文章目录
一、工具与环境
二、深度学习环境的搭建
1.安装Anaconda
2.创建虚拟环境
第1步:打开Anaconda的命令窗口,即Anaconda Prompt
第2步:使用命令创建指定版本的python环境(这里以py36命令环境名称举例)
3.切换环境
4.下载项目所需的工具包
5.设置Pycharm的环境为创建好的环境
三、基于Keras的手写数字图像识别项目运行与测试
1.核心代码
2.识别的手写图片集合
3.识别的基本原理
4.运行与测试
四、分析与小结
参考文章
一、工具与环境
- Pycharm 2022.1.4
- conda version : 4.5.4
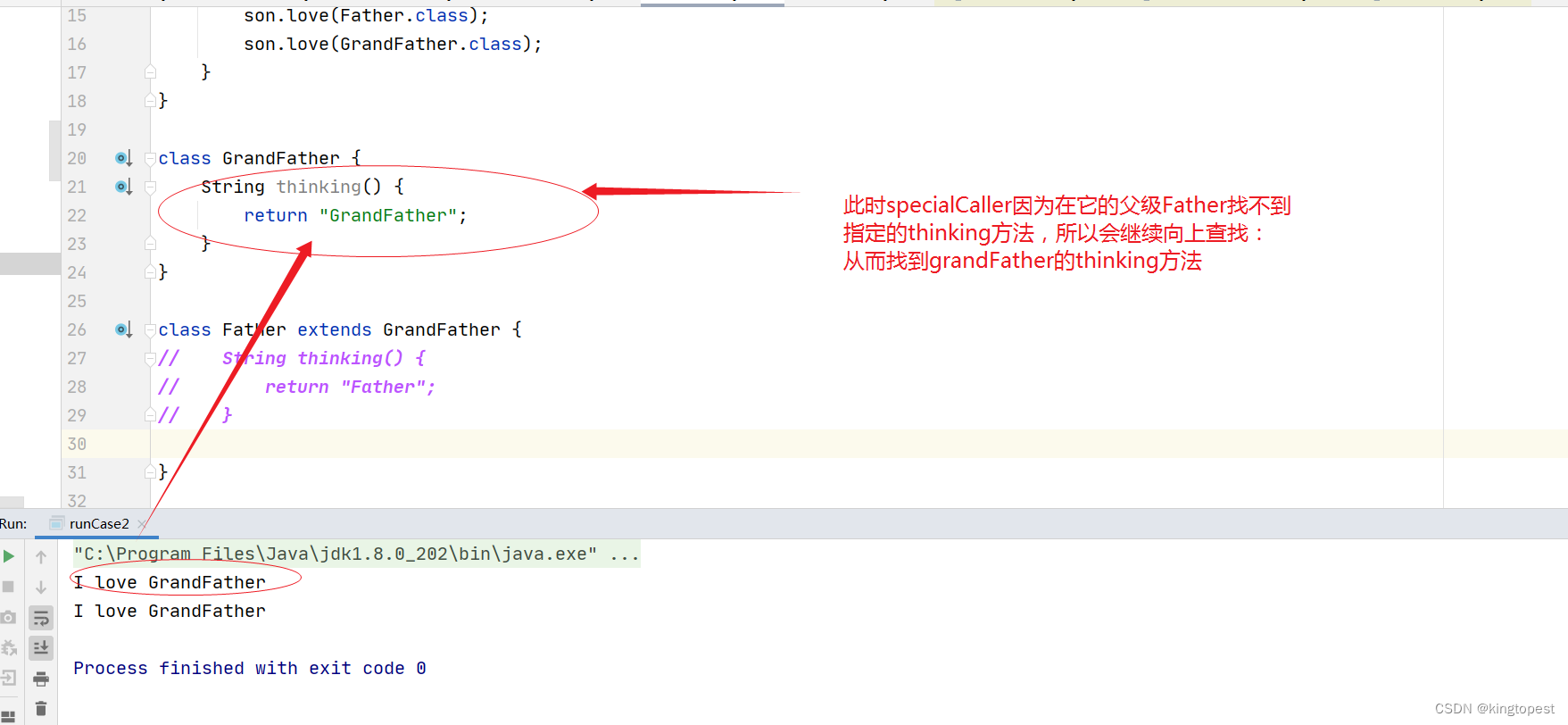
- python version : 3.6.5.final.0
- platform : win-64
二、深度学习环境的搭建
1.安装Anaconda
Anaconda是一个开源的Python发行版本,用来管理Python相关的包,使用anaconda可以很方便的切换到不同的python环境,使用不同的深度学习框架来开发项目,非常高效!
