深度学习-第T9周——猫狗识别
- 深度学习-第T9周——猫狗识别
- 一、前言
- 二、我的环境
- 三、前期工作
- 1、导入数据集
- 2、查看图片数目
- 四、数据预处理
- 1、 加载数据
- 1.1、设置图片格式
- 1.2、划分训练集
- 1.3、划分验证集
- 1.4、查看标签
- 1.5、再次检查数据
- 1.6、配置数据集
- 2、数据可视化
- 五、搭建VGG网络
- 六、编译
- 七、训练模型
- 八、模型评估
- 1、Loss和Acc图
- 2、指定图片进行预测
- 九、总结
- 1、train_on_batch的概念及其使用方法
- 2、tqdm的概念以及使用方法
- 3、T9的总结
深度学习-第T9周——猫狗识别
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.5
- 编译器:colab在线编译
- 深度学习环境:Tensorflow
三、前期工作
1、导入数据集
导入数据集,这里使用k同学的数据集,共2个分类。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os, PIL, pathlib
#1、载入数据
data_dir = ("D:/DL_Camp/CNN/T8/365-7-data")
data_dir = pathlib.Path(data_dir)
这段代码将字符串类型的 data_dir 转换为了 pathlib.Path 类型的对象。pathlib 是 Python3.4 中新增的模块,用于处理文件路径。
通过 Path 对象,可以方便地操作文件和目录,如创建、删除、移动、复制等。
在这里,我们使用 pathlib.Path() 函数将 data_dir 转换为路径对象,这样可以更加方便地进行文件路径的操作和读写等操作。
2、查看图片数目
image_mount = len(list(data_dir.glob("*/*.jpg")))
print(image_mount)
获取指定目录下所有子文件夹中 jpg 格式的文件数量,并将其存储在变量 image_count 中。
data_dir 是一个路径变量,表示需要计算的目标文件夹的路径。
glob() 方法可以返回匹配指定模式(通配符)的文件列表,该方法的参数 “/.jpg” 表示匹配所有子文件夹下以 .jpg 结尾的文件。
list() 方法将 glob() 方法返回的生成器转换为列表,方便进行数量统计。最后,len() 方法计算列表中元素的数量,就得到了指定目录下 jpg 格式文件的总数。
所以,这行代码的作用就是计算指定目录下 jpg 格式文件的数量。

四、数据预处理
1、 加载数据
1.1、设置图片格式
batch_size = 64
img_height = 224
img_width = 224
1.2、划分训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.2,
subset = 'training',
seed = 12,
image_size = (img_height, img_width),
batch_size = batch_size
)
这行代码使用 TensorFlow 读取指定路径下的图片文件,并生成一个 tf.data.Dataset 对象,用于模型的训练和评估。
具体来说,tf.keras.preprocessing.image_dataset_from_directory() 函数从指定目录中读取图像数据,并自动对其进行标准化和预处理。该函数有以下参数:
data_dir: 字符串,指定要读取的图片文件夹路径。
validation_split: 浮点数,指定验证集所占的比例。默认值为 0.2。
subset: 字符串,表示要读取哪个子集的数据。默认为 “training”,即读取训练集数据。
seed: 整型,用于设置随机种子以生成可重复的随机数,默认为 None。
image_size: 元组,表示所有图像的期望尺寸。例如 (150, 150) 表示将所有图像调整为 150x150 大小。
batch_size: 整型,表示每个批次的样本数。
通过这些参数,函数将指定目录中的图像按照指定大小预处理后,随机划分为训练集和验证集。最终,生成的 tf.data.Dataset 对象包含了划分好的数据集,可以用于后续的模型训练和验证。
需要注意的是,这里的 img_height 和 img_width 变量应该提前定义,并且应该与实际图像的尺寸相对应。同时,batch_size 也应该根据硬件设备的性能合理调整,以充分利用 GPU/CPU 的计算资源。

