1. 链表的概念
1.1. 链表的结构
在计算机里,不保存在连续存储空间中,而每一个元素里都保存了到下一个元素的地址的数据结构,我们称之为链表(Linked List)。链表上的每一个元素又可以称它为节点(Node),而链表中第一个元素,称它为头节点(Head Node),最后一个元素称它为尾节点(Tail Node)。
链表的结构定义中,包含了两个信息,一个是数据信息,用来存储数据的,也叫做数据域;另外一个是地址信息,用来存储下一个节点地址的,也叫做指针域。
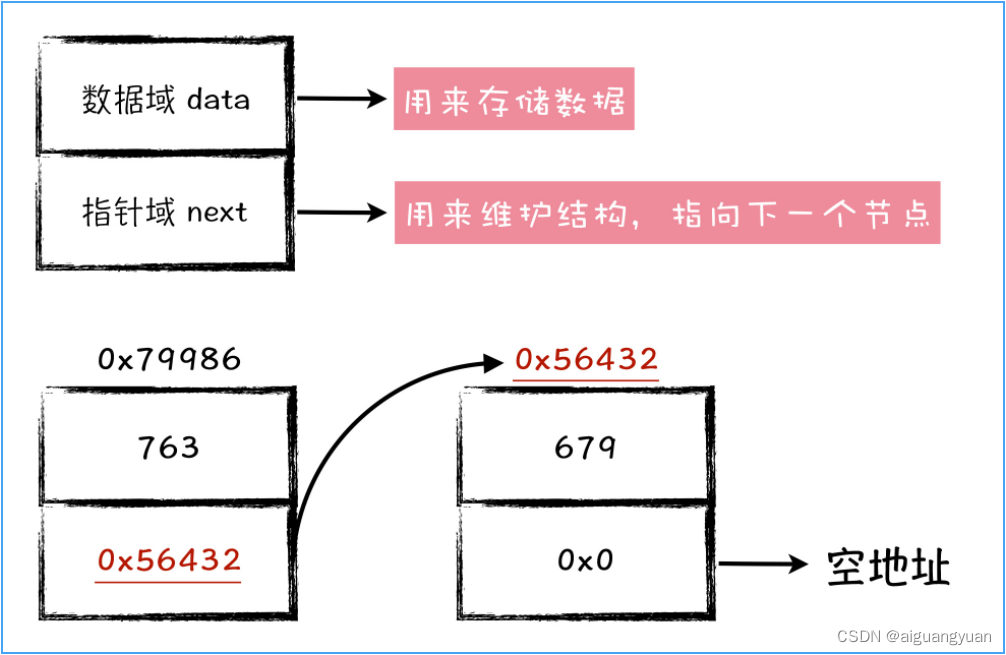
可以看到,链表节点以整型作为数据域的类型,其中第一个链表节点,存储了 763 这个数据,指针域中呢,存储了一个 0x56432 地址,这个地址而 0x56432 正是第二个链表节点的地址。这样,第一个节点指向第二个节点,因此这两个节点之间,在逻辑上构成了一个指向关系。
在第二个节点的指针域中呢,存储了一个地址,是 0x0,这个地址值所对应就是 0。这是一个特殊的地址,我们称它为空地址,用 NULL 表示这个空地址。第二个链表节点指向空地址,就意味着它就是这个链表结构的最后一个节点。
在JavaScript中,链表的定义中包含两个属性,val 用来保存节点上的数据,next用来保存指向下一个节点的链接。使用一个构造函数来创建节点,在构造函数设置了这两个属性的值:
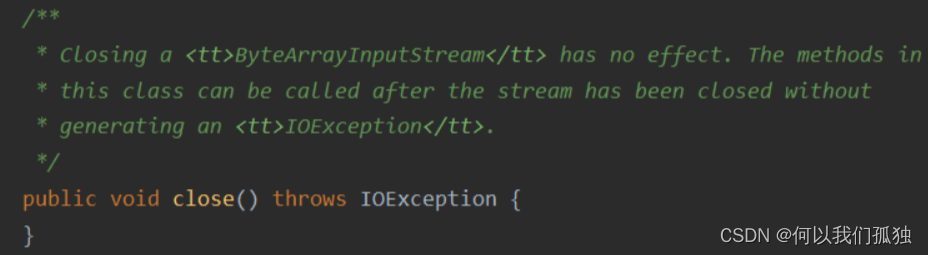
function ListNode(val) {
this.val = val;
this.next = null;
}注意,链表结构的指针域只有一个 next 变量,这说明每一个链表节点,只能唯一地指向后续的一个节点。在JavaScript中是没有指针的概念的,所以我们可以理解这个指针是一个地址的引用。
1.2. 链表与数组对比
其实,链表结构和数组结构很类似,只不过数组结构在内存中存储是连续的,链表结构由于有指针域的存在,它的每一个节点在内存中存储的位置未必连续。下面来对比一下两者的性能。
1.2.1. 空间利用率
数组在创建之后大小是无法改变的,想要增加元素的话就必须重新创建一个新的数组。所,以有时为了能够动态地增加元素,在开始创建数组时会声明一个比需要的大小还多的空间出来,以便后面添加新的元素。这个时候就会造成空间上的浪费,所以,数组的空间利用率相当于本来需要的大小除以创建出来数组的大小。