具体下载与安装步骤,请参照这位大佬的文章
史上最全Anaconda安装与使用教程![]() https://blog.csdn.net/wq_ocean_/article/details/103889237?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168594896716800180669116%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168594896716800180669116&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-2-103889237-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=Anaconda%E5%AE%89%E8%A3%85&spm=1018.2226.3001.4187
https://blog.csdn.net/wq_ocean_/article/details/103889237?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168594896716800180669116%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168594896716800180669116&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-2-103889237-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=Anaconda%E5%AE%89%E8%A3%85&spm=1018.2226.3001.4187
2.创建虚拟环境
第1步:打开Anaconda的命令窗口,即Anaconda Prompt
Anaconda安装成功后会附带,在开始栏处
第2步:使用命令创建指定版本的python环境(这里以py36命令环境名称举例)
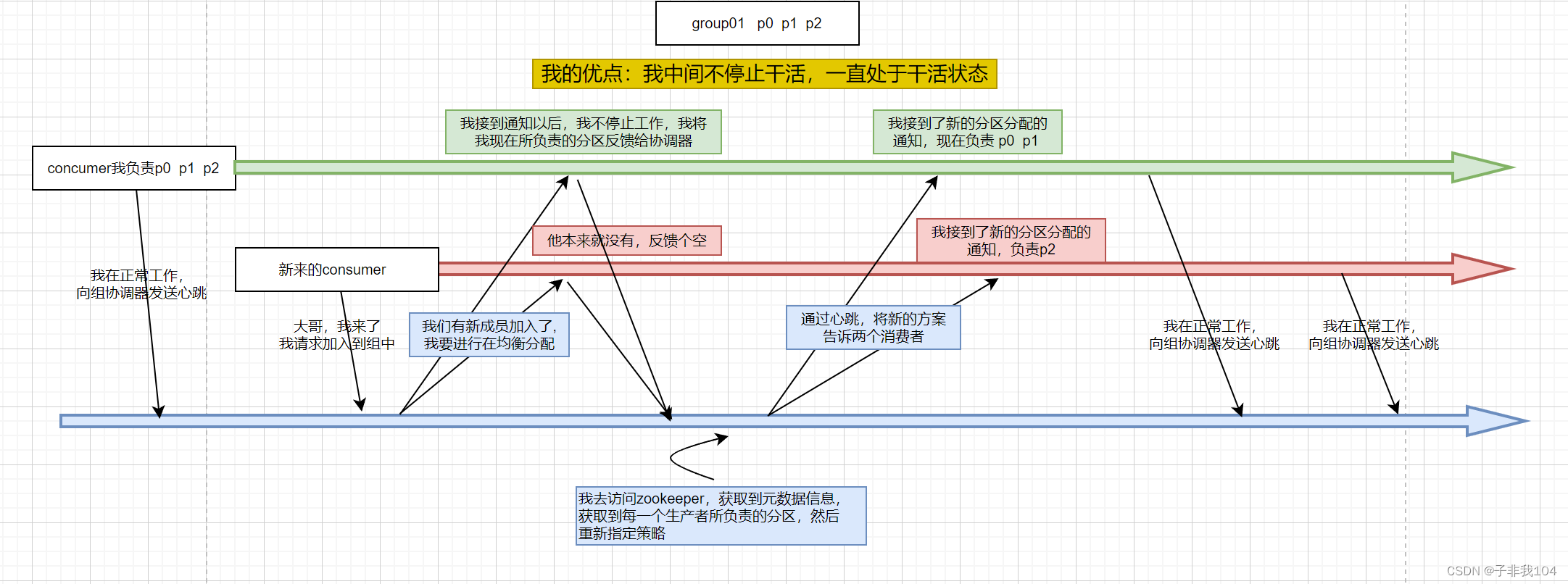
conda create -n py36 python=3.63.切换环境
默认环境是base,我们需要创建一个指定版本的环境供我们使用,可以理解为开发一个项目所需要创建的指定环境,这样不同项目之间环境是相互隔离开的 。使用命令activate +环境名即可实现环境的切换。
activate py36切换到py36环境后,输入conda info 命令,出现如下信息即表面环境创建成功!