1.3、划分验证集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.2,
subset = "validation",
seed = 12,
image_size = (img_height, img_width),
batch_size = batch_size
)
这段代码和上一段代码类似,使用 TensorFlow 的 keras.preprocessing.image_dataset_from_directory() 函数从指定的目录中读取图像数据集,并将其划分为训练集和验证集。
其中,data_dir 指定数据集目录的路径,validation_split 表示从数据集中划分出多少比例的数据作为验证集,subset 参数指定为 “validation” 则表示从数据集的 20% 中选择作为验证集,其余 80% 作为训练集。seed 是一个随机种子,用于生成可重复的随机数。image_size 参数指定输出图像的大小,batch_size 表示每批次加载的图像数量。
该函数返回一个 tf.data.Dataset 对象,代表了整个数据集(包含训练集和验证集)。可以使用 train_ds 和 val_ds 两个对象分别表示训练集和验证集。
不过两段代码的 subset 参数值不同,一个是 “training”,一个是 “validation”。
因此,在含有交叉验证或者验证集的深度学习训练过程中,需要定义两个数据集对象 train_ds 和 val_ds。我们已经定义了包含训练集和验证集的数据集对象 train_ds,可以省略这段代码,无需重复定义 val_ds 对象。只要确保最终的训练过程中,两个数据集对象都能够被正确地使用即可。
如果你没有定义 val_ds 对象,可以使用这段代码来创建一个验证数据集对象,用于模型训练和评估,从而提高模型性能。

1.4、查看标签
class_names = train_ds.class_names
class_names
train_ds.class_names 是一个属性,它是通过数据集对象 train_ds 中的类别信息自动生成的一个包含类别名称的列表。
在创建数据集对象 train_ds 时,你可以通过 class_names 参数手动指定类别名称,也可以根据图像文件夹的目录结构自动推断出来。
例如,假设你有一个包含猫和狗两种类别的图像数据集,其中猫类别的图像存储在 “cat” 文件夹中,狗类别的图像存储在 “dog” 文件夹中,
那么当你使用 keras.preprocessing.image_dataset_from_directory() 函数加载数据集时,会自动将 “cat” 和 “dog” 文件夹作为两个不同的类别,
并将它们的名称存储在 train_ds.class_names 属性中。
执行该代码后,你就可以在控制台或者输出窗口中看到包含数据集中所有类别名称的列表。这些名称通常是按照字母顺序排列的
因此,train_ds.class_names 属性可以让你方便地查看数据集中所有的类别名称,以便后续的模型训练、预测和评估等任务。
如果你要对数据集进行多类别分类,则需要根据 train_ds.class_names 的元素个数设置输出层的神经元数量,并将每个类别与一个唯一的整数标签相关联。

1.5、再次检查数据
for images_batch, labels_batch in train_ds.take(1):
print(images_batch.shape)
print(labels_batch.shape)
break

image_batch 是张量的形状(64, 224, 224,3)。这是一批形状2242243的8张图片,最后一维指的是彩色通道RGB
label_batch是形状为(64,)的张量,这些标签对应64张图片
1.6、配置数据集
AUTOTUNE = tf.data.AUTOTUNE
"""
定义 AUTOTUNE 常量
这个常量的作用是指定 TensorFlow 数据管道读取数据时使用的线程个数,使得数据读取可以尽可能地并行化,提升数据读取效率。
具体来说,AUTOTUNE 的取值会根据系统资源和硬件配置等因素自动调节。"""
def preprocess_image(image, label):
return (image / 255.0, label)
"""这个函数的作用是对输入的图像数据进行预处理操作,其中 image 表示输入的原始图像数据,label 表示对应的标签信息。
函数体内的操作是把原始图像数据除以 255,使其数值归一化到 0 和 1 之间。
函数返回一个元组 (image / 255.0, label),其中第一个元素是经过处理后的图像数据,第二个元素是对应的标签信息。
"""
#归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls = AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls = AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size = AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size = AUTOTUNE)
"""
通过 map 方法对数据集中的每个元素应用 preprocess_image 函数进行预处理。
num_parallel_calls 参数指定了并行处理的个数,这里设为 AUTOTUNE,表示自动选择最优的并行个数。
接着,对经过预处理后的数据集,通过 cache 方法将其缓存到内存中,以提高读取效率。
然后,再利用 shuffle 方法和 prefetch 方法对训练数据集进行混洗和数据预取,增强训练稳定性和效率。
而验证数据集只需要进行缓存和数据预取操作即可。
"""
在 TensorFlow 中,map 是一种对数据集中的每个元素应用一个函数的方法,常用于数据预处理和数据增强等任务。其使用方式为:
dataset = dataset.map(map_func, num_parallel_calls=None)
其中,dataset 表示待处理的数据集对象,map_func 表示要应用的函数,num_parallel_calls 表示并行执行 map_func 的线程数。
具体来说,map_func 函数会被应用到数据集中的每个元素上,函数接受一个或多个张量作为输入,输出也可以是一个或多个张量。map_func 的定义方式应当符合 TensorFlow 的计算图模型,即是一组 TensorFlow 的计算操作(ops)。
使用 map 方法可以方便地对数据集进行预处理,例如图像数据的归一化、尺寸调整、数据增强等。同时,由于 map 方法本身支持并行处理,因此可以大大加速数据处理的速度。
在使用 map 方法时,应尽可能指定 num_parallel_calls 参数以充分利用计算资源,提高处理效率。
2、数据可视化
plt.figure(figsize = (15, 13))
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[labels[i]])
plt.axis("off")
train_ds.take(1) 是一个方法调用,它返回一个数据集对象 train_ds 中的子集,其中包含了 take() 方法参数指定的数量的样本。
在这个例子中,take(1) 意味着我们从 train_ds 数据集中获取一批包含一个样本的数据块。
因此,for images, labels in train_ds.take(1): 的作用是遍历这个包含一个样本的数据块,并将其中的图像张量和标签张量依次赋值给变量 images 和 labels。具体来说,
它的执行过程如下:
从 train_ds 数据集中获取一批大小为 1 的数据块。
遍历这个数据块,每次获取一个图像张量和一个标签张量。
将当前图像张量赋值给变量 images,将当前标签张量赋值给变量 labels。
执行 for 循环中的代码块,即对当前图像张量和标签张量进行处理。
plt.imshow() 函数是 Matplotlib 库中用于显示图像的函数,它接受一个数组或张量作为输入,并在窗口中显示对应的图像。
在这个代码中,images[i] 表示从训练集中获取的第 i 个图像张量。由于 images 是一个包含多个图像的张量列表,因此使用 images[i] 可以获取其中的一个图像。
plt.axis(“off”) 是 Matplotlib 库中的一个函数调用,它用于控制图像显示时的坐标轴是否可见。
具体来说,当参数为 “off” 时,图像的坐标轴会被关闭,不会显示在图像周围。这个函数通常在 plt.imshow() 函数之后调用,以便在显示图像时去掉多余的细节信息,仅仅显示图像本身。

