文章目录
- 一、背景
- 二、方法
- 2.1 A Unified VL Formulation and Architecture
- 2.2 GLIPv2 pre-training
- 2.3 将 GLIPv2 迁移到 Localization 和 VL task
- 三、结果
- 3.1 One model architecture for all
- 3.2 One set of model parameters for all
- 3.3 GLIPv2 as a strong few-shot learner
- 3.4 Analysis
论文:GLIPv2: Unifying Localization and Vision-Language Understanding
代码:https://github.com/microsoft/GLIP
出处:NIPS2022 | 华盛顿大学 | Meta | Microsoft | UCLA
时间:2022.10
一、背景
视觉基础模型在近来引起了人们很大的兴趣,其能够同时解决多个视觉任务,如图像分类、目标检测、图文理解等
这些任务可以统一如下:
- 定位任务:目标检测、语义分割
- Vision-Language 理解任务:图文问答、图像检索等
现在比较流行的训练方法是先训练定位任务,再训练 VLP,也就是两阶段的预训练策略
但这样无法将两个任务联合训练,如何将这两个任务联合起来让其互利互惠很重要
- 定位任务:仅仅是视觉任务,需要很精细的输出
- VL 理解任务:更关注两个模态之间的融合,需要更高级的语义信息输出
之前的方法是怎么进行两个任务统一的:
- 使用共享的 low-level visual encoder ,只是关于视觉的任务,无法从丰富语义信息的 VL 数据中获益
- 后面接两个并行的高级分支分别进行定位和 VL 理解
