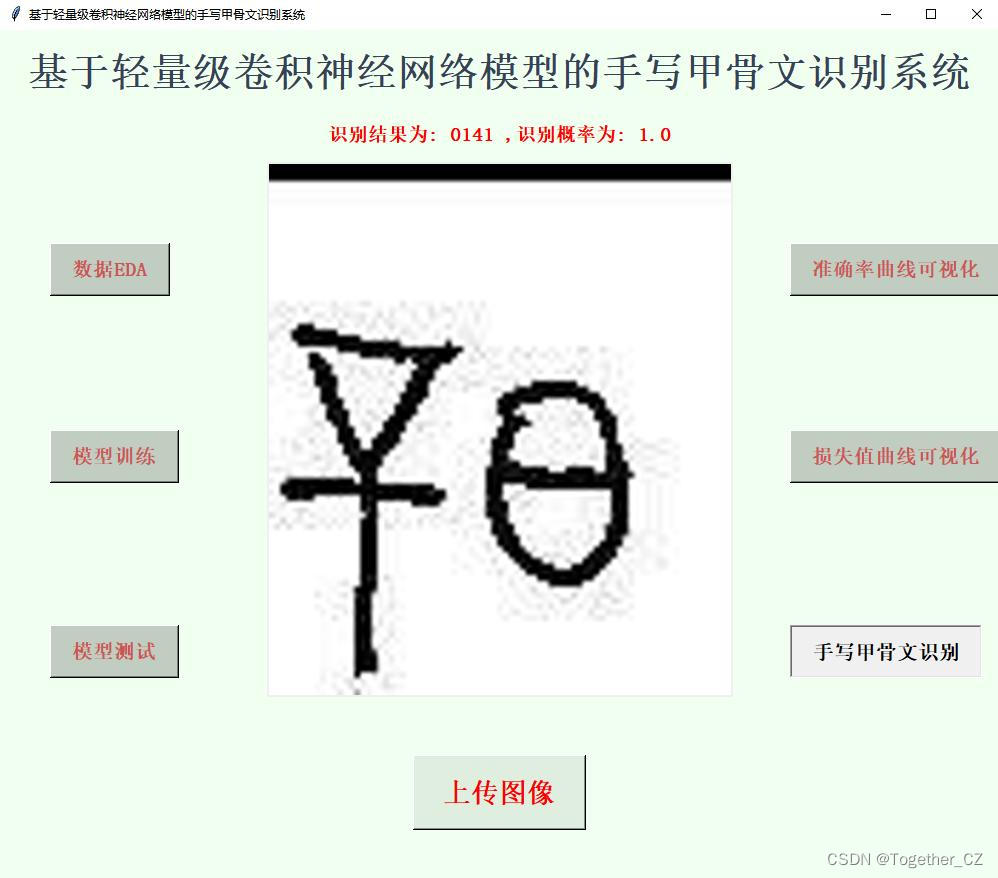
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Tomcat 部署及优化
- 一、Tomcat 概述
- 1.Tomcat 介绍
- 2.Tomcat 核心组件
- 3.Tomcat 组件结构
- 4.Tomcat 处理请求过程
- 二、Tomcat 部署步骤
- 1.关闭防火墙
- 2.安装JDK
- 3.设置JDK环境变量
- 4.安装启动Tomcat
- 5.优化tomcat启动速度
- 三、Tomcat 虚拟主机配置
- 1.创建 ztm 和 zs 项目目录和文件
- 2.修改 Tomcat 主配置文件 server.xml
- 3.客户端浏览器访问验证
- 四、Tomcat 优化
- Tomcat 配置文件参数优化
一、Tomcat 概述
1.Tomcat 介绍
Tomcat 是 Java 语言开发的,Tomcat 服务器是一个免费的开放源代码的 Web 应用服务器,是 Apache 软件基金会的 Jakarta 项目中的一个核心项目,由 Apache、Sun 和其他一些公司及个人共同开发而成。
Tomcat 属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试 JSP 程序的首选。一般来说,Tomcat 虽然和 Apache 或者 Nginx 这些 Web 服务器一样,具有处理 HTML 页面的功能,然而由于其处理静态 HTML 的能力远不及 Apache 或者 Nginx,所以 Tomcat 通常是作为一个 Servlet 和 JSP 容器,单独运行在后端。
- 免费的、开放源代码的Web应用服务器
- Apache软件基金会(Apache Software Foundation)Jakarta项目中的一个核心项目
- 由Apache、Sun和一些公司及个人共同开发而成
- 深受Java爱好者的喜爱,并得到部分软件开发商的认可
- 目前比较流行的Web应用服务器
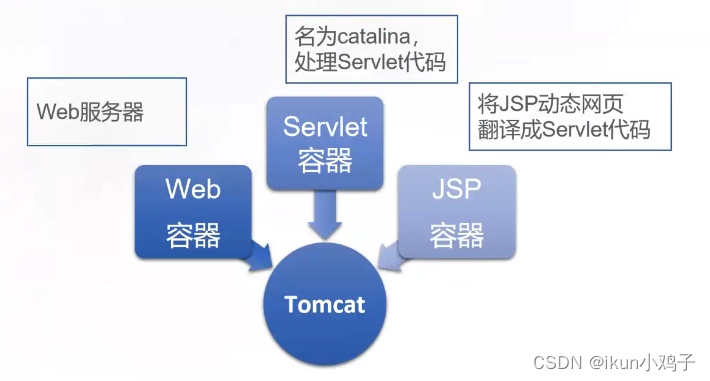
2.Tomcat 核心组件
web容器:完成 Web 服务器的功能(https请求)
servlet容器:名字为 catalina,用于处理 Servlet 代码
jsp容器:用于将 JSP 动态网页翻译成 Servlet 代码
3.Tomcat 组件结构
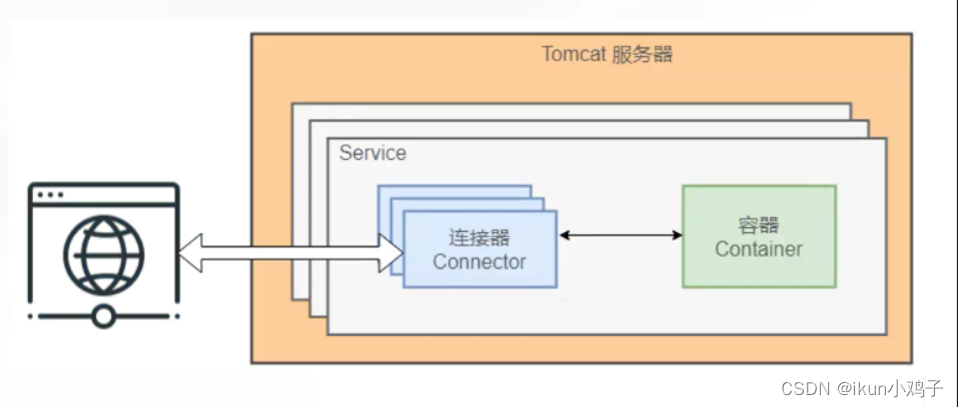