五、搭建VGG网络
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape = input_shape)
# 1st block
x = Conv2D(64, (3, 3), activation = 'relu', padding = 'same', name = 'block1_conv1')(input_tensor)
x = Conv2D(64, (3, 3), activation = 'relu', padding = 'same', name = 'block1_conv2')(x)
x = MaxPooling2D((2, 2), strides = (2, 2), name = 'block1_pool')(x)
#2nd block
x = Conv2D(128, (3, 3), activation = 'relu', padding = 'same', name = 'block2_conv1')(x)
x = Conv2D(128, (3, 3), activation = 'relu', padding = 'same', name = 'block2_conv2')(x)
x = MaxPooling2D((2, 2), strides = (2, 2), name = 'block2_pool')(x)
#3rd block
x = Conv2D(256, (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv1')(x)
x = Conv2D(256, (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv2')(x)
x = Conv2D(256, (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv3')(x)
x = MaxPooling2D((2, 2), strides = (2, 2), name = 'block3_pool')(x)
#4th block
x = Conv2D(512, (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv1')(x)
x = Conv2D(512, (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv2')(x)
x = Conv2D(512, (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv3')(x)
x = MaxPooling2D((2, 2), strides = (2, 2), name = 'block4_pool')(x)
#5th block
x = Conv2D(512, (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv1')(x)
x = Conv2D(512, (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv2')(x)
x = Conv2D(512, (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv3')(x)
x = MaxPooling2D((2, 2), strides = (2, 2), name = 'block5_pool')(x)
#full layers
x = Flatten()(x)
x = Dense(4096, activation = 'relu', name = 'fc1')(x)
x = Dense(4096, activation = 'relu', name = 'fc2')(x)
output_tensor = Dense(nb_classes, activation = 'softmax', name = 'predictions')(x)
model = Model(input_tensor, output_tensor)
return model
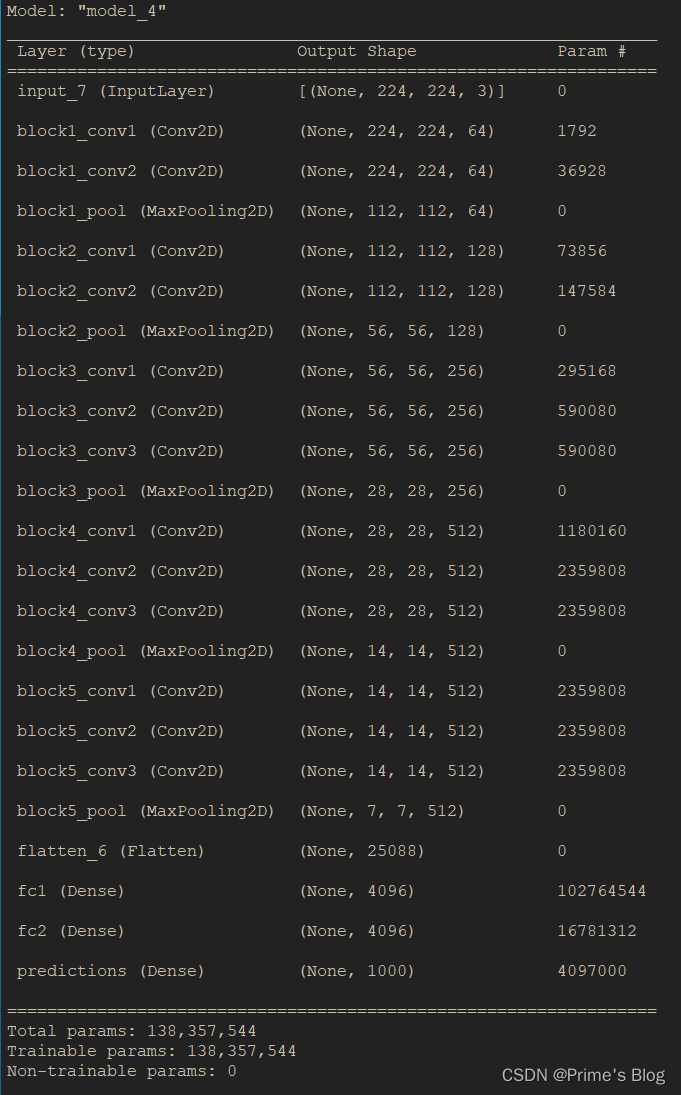
model = VGG16(1000, (img_width, img_height, 3))
model.summary()
函数 VGG16(nb_classes, input_shape) 接受两个参数,分别为 nb_classes 表示图像分类问题的类别数目,和 input_shape 表示输入图像的尺寸和通道数。在该函数中,首先通过 Input() 函数定义了一个输入张量 input_tensor,其形状为 (input_shape)。然后按照 VGG-16 的结构依次添加了 5 个卷积块(每个块包括两个卷积层和一个池化层),以及 2 个全连接层,最后输出了一个含有 nb_classes 个元素的 softmax 输出层 output_tensor。其中,卷积层的特征图大小和卷积核大小均为 3x3,除最后一层卷积层外,所有卷积层后面都接了一个 2x2 的最大池化层,以降低特征图的空间尺寸。全连接层的神经元数分别为 4096 个,采用了 ReLU 激活函数。最后使用 Model() 函数将输入、输出张量打包成一个 Keras 模型对象,并返回该对象。
