cpu的衡量指标
使用率util:代表的是单位时间内CPU繁忙情况的统计。操作系统对cpu的管理就是利用周期的tick时钟中断,将cpu的使用划分时间片。每个时间片内去执行不同进程/线程里的代码。所以cpu的使用率统计其实也是以tick为单位的:统计周期内,有多少个tick是在执行进程/线程里的指令的。
top、pidstat等工具查看到的cpu使用率是指统计周期内cpu的占用情况
- 操作系统维度:统计周期内,所有的cpu中,在执行进程/线程指令占用的tick和统计周期内总共tick数的比值
- 进程维度/线程:统计周期内,当前进程/线程占用一个cpu执行当前进程/线程中指令和周期捏总的tick数的壁纸。因为这里的统计视角是一个cpu,如果系统中有多个cpu,而统计周期内进程占用了多个cpu来执行自己的指令,那这个统计值将超过100%
load:平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,即R+D状态的进程数量
代表的是当前系统对cpu的负担情况,平均负载要结合当前系统所拥有的cpu个数来看 ,理想情况下:平均负载等于CPU个数
top、uptime等工具,可以查看系统cpu的平均负载情况。这些工具的结果展示中,一般都有三个值:
- 近5min内,cpu的平均负载
- 近10min内,cpu的平均负载
- 近15min内,cpu的平均负载
使用率飙高排查思路
- 确定是哪个进程导致的、哪个线程导致的
- 确定哪个进程什么原因导致的
确定是哪个进程/线程导致的
这里最场景的工具就是top:

top的输出关于cpu使用率的统计包含两部分:
- 系统总体的cpu使用率:这的百分比就表示统计周期内被占用cpu的比例,这里的统计口径是系统内的所有cpu,所以100%表示,统计时间内所有cpu都被占用了,比如系统又4个cpu,如上的数据表示4*0.3%的cpu时间消耗在了用户态、4*0.3%的cpu时间消耗在了内核态、4*99.3%的cpu时间是闲置的。
- 进程维度的cpu使用率: 统计的对象就变成了具体的进程,口径是线程对单个cpu的占用情况,所以这里的100%表示,统计周期内当前进程独占了一个cpu,如果系统内有多个cpu且统计周期内进程占用了不止一个cpu,那么这个地方的值是可以超过100%的。
通过简单的top命令,其实就能够找到,到底哪个进程当前占用cpu做多的。如果想要更进一步想要知道到底是进程中哪个线程对cpu的消耗最大,可以加上-Hp参数,即:top -Hp ,则第二部分的pid就是线程id。
ps:如果占用率最高的进程是个java进程,那么接下来我们可能需要使用java工具分析java进程内的线程,但是jstack工具中的线程号是十六进制的,top -Hp输出的线程号是10进制的,所以这里需要转换下。
进程什么原因导致的cpu使用上升
