练一练
需求:写一个生产者,不断的去生产用户行为数据,写入到 kafka 的一个 topic 中
生产的数据格式: 造数据
{"guid":1,"eventId":"pageview","timestamp":1637868346789} isNew = 1
{"guid":1,"eventId":"addcard","timestamp":1637868347625} isNew = 0
{"guid":2,"eventId":"collect","timestamp":16378683463219}
{"guid":3,"eventId":"paid","timestamp":16378683467829}
......
再写一个消费者,不断的从 kafka 中消费上面的用户行为数据,做一个统计
1. 每 5s 输出一次当前来了多少用户 ( 去重 ) uv
2. 将每条数据添加一个字段来标识,如果这个用户的 id 是第一次出现,那么就标注 1 ,否则就是 0
依赖:
XML <dependencies >dependency >groupId >org.apache.kafka</groupId >artifactId >kafka-clients</artifactId >version >${kafka.version}</version >dependency >dependency >groupId >com.alibaba</groupId >artifactId >fastjson</artifactId >version >1.2.75</version >dependency >dependency >groupId >org.apache.commons</groupId >artifactId >commons-lang3</artifactId >version >3.8.1</version >dependency >dependency >groupId >org.projectlombok</groupId >artifactId >lombok</artifactId >version >1.18.22</version >dependency ><!-- https://mvnrepository.com/artifact/org.roaringbitmap/RoaringBitmap --> <dependency >groupId >org.roaringbitmap</groupId >artifactId >RoaringBitmap</artifactId >version >0.9.0</version >dependency ><!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency >groupId >com.google.guava</groupId >artifactId >guava</artifactId >version >31.1-jre</version >dependency >dependency >groupId >mysql</groupId >artifactId >mysql-connector-java</artifactId >version >8.0.28</version >dependency >
生产者代码示例:
Java package com.doitedu;import com.alibaba.fastjson.JSON;import lombok.AllArgsConstructor;import lombok.Getter;import lombok.NoArgsConstructor;import lombok.Setter;import org.apache.commons.lang3.RandomStringUtils;import org.apache.commons.lang3.RandomUtils;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;/** * 验证数据: * 创建topic * kafka-topics.sh --create --topic event-log --zookeeper linux01:2181 --partitions 3 --replication-factor 3 * 搞个消费者消费数据 * kafka-console-consumer.sh --bootstrap-server linux01:9092 --topic event-log * {"eventId":"zTUAbXcWbn","guid":7170,"timeStamp":1659944455262} * {"eventId":"KSzaaNmczb","guid":9743,"timeStamp":1659944455823} * {"eventId":"FNUERLlCNu","guid":7922,"timeStamp":1659944456295} * {"eventId":"VmXVJHlpOF","guid":2505,"timeStamp":1659944458267} * {"eventId":"pMIHwLzSIE","guid":7668,"timeStamp":1659944460088} * {"eventId":"ZvGYIvmKTx","guid":3636,"timeStamp":1659944460461} * {"eventId":"jBanTDSlCO","guid":3468,"timeStamp":1659944460787} * {"eventId":"vXregpYeHu","guid":1107,"timeStamp":1659944462525} * {"eventId":"PComosCafr","guid":7765,"timeStamp":1659944463640} * {"eventId":"xCHFOYIJlb","guid":3443,"timeStamp":1659944464697} * {"eventId":"xDToApWwFo","guid":5034,"timeStamp":1659944465953} */ public class Exercise_kafka编程练习 {public static void main(String[] args) throws InterruptedException {new MyData();class MyData{producer = null ;public MyData(){new Properties();BOOTSTRAP_SERVERS_CONFIG "linux01:9092,linux02:9092,linux03:9092" );KEY_SERIALIZER_CLASS_CONFIG class .getName());VALUE_SERIALIZER_CLASS_CONFIG class .getName());producer = new KafkaProducer<String, String>(props);public void genData() throws InterruptedException {new UserEvent();while (true ){// 造数据 userEvent.setGuid(RandomUtils.nextInt (0,10000));randomAlphabetic (10));currentTimeMillis ());toJSONString (userEvent);// 数据造完了就往kafka中写 ProducerRecord<String, String> stringProducerRecord = new ProducerRecord<>("event-log" , json);sleep (RandomUtils.nextInt (200,1000));producer .send(stringProducerRecord);/* {"guid":1,"eventId":"pageview","timestamp":1637868346789} {"guid":1,"eventId":"addcard","timestamp":1637868347625} {"guid":2,"eventId":"collect","timestamp":16378683463219} */ class UserEvent{private Integer guid ;private String eventId ;private long timeStamp ;
消费者代码示例:用hashset来实现:
Java package com.doitedu;import com.alibaba.fastjson.JSON;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;import java.util.*;/** * 分两步走: * 第一步:一个消费者不断的去消费数据 * 第二步:5分钟计算一次,返回用户数这个结果 */ public class Exercise_consumerDemo {public static void main(String[] args) {new HashSet<>();new Thread(new ConsumerThread(set)).start();// 定时的任务调度 Timer timer = new Timer();调度,第一个参数,你给我一个任务,new ConsumerTask(set),5000,10000);class ConsumerThread implements Runnable {set = null ;consumer = null ;public