六、编译
model.compile(
optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy']
)
Sparse_Categorical_Crossentropy 是一种常用的损失函数,通常用于多分类问题。
它的输入是模型输出结果经过 softmax 处理后得到的概率分布和真实的分类标签,输出是一个标量值,表示模型在当前数据上的损失值。
其中 from_logits=True 表示输入的模型输出结果是没有进行 softmax 处理的 logits,这种设置可以提高计算效率,并且对于梯度计算也更加稳定。
SparseCategoricalCrossentropy 的计算公式为:
loss = -Σ[y * log(y_hat)]
其中 y 是真实的分类标签,y_hat 是模型在该分类下的预测概率分布,log 是自然对数。通过最小化损失函数,模型可以调整参数以提高预测准确率,并不断逼近真实结果
七、训练模型
#5、训练
from tqdm import tqdm
import tensorflow.keras.backend as K
epochs = 10
lr = 1e-4
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):
train_total = len(train_ds)
val_total = len(val_ds)
#
#total:预期的迭代数目
#ncols:控制进度条宽度
#mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)
#
with tqdm(total = train_total, desc = f'Epoch {epoch + 1} / {epochs}', mininterval=1, ncols = 100) as pbar:
lr = lr * 0.92
K.set_value(model.optimizer.lr, lr)
#与T8不同的地方
train_loss = []
train_accuracy = []
for image, label in train_ds:
history = model.train_on_batch(image, label)
#与T8不同的地方
train_loss.append(history[0])
train_accuracy.append(history[1])
pbar.set_postfix({"train_loss":"%.4f" % history[0],
"train_accuracy": "%.4f" % history[1],
"lr" : K.get_value(model.optimizer.lr)
})
pbar.update(1)
#与T8不同的地方
history_train_loss.append(np.mean(train_loss))
history_train_accuracy.append(np.mean(train_accuracy))
print('开始验证!')
with tqdm(total = val_total, desc = f'Epoch {epoch + 1} / {epochs}', mininterval=0.3, ncols = 100) as pbar:
val_loss = []
val_accuracy = []
for image, label in val_ds:
history = model.test_on_batch(image, label)
val_loss.append(history[0])
val_accuracy .append (history[1])
pbar.set_postfix({"val_loss":"%.4f" % history[0],
"val_accuracy": "%.4f" % history[1],
})
pbar.update(1)
history_val_loss.append(np.mean(val_loss))
history_val_accuracy.append(np.mean(val_accuracy))
print('结束验证!')
print("验证Loss为: %.4f" % np.mean(val_loss))
print("验证准确率为: % .4f" % np.mean(val_accuracy))
"""
history = model.fit(
train_ds,
validation_data = val_ds,
epochs = epochs
)
"""

