为了学习机器学习,在此先学习以下数据分析的matplotlib,numpy,pandas,主要是为自己的学习做个记录,如有不会的可以随时查阅。希望大家可以一起学习共同进步,我们最终都可以说:功不唐捐,玉汝于成。
数据分析
把大量的数据进行统计和整理,得出结论,为后续的决策提供数据支持
matplotlib
1.什么是matplotlib
2.matplotlib基本要点
3.matolotlib的散点图、直方图、柱状图
4.更多的画图工具
为什么要学习matplotlib
- 能将数据进行可视化,更直观的呈现
- 使数据更加客观、更具说服力
什么是matplotlib
最流行的python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建
matplotlib可以绘制折线图、散点图、柱状图、直方图、箱线图、饼图等。
折线图
以折线的上升或下降来表示统计数量的增减变化的统计图
特点:能够显示数据的变化趋势,反映事务的变化情况(变化)
直方图
由一系列高度不等的纵向条纹或线段表示数据分布的情况,一般用横轴表示数据范围,纵轴表示分布情况
特点:绘制连续性的数据,展示一组或多组数据的分布状况(统计)
条形图
排列在工作表的列或行中的数据可以绘制到条形图中
特点:绘制离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别(统计)
散点图
用两组数据构成多个坐标点,考虑坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式
特点:
判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
matplotlib基本要点

那么上面的每一个红色的点是什么呢?
每个红色的点是坐标,把5个点的坐标连接成一条线,组成了一个折线图。
演示matplotlib简单的使用
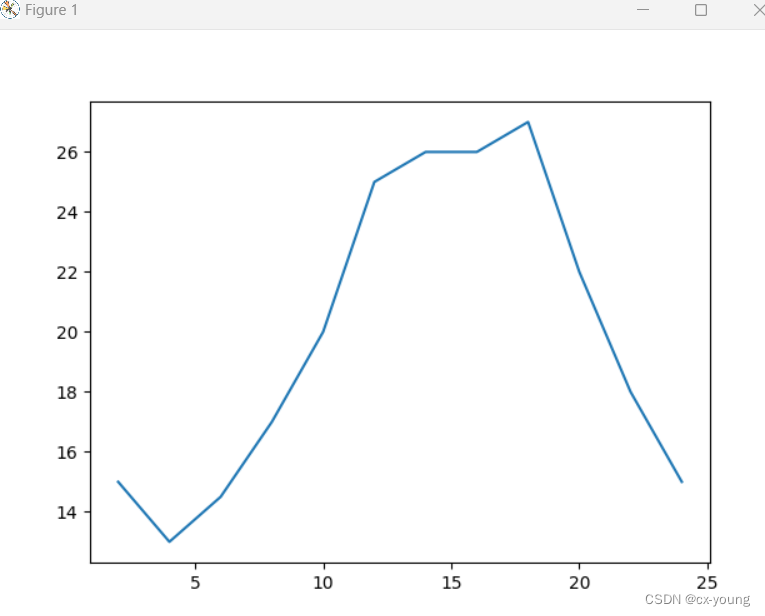
假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是
[15,13,14,5,17,20,25,26,26,27,22,18,15]
'''
假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是
[15,13,14,5,17,20,25,26,26,27,22,18,15]
'''
from matplotlib import pyplot as plt#导入pyplot
#数据在x轴的位置,是一个可迭代对象
x = range(2,26,2)
#数据在y轴的位置,是一个可迭代对象
y = [15,13,14.5,17,20,25,26,26,27,22,18,15]
'''x轴和y轴的数据一起组成了所有要绘制的坐标
分别是(2,15),(4,13),(6,14.5),(8,17)......'''
#传入x和y,通过plot绘制出折线图
plt.plot(x,y)
plt.show()#在执行程序的时候展示图形
运行结果:
案例存在以下几个问题
1.设置图片大小(想要一个高清无码大图)
2.保存到本地
3.描述信息,比如x轴和y轴表示什么,这个图表示什么
4.调整x或y的刻度的间距
5.线条的样式(比如颜色,透明度等)
6.标记出特殊的点(比如告诉别人最高点和最低点在哪里)
7.给图片添加一个水印(防伪,防止盗用)
'''
假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是
[15,13,14,5,17,20,25,26,26,27,22,18,15]
'''
from matplotlib import pyplot as plt#导入pyplot
### 设置图片大小
'''设置图片大小
figure图形图标的意思,在这里指的就是我们画的图
通过实例化一个figure并且传递参数,能够在后台自动使用该figure实例
在图像模糊时,可以传入dpi参数,让图片更清晰
'''
fig = plt.figure(figsize=(20,8),dpi=80)
#数据在x轴的位置,是一个可迭代对象
x = range(2,26,2)
#数据在y轴的位置,是一个可迭代对象
y = [15,13,14.5,17,20,25,26,26,27,22,18,15]
'''
x轴和y轴的数据一起组成了所有要绘制的坐标
分别是(2,15),(4,13),(6,14.5),(8,17)......
'''
#传入x和y,通过plot绘制出折线图
plt.plot(x,y)
### 保存图片,可以保存svg这种矢量图格式,放大不会有锯齿
# plt.savefig('./t1.png')
###设置x或y轴的刻度
# plt.xticks(x)
_xtick_labels = [i/2 for i in range(4,49)]
# plt.xticks(_xtick_labels)
# plt.xticks(_xtick_labels[::3])#当刻度太密集时,使用列表的步长(间隔取值)来解决,matplotlib会自动帮我们对应
plt.xticks(range(25,50))#设置x的刻度
plt.yticks(range(min(y),max(y)+1))
plt.show()#在执行程序的时候展示图形
那么问题来了:
如果列表a表示10点到12点的每一分钟的气温,如何绘制折线图观察每分钟气温的变化情况?
from matplotlib import pyplot as plt
