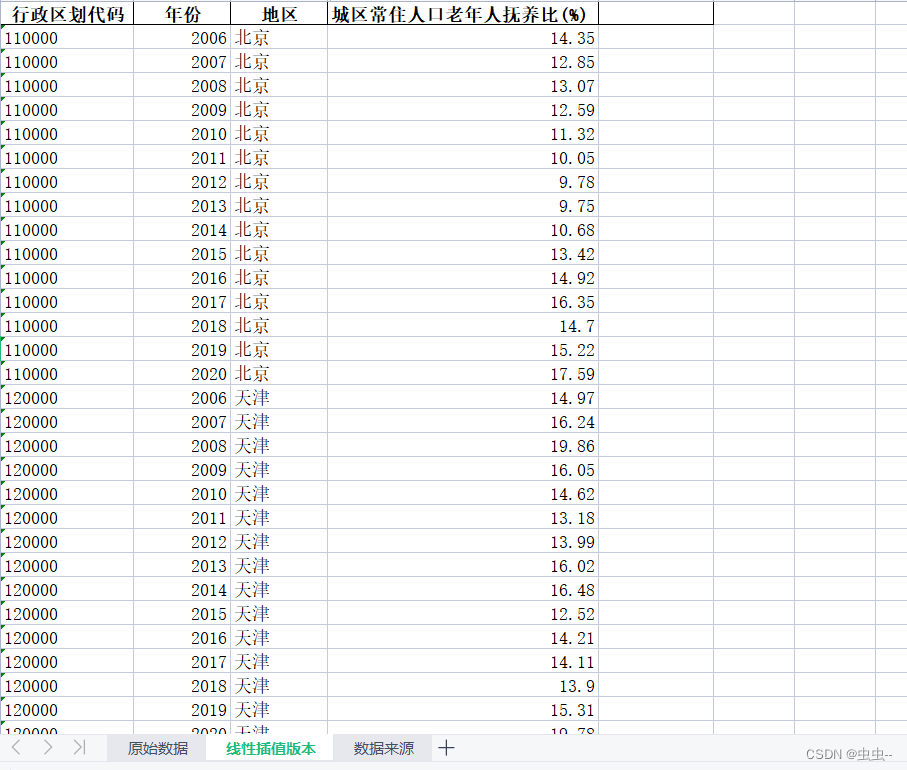
目录
编辑
SegmentationModel类
DetectionModel类
推理阶段
DetectionModel--forward()
BaseModel--forward()
Segment类
Detect--forward
SegmentationModel类
定义model将会调用models/yolo.py中的类SegmentationModel。该类是继承父类--DetectionModel类。
class SegmentationModel(DetectionModel): # SegmentationModel这个类是继承了DetectionModel这个类
# YOLOv5 segmentation model
def __init__(self, cfg='yolov5s-seg.yaml', ch=3, nc=None, anchors=None):
super().__init__(cfg, ch, nc, anchors)DetectionModel类
因此直接去看下DetectionModel这个类代码,同时也能发现这个类又是继承BaseModel这个类。这里先看一下DetectionModel,后面再看BaseModel这个类。这个类的功能可以根据yaml文件定义网络【定义网络的函数为parse_model()】,在分割任务中,anchors为None。
class DetectionModel(BaseModel): # 继承BaseModel这个类
# YOLOv5 detection model
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, encoding='ascii', errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
得到的model如下,这里需要注意的是此时的self指SegmentationModel类。
Sequential(
(0): Conv(
(conv): Conv2d(3, 32, kernel_size=(6, 6), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(1): Conv(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(2): C3(
(cv1): Conv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(3): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(4): C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(5): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(6): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(7): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(8): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(9): SPPF(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(10): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(11): Upsample(scale_factor=2.0, mode=nearest)
(12): Concat()
(13): C3(
(cv1): Conv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(14): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(15): Upsample(scale_factor=2.0, mode=nearest)
(16): Concat()
(17): C3(
(cv1): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(18): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(19): Concat()
(20): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(21): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(22): Concat()
(23): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(24): Segment(
(m): ModuleList(
(0): Conv2d(128, 351, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 351, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 351, kernel_size=(1, 1), stride=(1, 1))
)
(proto): Proto(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(upsample): Upsample(scale_factor=2.0, mode=nearest)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
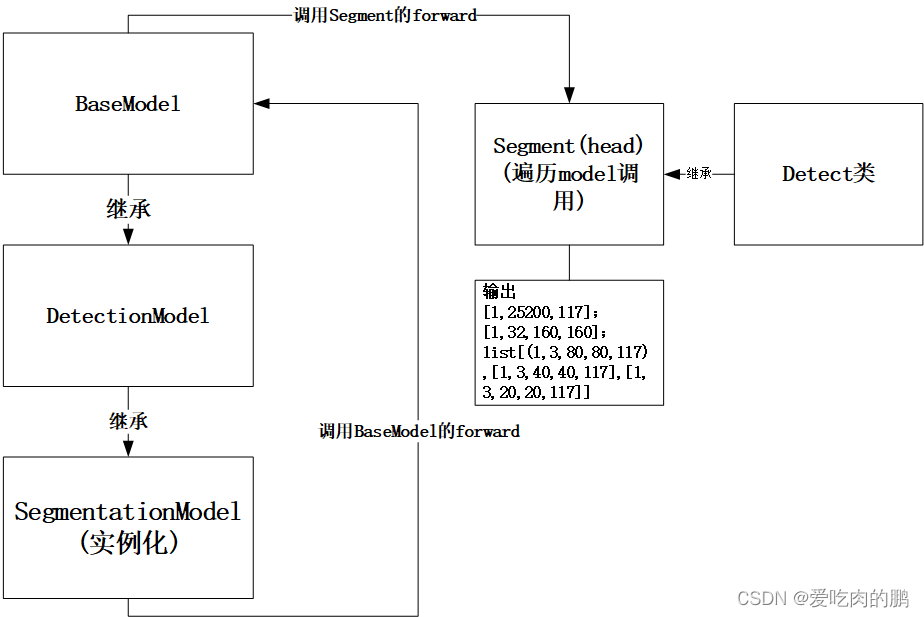
