4.其他数据功能
4.1pubsub发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
下面示例展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
发布者
| Shell
192.168.77.51:6379>publish channel1 频道名称
(integer) 1
192.168.77.51:6379> publish channel1 bbb
(integer) 1
192.168.77.51:6379> publish channel1 ccc
(integer) 1 |
订阅者1:
| Shell
[root@doitedu04 redis6]# bin/redis-cli -h 192.168.77.54 -p 6379 -c
192.168.77.54:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit) |
订阅者2:
| Shell
192.168.77.53:6379> subscribe channel1
Reading messages... (press Ctrl-C to quit) |
对频道的生命周期而言,如果给定的频道之前未曾被订阅过,那么SUBSCRIBE命令会自动创建频道。此外,当频道上没有活跃的订阅者时,频道将会被删除。
PubSub相关的机制均不支持持久化。这意味着,消息、频道和 PubSub的关系均不能保存到磁盘上。如果服务器出于某种原因退出,那么所有的这些对象都将丢失。
此外,在消息投递和处理场景中,如果频道没有订阅者,那么被发到频道上的消息将被丢弃。换句话说,redis并没有保证消息投递可靠性的机制。
总之,虽然redis 中的PubSub功能并不适合重要消息的投递场景,但是有些人可能会由于其简洁的通信方式而在速度方面获益。
4.2pipeline管道操作
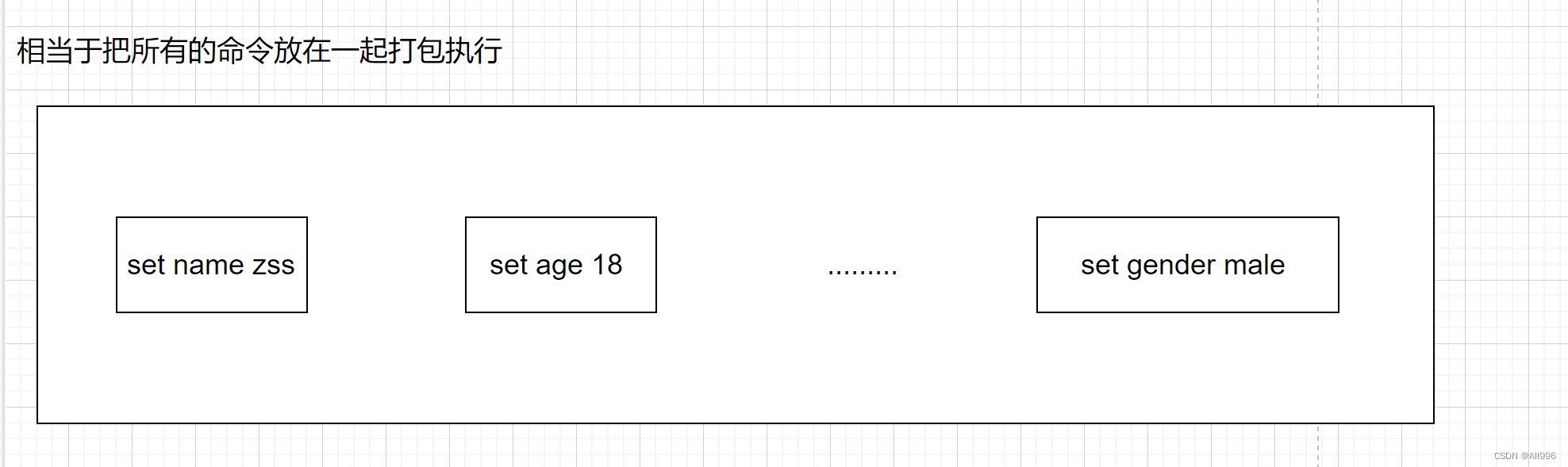
可以一次性的执行多个命令,redis的指令执行是单线程 : [sadd set get lpush lrange] ---> (统一执行),简而言之就是将一系列的命令一起打包。写个脚本运行
示例:
如果有大量命令需要执行,如:
| Shell
get a
set b aaa
set c ddd
set x yyy
get x
incr d
set y uuu |
如果一条一条去执行,则每次命令执行都要经历网络请求、服务器执行、网络响应!而其中,网络请求、网络响应所耗费的时间是很浪费的;
可以利用pipeline将这一系列命令,一次性发给redis去执行,然后一次性返回结果,极大提高效率;
redis客户端和服务器之间典型的通信过程可以看作:
- 客户端向服务器发送一个命令。发一个pipeline这个命令
- 服务器接收该命令并将其放入执行队列(因为redis是单线程的执行模型)。
- 命令被执行。
- 服务器将命令执行的结果返回给客户端。
使用redis管道(pipeline)可以加快上述的过程。redis管道的基本思想是,客户端将多个命令打包在一起,并将它们一次性发送,而不再等待每个单独命令的执行结果;同时,redis管道需要服务器在执行所有的命令后再返回结果。即便是执行多个命令,但由于第1步和第4步只发生一次,时间会大大减少。
示例:1.准备一个文件,放入一批命令
| Shell
[root@doitedu01 ~]# cat pipeline.txt
set a 111
set b 222
sadd set:x v1 v2
get a
scard myset |
2.使用redis-cli的--pipe选项,通过管道发送命令:
| Shell