GLIPv2 是什么:grounded VL understanding 模型,是 localization 和 VL understanding 任务的统一模型
1、 grounded VL understanding = Localization + VL understanding
- Localization:同时涉及到定位和语义分类,可以使用 classification-to-matching 来将 classification 任务转换为 VL understanding 任务,所以 localization 任务可以看做 VL grounding 任务,language input 就是所有类别的合集。使用 self-training 方法就可以很方便的将大量 VL understanding data 转换为 grounding data。所以 GLIPv2 将所有任务统一为 grounding 任务
- VL understanding
2、A stronger VL grounding task:inter-image region-word 对比学习(跨 image 的对比学习)
GLIP 中提出了 phrase grounding 任务作为预训练任务,作者认为这个任务比较简单而且没有利用到全部信息。
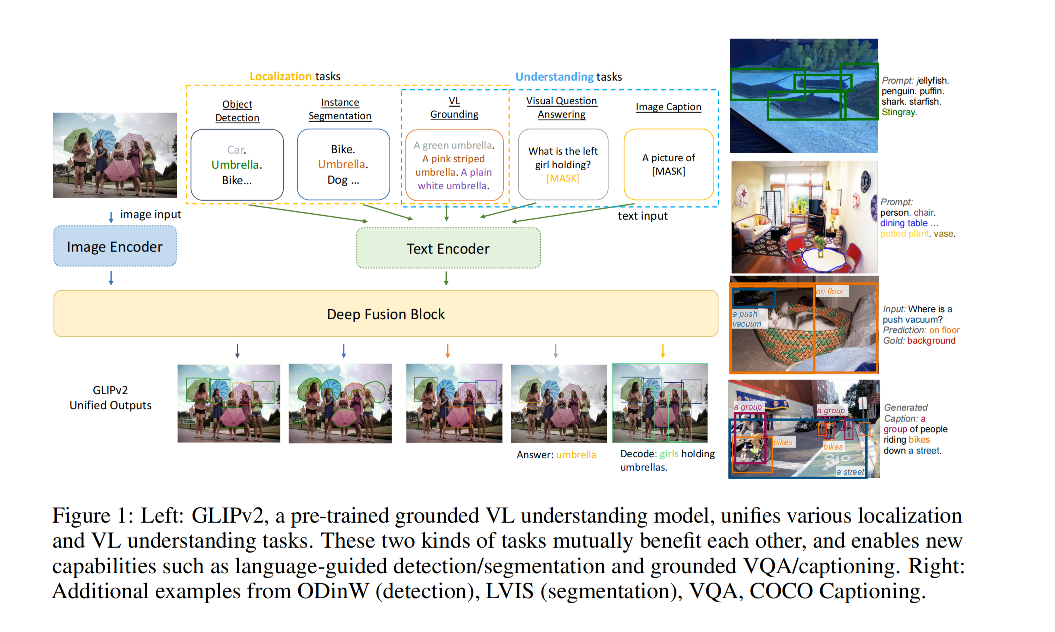
如图 1 所示的 VL grounding 任务,phrase grounding 任务只需要模型能够将给定的图片区域匹配到 text 中的一个单词即可(如 green, pink striped, or plain white umbrella),也就是相当于 1-in-3 选择任务,是比较简单的。因为这个 sentence 中只涉及到了三个颜色,没有涉及到其他颜色(如绿色、黑色、黄色等),目标物体只涉及到了雨伞,没有其他类别。在对比学习层面,phrase grouding 任务只有两个 negative,其他的 negative 并没有输入到该对比学习中。