ConsumerThread(HashSet<Integer> set) {this .set = set;new Properties();BOOTSTRAP_SERVERS_CONFIG "linux01:9092" );KEY_DESERIALIZER_CLASS_CONFIG class .getName());VALUE_DESERIALIZER_CLASS_CONFIG class .getName());GROUP_ID_CONFIG "test001" );consumer = new KafkaConsumer<String, String>(props);consumer .subscribe(Arrays.asList ("event-log" ));/** * 重写run方法的话,我需要在里面实现什么逻辑? * 消费者消费数据,拿到数据以后,只需要获取到用户id * 将用户id写到hashset集合里面 */ @Overridepublic void run() {while (true ) {consumer .poll(Duration.ofMillis (Integer.MAX_VALUE for (ConsumerRecord<String, String> record : records) {parseObject (json, UserEvent.class );set .add(guid);class ConsumerTask extends TimerTask {set = null ;public ConsumerTask(HashSet<Integer> set) {this .set = set;/** * 这里面就是返回的一个用户数 */ @Overridepublic void run() {int userCount = set .size();out currentTimeMillis () + ", 截至到当前为止的一个用户数为:" +userCount);
用hashset来实现很显然会出问题,如果数据量一直往上增长,会出现oom的问题,而且占用资源越来越多,影响电脑性能!!!
方案二:将HashSet改成bitMap来计数,就很完美,大逻辑不变,小逻辑就是将HashMap改成bitMap
Java package com.doitedu;import com.alibaba.fastjson.JSON;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.apache.kafka.common.serialization.StringDeserializer;import org.roaringbitmap.RoaringBitmap;import java.time.Duration;import java.util.*;/** * 分两步走: * 第一步:一个消费者不断的去消费数据 * 第二步:5分钟计算一次,返回用户数这个结果 */ public class BitMap_consumerDemo {public static void main(String[] args) {// 原来我用的是Hashset来记录,现在我用RoaringBitmap来记录 RoaringBitmap bitMap = RoaringBitmap.bitmapOf ();new Thread(new BitMapConsumerThread(bitMap)).start();// 定时的任务调度 Timer timer = new Timer();new BitMapConsumerTask(bitMap),1000,5000);class BitMapConsumerThread implements Runnable {bitMap = null ;consumer = null ;public BitMapConsumerThread(RoaringBitmap bitMap) {this .bitMap = bitMap;new Properties();BOOTSTRAP_SERVERS_CONFIG "linux01:9092" );KEY_DESERIALIZER_CLASS_CONFIG class .getName());VALUE_DESERIALIZER_CLASS_CONFIG class .getName());GROUP_ID_CONFIG "test001" );consumer = new KafkaConsumer<String, String>(props);consumer .subscribe(Arrays.asList ("event-log" ));/** * 重写run方法的话,我需要在里面实现什么逻辑? * 消费者消费数据,拿到数据以后,只需要获取到用户id * 将用户id写到hashset集合里面 */ @Overridepublic void run() {while (true ) {consumer .poll(Duration.ofMillis (Integer.MAX_VALUE for (ConsumerRecord<String, String> record : records) {parseObject (json, UserEvent.class );bitMap .add(guid);class BitMapConsumerTask extends TimerTask {bitMap = null ;public BitMapConsumerTask(RoaringBitmap bitMap) {this .bitMap = bitMap;/** * 这里面就是返回的一个用户数 */ @Overridepublic void run() {int userCount = bitMap .getCardinality();out currentTimeMillis () + ", 截至到当前为止的一个用户数为:" +userCount);
需求二:判断来没来过的问题,可以用bitmap来搞,当然还可以用布隆过滤器来搞
Java package com.doitedu;import com.alibaba.fastjson.JSON;import com.google.common.hash.BloomFilter;import com.google.common.hash.Funnels;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;import java.util.Arrays;import java.util.Properties;import java.util.Timer;import java.util.TimerTask;/** * 用布隆过滤器来判定是否重复,当然,bitMap也是可以操作的 */ public class BloomFilter_consumerDemo {public static void main(String[] args) {create (Funnels.longFunnel (), 100000);new Thread(new BloomFilterConsumerThread(longBloomFilter)).start();class BloomFilterConsumerThread implements Runnable {longBloomFilter = null ;consumer = null ;public BloomFilterConsumerThread(BloomFilter<Long> longBloomFilter) {this .longBloomFilter = longBloomFilter;new Properties();BOOTSTRAP_SERVERS_CONFIG "linux01:9092" );KEY_DESERIALIZER_CLASS_CONFIG class .getName());VALUE_DESERIALIZER_CLASS_CONFIG class .getName());GROUP_ID_CONFIG "test001" );consumer = new KafkaConsumer<String, String>(props);consumer .subscribe(Arrays.asList ("event-log" ));/** * 重写run方法的话,我需要在里面实现什么逻辑? * 消费者消费数据,拿到数据以后,只需要获取到用户id * 将用户id写到hashset集合里面 */ @Overridepublic void run() {while (true ) {consumer .poll(Duration.ofMillis (Integer.MAX_VALUE for (ConsumerRecord<String, String> record : records) {parseObject (json, UserEvent.class );boolean flag = longBloomFilter .mightContain((long ) guid);if (flag) {else {// 判断完成以后,得把他加进去 longBloomFilter .put((long ) guid);out toJSONString (userEvent));
消费者组再均衡分区分配策略
会触发rebalance(消费者)的事件可能是如下任意一种:
有消费者宕机下线,消费者并不一定需要真正下线,例如遇到长时间的 GC 、网络延迟导致消费者长时间未向GroupCoordinator发送心跳等情况时,GroupCoordinator 会认为消费者己下线。 有消费者主动退出消费组(发送LeaveGroupRequest 请求):比如客户端调用了unsubscrible()方法取消对某些主题的订阅。 消费组所对应的 GroupCoorinator节点发生了变更。 消费组内所订阅的任一主题或者主题的分区数量发生变化。 将分区的消费权从一个消费者移到另一个消费者称为再均衡(rebalance),如何rebalance也涉及到分区分配策略。