Tomcat 的核心功能有两个,分别是负责接收和反馈外部请求的连接器 Connector,和负责处理请求的容器 Container。 其中连接器和容器相辅相成,一起构成了基本的 web 服务 Service。每个 Tomcat 服务器可以管理多个 Service。
● Connector:负责对外接收和响应请求。它是Tomcat与外界的交通枢纽,监听端口接收外界请求,并将请求处理后传递给容器做业务处理,最后将容器处理后的结果响应给外界。
● Container:负责对内处理业务逻辑。其内部由 Engine、Host、Context和Wrapper 四个容器组成,用于管理和调用 Servlet 相关逻辑。
● Service:对外提供的 Web 服务。主要包含 Connector 和 Container 两个核心组件,以及其他功能组件。Tomcat 可以管理多个 Service,且各 Service 之间相互独立。
Container 结构分析:
每个 Service 会包含一个 Container 容器。在 Container 内部包含了 4 个子容器:
4个子容器的作用分别是:
(1)Engine:引擎,用来管理多个虚拟主机,一个 Service 最多只能有一个 Engine;
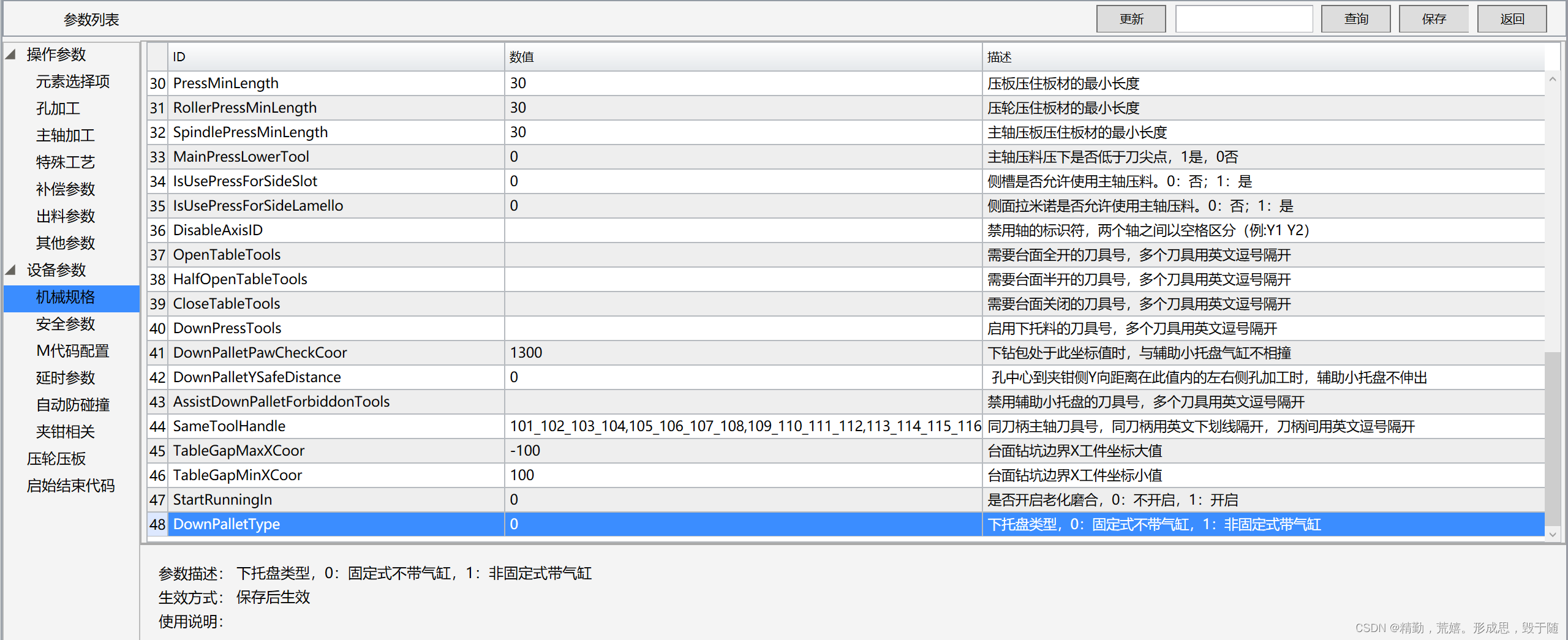
(2)Host:代表一个虚拟主机,也可以叫站点,通过配置 Host 就可以添加站点;
(3)Context:代表一个 Web 应用,包含多个 Servlet 封装器;
(4)Wrapper:封装器,容器的最底层。每一 Wrapper 封装着一个 Servlet,负责对象实例的创建、执行和销毁功能。
Engine、Host、Context 和 Wrapper,这四个容器之间属于父子关系。
容器 由一个引擎可以管理多个虚拟主机。每个虚拟主机可以管理多个 Web 应用。每个 Web 应用会有多个 Servlet 封装器。
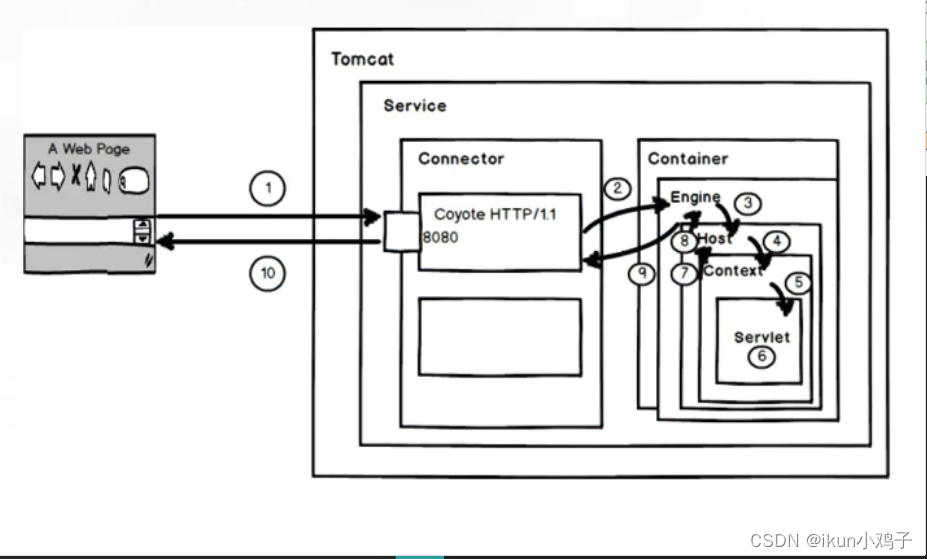
4.Tomcat 处理请求过程
1、用户在浏览器中输入网址,请求被发送到本机端口 8080,被在那里监听的 Connector 获得;
2、Connector 把该请求交给它所在的 Service 的 Engine(Container)来处理,并等待 Engine 的回应;
3、请求在 Engine、Host、Context 和 Wrapper 这四个容器之间层层调用,最后在 Servlet 中执行对应的业务逻辑、数据存储等。
4、执行完之后的请求响应在 Context、Host、Engine 容器之间层层返回,最后返回给 Connector,并通过 Connector 返回给客户端。
二、Tomcat 部署步骤