在 GLIPv2 中,作者引入了一个新的 inter-image region-word (inter 表示图像间)对比训练任务,能从同一 batch 的不同句子中拿到潜在的负样本,让 GLIPv2 能够学习更有区分力的 region-word 特征,并且能够提高下游任务的效果
3、GLIPv2 可以让定位任务和 VL 理解任务互惠互利
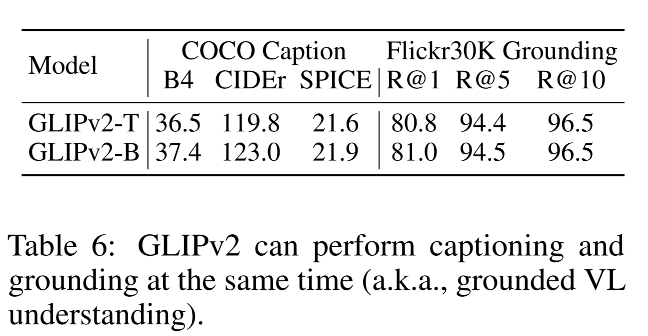
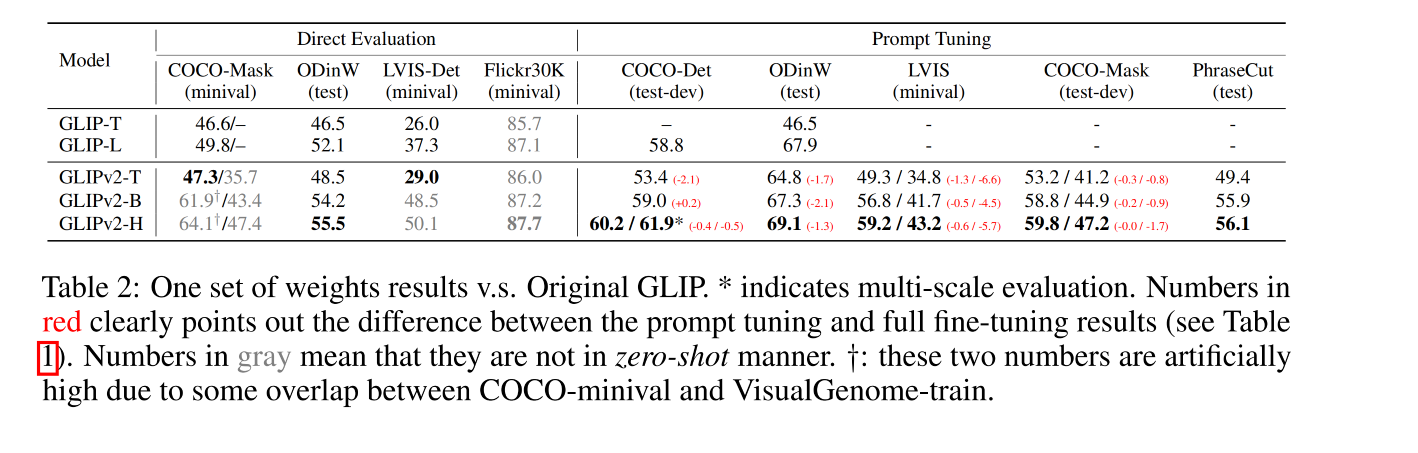
- 如表 2 所示,展示了单个 GLIPv2 模型能够达到接近 SOTA 的效果
- 受益于语义信息丰富的 image-text 标注数据,GLIPv2 展示了很强的零样本和少样本迁移到开放世界的目标检测和语义分割任务的能力
- GLIPv2 具有 language-guided 的检测和分割能力,并且获得了很好的效果
- 在 grounding model 内部,GLIPv2 能够让 VL 理解模型有很强的 grounding 能力。
4、GLIPv2 和 GLIP 的不同
- GLIP 展示了 grounded pre-training 提升定位的能力,GLIPv2 进一步证明了 grounded pre-training 能够提升 VL 理解能力,并且能将两个任务进行统一
- GLIPv2 引入了 inter-image region-word 对比学习 loss,能够提供更强的 grounding 能力
二、方法
Unifying Localization and VL Understanding
2.1 A Unified VL Formulation and Architecture
GLIPv2 统一结构的中心思想:
- classification-to-matching trick
- 该 trick 的目标:将固定类别的分类问题重构为了一个开集(open-vocabulary)vision-language 匹配问题
- 一个很好的例子就是 CLIP 将分类任务重构为了 image-text 匹配任务,可以让模型从大量的 image-text 数据中学习到很多,并且提升在开集分类任务上的零样本迁移能力
- GLIPv2 如何实现:将 vision model 中的语义分类的 linear layer 替换为 vision-language matching dot-product layer
如图 1 所示,GLIPv2 基于通用的框架将 VL 结构进行了统一:
-
dual encoder: E n c V Enc_V EncV、 E n c L Enc_L EncL
-
fusion encoder: E n c V L Enc_{VL} EncVL
-
模型输入:image-text pair (Img, Text)
-
抽取特征: ( O o , P o ) (O^o, P^o) (Oo,Po) 表示 fusion 之前的特征, ( O , P ) (O, P) (O,P) 表示 fusion 之后的特征
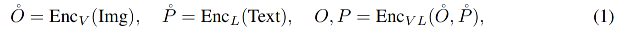
1、Vision-Language understanding task
Arch II 是常见的 VL understanding 任务的框架:
- 输入跨模态融合后的特征表达 ( O , P ) (O, P) (O,P),直接相加
- 如 GLIPv2 在 text feature P 之前添加了一个 two-layer MLP ,作为 masked language modeling(MLM)head,来进行 MLM pre-training