kafka有两种的分区分配策略:range(默认) 和 roundrobin(新版本中又新增了另外2种)
我们可以通过 partition.assignment.strategy 参数选择 range 或 roundrobin 。
partition.assignment.strategy 参数默认的值是 range 。
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
partition.assignment.strategy=org.apache.kafka.clients.consumer.RangeAssignor
Range Strategy
先将消费者按照client.id字典排序,然后按topic逐个处理; 针对一个topic,将其partition总数/消费者数得到商n和 余数m,则每个consumer至少分到n个分区,且前m个consumer每人多分一个分区; 举例说明 1 :假设有 TOPIC_A 有 5 个分区,由 3 个 consumer ( C1,C2,C3 )来消费; 5/3 得到商 1 ,余 2 ,则每个消费者至少分 1 个分区,前两个消费者各多 1 个分区 C1: 2 个分区, C2:2 个分区 ,C3:1 个分区
接下来,就按照 “ 区间 ” 进行分配:
TOPIC_A-0 TOPIC_A-1 TOPIC_A-2 TOPIC_A_3 TOPIC_A-4
C1: TOPIC_A-0 TOPIC_A-1
C2 : TOPIC_A-2 TOPIC_A_3
C3: TOPIC_A-4
举例说明 2 :假设 TOPIC_A 有 5 个分区, TOPIC_B 有 3 个分区,由 2 个 consumer ( C1,C2 )来消费
5/2 得到商 2 ,余 1 ,则 C1 有 3 个分区, C2 有 2 个分区,得到结果
C1: TOPIC_A-0 TOPIC_A-1 TOPIC_A-2
C2: TOPIC_A-3 TOPIC_A-4
3/2 得到商 1 ,余 1 ,则 C1 有 2 个分区, C2 有 1 个分区,得到结果
C1: TOPIC_B-0 TOPIC_B-1
C2: TOPIC_B-2
C1: TOPIC_A-0 TOPIC_A-1 TOPIC_A-2 TOPIC_B-0 TOPIC_B-1
C2: TOPIC_A-3 TOPIC_A-4 TOPIC_B-2
Round-Robin Strategy
将所有主题分区组成TopicAndPartition列表,并对TopicAndPartition列表按照其hashCode 排序 以上述 “ 例 2” 来举例:
先对 TopicPartition 的 hashCode 排序,假如排序结果如下: TOPIC_A-0 TOPIC_B-0 TOPIC_A-1 TOPIC_A-2 TOPIC_B-1 TOPIC_A-3 TOPIC_A-4 TOPIC_B-2
C1: TOPIC_A-0 TOPIC_A-1 TOPIC_B-1
C2: TOPIC_B-0 TOPIC_A-2 TOPIC_A-3
C3 TOPIC_A-4
Sticky Strategy
对应的类叫做: org.apache.kafka.clients.consumer.StickyAssignor
sticky策略的特点:
再均衡的过程中,还是会让各消费者先取消自身的分区,然后再重新分配(只不过是分配过程中会尽量让原来属于谁的分区依然分配给谁)
6.4.4Cooperative Sticky Strategy
对应的类叫做: org.apache.kafka.clients.consumer.ConsumerPartitionAssignor
sticky策略的特点:
支持cooperative再均衡机制(再均衡的过程中,不会让所有消费者取消掉所有分区然后再进行重分配) 消费者组再均衡流程
消费组在消费数据的时候,有两个角色进行组内的各事务的协调;
角色1: Group Coordinator (组协调器) 位于服务端(就是某个broker)
组协调器的定位:
Plain Text coordinator 在我们组记偏移量的__consumer_offsets分区的leader所在broker上 groupMetadataTopicPartitionCount 为__consumer_offsets的分区总数,这个可以通过broker端参数offset.topic.num.partitions来配置,默认值是50 ;
角色2: Group Leader (组长) 位于消费端(就是消费组中的某个消费者)
GroupCoordinator 介绍