import random
x = range(0,120)
y = [random.randint(20,35) for i in range(120)]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y)
plt.show()
运行结果:
根据每分钟气温变化绘制折线图
from matplotlib import pyplot as plt, font_manager
import random
import matplotlib
#windows和linux设置字体方法
my_font = {'family' : 'FangSong',
'weight' : 'bold',
'size' : '16'}
# plt.rc( 'font' , ** font) # 步骤一(设置字体的更多属性)
# plt.rc( 'axes' , unicode_minus = False ) # 步骤二(解决坐标轴负数的负号显示问题)
matplotlib.rc('font',** my_font)
x = range(0,120)
y = [random.randint(20,35) for i in range(120)]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y)
#调整x的刻度
_xtick_labels = ["10点{}分".format(i) for i in range(60)]
_xtick_labels += ["11点{}分".format(i) for i in range(60)]
#取步长,数字和字符串一一对应,数据的长度一样 rotation旋转的度数
plt.xticks(list(x)[::3],_xtick_labels[::3],rotation=45)
plt.show()
运行结果:
在上题基础上添加描述信息
from matplotlib import pyplot as plt, font_manager
import random
import matplotlib
#windows和linux设置字体方法
my_font = {'family' : 'FangSong',
'weight' : 'bold',
'size' : '16'}
# plt.rc( 'font' , ** font) # 步骤一(设置字体的更多属性)
# plt.rc( 'axes' , unicode_minus = False ) # 步骤二(解决坐标轴负数的负号显示问题)
matplotlib.rc('font',** my_font)
x = range(0,120)
y = [random.randint(20,35) for i in range(120)]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y)
#调整x的刻度
_xtick_labels = ["10:0{}".format(i) for i in range(10)]
_xtick_labels += ["10:{}".format(i) for i in range(10,60)]
_xtick_labels += ["11:0{}".format(i) for i in range(10)]
_xtick_labels += ["11:{}".format(i) for i in range(10,60)]
#取步长,数字和字符串一一对应,数据的长度一样 rotation旋转的度数
plt.xticks(list(x)[::3],_xtick_labels[::3],rotation=45)
#添加描述信息
plt.xlabel("时间")
plt.ylabel("温度 单位(℃)")
plt.title("10点到12点每分钟的气温变化情况")
plt.show()
运行结果:
案例绘制11到30岁看书数量折线图
from matplotlib import pyplot as plt
import matplotlib
'''
假设小明在30岁的时候,根据自己的实际情况,统计出
从1到30岁每年看过的书籍数量,请绘制折线图,
以便分析自己每年所看书籍数量走势
x轴表示岁数
y轴表示个数
'''
#windows和linux设置字体方法
my_font = {'family' : 'FangSong',
'weight' : 'bold',
'size' : '16'}
# plt.rc( 'font' , ** font) # 步骤一(设置字体的更多属性)
# plt.rc( 'axes' , unicode_minus = False ) # 步骤二(解决坐标轴负数的负号显示问题)
matplotlib.rc('font',** my_font)
y = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
x = range(11,31)
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y)
#设置x轴刻度
_xtick_labels = ["{}岁".format(i) for i in x]
plt.xticks(x,_xtick_labels)
plt.yticks(range(0,9))
#绘制网格
plt.grid(alpha=0.4)
#添加描述信息
plt.xlabel("年龄")
plt.ylabel("书本数量")
plt.title("每年所看书籍数量走势")
#展示