2、(Language-guided) object detection and phrase grounding
- GLIPv2 和 GLIP 使用的相同,使用 classification-to-matching 方法来对 detection 和 grounding 任务进行统一
- 对于 detection:使用 S g r o u n d = O P T S_{ground}=OP^T Sground=OPT 来代替 class logits S c l s = O W T S_{cls}=OW^T Scls=OWT,text feature P 是经过 language encoder 编码后的文本特征。detection 任务的 text input 是 label 组成的句子
- phrase grounding:text input 是自然描述语言
3、(Language-guided) instance segmentation and referring image segmentation
- 得到检测结果后,添加了实例分割 head
2.2 GLIPv2 pre-training
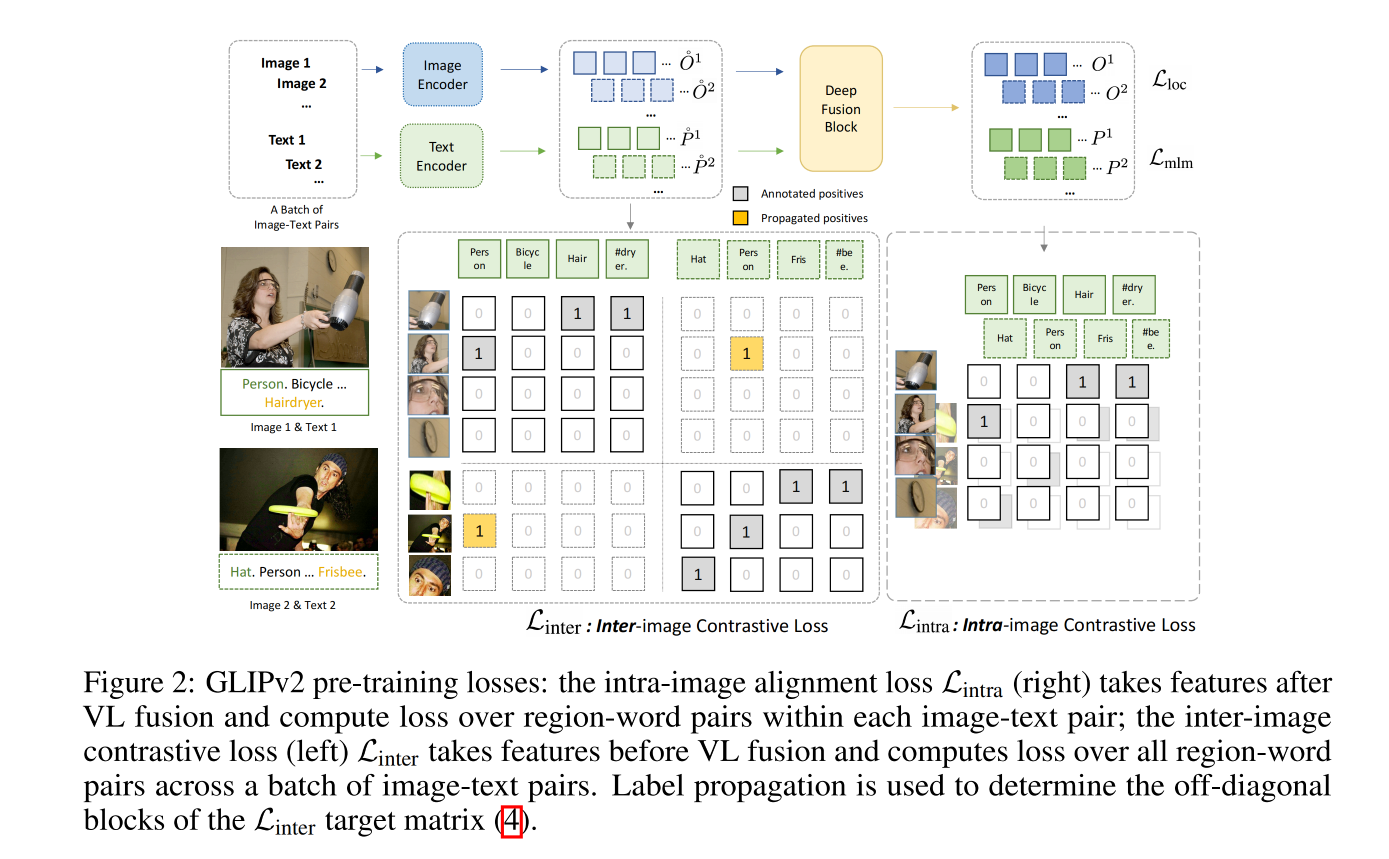
GLIPv2 的训练包括三个 pre-training loss:

1、phrase grounding loss: L g r o u n d L_{ground} Lground,由两部分组成:
-
L l o c L_{loc} Lloc:定位 loss
-
L i n t r a L_{intra} Lintra: 单个图像内的 intra-image region-word alignment loss,也就是每个 region 的语义分类 loss,给定一个 image-text pair (Img, Text),在对 O 和 P 融合后获得图像和 text 的特征, L i n t r a L_{intra} Lintra 如下:
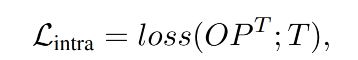
- 其中 O P T OP^T OPT 是 image region 和 word token 的相似性得分
- T T T 是 target affinity matrix,由 gt annotations 确定。
- 这里的 l o s s loss loss 在两阶段检测器中一般是 cross-entropy loss,在单阶段检测器中一般是 focal loss
- 图像间的 region-word 对比学习能力比较弱,因为可以捕捉的可用的 phrases 很有限
- GLIP 中通过添加一些 negative sentence 来让网络接收到更多 negative phrases,但由于 token 的长度限制为 256,也只能增加很少的 negative sentences
2、Inter-image region-word contrastive loss: L i n t e r L_{inter} Linter,图像间的 region-word 对比学习
在 GLIPv2 中,作者提出了从同一 batch 中的其他 image-text pairs 来提取 negative examples 的方法,这样能提高 negative examples 到 1000 倍,且不会带来很多额外的计算量

inter-image region-word contrastive loss 如下:
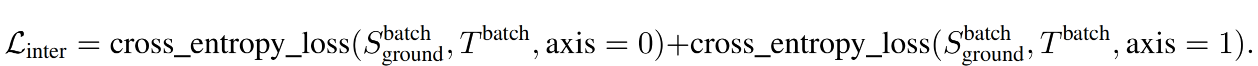
3、masked language modeling loss: L m l m L_{mlm} Lmlm
预训练方式:同时使用 detection 和 paired-image-text data 进行 预训练