4.下载项目所需的工具包
在成功切换到py36(自己创建的环境)之后,依次在Anaconda Prompt中执行下面的命令来下载所需工具包,注意:由于默认下载源在国外,所以下载速度会很慢,我们可以使用国内的一些镜像来下载,速度很快。只需要在下面每一个命令后面加上 -i 镜像地址 即可。
我使用的是清华大学的镜像源: -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplolib -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install keras==2.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple5.设置Pycharm的环境为创建好的环境
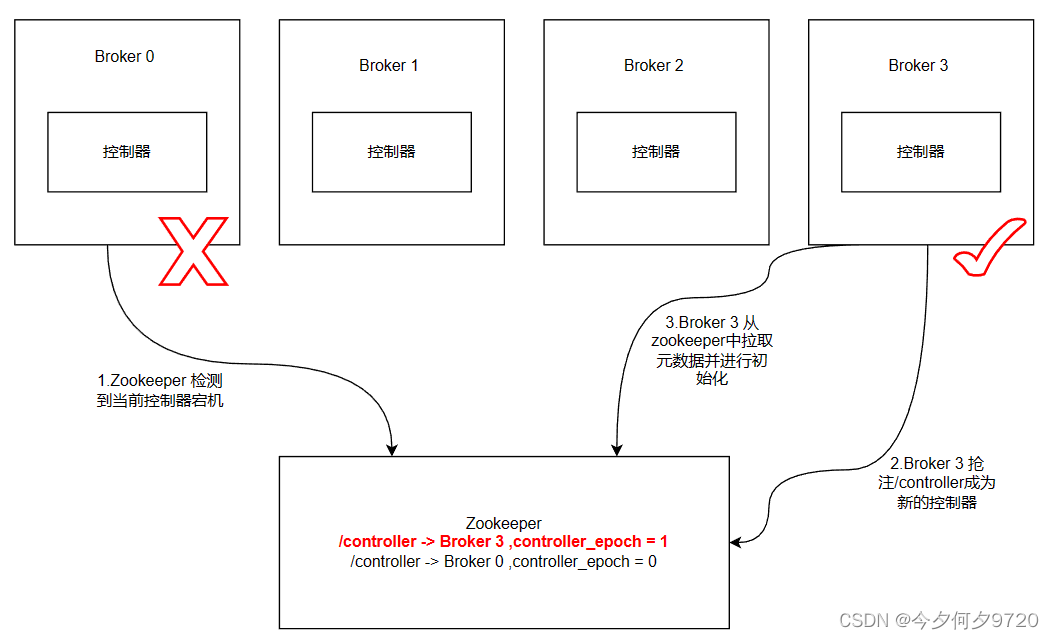
点击Pycharm右下角Add Interpreter
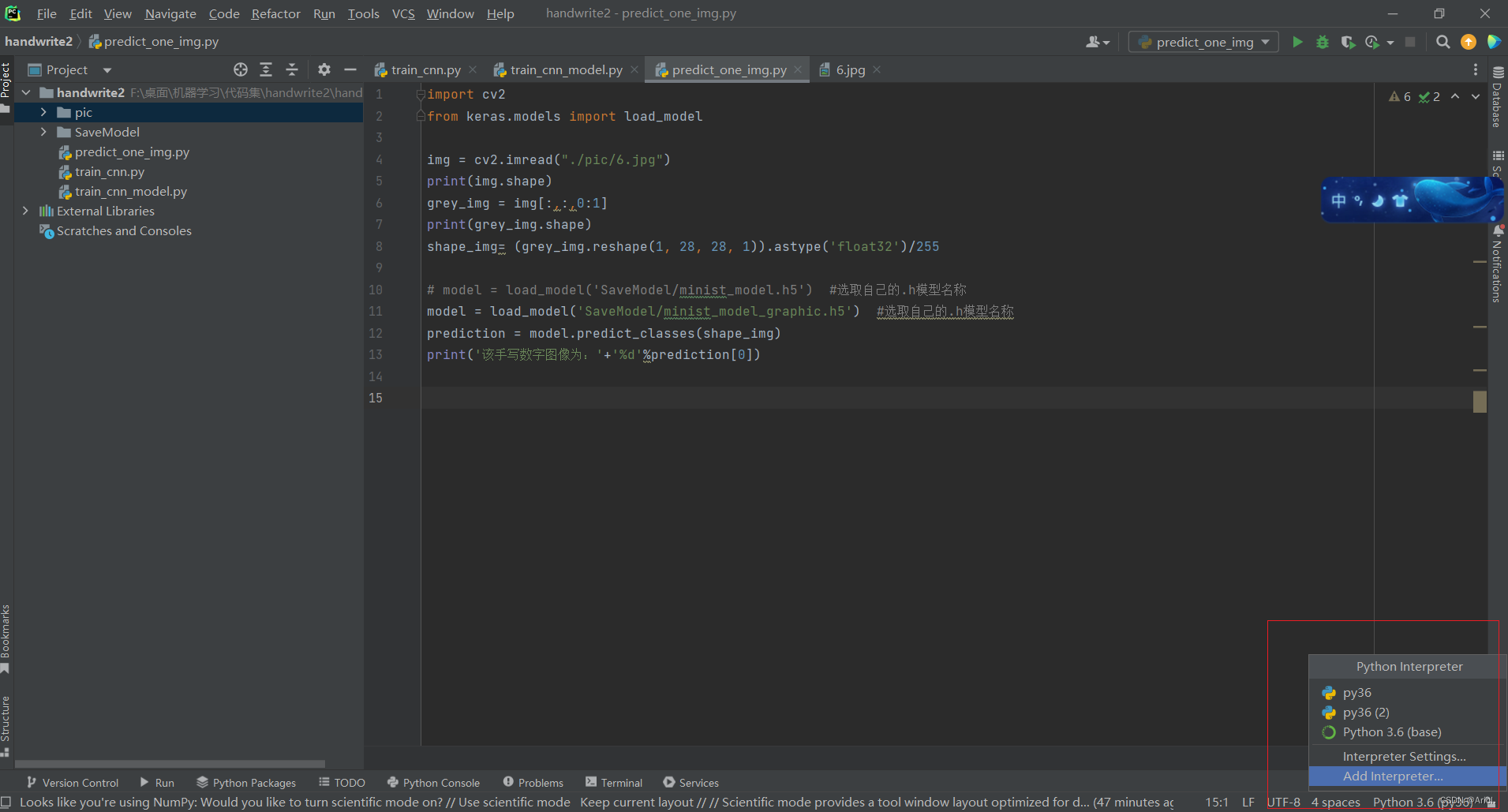
如下图所示,选择Anaconda安装目录下 Scripts文件夹下的conda.exe
(有些也会出现在根目录下,选择根目录下的conda.exe也行,根据Pycharm不同版本会有区别)

Pycharm切换解释器之后,至此,环境准备工作完成了
三、基于Keras的手写数字图像识别项目运行与测试
1.核心代码
train_cnn.py
#步骤01 入所需要的模块
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
import numpy as np
np.random.seed(10)
#步骤02 下载mnist数据集、读取数据集
(x_Train, y_Train) , (x_Test, y_Test) = mnist.load_data()
#步骤03 将图像特征值转化为6000,28,28,1的4维矩阵
x_Train4D = x_Train.reshape(x_Train.shape[0], 28, 28,1).astype('float32')
x_Test4D = x_Test.reshape(x_Test.shape[0], 28, 28, 1).astype('float32')
#步骤04 进行标准化
#将像素范围设置在【0,1】
x_Train4D_normalize = x_Train4D / 255
x_Test4D_normalize = x_Test4D / 255
#步骤05 label进行一位有效编码转换
#将标签转成读热码
y_TrainHot = np_utils.to_categorical(y_Train)
y_TestHot = np_utils.to_categorical(y_Test)
#=>建立模型
#步骤01 定义模型
model = Sequential()