而因为链表中的元素只有当需要的时候才会被创建出来,所以不存在需要多预留空间的情况。对于我们来说,只有节点里的值是可以利用上的,而保存节点地址的内存其实对于我们来说是无法应用的。所以链表的空间利用率上相当于值的大小除以值的大小和节点地址大小的和。
1.2.2. 时间复杂度
访问数组元素的时间复杂度是 O(1)。而因为链表顺序访问的这个特性,访问链表中第 N 个元素需要从第一个元素一直遍历到第 N 个元素,所以平均下来的时间复杂度是 O(N)。
对于数组来说,插入操作无论是发生在数组结尾还是发生在数组的中间,因为都需要重新创建一个新的数组出来,并复制一遍之前的元素到新的数组中,所以平均的时间复杂度都是 O(N)。而对于链表来说,要是一直都能维护一个尾节点的地址的话,那么插入一个新的元素只需要 O(1) 的时间复杂度。而当插入一个元素到链表中间的时候,因为链表顺序访问的这个特性,需要先遍历一遍链表,从第一个节点开始直到第 N 个位置,然后再进行插入,所以平均下来的时间复杂度是 O(N)。
1.3. 链表的形式
1.3.1. 单向链表
所有的链表节点中都只保存了指向下一个节点地址的信息。这种在一个节点中既保存了数据,也保存了指向下一个节点地址信息的链表,称之为单向链表(Singly Linked List)。如下图所示:

1.3.2. 双向链表
单向链表有着只能朝着一个方向遍历的局限性,既然可以保存指向下一个节点地址的信息,也可以保存指向上一个节点地址的信息。这种在一个节点中保存了数据也保存了连向下一个和上一个节点地址信息的链表,称之为双向链表(Doubly Linked List)。和链表中尾节点的下一个节点只保存空地址一样,链表中头节点的上一个节点地址也保存着空地址,如下图所示:

1.3.3. 循环链表
无论是单向链表或者是双向链表,当遍历至尾节点之后就无法再遍历下去了,如果将尾节点指向下一个节点地址的信息更新成指向头节点的话,这样整个链表就形成了一个环,这种链表称之为循环链表(Circular Linked List)。如下图所示:

2. 链表的操作
在实现链表时候,通常在链表前面加一个假头,所谓假头,通常也叫作 Dummy Head 或者“哑头”。实际上,就是在链表前面,加上一个额外的结点。此时,存放了 N 个数据的带假头的链表,算上假头一共有 N+1 个结点。
那额外的结点不会存放有意义的数据。那么它的作用是什么呢?