- 在部署 Tomcat 之前必须安装好 jdk,因为 jdk 是 Tomcat 运行的必要环境。
1.关闭防火墙
jdk-8u201-linux-x64.rpm
apache-tomcat-9.0.16.tar.gz
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
2.安装JDK
cd /opt
rpm -qpl jdk-8u201-linux-x64.rpm
rpm -ivh jdk-8u201-linux-x64.rpm
java -version
3.设置JDK环境变量
vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
source /etc/profile.d/java.sh
java -version
- JDK :java development kit (java开发工具)
- JRE :java runtime environment (java运行时环境)
- JVM :java virtuak machine (java虚拟机),使java程序可以在多种平台上运行class文件。
- CLASSPATH:告诉jvm要使用或执行的class放在什么路径上,便于JVM加载class文件。
- tools.jar:是系统用来编译一个类的时候用到的,即执行javac的时候用到。
- dt.jar:dt.jar是关于运行环境的类库,主要是swing包。
首先使用文本工具编写java源代码,比如 Hello.java ;
在命令行中,输入命令:javac Hello.java,对源代码进行编译,生成 class 字节码文件;
编译完成后,如果没有报错信息,输入命令:java Hello,运行 class 字节码文件,由 JVM 对字节码进行解释和运行,打印 “Hello World”。
vim Hello.java
#类名、接口名命令:英文大小写字母、数字字符、$和_,不能使用关键字和数字开头;
一个单词命名时第一个单词的首字母要大写;多单词组成时,所有单词的首字母大写:XxxYyyZzz(大驼峰命名法)
public class Hello {
public static void main(String[] args){
System.out.println(“Hello world!”);
}
}
javac Hello.java
java Hello
4.安装启动Tomcat
cd /opt
tar zxvf apache-tomcat-9.0.16.tar.gz
mv apache-tomcat-9.0.16 /usr/local/tomcat