#步骤02 建立卷积层1
model.add(Conv2D(filters=16, # filter = 16 建立16个滤镜
# kernel_size = (5,5) 每一个滤镜是5 × 5的大小
kernel_size=(5,5),
# padding = 'same' 设置卷积运算产生的图像大小不变
padding='same',
#输入的图像形状为28*28,1代表单色灰度,3代表RGB
input_shape= (28, 28, 1),
# activation设置激活函数为relu建立池化层1
activation='relu'))
#步骤03 建立池化层1
model.add(MaxPooling2D(pool_size=(2,2)))#缩减采样,输出16个14*14图像
#步骤04建立卷积层2
model.add(Conv2D(filters=36,#建立36个滤镜
kernel_size=(5,5),#每一个滤镜是5 × 5的大小
padding='same',#Convolution完成后的图像大小不变
activation='relu'#输出36个14*14的图像
))
#步骤05 建立池化层2,加入Dropout避免Overfitting
model.add(MaxPooling2D(pool_size=(2,2)))#图像大小变为7*7
# 加入DropOut(0.25),每次训练时,会在神经网络中随机放弃25%的神经元,避免过拟合建立神经网络(平坦层,隐藏层,输出层)建立平坦层
model.add(Dropout(0.25))
#步骤06 建立平坦层
model.add(Flatten())#长度是36*7*7个神经元
#步骤07 建立隐藏层
model.add(Dense(128, activation='relu'))
# 把DropOut加入模型中,DropOut(0.5)在每次迭代时候会随机放弃50%的神经元,避免过拟合
model.add(Dropout(0.5))
# 建立输出层,一共10个单元,对应0-9一共10个数字。使用softmax进行激活
model.add(Dense(10, activation='softmax'))
# 查看模型摘要
print(model.summary())
#=>进行训练
#步骤01 定义训练方式
# 定义训练方式compile
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#步骤02 开始训练
train_history = model.fit(x = x_Train4D_normalize, y = y_TrainHot,
validation_split=0.2,
#将80%作为训练数据,20%作为测试数据
epochs=10,#执行10个训练周期
batch_size=300,#每一批300项数据
verbose=2#参数为2表示显示训练过程
)