然后继续看下面的代码,m=self.model[-1]是获取上面定义model的最后一个模块即Segment类【这个类又继承Detect类,这个】,所以此时的m类型为Segment类。然后看forward 的lambda表达式那行, 由于通过isinstance判断m为Segment为True,所以此时调用SegmentationModel类的forward函数,并且可以回看前面SegmentationModel这个类发现没有重新父类DetectionModel的forward函数,所以这里直接调用父类的forward即可。
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment)):
s = 256 # 2x min stride
m.inplace = self.inplace
forward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)下面这两行代码分别为anchors的映射与获得stride,前面的映射是指将anchors映射到对应feature map上。【看到这里可能有些懵,不是前面已经说anchors为None了么,怎么现在又有anchors了,前面的None指在SegmentationModel这个类,而现在的anchors是Segment类中,也就是上面代码中m这个变量,这个anchors是通过YAML文件获取的】 。
m.anchors /= m.stride.view(-1, 1, 1) # anchors的缩放
self.stride = m.stride推理阶段
DetectionModel--forward()
从面前我们已经知道了虽然我们可以通过SegmentationModel类的实例化来定义model,但在推理阶段是调用的DetectionModel这个类下的forward函数。
def forward(self, x, augment=False, profile=False, visualize=False):
if augment:
return self._forward_augment(x) # augmented inference, None
return self._forward_once(x, profile, visualize) # single-scale inference, trainBaseModel--forward()
可以看到DetectionModel调用的为_forward_once(x,profile,visualize)这个函数,而这个函数是父类BaseModel下的函数。
class BaseModel(nn.Module):
# YOLOv5 base model
def forward(self, x, profile=False, visualize=False):
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers 当为segment时xshape:[128,80,80]、[256,40,40],[512,20,20]
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run 将x放入每个卷积层提取特征,得到的x是提取后的
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x此时的x为输入的图像,shape为【1,3,640,640】。self为SegmentationModel,因此后面的self,model调用的前面定义好的分割网络model。
for m in self.model是遍历网络的每一层,当遍历到head时【也就是遍历到segment类时】,得到的shape大小为[128,80,80],[256,40,40],[512,20,20],也就是会得到三个feature map,这三个层是通过m.f在y[j]中获得的。
下面这行代码是会将[4, 6, 10, 14, 17, 20, 23]这几层输出的output进行保存【这几层可以对照yaml文件看】。
y.append(x if m.i in self.save else None) # save output下面是Segment【head】结构。
经过卷积以后得到的x为tuple类型,包含的内容为:
①【batch,25200,117】,
②【batch,32,160,160】,
③ list【[batch,3,80,80,117],【[batch,3,40,40,117]】,[batch,3,20,20,117]】
注:25200=3*80*80+40*40*3+20*20*3【可理解为将三个featrue map铺平后叠加在一起】;
这里的160是通过将80*80的feature上采样得到的
这里的117指:5+80+32【这里的32是mask的数量】
最后得到的输出就是我们要的output。
Segment(
(m): ModuleList(
(0): Conv2d(128, 351, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 351, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 351, kernel_size=(1, 1), stride=(1, 1))
)
(proto): Proto(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(upsample): Upsample(scale_factor=2.0, mode=nearest)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(cv3): Conv(
(conv): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
Segment类
前面我们说到了在BaseModel中对派生类SegmentationModel遍历时,在head部分会得到Segment获得最终的输出,那么我们来看一下这个类。
参数:
nc:分类数量。coco为80个类
anchors:通过yaml文件获得的anchors。