plt.show()
运行结果:
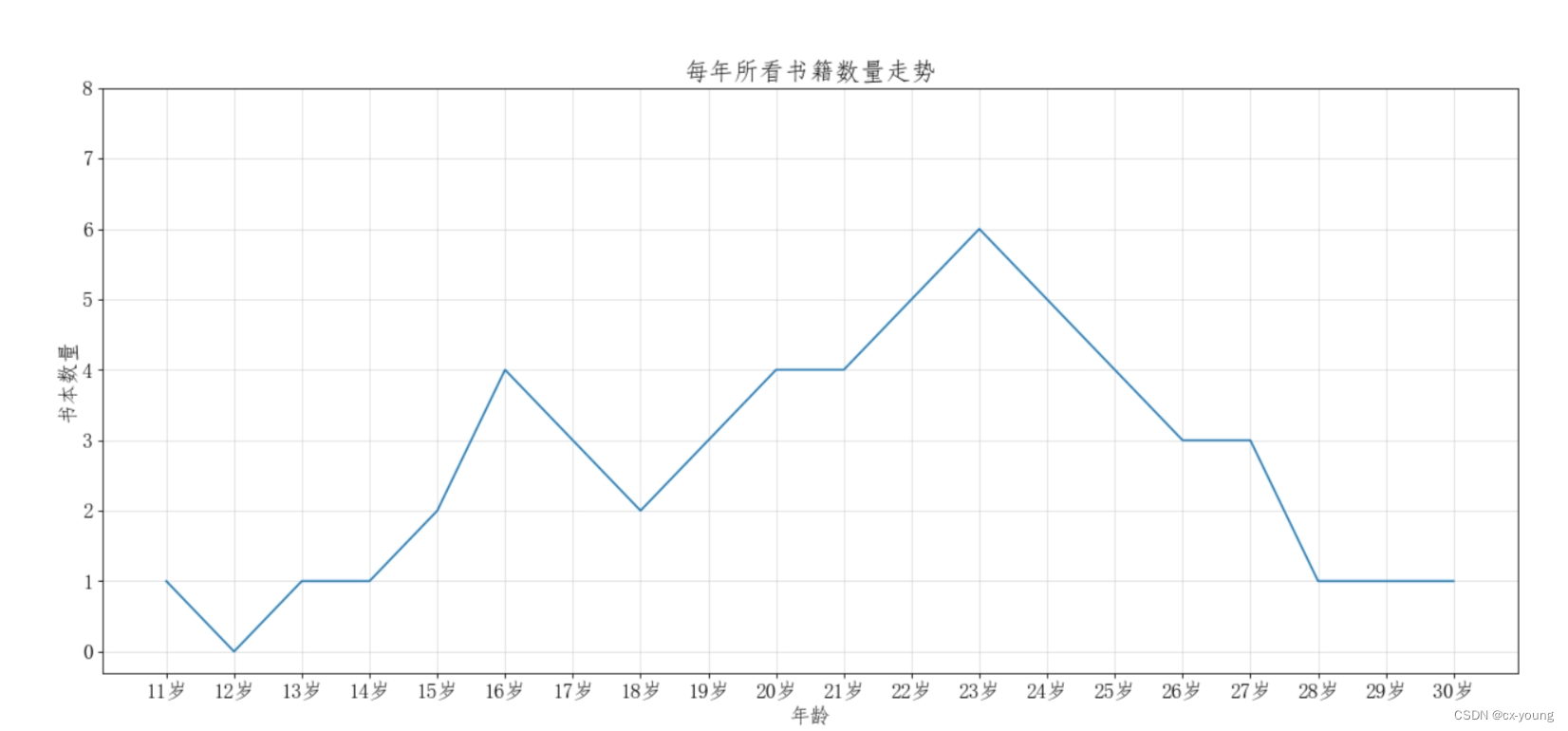
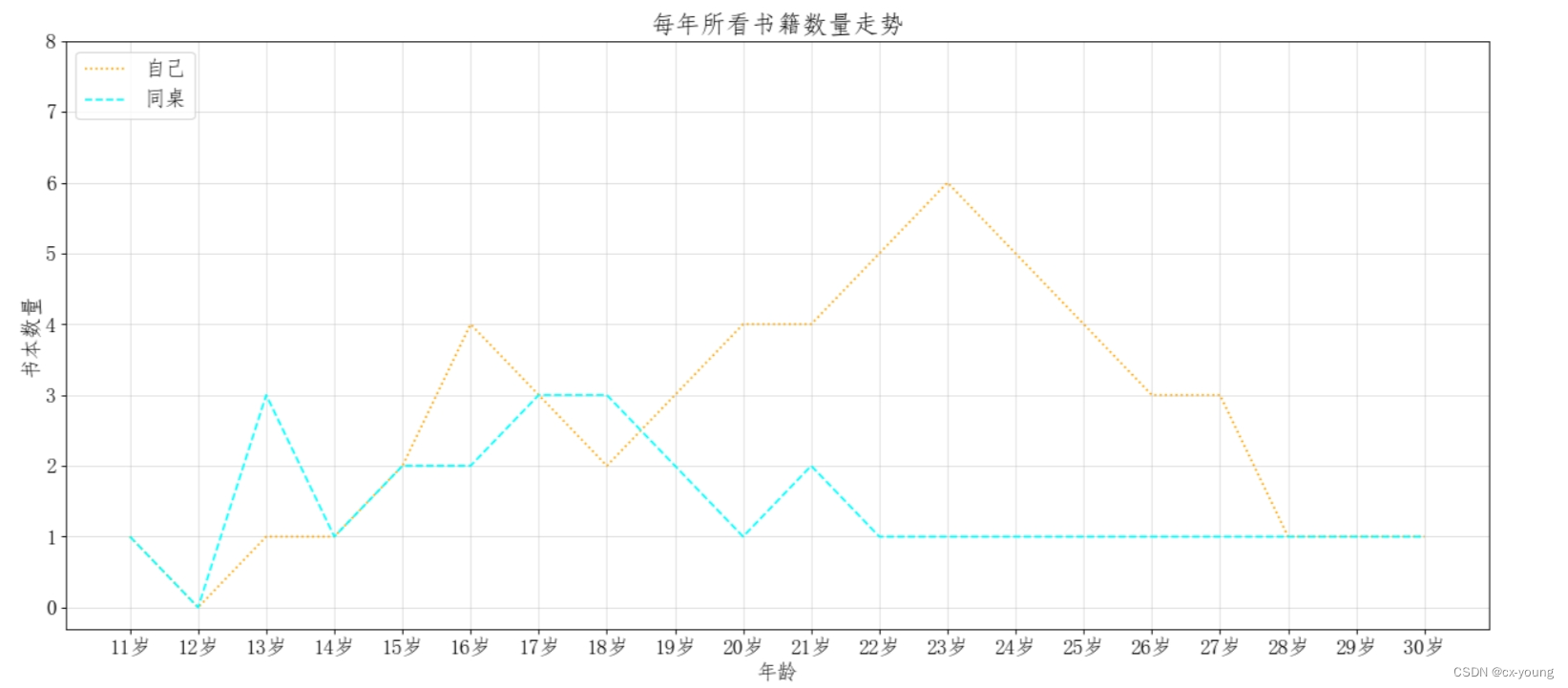
案例绘制自己和同桌两人的看书数量折线图
from matplotlib import pyplot as plt
import matplotlib
'''
假设小明在30岁的时候,根据自己的实际情况,统计出
从1到30岁每年看过的书籍数量,请绘制折线图,
以便分析自己每年所看书籍数量走势
x轴表示岁数
y轴表示个数
'''
#windows和linux设置字体方法
my_font = {'family' : 'FangSong',
'weight' : 'bold',
'size' : '16'}
# plt.rc( 'font' , ** font) # 步骤一(设置字体的更多属性)
# plt.rc( 'axes' , unicode_minus = False ) # 步骤二(解决坐标轴负数的负号显示问题)
matplotlib.rc('font',** my_font)
y_1 = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
y_2 = [1,0,3,1,2,2,3,3,2,1,2,1,1,1,1,1,1,1,1,1]
x = range(11,31)
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
#通过label指定显示的图例内容
plt.plot(x,y_1,label="自己",color='orange',linestyle=':')
plt.plot(x,y_2,label="同桌",color='cyan',linestyle='--')
#设置x轴刻度
_xtick_labels = ["{}岁".format(i) for i in x]
plt.xticks(x,_xtick_labels)
plt.yticks(range(0,9))
#绘制网格
plt.grid(alpha=0.4)
#添加图例
#通过prop指定图例的字体
#通过loc指定图例的位置,默认右上角
plt.legend(prop=my_font,loc='upper left')
#添加描述信息
plt.xlabel("年龄")
plt.ylabel("书本数量")
plt.title("每年所看书籍数量走势")
#展示
plt.show()
运行结果:
自定义绘制图形风格
plt.plot(
x,#x
y,#y
#在绘制的时候指定即可
color='r',#线条颜色 r红色,g绿色,b蓝色,w白色,y黄色
linestyle='--',#线条风格 -实线 --虚线 -.点画线 :点虚线
linewidth=5,#线条粗细
alpha=0.5#透明度
)
matplotlib绘制散点图
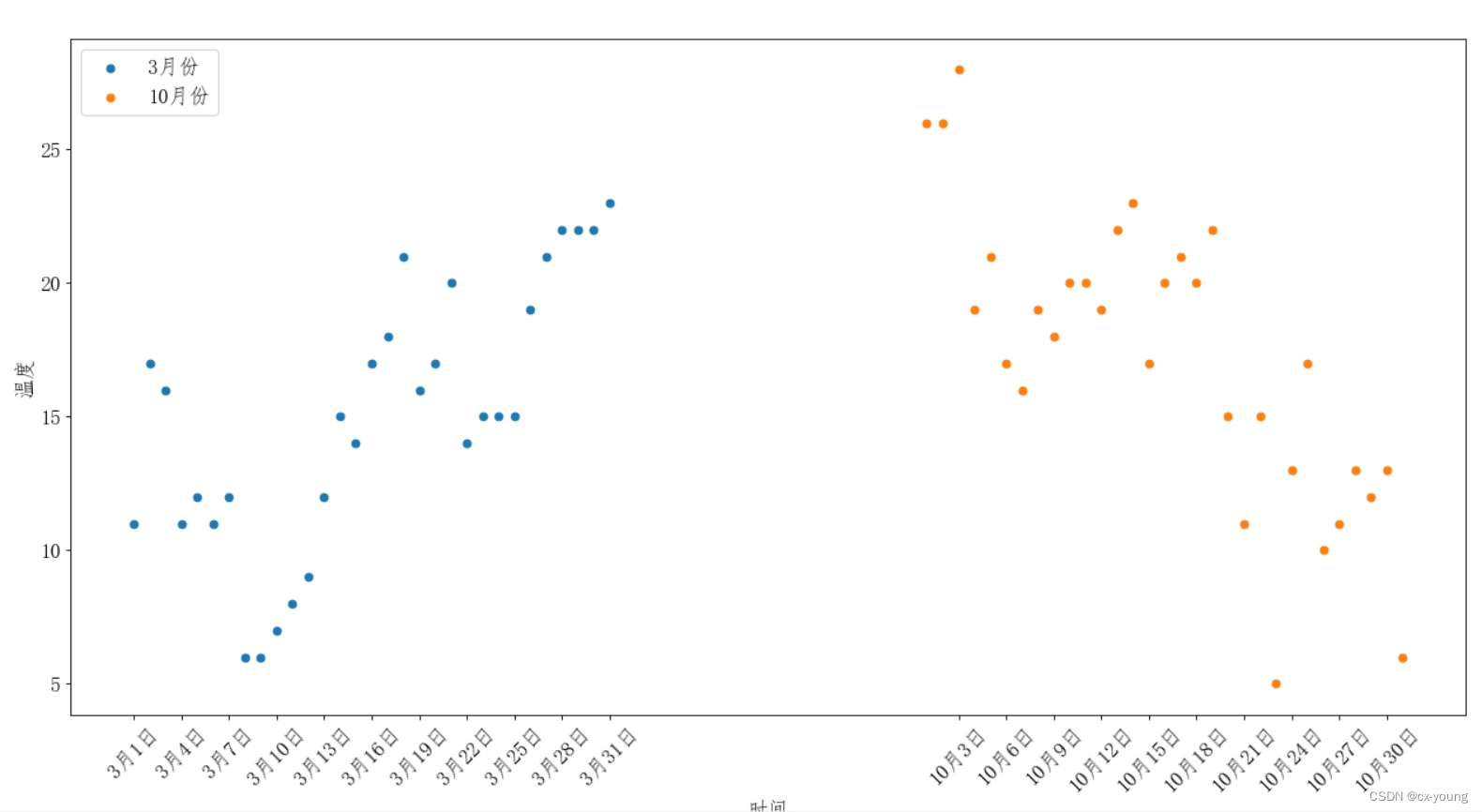
假设通过爬虫你获取了某地3
月份,10月份每天白天的最高气温,那么此时绘制出它的散点图
y_3 = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
y_10 = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
#绘制散点图
from matplotlib import pyplot as plt
import matplotlib
#windows和linux设置字体方法
my_font = {'family' : 'FangSong',
'weight' : 'bold',
'size' : '16'}
# plt.rc( 'font' , ** font) # 步骤一(设置字体的更多属性)
# plt.rc( 'axes' , unicode_minus = False ) # 步骤二(解决坐标轴负数的负号显示问题)
matplotlib.rc('font',** my_font)
y_3 = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
y_10 = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
x_3 = range(1,32)
x_10 = range(51,82)
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
#使用scatter绘制散点图,和之前绘制折线图的唯一区别
plt.scatter(x_3,y_3,label='3月份')
plt.scatter(x_10,y_10,label='10月份')
#调整x轴的刻度
_x = list(x_3) + list(x_10)
_xtick_labels = ['3月{}日'.format(i) for i in x_3]
_xtick_labels += ['10月{}日'.format(i-50) for i in x_10]
plt.xticks(_x[::3],_xtick_labels[::3],rotation=45)
#添加图例
plt.legend(loc = 'upper left')
#添加描述信息
plt.xlabel('时间')
plt.ylabel('温度')
plt.show()
运行结果:
散点图应用场景
不同条件(维度)之间的内在关联关系
观察数据的离散聚合程度
绘制条形图
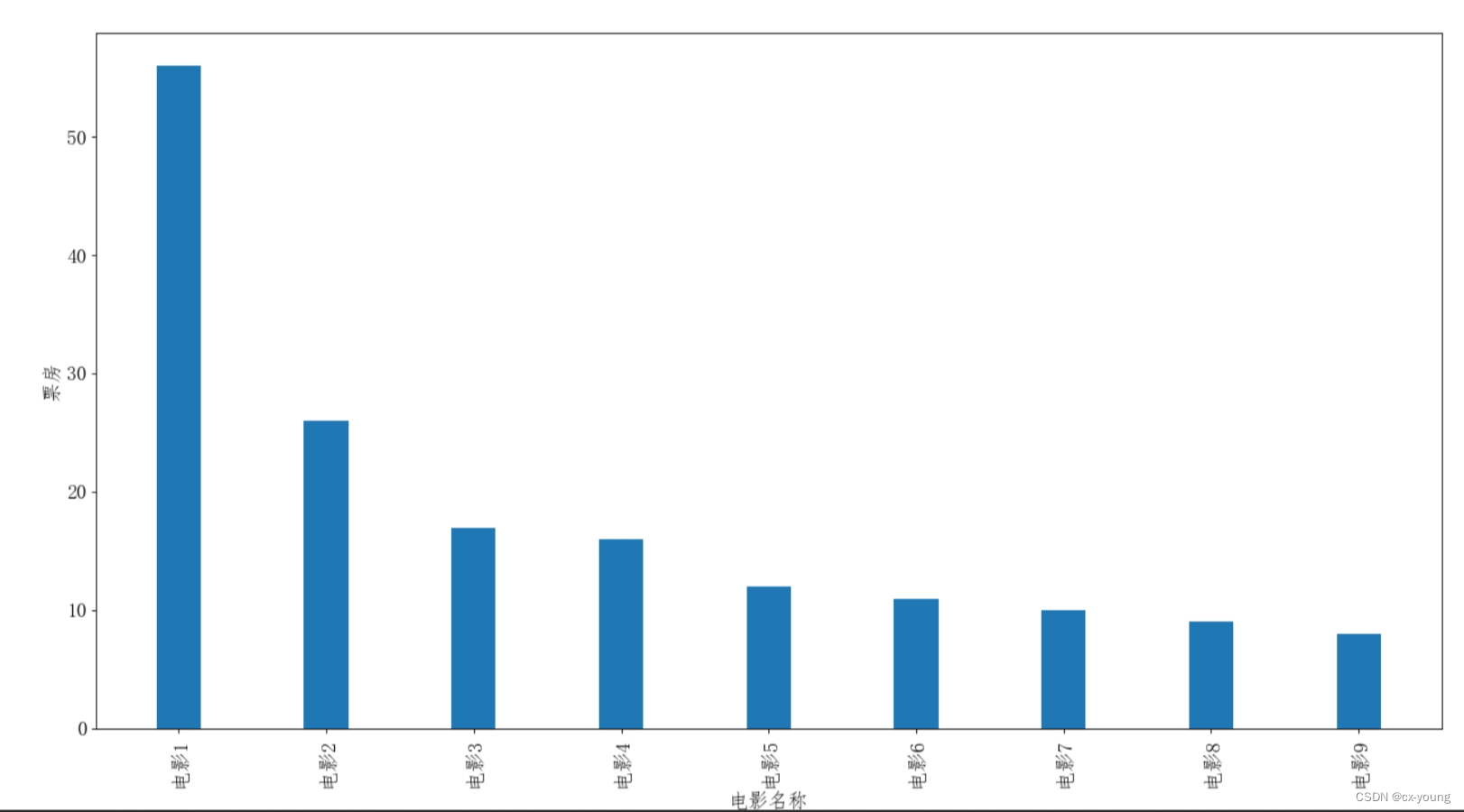