cpu的使用率高,只能说明cpu比较繁忙,为了定位cpu繁忙到底在干啥么?
- 处理中断(执行中断服务)
- 执行内核函数
- 执行用户函数
- 等待IO
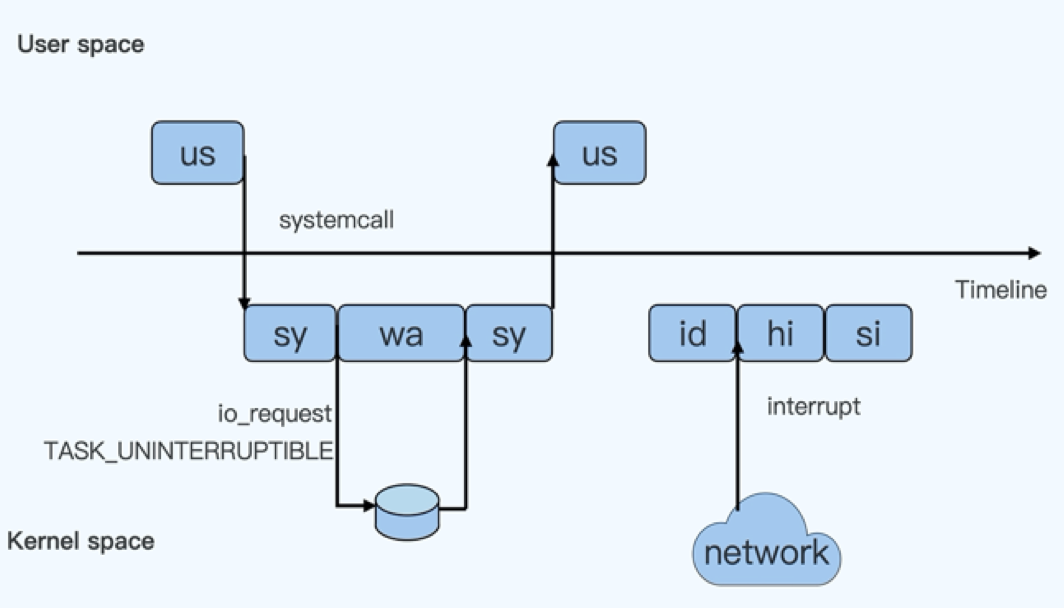
好在是操作系统提供的cpu监控工具中,是可以很方便的查看在每一阶段cpu的消耗统计的。
- top命令可以看到系统维度,在每个阶段cpu的消耗统计。
- pidstat -u -p进程号 可以看到进程维度的统计。-t可以看到线程维度的统计。
pidstat -u
pidstat -t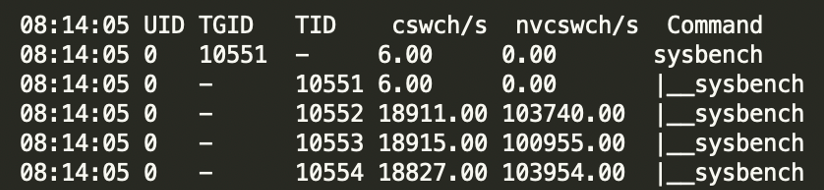
执行用户空间的函数的统计:us统计 vs ni统计
- us是user的缩写,表示的是执行用户函数所消耗的cpu情况。但是这部分统计不包含nice值为1到99的线程里函数执行所占用的cpu时间。
- ni:nice值为1到99用户线程执行消耗的cpu统计情况。
同样是用户函数执行消耗的cpu时间,为什么需要分开统计?
通过调整线程的nice值,可以调整改该线程占用的cpu时间。当我们将一个线程的nice值调大,那么就是期望这个线程获得较少的cpu。所以才cpu占用统计中,将调整过的nice值的进程单独来统计,方便我们观察nice值的调整效果。所以在排查cpu飚高的情况下,us和ni没有什么区别,ni反而是将导致飙高的进程范围给缩小了。
进程创建,nice值默认为0,这种nice值为0的进程运行所占cpu的统计是放在us项中的。我们可以通过renice来修改进程nice值,当你设置的值为1到99的时候,该进程运行所占cpu的统计就会在ni统计项中;如果nice值设置成负数,那么该进程运行所消耗cpu的统计不会出现在ni统计项中。
用户空间的函数,代表的就是我们的业务逻辑,所以正常情况下,我们期望的是cpu更多的都是在执行用户空间的函数。即us越高,cpu的利用率就越高(即cpu更多的是消耗在了执行业务逻辑上),这是我们期望的。
所以,我们期望是cpu的消耗统计中,us是尽量高的。如果us部分的统计突然变高,那就有可能是我们的业务代码出现了问题。
- 业务问题导致:比如业务流量突然上涨,出现了流量尖刺。这种情况,其实我们做好限流等自我保护性措施、并能够快速扩缩容
- 非业务导致:出现了频繁的gc、代码bug出现了死循环等,这种情况就需要排查并处理了。
在cpu调度使用上,都是一线程为基本单位的。为了确定到底us统计的cpu标高到底是什么原因,那么其实我们就需要确定到底是哪个线程引起的就好了,所以进一步排查到底是哪个线程因为的us飙高:
- 首先:查看进程中,线程维度的cpu统计
- top -Hp 进程
- pidstat -t 进程号
通过这两个命令,基本上就能分析出到底是哪些线程消耗的cpu最多。那么接下来就是要确定这个线程到底是干啥的?