nm:mask数量
npr:protos数量
ch:3通道
Segment继承Detect这个类
在forward部分,x是前面获得的三个feature,分别从网络的17,20,23层获得。
proto的功能是针对x[0]进行卷积,将原来80*80大小的feature通过上采样变为160*160。然后调用Detect中的forward进行前向推理获得输出,然后返回[x[0],p,x[1]]也就是shape为【1,128,80,80】,【1,128,40,40】,【1,256,20,20】的tuple。
class Segment(Detect):
# YOLOv5 Segment head for segmentation models
def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), inplace=True):
super().__init__(nc, anchors, ch, inplace)
self.nm = nm # number of masks
self.npr = npr # number of protos
self.no = 5 + nc + self.nm # number of outputs per anchor 5+80+32
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # * output conv
self.proto = Proto(ch[0], self.npr, self.nm) # protos
self.detect = Detect.forward
def forward(self, x):
"""
Args x is list,from 17,20,23
x[0].shape=[batch_size,128,80,80],
x[1].shape=[batch,256,40,40],
x[2].shpe=[batch,512,20,20]
proto:功能是将P3输出的80*80变160*160
conv1(x[0])->upsample[x[0]=160*160]->conv2->conv3->output.shape=[batch,32,160,160],
"""
p = self.proto(x[0])
x = self.detect(self, x) # x[0]:[batch,3,80,80,117],x[1]:[1,3,40,40,117],x[2]:[1,3,20,20,117]
return (x, p) if self.training else (x[0], p) if self.export else (x[0], p, x[1])Detect--forward
在上面Segment中调用Detect的forward对x进行推理,下面就看看具体发生了什么变化。通过遍历三个head,在self指的Segment类,而self.m是Segment的三个卷积,如下:
(m): ModuleList(
(0): Conv2d(128, 351, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 351, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 351, kernel_size=(1, 1), stride=(1, 1))
)
因此用这三个卷积对x进行卷积,x为Segment类中的x,为tuple类型。
class Detect(nn.Module):
# YOLOv5 Detect head for detection models
stride = None # strides computed during build
dynamic = False # force grid reconstruction
export = False # export mode
# Detect layer init
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.empty(0) for _ in range(self.nl)] # init grid
self.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use inplace ops (e.g. slice assignment)
# x是列表类型为P3 P4 P5的输出大小
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape
# x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
由于self前面说了是Segment类型,因此可以将x[1,3,80,80,117=5+80+32]进行划分,得到boxes+mask的形式,形式为xy[中心点],wh[宽高],conf,mask ,并在对应head划分网格,最终将xy,wh,conf与mask进行拼接【在第四维度上,也就是最后一个维度】拼接为shape[batch,feature_w,feature_h,117]。
if isinstance(self, Segment): # (boxes + masks)
xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)经过上面的操作,我们可以再返回Segment了,经过detect的forward我们得到的输出为:【(1,25200,117),list[(1,3,80,80,117),[1,3,40,40,117],[1,3,20,20,117]]】
再经过下面的操作,返回的形式为【x[0]=[1,25200,117],p=[1,32,160,160],x[1]=list[(1,3,80,80,117),[1,3,40,40,117],[1,3,20,20,117]]】
return (x, p) if self.training else (x[0], p) if self.export else (x[0], p, x[1])