##启动tomcat ##
#后台启动
/usr/local/tomcat/bin/startup.sh
或
/usr/local/tomcat/bin/catalina.sh start
#前台启动
/usr/local/tomcat/bin/catalina.sh run
netstat -natp | grep 8080
vim /usr/lib/systemd/system/tomcat.service
[Unit]
Description=tomcat server
Wants=network-online.target
After=network.target
[Service]
Type=forking
Environment="JAVA_HOME=/usr/java/jdk1.8.0_201-amd64"
Environment="PATH=$JAVA_HOME/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
Environment="CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar"
ExecStart=/usr/local/tomcat/bin/startup.sh
ExecStop=/usr/local/tomcat/bin/shutdown.sh
Restart=on-failure
[Install]WantedBy=multi-user.target
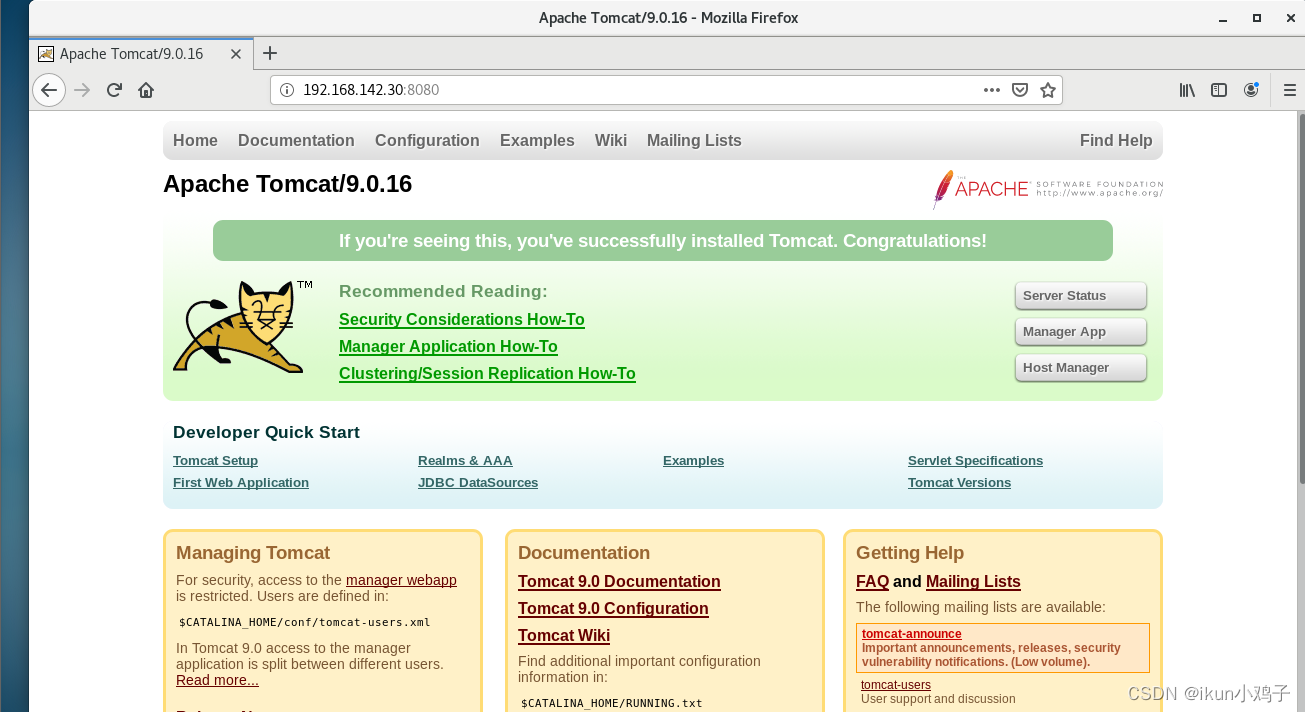
浏览器访问Tomcat的默认主页 http://192.168.142.30:8080
5.优化tomcat启动速度
第一次启动tomcat可能会发现 Tomcat 启动很慢,默认情况下可能会需要几十秒,可以修改jdk参数进行改。
vim /usr/java/jdk1.8.0_201-amd64/jre/lib/security/java.security
--117行--修改
securerandom.source=file:/dev/urandom
从新启动tomcat
/usr/local/tomcat/bin/shutdown.sh
/usr/local/tomcat/bin/startup.sh
●tomcat 启动慢的原因是随机数产生遭到阻塞,遭到阻塞的原因是 熵池大小 。
●/dev/random:阻塞型,读取它就会产生随机数据,但该数据取决于熵池噪声,当熵池空了,对/dev/random 的读操作也将会被阻塞。