其实,添加假头后,可以省略掉很多空指针的判断,链表的各种操作会变得更加简洁。关于链表的各种操作,主要是以下 6 种基本操作:
1. 链表初始化;
2. 尾部追加结点;
3. 头部插入结点;
4. 查找结点;
5. 插入指定位置之前;
6. 删除结点;
下面以 LeetCode 的707题《设计链表》为例,来实现一下单链表,题目要求将这 6 种基本的操作加以实现:注释中的 /code here/ 部分是填写相应的 6 种功能代码:
var MyLinkedList = function () {
/* code here: 初始化链表 */
};
MyLinkedList.prototype.addAtTail = function (val) {
/* code here: 将值为 val 的结点追加到链表尾部 */
};
MyLinkedList.prototype.addAtHead = function (val) {
/* code here: 插入值val的新结点,使它成为链表的第一个结点 */
};
MyLinkedList.prototype.get = function (index) {
/* code here: 获取链表中第index个结点的值。如果索引无效,则返回-1 */
// index从0开始。
};
MyLinkedList.prototype.addAtIndex = function (index, val) {
// code here:
// 在链表中的第 index 个结点之前添加值为 val 的结点。
// 1. 如果 index 等于链表的长度,则该结点将附加到链表的末尾。
// 2. 如果 index 大于链表长度,则不会插入结点。
// 3. 如果 index 小于0,则在头节点前插入
};
MyLinkedList.prototype.deleteAtIndex = function (index) {
/* code here: 如果索引index有效,则删除链表中的第index个结点 */
2.1. 链表初始化
初始化假头链表,首先需要 new 出一个链表结点,并且让链表的 dummy 和 tail 指针都指向它,代码如下:
var listNode = function (val) {
this.val = val
this.next = null
};
var MyLinkedList = function () {
this.dummy = new listNode()
this.tail = this.dummy
this.length = 0
};初始化完成后,链表已经有了一个结点,但是此时,整个链表中还没有任何数据。因此,对于一个空链表,就是指已经初始化好的带假头链表。
虽然 head 和 tail 初始化完成之后,都指向null。但是这两者有一个特点,叫“动静结合”:
1. 静:head 指针初始化好以后,永远都是静止的,再也不会动了;
2. 动:tail 指针在链表发生变动的时候,就需要移动调整;
2.2. 尾部追加结点
尾部添加新结点操作只有两步,代码如下:
MyLinkedList.prototype.addAtTail = function (val) {
// 尾部添加一个新结点
this.tail.next = new listNode(val)
// 移动tail指针
this.tail = this.tail.next;
// 链表长度+1
this.length++
};带假头的链表初始化之后,可以保证 tail 指针永远非空,因此,也就可以直接去修改 tail.next 指针,省略掉了关于 tail 指针是否为空的判断。
2.3. 头部插入结点
需要插入的新结点为 p,插入之后,新结点 p 会成为第一个有意义的数据结点。通过以下 3 步可以完成头部插入:
1. 新结点 p.next 指向 dummy.next;
2. dummy.next 指向 p;
3. 如果原来的 tail 指向 dummy,那么将 tail 指向 p;
对应的代码如下:
MyLinkedList.prototype.addAtHead = function (val) {
// 生成一个结点,存放的值为val
const p = new listNode(val)
// 将p.next指向第一个结点
p.next = this.dummy.next;
// dummy.next指向新结点,使之变成第一个结点
this.dummy.next = p;
// 注意动静结合原则,添加结点时,注意修改tail指针。
if (this.tail == this.dummy) {
this.tail = p;
};
// 链表长度+1
this.length++
};这段代码有趣的地方在于,当链表为空的时候,它依然是可以工作的。因为虽然链表是空的,但是由于有 dummy 结点的存在,代码并不会遇到空指针。
注意: 如果链表添加了结点,或者删除了结点,一定要记得修改 tail 指针。如果忘了修改,那么就不能正确地获取链表的尾指针,从而错误地访问链表中的数据。
2.4. 查找结点
在查找索引值为 index(假设 index 从 0 开始)的结点时,你需要注意,大多数情况下,返回指定结点前面的一个结点 prev 更加有用。好处有以下两个方面:
1. 通过 prev.next 就可以访问到想要找到的结点,如果没有找到,那么 prev.next 为 null;
2. 通过 prev 可以方便完成后续操作,比如在 target 前面 insert 一个新结点,或者将 target 结点从链表中移出去;
因此,如果要实现 get 函数,应该先实现一个 getPrevNode 函数:
MyLinkedList.prototype.getPreNode = function (index) {
if (index < 0 || index >= this.length) {
return -1;
}
// 初始化front与back,分别一前一后