假设你获得了电影以及其对应的票房。
绘制竖条形图
#绘制条形图
from matplotlib import pyplot as plt
import matplotlib
#windows和linux设置字体方法
my_font = {'family' : 'FangSong',
'weight' : 'bold',
'size' : '16'}
# plt.rc( 'font' , ** font) # 步骤一(设置字体的更多属性)
# plt.rc( 'axes' , unicode_minus = False ) # 步骤二(解决坐标轴负数的负号显示问题)
matplotlib.rc('font',** my_font)
a = ['电影1','电影2','电影3','电影4','电影5','电影6','电影7','电影8','电影9']
b = [56,26,17,16,12,11,10,9,8]
#设置图片大小
plt.figure(figsize=(20,15),dpi=80)
#绘制条形图 竖着的
plt.bar(range(len(a)),b,width=0.3)
#设置字符串到x轴
plt.xticks(range(len(a)),a,rotation=90)
plt.xlabel('电影名称')
plt.ylabel('票房')
plt.show()
运行结果:
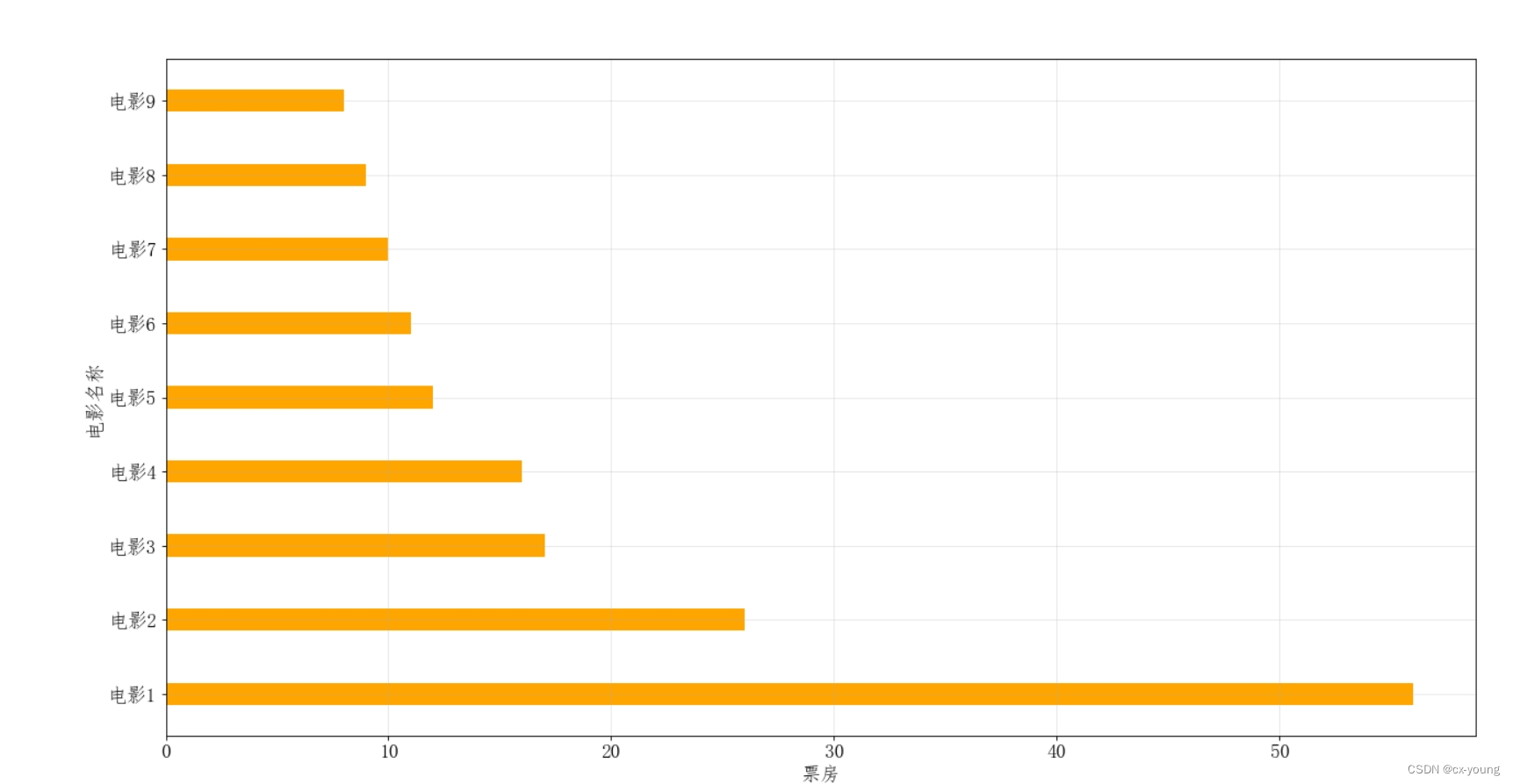
绘制横条形图
#绘制条形图
from matplotlib import pyplot as plt
import matplotlib
#windows和linux设置字体方法
my_font = {'family' : 'FangSong',
'weight' : 'bold',
'size' : '16'}
# plt.rc( 'font' , ** font) # 步骤一(设置字体的更多属性)
# plt.rc( 'axes' , unicode_minus = False ) # 步骤二(解决坐标轴负数的负号显示问题)
matplotlib.rc('font',** my_font)
a = ['电影1','电影2','电影3','电影4','电影5','电影6','电影7','电影8','电影9']
b = [56,26,17,16,12,11,10,9,8]
#设置图片大小
plt.figure(figsize=(20,15),dpi=80)
#绘制条形图 竖着的
plt.barh(range(len(a)),b,height=0.3,color='orange')
#设置字符串到x轴
plt.yticks(range(len(a)),a)
plt.grid(alpha=0.3)
plt.ylabel('电影名称')
plt.xlabel('票房')
plt.show()
运行结果:
绘制三天数据条形图
假设你知道了列表a中电影分别在2017-9-14(b_14),2017-9-15(b_15),2017-9-16(b_16)三天的票房,为了展示列表中电影本身的票房以及其它电影的数据对比情况,应该如何更加直观地呈现该数据
a=[“猩球崛起”,“敦刻尔克”,“蜘蛛侠”,“战狼2”]
b_16 = [15746,312,4497,319]
b_15=[12357,156,2045,168]
b_14=[2358,399,2358,362]
条形图应用场景
数量统计
频率统计(市场饱和度)
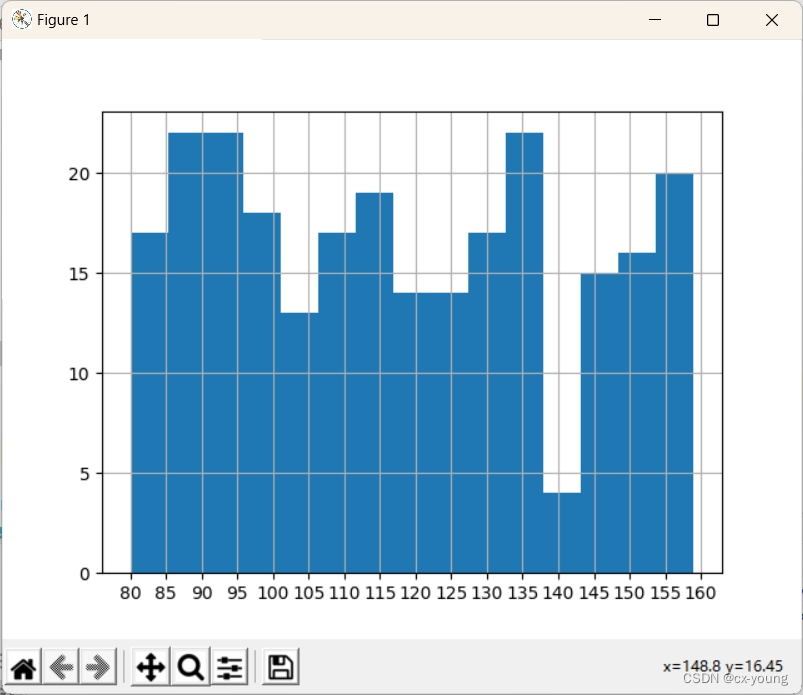
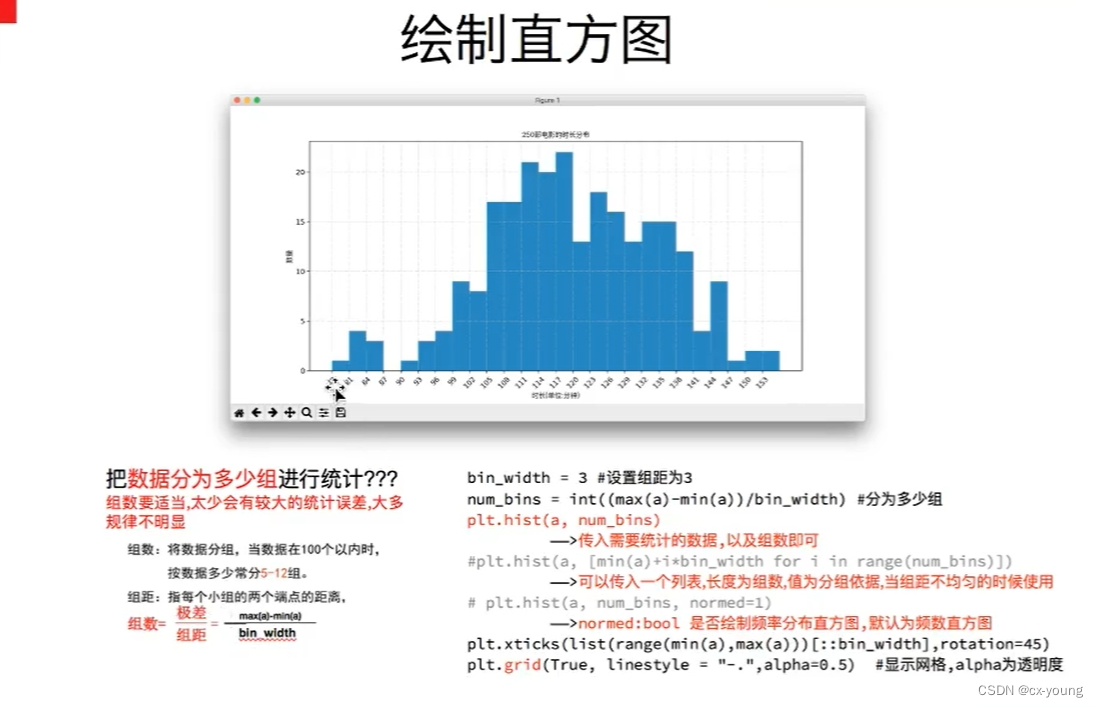
绘制直方图
import matplotlib.pyplot as plt
import numpy as np
lst=[]
for _ in range(250):
a = np.random.randint(80,160)
lst.append(a)#生成数据
#计算组数
d = 5
num_bins = (max(lst) - min(lst))//d
print(lst)
plt.hist(lst,num_bins)
#设置x轴的刻度
plt.xticks(range(min(lst),max(lst)+d,d))
plt.grid()
plt.show()
直方图应用场景
用户的年龄分布状态
一段时间内用户点击次数的分布状态
用户活跃时间的分布状态
matplotlib浅浅总结
| matplotlib | |||
|---|---|---|---|
| plt.plot绘制折线图 | from matplotlib import pyplot as plt | ||
| 设置图形大小和分辨率 | plt.figure(figsize=(20,8),dpi=80) | ||
| 绘图 | plt.plot(x,y) | x(y):所有的坐标的x(y)值 | |
| 调整x(y)轴的刻度 | plt.xticks() | ||
| 调整间距: | 传一个参数(包含数字的可迭代对象),步长合适即可 | ||
| 添加字符串到x(y)轴: | 传入两个参数,分别是两个可迭代对象,数字和字符串最终会一一对应,只显示字符串 | ||
| 展示 | plt.show() | ||
| 图片保存 | plt.savefig(“file_path”) | ||
| 显示中文 | matplotlib.rc | my_font = {‘family’ : ‘FangSong’, ‘weight’ : ‘bold’, ‘size’ : ‘16’} matplotlib.rc(‘font’,** my_font) | |