●/dev/urandom:非阻塞的随机数产生器,它会重复使用熵池中的数据以产生伪随机数据。这表示对/dev/urandom的读取操作不会产生阻塞,但其输出的熵可能小于/dev/random的。它可以作为生成较低强度密码的伪随机数生成器,不建议用于生成高强度长期密码。
●Linux内核采用熵来描述数据的随机性。熵(entropy)是描述系统混乱无序程度的物理量,一个系统的熵越大则说明该系统的有序性越差,即不确定性越大。在信息学中,熵被用来表征一个符号或系统的不确定性,熵越大,表明系统所含有用信息量越少,不确定度越大。计算机本身是可预测的系统,因此,用计算机算法不可能产生真正的随机数。但是机器的环境中充满了各种各样的噪声,如硬件设备发生中断的时间,用户点击鼠标的时间间隔等是完全随机的,事先无法预测。Linux内核实现的随机数产生器正是利用系统中的这些随机噪声来产生高质量随机数序列。内核维护了一个熵池用来收集来自设备驱动程序和其它来源的环境噪音。理论上,熵池中的数据是完全随机的,可以实现产生真随机数序列。为跟踪熵池中数据的随机性,内核在将数据加入池的时候将估算数据的随机性,这个过程称作熵估算。熵估算值描述池中包含的随机数位数,其值越大表示池中数据的随机性越好。
要目录说明:
●bin:存放启动和关闭 Tomcat 的脚本文件,如 catalina.sh、startup.sh、shutdown.sh
●conf:存放 Tomcat 服务器的各种配置文件,如主配置文件 server.xml 和 应用默认的部署描述文件 web.xml
●lib:存放 Tomcat 运行需要的库文件的 jar 包,一般不作任何改动
●logs:存放 Tomcat 执行时的日志
●temp:存放 Tomcat 运行时产生的文件
●webapps:存放 Tomcat 默认的 Web 应用项目资源的目录
●work:Tomcat 的工作目录,存放 Web 应用代码生成和编译文件
三、Tomcat 虚拟主机配置
很多时候公司会有多个项目需要运行,一般不会是在一台服务器上运行多个 Tomcat 服务,这样会消耗太多的系统资源。此时, 就需要使用到 Tomcat 虚拟主机。
例如现在新增两个域名 www.ztm.com 和 www.zs.com, 希望通过这两个域名访问到不同的项目内容。
1.创建 ztm 和 zs 项目目录和文件
mkdir /usr/local/tomcat/webapps/ztm
mkdir /usr/local/tomcat/webapps/zs
echo "This is ztm page\!" > /usr/local/tomcat/webapps/ztm/index.jsp
echo "This is zs page\!" > /usr/local/tomcat/webapps/zs/index.jsp