[root@doitedu03 redis6]# cat /root/pipeline.txt | bin/redis-cli -h linux01 --pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
用于更新数据 , 插入数据的数据操作命令 查询数据 数据不会返回 |
4.3Multi事务操作
事务是一组原子性的操作 , 在原子中所有的操作要么全部成功 , 要么全部失败 !
原子性
一致性
隔离性
持久性
所谓事务,就是把一系列的操作绑定成一个原子操作,其中一个操作失败,就会让整个操作全部失败(回滚)
但是,redis并没有实现严格的事务;不支持失败回滚
4.3.1基本操作
示例:
| Shell
doit01:6379> multi
OK
doit01:6379(TX)> set a 1
QUEUED
doit01:6379(TX)> set b 2
QUEUED
doit01:6379(TX)> set c aaa
QUEUED
doit01:6379(TX)> incr c
QUEUED
doit01:6379(TX)> set d 3
QUEUED
doit01:6379(TX)> set e 4
QUEUED
doit01:6379(TX)> exec |
| 这个事务控制中,就算有某个步骤执行失败,也不会影响其他步骤的执行! |
4.3.2watch + 事务
监听: mysql中的数据如果发生变化 (今天更新的数据) binlog
mysql中有binlog ,默认服务是关闭的, 开启binlog监控服务 , 当mysql中的数据发生变化, 记录在binlog中 , 我们可以监听binlog的变化, 确定数据的变化!
watch是用于监视一个指定的key是否被修改
watch +事务,可以用于在事务开启之前,监视指定key,如果这个key在事务提交前被修改,则事务就会自动取消(discard)
示例:
| Shell
doit01:6379> watch b
OK
doit01:6379> multi
OK
doit01:6379(TX)> set a 1
QUEUED
doit01:6379(TX)> set b 20
QUEUED
doit01:6379(TX)> set c 30
QUEUED
doit01:6379(TX)> exec
(nil)
当我在事务没有提交之前,修改了b的值,那么,这个事务就会被自动取消 |
5.redis数据持久化
Redis是基于内存的,如果不想办法将数据保存在硬盘上,一旦Redis重启(退出/故障),内存的数据将会全部丢失。(业务库中缓存的数据 , 存储的一些重要的标签, 状态数据)
我们肯定不想Redis里头的数据由于某些故障全部丢失(导致所有请求都走MySQL),即便发生了故障也希望可以将Redis原有的数据恢复过来,这就是持久化的作用。
Redis提供了两种不同的持久化方法来将数据存储到硬盘里边:
- RDB(基于快照),将某一时刻的内存中的所有数据保存到一个RDB文件中(二进制带压缩)
- AOF(append-only-file),当Redis服务器执行写命令的时候,将执行的写命令保存到AOF文件中。
5.1RDB(快照持久化)
RDB持久化可以手动执行,也可以根据服务器配置定期执行。RDB持久化所生成的RDB文件是一个经过压缩的二进制文件,Redis可以通过这个文件还原数据库的数据。

有两个命令可以生成RDB文件:
- SAVE会阻塞Redis服务器进程,服务器不能接收任何请求,直到RDB文件创建完毕为止
- BGSAVE创建(fork)出一个子进程,由子进程来负责创建RDB文件,服务器进程可以继续接收请求。
Redis服务器在启动的时候,如果发现有RDB文件,就会自动载入RDB文件(不需要人工干预)
服务器在载入RDB文件期间,会处于阻塞状态,直到载入工作完成。