八、模型评估
1、Loss和Acc图
#6、模型评估
epochs_range = range(epochs)
plt.figure(figsize = (12, 4))
plt.subplot(1, 2, 1 )
plt.plot(epochs_range, history_train_accuracy, label = 'Training Accuracy')
plt.plot(epochs_range, history_val_accuracy, label = 'Validation Accuracy')
plt.legend(loc = 'lower right')
plt.title('Training And Validation Accuracy')
plt.subplot(1, 2, 2 )
plt.plot(epochs_range, history_train_loss, label = 'Training Loss')
plt.plot(epochs_range, history_val_loss, label = 'Validation Loss')
plt.legend(loc = 'upper right')
plt.title('Training And Validation Loss')
plt.show()

2、指定图片进行预测
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize = (18, 3))
plt.subtitle("预测结果显示")
for images, labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
#显示图片
ax.imshow(images[i].numpy())
#需要给图片增加一个维度
img_array = tf.expand_dims(images[i], 0)
#使用模型预测图片中的人物
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")

九、总结
1、train_on_batch的概念及其使用方法
model.train_on_batch(x, y) 是 Keras 模型对象的一个方法,用于训练模型的一个批次数据(batch)。该方法的输入参数 x 和 y 分别表示输入样本数据和对应的真实标签数据。在训练过程中,模型会根据输入数据与真实标签数据的差异(即损失函数)来调整模型参数,以达到更好的预测效果。
train_on_batch() 方法会执行以下操作:
- 将输入数据 x 和对应的真实标签数据 y 喂入模型;
- 根据当前模型参数计算输出结果,计算损失函数并更新梯度;
- 根据梯度更新模型参数;
- 返回本批次数据的平均损失值。
在使用 train_on_batch() 方法前,需要先编译模型,并指定优化器(如 Adam、SGD 等)和损失函数(如交叉熵、均方误差等)
使用 train_on_batch() 方法时,通常的调用方式是批量读取训练数据,然后循环调用该方法对每个批次数据进行训练
test_on_batch(x, y) 方法则是用于在测试集上评估模型的性能,与 train_on_batch() 方法类似,该方法将输入数据 x 和对应的真实标签数据 y 喂入模型,但不会更新模型参数。而是计算模型在该批次数据上的预测输出以及相应的损失函数值,并返回本批次数据的平均损失值。通常在整个测试集上执行多次 test_on_batch() 方法,以获得模型在测试集上的总体性能指标。
2、tqdm的概念以及使用方法
tqdm 是一个 Python 的进度条库,可以在终端或 Jupyter notebook 中以可视化方式展示代码运行的进度情况。它能够自动计算迭代对象的长度,并显示当前迭代的进度、剩余时间等信息,可以方便地监控长时间运行的代码进度,提高编程效率。
如:
from tqdm import tqdm
import time
for i in tqdm(range(10)):
time.sleep(1)
以下是tqdm示例的输出结果, 10/10 表示当前迭代到了第 10 个元素,总共有 10 个元素需要迭代;[00:10<00:00, 1.00s/it] 表示已经用时 10 秒,剩余时间为 0 秒,每次迭代需要 1 秒。这样,我们就能够清晰地了解程序的运行进展,避免反复手动查看日志或打印语句,提高开发效率。
tqdm 还支持多种进度条样式、自定义单位、动态更新等高级功能。

3、T9的总结
修改了T8中出现的bug,T8的代码里每轮训练后,loss和accuracy的值都会被重置,即将history的值赋给了loss和accuracy,这样会导致每轮记录的结果都相同。而在T9中,通过将每轮的loss和accuracy记录到一个列表中(loss.append(history)),实现了历史记录的保存,避免了上述的bug。因此,在T9中每轮训练后,可以通过查看loss和accuracy列表的最后一个元素来获取该轮的训练结果。本次代码使用的是loss和accuracy的平均值。