2.修改 Tomcat 主配置文件 server.xml
vim /usr/local/tomcat/conf/server.xml
--165行前--插入
<Host name="www.ztm.com" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false">
<Context docBase="/usr/local/tomcat/webapps/ztm" path="" reloadable="true" />
</Host>
<Host name="www.zs.com" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false">
<Context docBase="/usr/local/tomcat/webapps/zs" path="" reloadable="true" />
</Host>
从新启动tomcat
/usr/local/tomcat/bin/shutdown.sh
/usr/local/tomcat/bin/startup.sh

Host
name:主机名
appBase:Tomcat程序工作目录,即存放web应用程序的目录;相对路径为webapps,绝对路径为 /usr/local/tomcat/webapps
unpackWARs:在启用此webapps时是否对WAR格式的归档文件先进行展开;默认为true
autoDeploy:在Tomcat处于运行状态时放置于appBase目录中的应用程序文件是否自动进行deploy;默认为true
xmlValidation:是否验证xml文件执行有效性检验的标志
xmlNamespaceAware:是否启用xml命名空间,设置该值与xmlValidation为true,表示对web.xml文件执行有效性检验
Context
docBase:相应的Web应用程序的存放位置;也可以使用相对路径,起始路径为此Context所属Host中appBase定义的路径;
path:相对于Web服务器根路径而言的URI;如果为空"",则表示为此webapp的根路径 / ;
reloadable:是否允许重新加载此context相关的Web应用程序的类;默认为false
3.客户端浏览器访问验证
echo "192.168.80.100 www.ztm.com www.zs.com" >> /etc/hosts
浏览器访问 http://www.ztm.com:8080/ 页面显示This is ztm page!