- 再次:jstack是可以打印出线程相关的信息,比如线程号、线程名、状态、堆栈等。但是jstack里展示的线程号是16进制的,而top、pidstat等操作系统提供的命令展示的线程号是十进制的,所以需要做一个进程转换,才能方便的对应上jstack输出的线程号和top/pidstat等这些操作系统工具输出的线程号。
- 然后:根据jstack中的线程名,大概就能看出这个线程到底是干啥的。据此很多情况也能分析各七七八八了。
- 最后:如果根据jstack的输出判断不了现成到底在干啥,那么就只能使用一些追踪工具了。比如perf等
一些常见的线程
- 如果发现消耗cpu高的是gc线程,那么说明出现了频繁的gc,这个时候就应该去排查gc问题。
- 如果发现是tomcat等web容器的线程,
- 那么首先应该应该注意下我们的rest服务监控是否有尖刺、如果有尖刺,尖刺下降后cpu的使用率是否恢复了;如果恢复了,说明cpu的突然飙高大概率就是rest流量上涨引起的;
- 如果没有尖刺或者尖刺消失,cpu的使用率依然很高,那就需要排查到底哪个rest接口导致的。这种情况,大概率是我们的业务逻辑不合理、或者bug导致的,比如死循环等。
- 如果我们是在上线期间,那么应该回滚变更后观察,如果回滚后cpu使用率恢复正常,那么说明是变更导致的,则应该检查变更代码。
- 如果不是变更导致的,那么就比较麻烦了,那么多的rest接口、那么多的逻辑要排查就不那么容易了,可能就需要借助一些追踪工具,比如perf等。最后的最后,我们才去考虑是因为web容器的问题导致cpu飚高(本身设计实现不合理、或者是我们使用不合理),因为毕竟这都是被大量使用和测试的开源工具,出错概率相对是比较低的,但历史上也不是没有出现过
- 如果是rpc线程,道理同tomcat等web容器的线程
执行内核函数高
在统计执行内核函数占用cpu的统计上,其实最主要的就是区分了到底是执行中断服务消耗的cpu 还是执行非中断服务消耗的cpu。
cpu需要在内核态执行的函数一定是操作系统的内核代码,我们常见的主要包括:
- cpu上线文切换的处理
- 中断服务。比如硬件中断信号的响应、tcp/ip协议的解析处理等等
基本概念之上下文切换
cpu上下文切换有三种情况:
- 进程上下文切换:cpu的使用权从一个进程切换到另一个进程。
- 保存当前进程用户态的现场数据,比如虚拟内存、栈等
- 系统调用:切换到内核态,然后分配cpu的使用权(其实就是寄存器、内核栈等数据变更)
- 加载新进程的上次切换保存下来的现场数据。
- 线程上下文切换:这里特指相同进程内的不同线程的上线文切换,即将cpu的使用权从相同进程的一个线程切换到另外一个线程执行。不同进程的线程切换其实就是进程上下文切换。
因为是同一进程,他们是共享一个进程的虚拟内存等用户态自愿的,所以就不需要保存用户态的虚拟内存等现场数据,只是需要通过系统调用,在内核态处理当前线程的寄存器、内核栈等就可以了。所以线程上下文切换的代价比进程切换要小。 - 中断上下文切换:将cpu的使用权切换给中断,让cpu去执行中断服务。
按照是谁发起的分为,上下文切换可分为:
- 自愿上下文切换。比如进程运行完成、阻塞等待(比如等待IO等)、主动执行sleep等让出cpu的操作。
- 非自愿上下文切换:操作系统的调度。中断上下文切换、优先级更高的线程、公平调度
如果sys系统内核态cpu使用率是比较高的,首先就检查cpu的上下文切换次数。
- vmstat:只能看到上下文切换的次数

期中的cs列就是上线文切换次数。这里的r和b列分别是运行态和阻塞态的线程数,这对分析cpu情况也是有帮助的。 - pidstat:更细粒度的区分了是自愿上线问切换、还是非自愿的上线文切换。通过-w来输出上下文切换的统计。
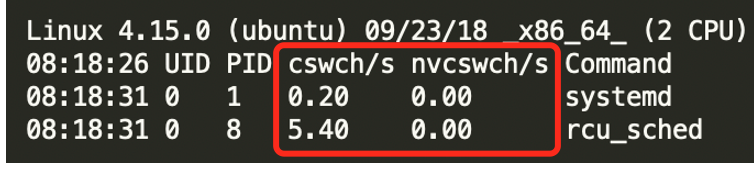
cswch/s :每秒自愿上线文切换次数