| font_manager | from matplotlib import font_manager | ||
| my_font=font_manager.FontProperties(fname=“”) | |||
| 一个图中绘制多个图形 | plt.plot()调用多次 | plt.plot(x,y_1,label=“自己”,color=‘orange’,linestyle=‘:’) | |
| plt.plot(x,y_2,label=“同桌”,color=‘cyan’,linestyle=‘–’) | |||
| 图例 | 展示当前这个图形是谁 | ||
| 1.plot(label=“自己”) | |||
| 2.plot.legend(loc,prop) | loc表示的是图例的位置 | ||
| 图形的样式 | color | linestyle,linewidth | |
| 添加图形的描述 | plt.xlabel(“添加描述”) | ||
| plt.ylabel(“添加描述”) | |||
| plt.title(“添加描述”) | |||
| 网格 | plt.grid(alpha=0.4,linestyle=) |
numpy
1.什么是numpy
2.numpy基础
3.numpy常用方法
4.numpy常用统计方法
为什么学习numpy
1.快速
2.方便
3.科学计算的基础库
- 对同样的数据计算任务,使用Numpy比直接使用python代码实现,优点
- 代码更简洁:Numpy直接以数组、矩阵为粒度计算并且支撑大量的数字函数,而python需要for循环从底层实现
- 性能更高效:Numpy的数组存储效率和输入输出计算性能,比Python使用list或者嵌套list好很多
注:Numpy的数据存储和Python原生的list是不一样的
注:Numpy的大部分代码都是C语言实现的,这是Numpy比纯Python代码高效的原因 - Numpy是Python各种数据科学类库的基础库
比如:Scipy、Scikit-Learn、TensorFlow、pandas等
什么是numpy
一个在python中做科学计算的基础库,重在数值计算,也是大部分python科学计算库的急促库,多用于大型、多多维数组上执行数值运算
- Numerical Python
- 一个开源的python科学计算库
- 使用Numpy可以方便地使用数组、矩阵进行计算
- 包含线性代数、傅里叶变换、随机数生成等大量函数
Numpy下载与安装
- 在Windows系统下安装Numpy有两种常用方式
1.使用Python包管理器pip来安装numpy,是一种最简单、最轻量级的方法。只需要执行以下命令即可
pip install numpy
2.使用anaconda(官网下载:https://www.anaconda.com/)是一个开源的python发行版,应用较为广泛。
numpy ndarray对象
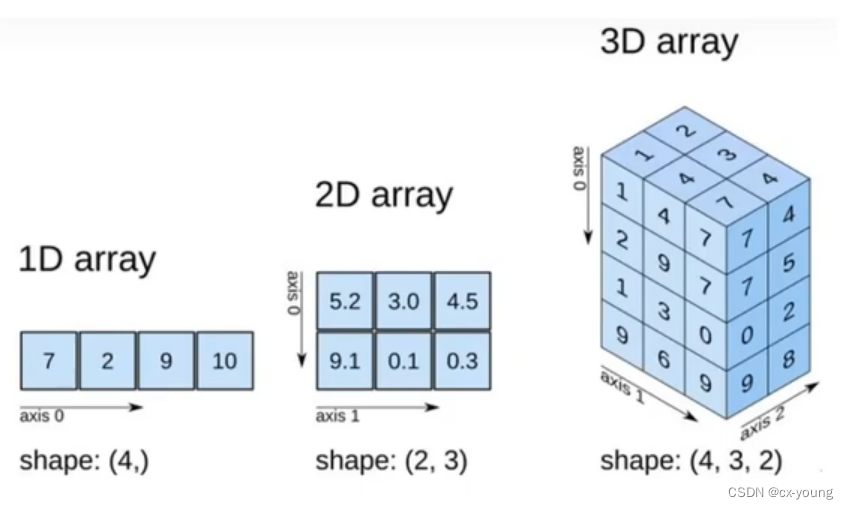
- numpy定义了一个n维数组对象,简称ndarray对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块。
- ndarray对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列(行或列)
numpy创建数组(矩阵)
numpy.array(object,dtype = None,copy = True,order = None,subok = False,ndmin = 0)
参数
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | object | 表示一个数组序列 |
| 2 | dtype | 可选参数,通过它可以更改数组的数据类型 |
| 3 | copy | 可选参数,当数据源是ndarray时表示数组能否被复制,默认时True |
| 4 | order | 可选参数,以哪种内存布局创建数组,有3个可选值,分别是C(行序列)/F(列序列)/A(默认) |
| 5 | ndmin | 可选参数用于指定数组的维度 |
| 6 | subok | 可选参数,类型为bool值,默认False。为True:使用object的内部数据类型;False:使用object数组的数据类型 |
import random
import numpy as np
# 使用numpy生成数组,得到ndarray的类型
t1 = np.array([1, 2, 3])
print(t1, type(t1))
t2 = np.array(range(10))
print(t2, type(t2))
t3 = np.arange(4, 10, 2)
print(t3, type(t3), t3.dtype)
# 调整数据类型
t4 = t3.astype(int)
print(t4, t4.dtype)
# numpy中的小数
t5 = np.array([random.random() for i in range(10)])
print(t5, t5.dtype)
print('------------')
# 取两位小数
t8 = np.round(t5, 2)
print(t8)
运行结果:
[1 2 3] <class 'numpy.ndarray'>
[0 1 2 3 4 5 6 7 8 9] <class 'numpy.ndarray'>