let front = this.dummy.next
let back = this.dummy
// 在查找的时候,front与back总是一起走
for (let i = 0; i < index && front != null; i++) {
back = front;
front = front.next;
}
// 把back做为prev并且返回
return back
};有了假头的帮助,这段查找代码就非常健壮了,可以处理以下 2 种情况:
1. 如果 target 在链表中不存在,此时 prev 返回链表的最后一个结点;
2. 如果为空链表(空链表指只有一个假头的链表),此时 prev 指向 dummy。也就是说,返回的 prev 指针总是有效的;
借助 getPrevNode 函数来实现 get 函数:
MyLinkedList.prototype.get = function (index) {
// 获取链表中第 index 个结点的值。如果索引无效,则返回-1。
// index从0开始
if (index < 0 || index >= this.length) {
return -1;
}
// 因为getPrevNode总是返回有效的结点,所以可以直接取值。
return this.getPreNode(index).next.val
};2.5. 插入指定位置之前
插入指定位置的前面,有 4 点需要注意。
1. 如果 index 大于链表长度,则不会插入结点;
2. 如果 index 等于链表的长度,则该结点将附加到链表的末尾;
3. 如果 index 小于 0,则在头部插入结点;
4. 否则在指定位置前面插入结点;
其中,Case 1~3 较容易处理。可以直接写。重点在于 Case 4。现在已经有了 getPrevNode() 函数,就可以比较容易地写出 Case 4 的代码,思路如下:
1. 使用 getPrevNode() 函数拿到 index 之前的结点 pre;
2. 在 pre 的后面添加一个新结点;
以下是具体的 Case 1~4 的操作过程:
MyLinkedList.prototype.addAtIndex = function (index, val) {
if (index > this.length) {
// Case 1 如果 index 大于链表长度,则不会插入结点。
return;
} else if (index == this.length) {
// Case 2 如果 index 等于链表的长度,则该结点将附加到链表的末尾。
this.addAtTail(val);
} else if (index <= 0) {
// Case 3 如果index小于0,则在头部插入结点。
this.addAtHead(val);
} else {
// Case 4 得到index之前的结点pre
const pre = this.getPreNode(index);
// 在pre的后面添加新结点
const p = new listNode(val);
p.next = pre.next;
pre.next = p;
// 链表长度+1
this.length++;
}
}2.6. 删除节点
删除结点操作是给定要删除的下标 index(下标从 0 开始),删除的情况分 2 种:
1. 如果 index 无效,那么什么也不做;
2. 如果 index 有效,那么将这个结点删除;
上面这 2 种情况中,Case 1 比较容易处理,相对要麻烦一些的是 Case 2。要删除 index 结点,最好是能找到它前面的结点。有了前面的结点,再删除后面的结点就容易多了。不过已经有了 getPrevNode 函数,所以操作起来还是很简单的。
以下是具体的操作过程:
MyLinkedList.prototype.deleteAtIndex = function (index) {
// Case 1 如果index无效,那么什么也不做。
if (index < 0 || index >= this.length) {
return;
}
// Case 2 删除index结点
// step 1 找到index前面的结点
const pre = this.getPreNode(index);
// step 2 如果要删除的是最后一个结点,那么需要更改tail指针
if (this.tail == pre.next) {
this.tail = pre;
}
// step 3 进行删除操作。并修改链表长度。
pre.next = pre.next.next;
this.length--;
};2.7. 总结
使用哑结点来实现链表的总代码如下:
// 节点初始化
var listNode = function (val) {
this.val = val
this.next = null
};
// 初始化链表
var MyLinkedList = function () {
this.dummy = new listNode()
this.tail = this.dummy
this.length = 0
};
// 获取上一个节点
MyLinkedList.prototype.getPreNode = function (index) {
if (index < 0 || index >= this.length) {
return -1;
}
// 初始化front与back,分别一前一后
let front = this.dummy.next
let back = this.dummy
// 在查找的时候,front与back总是一起走
for (let i = 0; i < index && front != null; i++) {
back = front;
front = front.next;
}
// 把back做为prev并且返回
return back
};
// 获取指点节点值