浏览器访问 http://www.zs.com:8080/ 页面显示This is zs page!

HTTP 请求过程:
(1)Connector 连接器监听的端口是 8080。由于请求的端口和监听的端口一致,连接器接受了该请求。
(2)因为引擎的默认虚拟主机是 www.ztm.com,并且虚拟主机的目录是webapps。所以请求找到了 tomcat/webapps 目录。
(3)访问的路径为根路径,URI 为空,即空是 Web 程序的应用名,也就是 context。此时请求找到 /usr/local/tomcat/webapps/ztm 目录,解析 index.jsp 并返回。
四、Tomcat 优化
Tomcat默认安装下的缺省配置并不适合生产环境,它可能会频繁出现假死现象需要重启,只有通过不断压测优化才能让它最高效率稳定的运行。优化主要包括三方面,分别为操作系统优化(内核参数优化),Tomcat配置文件参数优化,Java虚拟机(JVM)调优。
Tomcat 配置文件参数优化
- 【redirectPort】如果某连接器支持的协议是HTTP,当接收客户端发来的HTTPS请求时,则转发至此属性定义的 8443 端口
- 【maxThreads】Tomcat使用线程来处理接收的每个请求,这个值表示Tomcat可创建的最大的线程数,即支持的最大并发连接数,默认值是 200。
- 【minSpareThreads】最小空闲线程数,Tomcat 启动时的初始化的线程数,表示即使没有人使用也开这么多空线程等待,默认值是 10。
- 【maxSpareThreads】最大备用线程数,一旦创建的线程超过这个值,Tomcat就会关闭不再需要的socket线程。默认值是-1(无限制)。一般不需要指定。
- 【processorCache】进程缓冲器,可以提升并发请求。默认值是200,如果不做限制的话可以设置为-1,一般采用maxThreads的值或者-1。
- 【URIEncoding】指定 Tomcat 容器的 URL 编码格式,网站一般采用UTF-8作为默认编码。
- 【connnectionTimeout】网络连接超时,单位:毫秒,设置为 0 表示永不超时,这样设置有隐患的。通常默认 20000 毫秒就可以。
- 【enableLookups】是否反查域名,以返回远程主机的主机名,取值为:true 或 false,如果设置为 false,则直接返回 IP 地址,为了提高处理能力,应设置为 false。
- 【disableUploadTimeout】上传时是否使用超时机制。应设置为 true。
- 【connectionUploadTimeout】上传超时时间,毕竟文件上传可能需要消耗更多的时间,这个根据你自己的业务需要自己调,以使Servlet有较长的时间来完成它的执行,需要与上一个参数一起配合使用才会生效。