train_cnn_model.py
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
np.random.seed(10)
(x_Train, y_Train) , (x_Test, y_Test) = mnist.load_data()
x_Train4D = x_Train.reshape(x_Train.shape[0], 28, 28,1).astype('float32')
x_Test4D = x_Test.reshape(x_Test.shape[0], 28, 28, 1).astype('float32')
x_Train4D_normalize = x_Train4D / 255
x_Test4D_normalize = x_Test4D / 255
y_TrainHot = np_utils.to_categorical(y_Train)
y_TestHot = np_utils.to_categorical(y_Test)
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=(5,5), padding='same', input_shape = (28, 28, 1), activation='relu'))
# 参数说明
# filter = 16 建立16个滤镜
# kernel_size = (5,5) 每一个滤镜是5 × 5的大小
# padding = 'same' 设置卷积运算产生的图像大小不变
# input_shape = (28, 28, 1) 第一二维代表输入图像的形状是28 × 28,第三维因为是单色灰度图像,所以最后维数值是1
# activation设置激活函数为relu建立池化层1
model.add(MaxPooling2D(pool_size=(2,2)))
# 输入参数为pool_size=(2,2),执行第一次缩减采样,将16个28 ×28的图像缩小为16个14 × 14的图像建立卷积层2,将16个图像转化为36个图像,不改变图像大小,仍为14 × 14
model.add(Conv2D(filters=36, kernel_size=(5,5), padding='same', activation='relu'))
# 加入池化层2,并加入DropOut避免过拟合
model.add(MaxPooling2D(pool_size=(2,2)))
# 执行第二次缩减采样,将14 × 14图像转换为7 × 7图像
model.add(Dropout(0.25))
# 加入DropOut(0.25),每次训练时,会在神经网络中随机放弃25%的神经元,避免过拟合建立神经网络(平坦层,隐藏层,输出层)建立平坦层
model.add(Flatten())