MyLinkedList.prototype.get = function (index) {
if (index < 0 || index >= this.length) {
return -1;
}
return this.getPreNode(index).next.val
};
// 添加节点到链表头部
MyLinkedList.prototype.addAtHead = function (val) {
// 生成一个结点,存放的值为val
const p = new listNode(val)
// 将p.next指向第一个结点
p.next = this.dummy.next;
// dummy.next指向新结点,使之变成第一个结点
this.dummy.next = p;
// 注意动静结合原则,添加结点时,注意修改tail指针。
if (this.tail == this.dummy) {
this.tail = p;
}
// 链表长度+1
this.length++
};
// 添加节点到链表尾部
MyLinkedList.prototype.addAtTail = function (val) {
// 尾部添加一个新结点
this.tail.next = new listNode(val)
// 移动tail指针
this.tail = this.tail.next;
// 链表长度+1
this.length++
};
// 添加节点到指定下标
MyLinkedList.prototype.addAtIndex = function (index, val) {
if (index > this.length) {
// Case 1 如果 index 大于链表长度,则不会插入结点。
return;
} else if (index == this.length) {
// Case 2 如果 index 等于链表的长度,则该结点将附加到链表的末尾。
this.addAtTail(val);
} else if (index <= 0) {
// Case 3 如果index小于0,则在头部插入结点。
this.addAtHead(val);
} else {
// Case 4 得到index之前的结点pre
const pre = this.getPreNode(index);
// 在pre的后面添加新结点
const p = new listNode(val);
p.next = pre.next;
pre.next = p;
// 链表长度+1
this.length++;
}
};
// 按指定下标删除节点
MyLinkedList.prototype.deleteAtIndex = function (index) {
// Case 1 如果index无效,那么什么也不做。
if (index < 0 || index >= this.length) {
return;
}
// Case 2 删除index结点
// step 1 找到index前面的结点
const pre = this.getPreNode(index);
// step 2 如果要删除的是最后一个结点,那么需要更改tail指针
if (this.tail == pre.next) {
this.tail = pre;
}
// step 3 进行删除操作。并修改链表长度。
pre.next = pre.next.next;
this.length--;
};
// 使用示例
// var obj = new MyLinkedList();
// var result = obj.get(index);
// obj.addAtHead(val);
// obj.addAtTail(val);
// obj.addAtIndex(index,val);
// obj.deleteAtIndex(index);
3. 经典题目:链表的属性
3.1. 环形链表一
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true解释:链表中有一个环,其尾部连接到第二个节点。

示例 2:
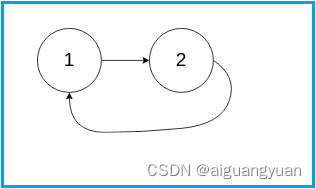
输入:head = [1,2], pos = 0
输出:true解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false解释:链表中没有环。

进阶:你能用 O(1)(即,常量)内存解决此问题吗?
我们只需要对每个遍历过的节点进行标记(因为这里每个节点都是一个对象,所以相当于遍历这个节点时,给他设置一个flag属性,如果在此遍历到的节点存在这个属性说明形成了环),后面如果再遇到它,说明有环,就直接返回true:
var hasCycle = function (head) {
while (head) {
if (head.flag) {
return true
} else {
head.flag = true
head = head.next
}
}
return false
};复杂度分析:
1. 时间复杂度:O(n),其中n是链表的节点数,最差坏的情况下我们要遍历完整个链表;
2. 空间复杂度:O(n),其中n是链表的节点数,主要为哈希表的开销,最坏情况下需要将每个节点插入到哈希表中一次;
3.2. 环形链表二
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:tail connects to node index 1
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:tail connects to node index 0
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:no cycle
解释:链表中没有环。
进阶:你是否可以不用额外空间解决此题?