除了手动调用SAVE或者BGSAVE命令生成RDB文件之外,我们可以使用配置的方式来定期执行:
在默认的配置下,如果以下的条件被触发,就会执行BGSAVE命令
示例:
| Shell
----------rdb快照------------
save 900 1 前面是时间 后面是操作次数
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据
rdbcompression yes
对于存储到磁盘中的快照,可以设置是否进行压缩存储。
如果是的话,redis会采用LZF算法进行压缩。
如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
rdbchecksum yes
默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,
但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
dbfilename dump.rdb
设置快照的文件名,默认是 dump.rdb
dir ./
设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
使用上面的 dbfilename 作为保存的文件名。 |
手动触发持久化
| Shell
save 他会阻塞 ==》 在保存dump.rdb文件完成之前,不能在客户端做任何的操作
bgsave 后台取保存 ==》 在后台开一个线程,单独的为你保存dump.rdb这个文件
CONFIG GET dir 数据恢复只需要将指定的dump.rdb文件导入到安装目录下即可 |
5.2AOF(文件追加)
上面已经介绍了RDB持久化是通过将某一时刻数据库的数据“快照”来实现的,下面我们来看看AOF是怎么实现的。
示例:
| SQL
APPEND ONLY MODE
appendonly no
默认该模式关闭
appendfilename "appendonly.aof"
aof文件名,默认是"appendonly.aof"
# appendfsync always
appendfsync everysec
# appendfsync no
aof持久化策略的配置;
no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快;
always表示每次写入都执行fsync,以保证数据同步到磁盘; 最多丢一条数据
everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
no-appendfsync-on-rewrite:
在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,
执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。
如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,
这样对持久化特性来说这是更安全的选择。
设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,
默认为no,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。默认值为no。
auto-aof-rewrite-percentage 100
默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少
进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。
当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