# 将之前步骤建立的池化层2,一共有36个7 × 7的图像转化为一维向量,长度是36 × 7 × 7 = 1764, 也就是1764个float数,对应1764个神经元建立隐藏层,一共128个神经元
model.add(Dense(128, activation='relu'))
# 把DropOut加入模型中,DropOut(0.5)在每次迭代时候会随机放弃50%的神经元,避免过拟合
model.add(Dropout(0.5))
# 建立输出层,一共10个单元,对应0-9一共10个数字。使用softmax进行激活
model.add(Dense(10, activation='softmax'))
# 查看模型摘要
print(model.summary())
# # 进行训练
# 定义训练方式
# # 加载之前训练的模型
try:
# model.load_weights("SaveModel/minist_model.h5")
model.load_weights("SaveModel/minist_model_graphic.h5")
print("加载模型成功!继续训练模型")
except :
print("加载模型失败!开始训练一个新模型")
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 开始训练
train_history = model.fit(x = x_Train4D_normalize, y = y_TrainHot,
validation_split=0.2, epochs=10, batch_size=300, verbose=2)
# model.save_weights("SaveModel/minist_model.h5")
model.save("SaveModel/minist_model_graphic.h5")
print("Saved model to disk")predict_one_img.py
import cv2
from keras.models import load_model
img = cv2.imread("./pic/6.jpg")
print(img.shape)
grey_img = img[:,:,0:1]
print(grey_img.shape)
shape_img= (grey_img.reshape(1, 28, 28, 1)).astype('float32')/255
# model = load_model('SaveModel/minist_model.h5') #选取自己的.h模型名称
model = load_model('SaveModel/minist_model_graphic.h5') #选取自己的.h模型名称
prediction = model.predict_classes(shape_img)
print('该手写数字图像为:'+'%d'%prediction[0])
2.识别的手写图片集合

3.识别的基本原理