和上面一题的思路一样,都是设置一个flag,只是返回值不一样,最后指向的是有flag 的节点,所以直接返回head即可。
上述方法需要开辟O(n)的储存空间来储存标记信息,那我们尝试用快慢指针来解决这个问题: 设置两个指针,快指针每次走两个节点,慢指针每次走一个节点,如果存在环,那么两个指针一定相遇。等快慢指针相遇之后,我们在用另一个指针,去寻找他们相遇的位置就可以了。
设置标识法:
// function ListNode(val) {
// this.val = val;
// this.next = null;
// }
var detectCycle = function (head) {
while (head) {
if (head.flag) {
return head
} else {
head.flag = true
head = head.next
}
}
return null
};快慢指针法:
// function ListNode(val) {
// this.val = val;
// this.next = null;
// }
var detectCycle = function(head) {
let fast = head;
let slow = head;
let cur = head;
while(fast && fast.next && fast.next.next){
slow = slow.next
fast = fast.next.next
if(fast == slow){
while(cur!=slow){
cur = cur.next
slow = slow.next
}
return slow
}
}
return null
};设置标识法复杂度分析:
1. 时间复杂度:O(n),其中n是链表的节点数,最差坏的情况下我们要遍历完整个链表;
2. 空间复杂度:O(n),其中n是链表的节点数,主要为哈希表的开销,最坏情况下需要将每个节点插入到哈希表中一次;
快慢指针法复杂度分析:
1. 时间复杂度:O(n),其中n是链表中节点数。在最初判断快慢指针是否相遇时,slow 指针走过的距离不会超过链表的总长度;随后寻找入环点时,走过的距离也不会超过链表的总长度。因此,总的执行时间为 O(N)+O(N)=O(N);
2. 空间复杂度:O(1)。我们只使用了 slow、fast、cur 三个指针;
3.3. 相交链表
编写一个程序,找到两个单链表相交的起始节点。
如下面的两个链表:
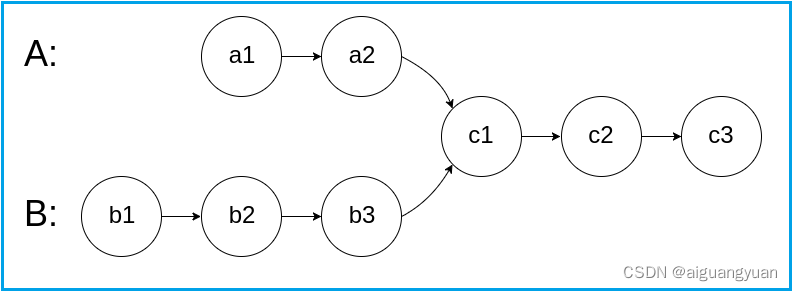
在节点 c1 开始相交。
示例 1:
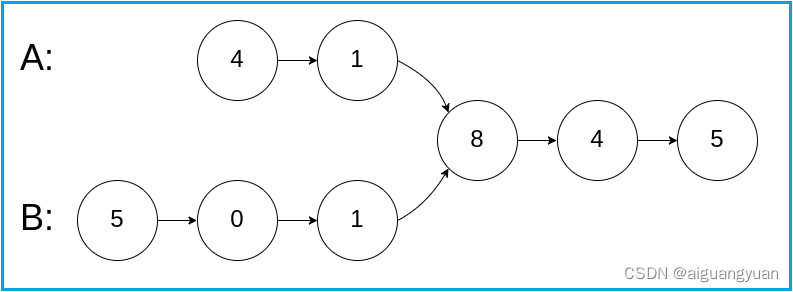
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA= 2, skipB = 3
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
输出:Reference of the node with value = 8
示例 2:

输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
解释:相交节点的值为 2(注意,如果两个链表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
输出:Reference of the node with value = 2
示例 3:
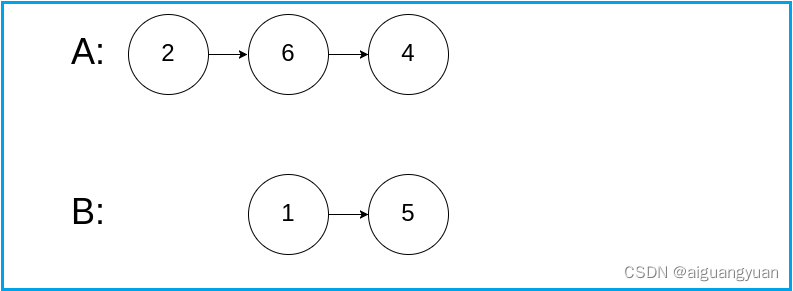
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB= 2
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。 解释:这两个链表不相交,因此返回 null
输出:null
注意:
1. 如果两个链表没有交点,返回 null;
2. 在返回结果后,两个链表仍须保持原有的结构;
3. 可假定整个链表结构中没有循环;
4. 程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存;
一个比较直接直接的方法就是用双指针来解决,思路就是将链表拼成ab和ba这样就消除了两者的高度差,如果a和b有相交的部分,那么ab和ba也一定有相交的部分。具体实现步骤如下:
1. 定义两个指针 pA 和 pB;
2. pA 从链表 a 的头部开始走,走完后再从链表 b 的头部开始走;
3. pB 从链表 b 的头部开始走,走完后再从链表 a 的头部开始走;
4. 如果存在相交的点就直接返回pA或者pB;
// function ListNode(val) {
// this.val = val;
// this.next = null;
// };
var getIntersectionNode = function (headA, headB) {
let pA = headA;
let pB = headB;
while (pA !== pB) {
pA = pA === null ? headB : pA.next;
pB = pB === null ? headA : pB.next;
};