每个消费组在服务端对应一个GroupCoordinator其进行管理,GroupCoordinator是Kafka服务端中用于管理消费组的组件。
消费者客户端中由ConsumerCoordinator组件负责与GroupCoordinator行交互;
ConsumerCoordinator和GroupCoordinator最重要的职责就是负责执行消费者rebalance操作
再均衡流程
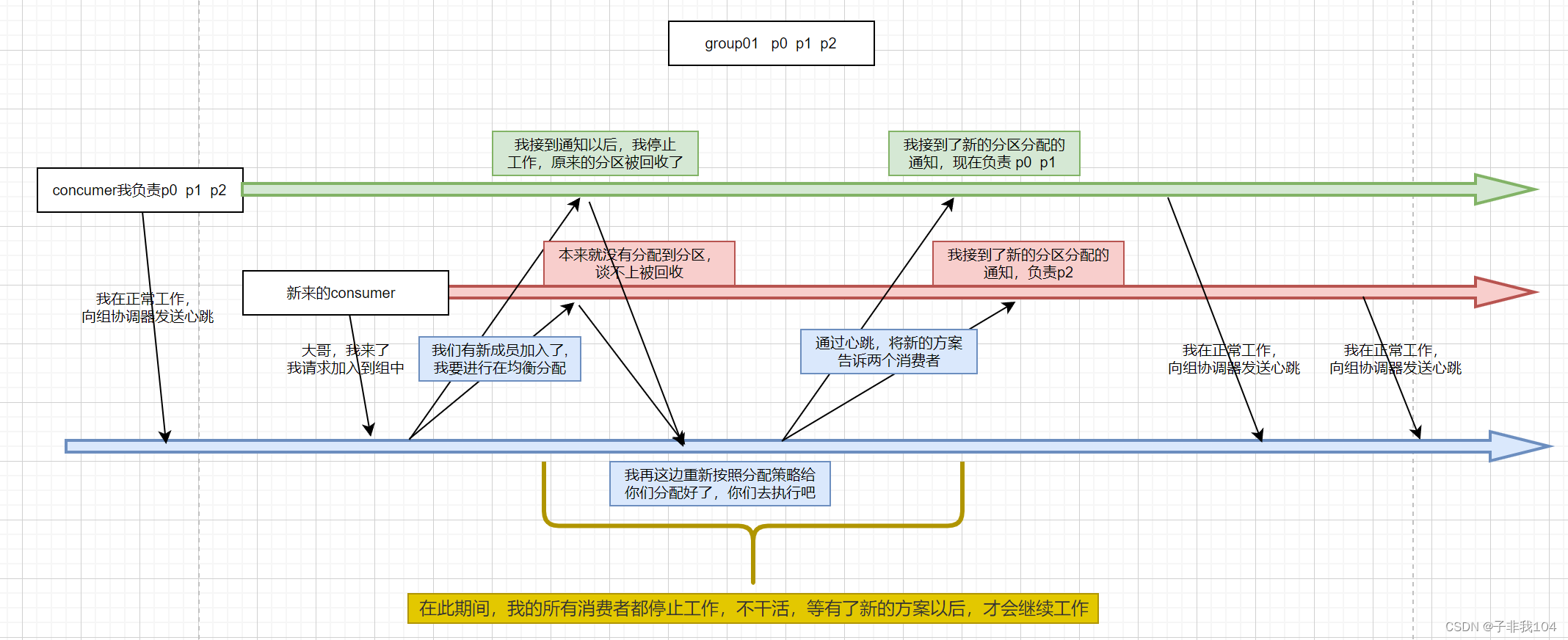
eager协议的再均衡过程整体流程如下图:
特点:再均衡发生时,所有消费者都会停止工作,等待新方案的同步
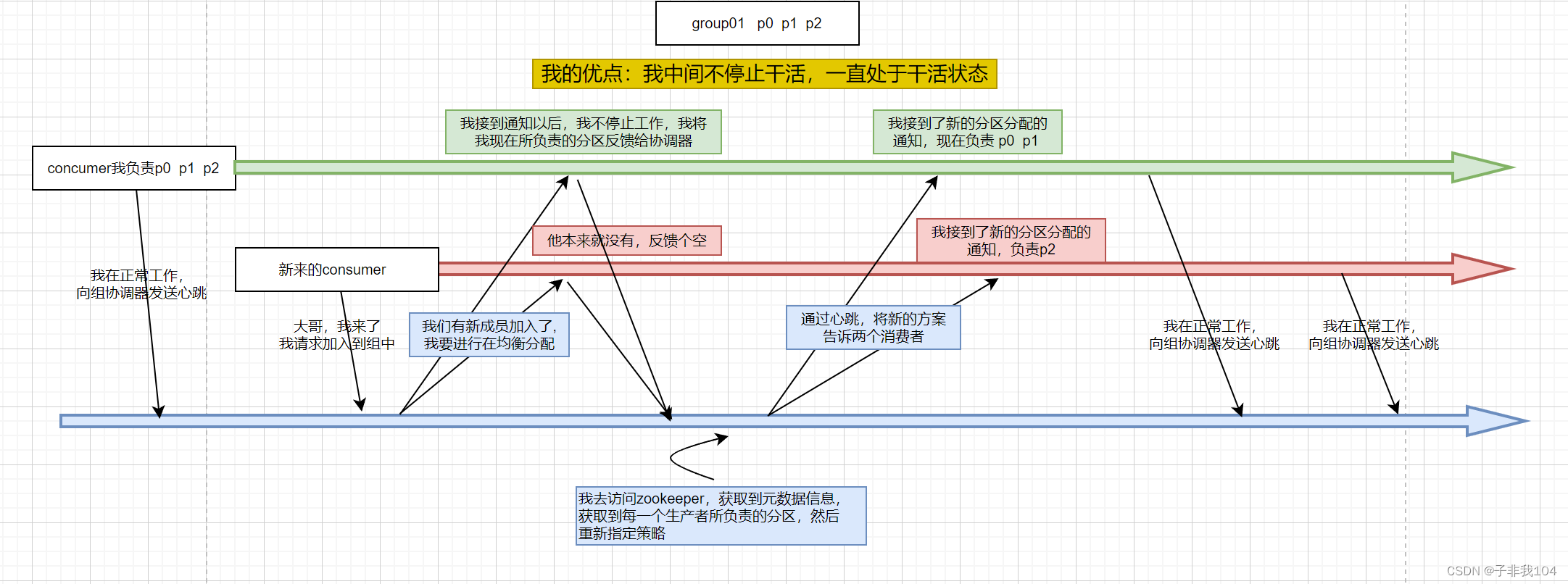
Cooperative协议的再均衡过程整体流程如下图:
特点: cooperative 把原来 eager 协议的一次性全局再均衡,化解成了多次的小均衡,并最终达到全局均衡的收敛状态
再均衡监听器
如果想控制消费者在发生再均衡时执行一些特定的工作,可以通过订阅主题时注册“再均衡监听器”来实现;
场景举例:在发生再均衡时,处理消费位移
如果A消费者消费掉的一批消息还没来得及提交offset,而它所负责的分区在rebalance中转移给了B消费者,则有可能发生数据的重复消费处理。此情形下,可以通过再均衡监听器做一定程度的补救;
代码示例:
Java package com.doitedu; import org.apache.kafka.clients.consumer.*; import org.apache.kafka.common.TopicPartition; import org.apache.kafka.common.header.Headers; import org.apache.kafka.common.record.TimestampType; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.Arrays; import java.util.Collection; import java.util.Optional; import java.util.Properties; /** * 消费组再均衡观察 */ public class ConsumerDemo2 { public static void main(String[] args) { //1. 创建kafka的消费者对象,附带着把配置文件搞定 Properties props = new Properties(); props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG "linux01:9092,linux02:9092,linux03:9092" ); props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG class .getName()); props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG class .getName()); props.setProperty(ConsumerConfig.GROUP_ID_CONFIG "g01" ); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); //2. 订阅主题(确定需要消费哪一个或者多个主题) // 我现在想看看如果我的消费者组里面,多了一个消费者或者少了一个消费者,他有没有给我做再均衡 consumer.subscribe(Arrays.asList ("reb-1" , "reb-2" ), new ConsumerRebalanceListener() { /** * 这个方法是将原来的分配情况全部取消,或者说把所有的分区全部回收了 * 这个全部取消很恶心,原来的消费者消费的好好的,他一下子就给他全部停掉了 * @param collection */ @Override public void onPartitionsRevoked(Collection<TopicPartition> collection) { System.out " 我原来的均衡情况是:" +collection + " 我已经被回收了!!" ); } /** * 这个方法是当上面的分配情况全部取消以后,调用这个方法,来再次分配,这是在均衡分配后的情况 * @param collection */ @Override public void onPartitionsAssigned(Collection<TopicPartition> collection) { System.out " 我是重新分配后的结果:" +collection); } }); while (true ){ consumer.poll(Duration.ofMillis (Integer.MAX_VALUE } } }