采用的数据集是MNIST数据集。在该数据集中每张图片由28x28个像素点构成,每个像素点用一个灰度值表示。如下是数字1的一个例子,我们的目的是做出一个模型,将这784个数值输入这个模型,然后它的输出结果就为1。

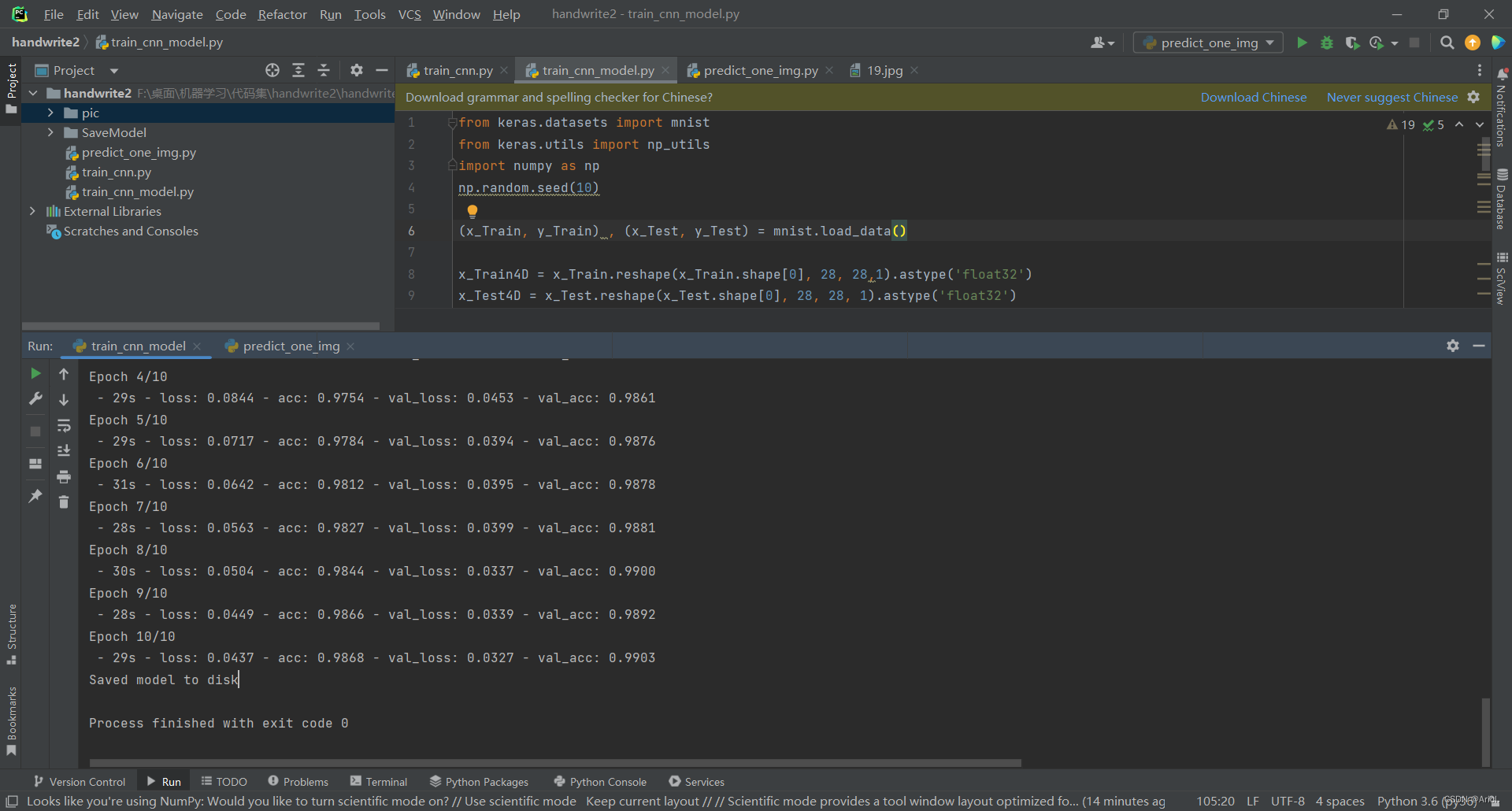
4.运行与测试
- 先读取数据集
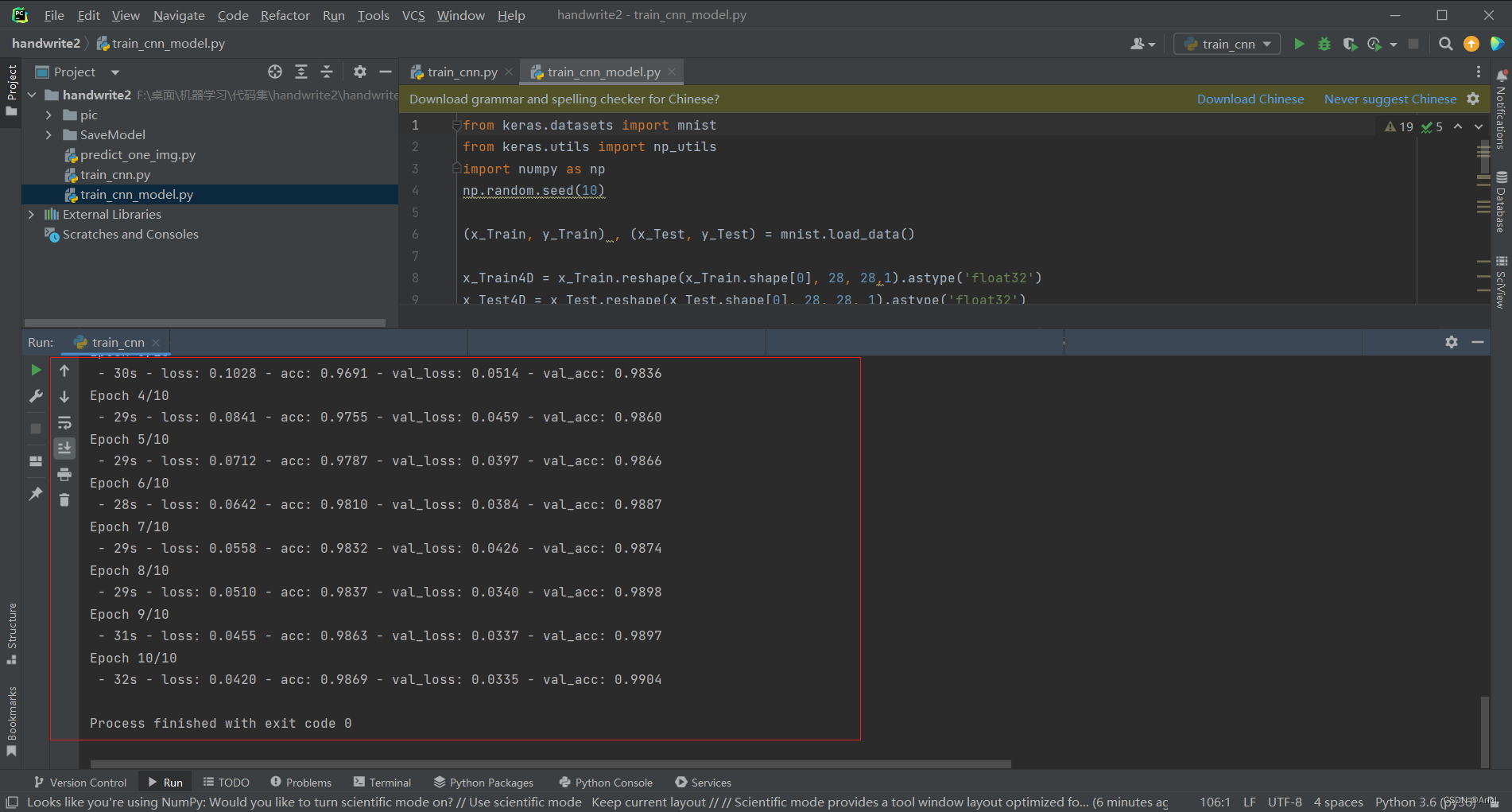
- 训练数据模型
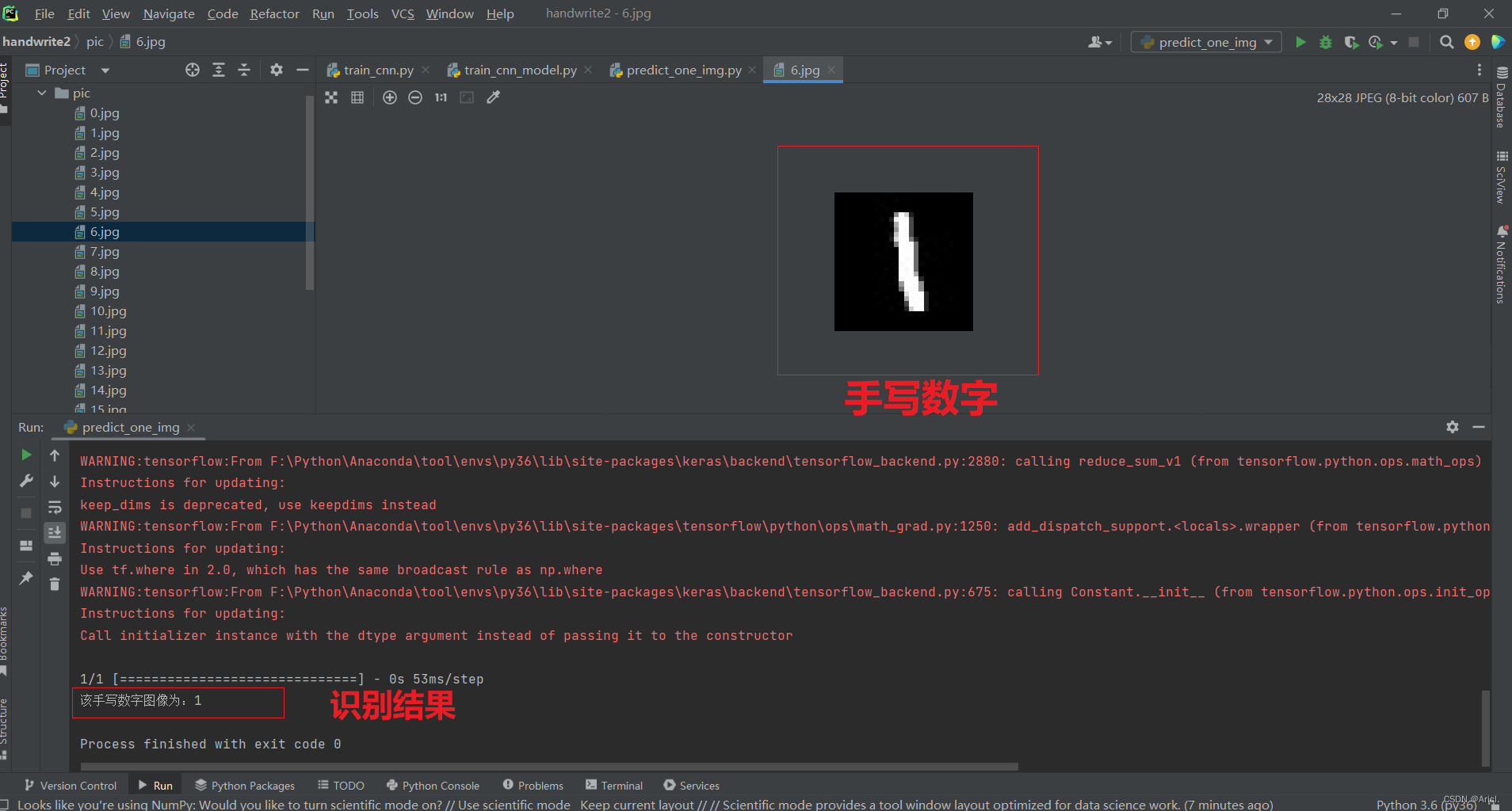
- 识别手写数字图像
四、分析与小结
本次通过基于Keras手写数字图像识别这一经典案例,初步学习了机器学习中另一个重要的分支领域——深度学习的内容,采用的数据集是MNIST数据集。在该数据集中每张图片由28x28个像素点构成,每个像素点用一个灰度值表示。首先是要使用pip命令行下载程序所要导入的工具包,同时使用activate py36 指令将python环境切换到我们创建并导入相关工具包的环境下,编译器采用pycharm,将程序跑起来。首先要进行数据集的训练,然后再用训练好的模型去识别6.jpg这个手写数字图像,控制台打印出识别的结果。
经过这个入门案例的学习,让我对机器学习领域产生了浓厚的学习兴趣,本质上是用海量的数据作为输入,让计算机去训练分析出一个模型,我们可以将其视为一个函数,一个“黑盒子”,然后用它去识别指定的数据,给出分析的结果,该过程类比于人脑总结以往经验,来预测未来指导行动的过程是异曲同工的,非常奇妙!!

参考文章
深度学习实例——Keras实现手写数字识别![]() https://blog.csdn.net/yjw123456/article/details/103811112?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168594730916800222827149%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168594730916800222827149&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-103811112-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=Keras%E6%89%8B%E5%86%99%E6%95%B0%E5%AD%97%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB&spm=1018.2226.3001.4187【深度学习实战—1】:基于Keras的手写数字识别(非常详细、代码开源)
https://blog.csdn.net/yjw123456/article/details/103811112?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168594730916800222827149%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168594730916800222827149&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-103811112-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=Keras%E6%89%8B%E5%86%99%E6%95%B0%E5%AD%97%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB&spm=1018.2226.3001.4187【深度学习实战—1】:基于Keras的手写数字识别(非常详细、代码开源)![]() https://blog.csdn.net/qq_42856191/article/details/121420268?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168594730916800222827149%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168594730916800222827149&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-121420268-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=Keras%E6%89%8B%E5%86%99%E6%95%B0%E5%AD%97%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_42856191/article/details/121420268?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168594730916800222827149%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168594730916800222827149&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-121420268-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=Keras%E6%89%8B%E5%86%99%E6%95%B0%E5%AD%97%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB&spm=1018.2226.3001.4187