return pA
};复杂度分析:
1. 时间复杂度:O(m + n) ,其中m和n分别是两个链表的节点数,最差情况下需要遍历完两个链表;
2. 空间复杂度:O(1),节点指针 A , B 使用常数大小的额外空间;
3.4. 链表的中间结点
给定一个头结点为 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
示例 1:
输入:[1,2,3,4,5]
输出:此列表中的中间结点为 3
解释:我们返回了一个 ListNode 类型的对象 ans,如下所示:
ans.val = 3,
ans.next.val = 4,
ans.next.next.val = 5,
ans.next.next.next = NULL.示例 2:
输入:[1,2,3,4,5,6]
输出:此列表中的结点 4
解释:由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点提示: 给定链表的结点数介于 1 和 100 之间。
对于这种求链表的中间点的题,我们可以使用快慢指针来实现,初始化slow和fast两个指针,开始时两个指针都指向头结点。然后慢指针一次走一步,快指针一次走两步,这样快指针走完整个链表时,慢指针正好走到链表的中间。
在遍历的过程中,如果快指针的后一个节点为空,就结束遍历,返回慢指针的值。
// function ListNode(val) {
// this.val = val;
// this.next = null;
// }
var middleNode = function (head) {
let fast = head, slow = head;
while (fast && fast.next) {
slow = slow.next;
fast = fast.next.next;
};
return slow;
};复杂度分析:
1. 时间复杂度:O(n),其中 n 是给定链表的结点数目;
2. 空间复杂度:O(1),只需要常数空间来存放 slow 和 fast 两个指针;
3.5. 回文链表
请判断一个链表是否为回文链表。
示例 1:
输入: 1->2
输出: false示例 2:
输入: 1->2->2->1
输出: true进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
1. 字符串拼接
对于这道题,最直接的思路就是,遍历链表,同时正向和反向拼接链表的节点,最后比较两个拼接出来的字符串是否一样。
// function ListNode(val) {
// this.val = val;
// this.next = null;
// }
var isPalindrome = function(head) {
let a = "";
let b = "";
while(head){
const nodeVal = head.val;
a = a + nodeVal;
b = nodeVal + b;
head = head.next;
};
return a === b;
};字符串拼接复杂度分析:
1. 时间复杂度:O(n),其中 n 指的是链表的元素个数,我们需要遍历完整个链表;
2. 空间复杂度:O(1),这里只需要常量的空间来保存两个拼接的字符串;
2. 递归遍历
1. 首先,定义一个全局的指针pointer,其初始值为head,用来正序遍历;
2. 然后,调用递归函数,对链表进行逆序遍历,当头部节点为null的时候停止遍历;
3. 如果正序遍历的节点值和逆序遍历的节点值都相等,就返回true,否则就返回false;
// function ListNode(val) {
// this.val = val;
// this.next = null;
// }
let pointer;
function fn(head) {
if (!head) return true;
const res = fn(head.next) && (pointer.val === head.val);
pointer = pointer.next;
return res;
}
var isPalindrome = function (head) {
pointer = head;
return fn(head)
};递归遍历复杂度分析:
1. 时间复杂度:O(n),其中 n 指的是链表的大小;
2. 空间复杂度:O(n),其中 n 指的是链表的大小,最差的情况下递归栈的深度为n;
3.6. 链表组件
3.7. 链表中倒数第k个节点
4. 经典题目:链表的操作
4.1. 两数相加(1)
4.2. 两数相加(2)
4.3. 反转链表(1)
4.4. 反转链表(2)
4.5. 旋转链表
4.6. K 个一组翻转链表
4.7. 两两交换链表中的节点
4.8. 交换链表中的节点
4.9. 分隔链表(1)
4.10. 分隔链表(2)
4.11. 重排链表
4.12. 排序链表
4.13. 移除链表元素
4.14. 删除排序链表中的重复元素(1)
4.15. 删除排序链表中的重复元素(2)
4.16. 删除链表的倒数第 N 个结点
4.17. 合并两个有序链表
4.18. 合并K个升序链表
4.19. 复制带随机指针的链表
4.20. 对链表进行插入排序
4.21. 奇偶链表