[4 6 8] <class 'numpy.ndarray'> int32
[4 6 8] int32
[0.15005218 0.04573021 0.16078498 0.81148836 0.69045563 0.50318601
0.04133977 0.04835085 0.04299551 0.79446533] float64
------------
[0.15 0.05 0.16 0.81 0.69 0.5 0.04 0.05 0.04 0.79]
数组的形状与修改
# 数组的形状
import numpy as np
t1 = np.arange(12)
# 查看数组的形状 x.shape
print(t1, 't1.shape',t1.shape)
print('*' * 15)
t2 = np.array([[1, 2, 3], [4, 5, 6]])
print(t2,'t2.shape',t2.shape)
print()
# 修改数组的形状 x.reshape
t1 = t1.reshape(3, 4)#.reshape有返回值,不会对本身t1影响进行改变
print('t1.reshape(3, 4)',t1)#若t1=None,原地操作,对数据本身进行修改,没有返回值
#转成一维数组
t1 = t1.flatten()
print(t1)
运行结果:
[ 0 1 2 3 4 5 6 7 8 9 10 11] t1.shape (12,)
***************
[[1 2 3]
[4 5 6]] t2.shape (2, 3)
t1.reshape(3, 4) [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[ 0 1 2 3 4 5 6 7 8 9 10 11]
轴(axis)
在numpy中可以理解为方向,使用0,1,2…数字表示,对于一个一维数组,只有一个0轴,对于二维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2,3)),有0,1,2轴
有了轴的概念之后,计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值
在前面的知识里,请问轴在哪里呢?
回顾np.arange(0,10).reshape(2,5),reshape中2表示0轴长度(包含数据的条数)为2,1轴长度为5,2x5一个10个数据。
numpy读取数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分割行列的格式化文本,每一行的数据表示一条记录
由于CSV便于展示读取和写入,所以很多地方也是用CSV的格式存储和传输中小型的数据。
np.loadtxt(frame,dtype=np.float,delimiter=',',skiprows=0,usecols=None,unpack=False)
| 参数解释 | |
|---|---|
| frame | 文件、字符串或产生器,可以是.gz或bz2压缩文件 |
| dtype | 数据类型,可选,CSV的字符串以什么数据类型读入数组中,默认np.float |
| delimiter | 分割字符串,默认是任何空格,改为逗号 |
| skiprows | 跳过前x行,一般跳过第一行表头 |
| usecols | 读取指定的列,索引,元组类型 |
| unpack | 如果True,读入属性将分别写入不同数组变量,相当于转置的效果;False读入数据只写入一个数组变量,默认False |
代码演示:
#这个是自己胡乱写的一个.csv文件
143,456,789,100
1,2,3,5
4,111,124,556
代码
import numpy as np
us_file_path ="file.csv"
t1 = np.loadtxt(us_file_path,delimiter=',',dtype='int',unpack=True)
t2 = np.loadtxt(us_file_path,delimiter=',',dtype='int')
print(t1)
print('*'*18)
print(t2)
运行结果:
[[143 1 4]
[456 2 111]
[789 3 124]
[100 5 556]]
******************
[[143 456 789 100]
[ 1 2 3 5]
[ 4 111 124 556]]
numpy中的转置
转置是一种变换,对于numpy中的数组来说,就是在对角线方向交换数据,目的也是为了更方便的去处理数据。以下代码演示的三种方法都可以实现二维数组的转置效果,转置和交换轴的效果一样。
代码:
# numpy中的转置
import numpy as np
t1 = np.arange(8).reshape(2,4)
print('转置前:\n', t1)
t2 = t1.transpose()
print('方法1转置后:\n',t2)
t3 = t1.swapaxes(1,0)
print('方法2转置后:\n',t3)
t4 = t1.T
print('方法3转置后:\n',t4)
运行结果:
转置前:
[[0 1 2 3]
[4 5 6 7]]
方法1转置后:
[[0 4]
[1 5]
[2 6]
[3 7]]
方法2转置后:
[[0 4]
[1 5]
[2 6]
[3 7]]
方法3转置后:
[[0 4]
[1 5]
[2 6]
[3 7]]
numpy索引和切片
对于刚刚加载出来的数据,若只想选择其中的某一行或某一列,应该如何操作?