auto-aof-rewrite-min-size 64mb
设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。
aof-load-truncated yes
aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。
重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项,
出现这种现象 redis宕机或者异常终止不会造成尾部不完整现象,可以选择让redis退出,或者导入尽可能多的数据。
如果选择的是yes,当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。
如果是no,用户必须手动redis-check-aof修复AOF文件才可以。默认值为 yes。 |
AOF是通过保存Redis服务器所执行的写命令来记录数据库的数据的。

| Plain Text
比如说我们对空白的数据库执行以下写命令:
redis> SET meg "hello"
OK
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> RPUSH numbers 128 256 512
(integer) 3
Redis会产生以下内容的AOF文件 |
5.3AOF重写(BGREWRITEAOF命令)
| Shell
数据库经历了如下操作
set a 1
set a 2
set a 3
set a 4
set a 5
set a 6
set a 7
set a 8
那么,aof中的记录也会有上述的8条
然而,数据库中的最终状态仅仅是: a -> 8
那么,aof中的大量记录都是冗余无效的,可以执行rewrite操作来精简体积提高效率
==> rewrite aof
set a 8
可以通过配置让redis自动定期对aof文件进行重写
也可以用命令来触发aof重写: BGREWRITEAOF |
5.4持久化方式的选择
RDB和AOF并不互斥,它俩可以同时使用。
- RDB的缺点:会一定程度上丢失数据(因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。)
- AOF的优点:丢失数据少(默认配置只丢失一秒的数据)。
如果Redis服务器同时开启了RDB和AOF持久化,服务器会优先使用AOF文件来还原数据(因为AOF更新频率比RDB更新频率要高,还原的数据更完善)
5.5相关参数
| Plain Text
redis持久化,两种方式
1、rdb快照方式
2、aof日志方式
----------rdb快照------------
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /var/rdb/
-----------Aof的配置-----------
appendonly no # 是否打开 aof日志功能
appendfsync always #每一个命令都立即同步到aof,安全速度慢
appendfsync everysec
appendfsync no #写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof 同步频率低,速度快
no-appendfsync-on-rewrite yes #正在导出rdb快照的时候不要写aof
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb |
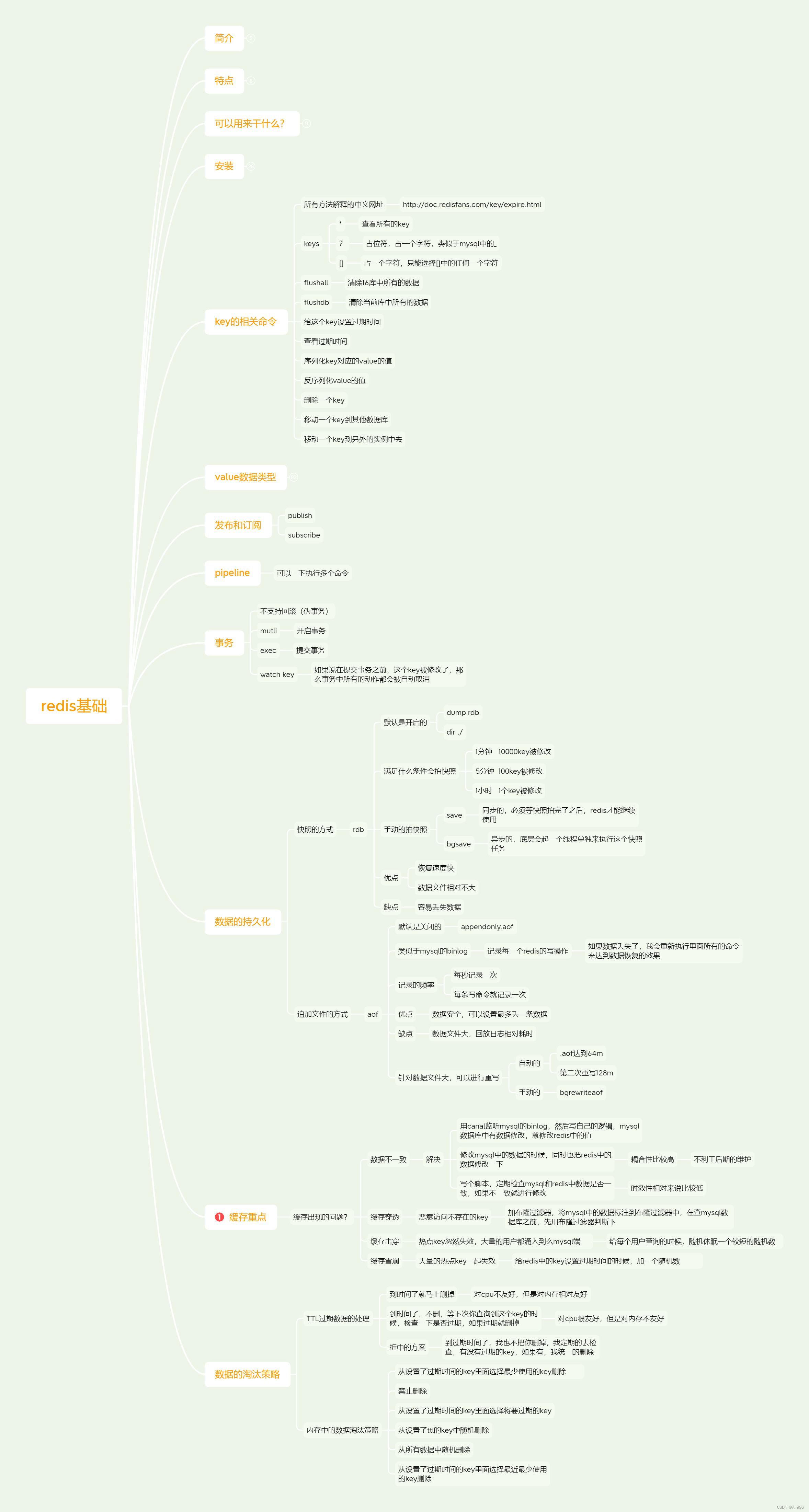
在多易杰哥的带领下 , 我也越来越喜欢用思维导图来整理一些东西.更好的理解并实用与复习.