nvcswch/s(none-volunteer context switch):每秒非自愿上线文切换次数
基本概念之中断
查看终端统计会稍微麻烦一点,直接去操作系统通过文件系统/proc对外提供的数据访问方式:
- /proc/interrupts:每个cpu上的硬中断的统计情况
- /proc/softirqs:每个cpu上按软中断类型的统计情况。
sys vs softirq(si) vs hardirq(hi) 三个统计项
- sys:表示的是执行内核代码消耗的cpu时间,但是不包含执行中断函数消耗的cpu时间
- hardirq/hi:hard interrupt的缩写,表示的是执行相应硬中断的中断服务消耗的cpu时间
- si/softriq:soft interrupt的缩写,表示的是执行相应软中断的中断服务消耗的cpu时间
如果是sys比较高:
- vmstat查看系统的上下文切换次数、pidstat -w查看自愿/非自愿的上下文切换次数(如果有监控更好,能看直观看到变化趋势是更好的)
- 如果上下文切换次数变高了,那么是很有可能,就是因为上下文切换导致的cpu sys飙高
- 如果是自愿上下文切换次数非常高。那么首先就结合iowait的统计项,看下是不是出现了大量的io操作,因为io阻塞/就绪导致的上线文切换变高
- 如果是非自愿上下文切换非常高,那说明是操作系统调度导致的。
- 查看线程监控,看看是不是有大量的短命线程,线程创建以及运行结束后,导致线程切换。ps:对于不使用线程池,每个请求用一个线程来处理,是容易出现这种情况的
- 结合si/si/iowait等的监控统计、中断次数统计,确定是否是因为大量中断导致的线程频繁切换。
如果是si/hi飙高:
如果是hi飚高,因为硬中断的中断服务逻辑很简单,处理效率非常高,所以理论上它不应该占用很多cpu资源,如果hi变高了,那大概率是因为中断太多了。那就去/proc/interrupts检查一下硬中断的次数是不是变高了很多。
中断处理的下半段就是软中断,hi上去了,si缺很低,几乎不会出现这种情况,所以还可以结合/proc/softirqs的情况,判断到底是哪类中断上去了,是网络io?磁盘io?还是其他。
空闲统计idle vs iowait
这两个维度的统计只有top命令会输出,而且只有系统维度的统计,没有线程维度的统计。
- idle:表示的是CPU空闲的比例,但不包含因等待io空闲。
- iowait:也表示cpu空闲的比例,但是是至少有一个线程是因为io阻塞等待而导致的。
load飙高
平均负载是统计周期内,R状态+D状态的进程数。所以load飙高可能是R状态进程数增多,也可能是D状态线程数增多。
top、uptime等工具,可以查看系统cpu的平均负载情况。这些工具的结果展示中,一般都有三个值:
- 近5min内,cpu的平均负载
- 近10min内,cpu的平均负载
- 近15min内,cpu的平均负载
近15min高,但近5min小了,其实说明负载在下降,在恢复正常,往往没什么问题。如果禁5min依然很高,那就需要排查了。结合CPU使用率、以及不同状态的线程数来排查。
top命令除了会展示load、cpu使用率,还会展示不同状态的进程数。这里的running就是R状态的,而sleeping可以姑且认为就是D状态的(不准确)。
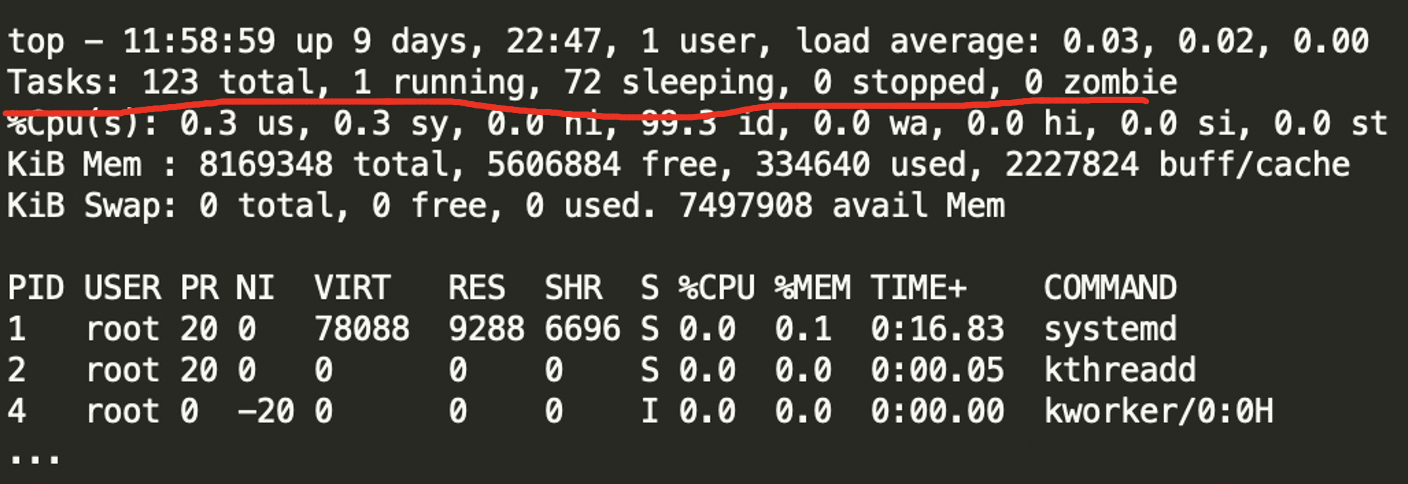
然后结合cpu使用率,凡是占用了cpu时间片的,那一定都是在R状态上的。所以,根据这些基本上就可以确定到底是什么原因引起的load飙高了。
- 如果是R状态的线程数增多,那基本上也就意味这cpu的使用率也会很高,那么排查思路就和CPU使用率飙高一样
- 如果是D状态的线程数增多,基本上可以确定是系统的IO增加了。这个时候就需要结合业务上的流量监控,看下是否是业务流量尖刺导致的?是否是IO性能导致的?