和python的列表一样
具体如代码所示:
import numpy as np
t1 = np.arange(20).reshape(4, 5)
print('输出原t1\n', t1)
print('取一行:\n', t1[2])
print('取连续多行:\n', t1[1:])
print('取不连续多行:\n', t1[[0, 2]])
print()
# 逗号前表示行,逗号后表示列
print('取一列:\n', t1[:, 0])
print('取连续的多列:\n', t1[:, 2:])
print('取不连续的多列:\n', t1[:, [0, 2, 4]])
print('取多行和多列,取第2行到4行,第2列到第4列')
print('取的是交叉点的位置')
print(t1[1:4,1:4])
print('取多个不相邻的点')
#选出来的结果是(0,1),(2,3)
print(t1[[0,2],[1,3]])
#取第2和第4行
print(t1[[1,3],:])
#取第1和第4列
print(t1[:,[0,3]])
运行结果:
输出原t1
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
取一行:
[10 11 12 13 14]
取连续多行:
[[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
取不连续多行:
[[ 0 1 2 3 4]
[10 11 12 13 14]]
取一列:
[ 0 5 10 15]
取连续的多列:
[[ 2 3 4]
[ 7 8 9]
[12 13 14]
[17 18 19]]
取不连续的多列:
[[ 0 2 4]
[ 5 7 9]
[10 12 14]
[15 17 19]]
取多行和多列,取第2行到4行,第2列到第4列
取的是交叉点的位置
[[ 6 7 8]
[11 12 13]
[16 17 18]]
取多个不相邻的点
[ 1 13]
[ 1 13]
[[ 5 6 7 8 9]
[15 16 17 18 19]]
[[ 0 3]
[ 5 8]
[10 13]
[15 18]]
numpy中数值的修改
修改行列的值,很容易实现,若想把数组中小于10的数字替换成3呢?
import numpy as np
t1 = np.arange(20).reshape(4, 5)
print('输出原t1\n', t1)
#输出行列<10的bool值
print('t1<10的bool值\n',t1<10)
#将<10的数字替换为3
t1[t1<10]=3
print('将<10的数字替换为3\n',t1)
#查看值>18的
print('查看值>18的\n',t1[t1>18])
#将>18的替换为100
t1[t1>18]=100
print('将>18的替换为100后\n',t1)
t1[:,2:4]=0
print(t1)
运行结果:
输出原t1
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
t1<10的bool值
[[ True True True True True]
[ True True True True True]
[False False False False False]
[False False False False False]]
将<10的数字替换为3
[[ 3 3 3 3 3]
[ 3 3 3 3 3]
[10 11 12 13 14]
[15 16 17 18 19]]
查看值>18的
[19]
将>18的替换为100后
[[ 3 3 3 3 3]
[ 3 3 3 3 3]
[ 10 11 12 13 14]
[ 15 16 17 18 100]]
[[ 3 3 0 0 3]
[ 3 3 0 0 3]
[ 10 11 0 0 14]
[ 15 16 0 0 100]]
numpy中布尔索引
若想把数组中小于10的数字替换为0,把大于10的替换为10,如何做?
import numpy as np
t1 = np.arange(20).reshape(4, 5)
print(t1)
print()
#小于10的替换为10,大于15的替换为15
t1 = t1.clip(10, 15)
print(t1)
print()
#小于10的替换为100,大于10的替换为300
t1 = np.where(t1 < 11, 100, 300)
print(t1)
运行结果:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
[[10 10 10 10 10]
[10 10 10 10 10]
[10 11 12 13 14]
[15 15 15 15 15]]
[[100 100 100 100 100]
[100 100 100 100 100]
[100 300 300 300 300]
[300 300 300 300 300]]
numpy中的nan和常用方法
- 两个nan是不相等的
np.nan == np.nan
#结果是False
np.nan != np.nan #为True
- 根据以上特性,判断数组中nan的个数
np.count_nonzero(t != t)
- 通过np.isnan(a)判断一个数字是否是nan,返回bool类型。比如希望把nan替换为0
np.isnan(t)
t[np.isnan(t)] = 0
- nan和任何值计算都为nan
以下是代码案例
import numpy as np
t = np.array([1., 2., 3.])
t[0] = np.nan
print(t)
print('判断数组中nan的个数',np.count_nonzero(t != t))
print('判断一个数字是否是nan',np.isnan(t))
print('根据返回bool类型,希望将nan替换为0')
t[np.isnan(t)] = 0
print(t)
运行结果:
[nan 2. 3.]
判断数组中nan的个数 1
判断一个数字是否是nan [ True False False]
根据返回bool类型,希望将nan替换为0
[0. 2. 3.]
案例 将数组中nan替换为该列的均值
#将数组中的nan替换为该列的均值
import numpy as np
def fill_ndarray(t1):
for i in range(t1.shape[1]): # 遍历每一列
temp_col = t1[:, i] # 当前的一列
#np.count_nonzero 判断数组中nan的个数
nan_num = np.count_nonzero(temp_col != temp_col)
if nan_num != 0: # 不为0,说明当前这一列有nan
temp_not_nan_col = temp_col[temp_col == temp_col]
# 选中当前为nan的位置,把值赋值为不为nan的均值
#判断一个数字是否为nan,通过np.isnan()来判断,通过布尔类型,比如希望nan替换为0
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()
return t1
if __name__ == '__main__':
t1 = np.arange(12).reshape(3, 4).astype('float')
t1[1, 2:] = np.nan
print(t1)
print()
t1 = fill_ndarray(t1)
print(t1)
运行结果:
[[ 0. 1. 2. 3.]
[ 4. 5. nan nan]
[ 8. 9. 10. 11.]]
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]]
numpy中常用的统计函数
| 常用的统计函数 | |
|---|---|
| 求和 | t.sum(axis=None) |
| 均值 | t.mean(a,axis=None) 受离群点的影响较大 |
| 中值 | np.median(t.axis=None) |
| 最大值 | t.max(axis=None) |
| 最小值 | t.min(axis=None) |
| 极值 | np.ptp(t,axis=None) 即最大值和最小值之差 |
| 标准差 | t.std(axis=None) |
| 默认返回多维数组的全部的统计结果,若指定axis,则返回一个当前轴上的结果 |
numpy小小结
| 切片和索引 | |
|---|---|
| 选择行 | t[2] |
| t[3:,:] | |
| 选择列 | t[:,4:] |
| 选择行列 | 连续的多行 t[2:,:3] |
| 不连续的t[[1,3],[2,4]]选择的是(1,2),(3,4)两个位置的值 | |
| 索引 | t[2,3] |
| 赋值 | t[2:,3]=3 |
| 布尔索引 | t[t>10]=10 |
| 三元运算符 | np.where(t>10,20,0) |
| 把t中大于10的替换为20,其他的替换为0 | |
| 裁剪 | t.clip(10,20) |
| 把小于10的替换为10,大于20的替换为20 | |
| 转置 | t.T |
| t.transpose() | |
| t.swapaxes(1,0) | |
| 读取本地文件 | np.loadtxt(file,path,delimiter,dtype) |
| nan和inf | |
| inf | 表示无穷 |
| nan | 不是一个数字 |
| np.nan != np.nan | |
| np.count_nonzero(np.nan != np.nan) | |
| np.isnan(t1)效果和np.nan != np.nan相同 |
数组的拼接
import numpy as np
t1 = np.arange(0, 12).reshape(2, 6)
t2 = np.arange(12, 24).reshape(2, 6)
#竖直拼接
t = np.vstack((t1, t2))
print('竖直拼接\n',t)
#水平拼接
t=np.hstack((t1,t2))
print('水平拼接\n',t)
运行结果:
竖直拼接
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
水平拼接
[[ 0 1 2 3 4 5 12 13 14 15 16 17]
[ 6 7 8 9 10 11 18 19 20 21 22 23]]
数组的行列交换
import numpy as np
# 数组的行列交换
t = np.arange(12, 24).reshape(3, 4)
print(t)
print('行交换')
t[[1, 2], :] = t[[2, 1], :]
print(t)
print('列交换')
t[:, [0, 2]] = t[:, [2, 0]]
print(t)
运行结果:
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]
行交换
[[12 13 14 15]
[20 21 22 23]
[16 17 18 19]]
列交换
[[14 13 12 15]
[22 21 20 23]
[18 17 16 19]]
numpy一些好用的方法
- 获取最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t,axis=1)
- 创建一个全0的数组
np.zeros((3,4))
- 创建一个全1的数组
np.ones((3,4))
- 创建一个对角线为1的正方形数组(矩阵)
np.eye(3)
numpy生成随机数
| 参数 | 解释 |
|---|---|
| .rand(d0,d1,…,dn) | 创建d0-dn维度的均匀分布的随机数数组,浮点数,范围从0-1 |
| .randn(d0,d1,…,dn) | 创建d0-dn维度的标准正态分布的随机数,浮点数,平均数0,标准差1 |
| .randint(low,high,(shape)) | 从给定上下范围选取随机数整数,范围是low,high,形状是shape |
| .uniform(low,high,(size)) | 产生具有均匀分布的数组,low起始值,high结束值,size形状 |
| .normal(loc,scale,(size)) | 从指定正态分布中随机抽取样本,分布中心是loc(概率分布的均值),标准差是scale,形状是size |
| .seed(s) | 随机数种子,s是给定的种子值。因为计算生成的是伪随机数,所以通过设定相同的随机数种子,可以每次生成相同的随机数 |
pandas
为什么学习pandas
numpy能够处理数据,可以结合matplotlib解决数据分析的问题,那么学习pandas的目的是?