- 【acceptCount】指定当所有可以使用的处理请求的线程数都被使用时,可传入连接请求的最大队列长度,超过这个数的请求将不予处理,默认为 100 个。
- 【maxKeepAliveRequests】指定一个长连接的最大请求数。默认长连接是打开的,设置为1时,代表关闭长连接;为-1时,代表请求数无限制
- 【compression】是否对响应的数据进行GZIP压缩,off:表示禁止压缩;on:表示允许压缩(文本将被压缩)、force:表示所有情况下都进行压缩,默认值为 off,压缩数据后可以有效的减少页面的大小,一般可以减小 1/3 左右,节省带宽。
- 【compressionMinSize】表示压缩响应的最小值,只有当响应报文大小大于这个值的时候才会对报文进行压缩,如果开启了压缩功能,默认值就是 2048。
- 【compressableMimeType】压缩类型,指定对哪些类型的文件进行数据压缩。
- 【noCompressionUserAgents=“gozilla, traviata”】对于以下的浏览器,不启用压缩
#如果已经进行了动静分离处理,静态页面和图片等数据就不需做 Tomcat 处理,也就不要在 Tomcat 中配置压缩了。
以上是一些常用的配置参数,还有好多其它的参数设置,还可以继续深入的优化,HTTP Connector 与 AJP Connector 的参数属性值,可以参考官方文档的详细说明进行学习。
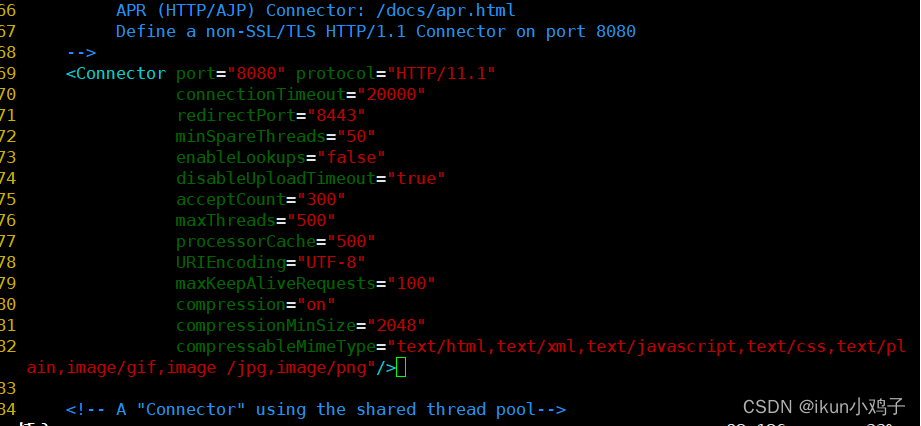
vim /usr/local/tomcat/conf/server.xml
......
<Connector port="8080" protocol="HTTP/11.1"
connectionTimeout="20000"
redirectPort="8443"
--71行--插入
minSpareThreads="50"
enableLookups="false"
disableUploadTimeout="true"
acceptCount="300"
maxThreads="500"
processorCache="500"
URIEncoding="UTF-8"
maxKeepAliveRequests="100"
compression="on"
compressionMinSize="2048"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain,image/gif,image /jpg,image/png"/>