numpy能够帮助我们处理数值型数据,但很多时候,数据除了数值之外,还有字符串,时间序列等。
numpy能够处理数值,但是pandas除了处理数值之外的(基于numpy),还能处理其它类型的数据
pandas的常用数据类型
- Series 一维,带标签数组
- DataFrame 二维,Series容器
pandas之Series创建
代码演示
import pandas as pd
#通过列表或可迭代对象创建Series
t = pd.Series([1, 23, 22, 2, 0], index=list('abcde'))
print(t)
# 通过字典创建Series,索引就是字典的键
print('\n通过字典创建:')
temp_dict = {'name': '张三', 'gender': '男', 'age': 15}
t3 = pd.Series(temp_dict)
print(t3)
print('Series切片和索引')
#切片:直接传入start end 或者步长即可
#索引:一个的时候直接传入序号或者index,多个的时候传入序号或index的列表
print("t3['name']:",t3['name'])
print("t3['gender']:",t3['gender'])
print("t3['age']: ",t3['age'])
print("t3[0]: ",t3[0])
print("t3[1]: ",t3[1])
print("t3[2]: ",t3[2])
print('取前两行\n',t3[:2])
print('取不连续的\n',t3[[1,2]])
print('取不连续的\n',t3[['gender','age']])
#Series对象本质由两个数组构成
#一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键->值
print(t3.index,'---',type(t3.index))
print(t3.values,'---',type(t3.values))
# ndarray的很多方法都可以运用于series类型,比如argmax,clip
#Series具有where方法,但结果和ndarray不同
运行结果:
a 1
b 23
c 22
d 2
e 0
dtype: int64
通过字典创建:
name 张三
gender 男
age 15
dtype: object
Series切片和索引
t3['name']: 张三
t3['gender']: 男
t3['age']: 15
t3[0]: 张三
t3[1]: 男
t3[2]: 15
取前两行
name 张三
gender 男
dtype: object
取不连续的
gender 男
age 15
dtype: object
取不连续的
gender 男
age 15
dtype: object
Index(['name', 'gender', 'age'], dtype='object') --- <class 'pandas.core.indexes.base.Index'>
['张三' '男' 15] --- <class 'numpy.ndarray'>
pandas之读取外部数据
数据存储在csv中,直接使用pd.read_csv即可
pd.read_sql(sql_sentence,connection)读取数据库数据
pandas之DataFrame
DataFrame对象既有行索引,又有列索引
行索引:表明不同行,横向索引,叫index,0轴,axis=0
列索引:表明不同列,纵向索引,叫columns,1轴,axis=1
代码演示:
import pandas as pd
import numpy as np
t = pd.DataFrame(np.arange(12).reshape(3,4))
print(t)
print('-'*30)
t1 = pd.DataFrame(np.arange(12).reshape(3,4),index=list('abc'),columns=list("WXYZ"))
print(t1)
运行结果:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
------------------------------
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
DataFrame的基本属性
| df.shape | 行数、列数 |
|---|---|
| df.dtypes | 列数据类型 |
| df.ndim | 数据维度 |
| df.index | 行索引 |
| df.columns | 列索引 |
| df.values | 对象值,二维ndarray数组 |
DataFrame整体情况查询
| df.head(3) | 显示头部几行,默认5行 |
|---|---|
| df.tail(3) | 显示末尾几行,默认5行 |
| df.info() | 相关信息概览:行数、列数、列索引、列非空值个数、列类型、内存占用 |
| df.describe() | 快速综合统计结果:计数、均值、标准差、最大值、四分位数、最小值 |
| df.sort_values(by=‘XX’,ascending=False) |
DataFrame的索引
pandas取行和列的注意点
方括号写数,表示取行,对行进行操作df[:20]
写字符串,表示取列索引,具体要选择某一列对列进行操作df['列索引']
若同时选择行和列,df[:100]['列索引']
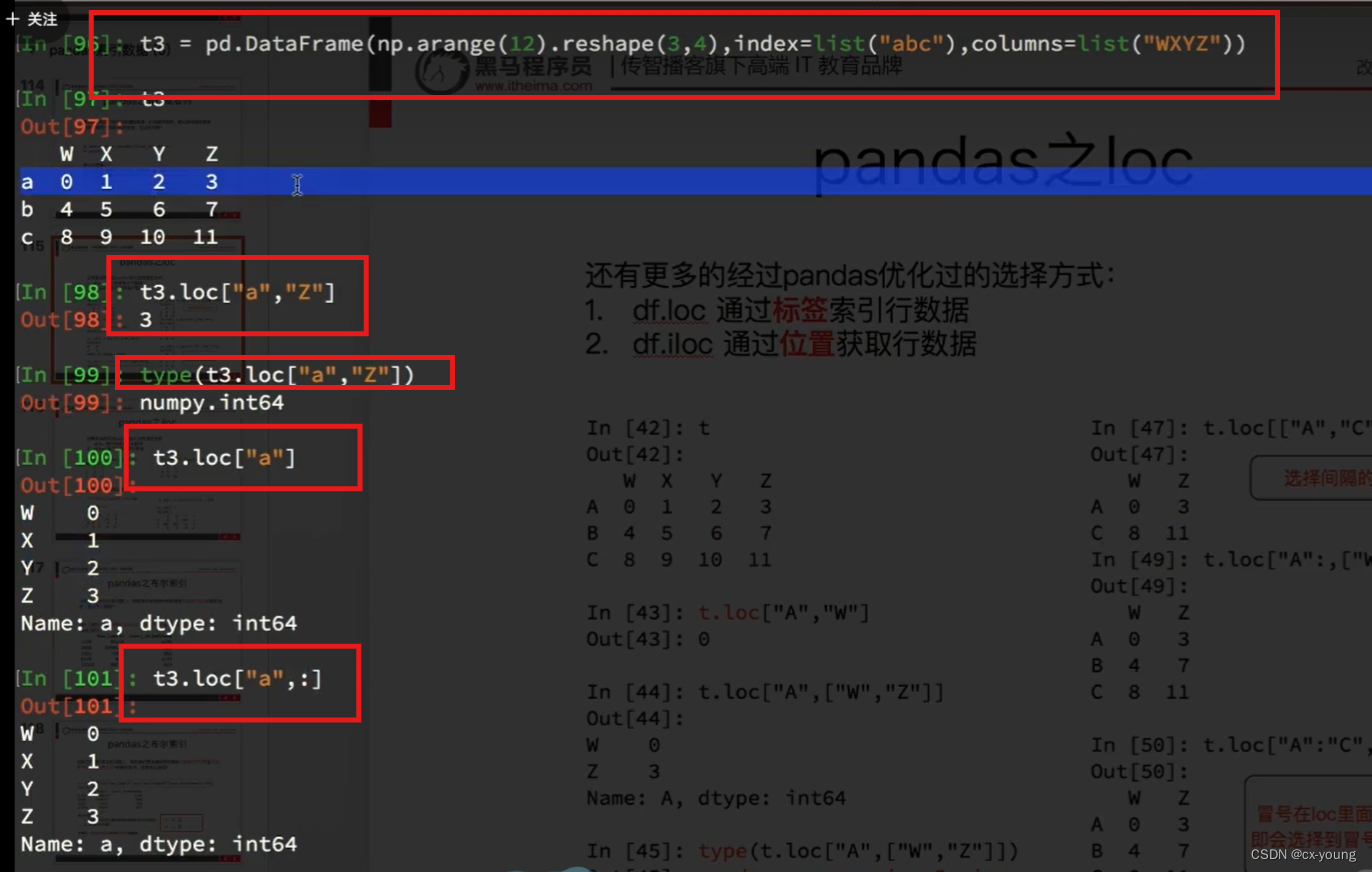
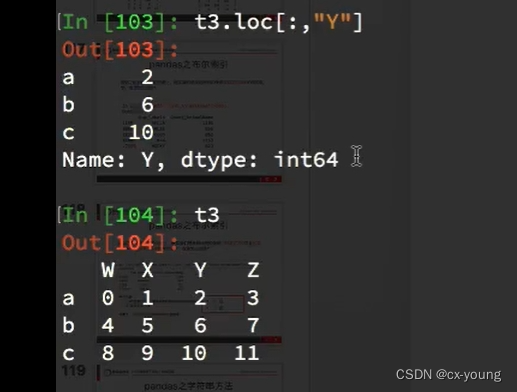
pandas之Ioc
- df.loc通过标签索引行数据
- df.iloc通过位置获取行数据


以上学习内容来自B站