- 预训练数据:image-text-target triplet format (Img,Text,T)
- target affinity matrix T 包括 box-label localization 标注结果
分割头的两级预训练:
- GLIPv2 支持两阶段的 language-guided 分割头的预训练
2.3 将 GLIPv2 迁移到 Localization 和 VL task
1、一个模型结构适用所有任务
GLIPv2 可以通过 fine-tuning 来迁移到很多下游任务:
- 检测和分割任务:不需要 task-specific head ,因为结构本来就可以实现检测和分割
- VL task:
- 对 VQA,需要增加一个分类头
- 对 caption generation:使用 unidirectional language modeling loss 训练
2、一个权重参数适用所有任务
如表 2 所示
3、Grounded VL understanding
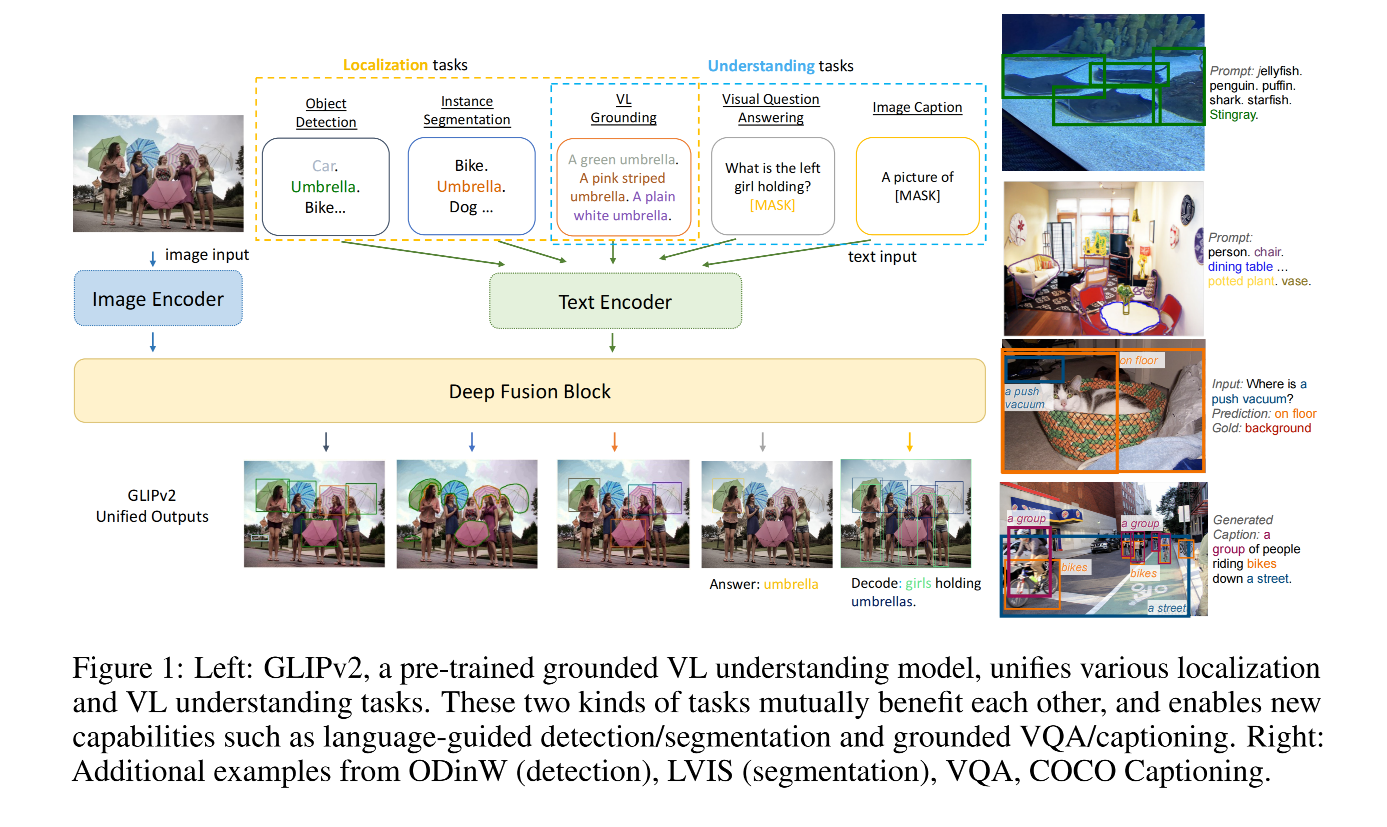
clearer illustration:
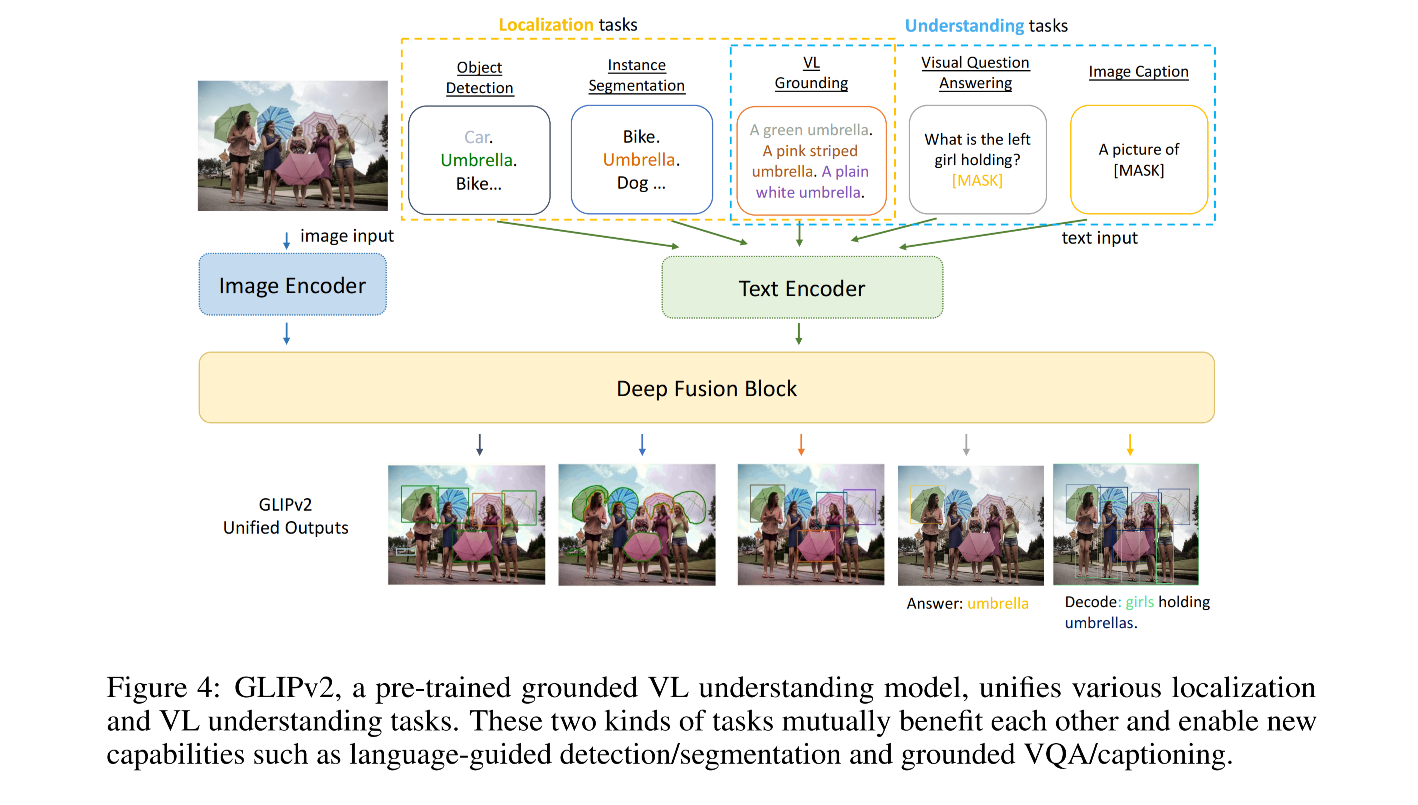
三、结果
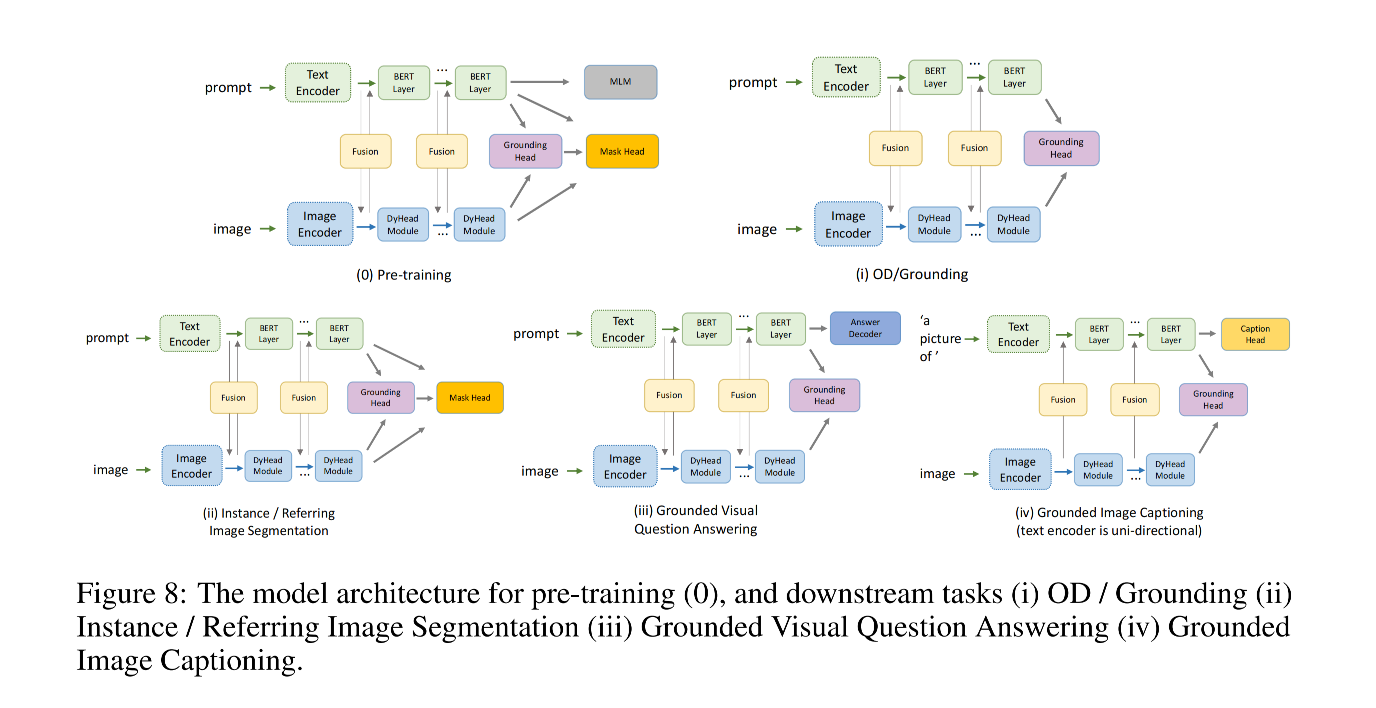
模型结构:
- E n c V Enc_V EncV: image encoder( Swin Transformer)
- E n c L Enc_L EncL:text transformer
- E n c V L Enc_{VL} EncVL:fusion encode,Dynamic Head
- instance segmentation head:Hourglass network
模型尺寸:
- GLIPv2-T:Swin-Tiny 和 BERT-Base 作为两个 encoder,数据:O365、GoldG 、Cap4M(4M image-text pairs collected from the web with boxes generated by GLIP-T [41])
- GLIPv2-B:Swin-Base 和 pre-layernorm text transformer [18] 作为两个 encoder,数据:
- FiveODs (2.78M data)
- GoldG as in MDETR [30]
- CC15M+SBU, 16M public image-text data with generated boxes by GLIP-L [41]
- Segmentation head 的预训练:模型其他参数都冻结,只基于 COCO、 LVIS 、PhraseCu 训练 head
- GLIPv2-H:Swin-Huge 和 pre-layernorm text transformer [18] 作为两个 encoder,数据:
- FiveODs (2.78M data)
- GoldG as in MDETR [30]
- CC15M+SBU, 16M public image-text data with generated boxes by GLIP-L [41]
- Segmentation head 的预训练:模型其他参数都冻结,只基于 COCO、 LVIS 、PhraseCu 训练 head

3.1 One model architecture for all


3.2 One set of model parameters for all
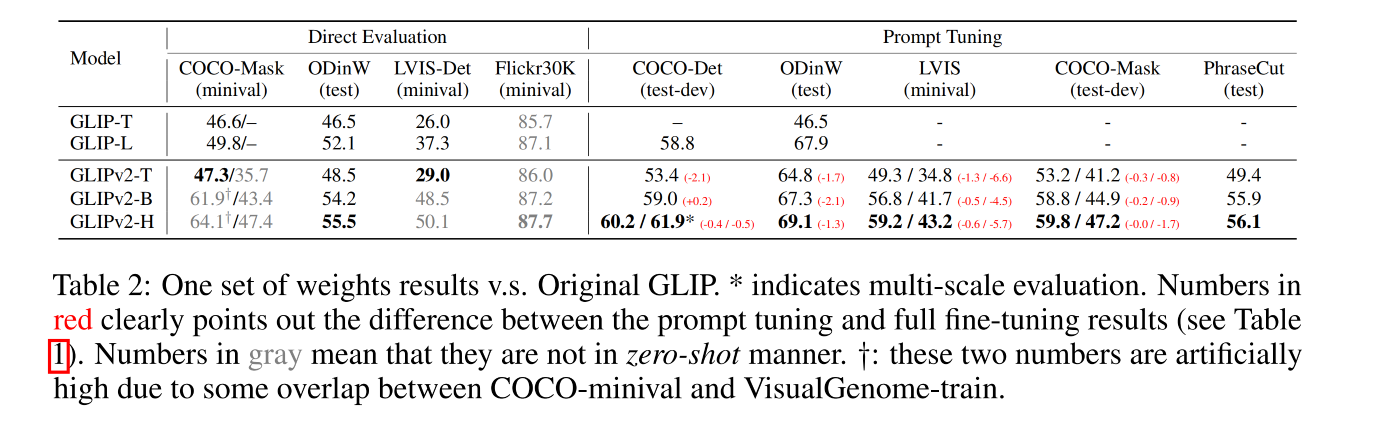
3.3 GLIPv2 as a strong few-shot learner
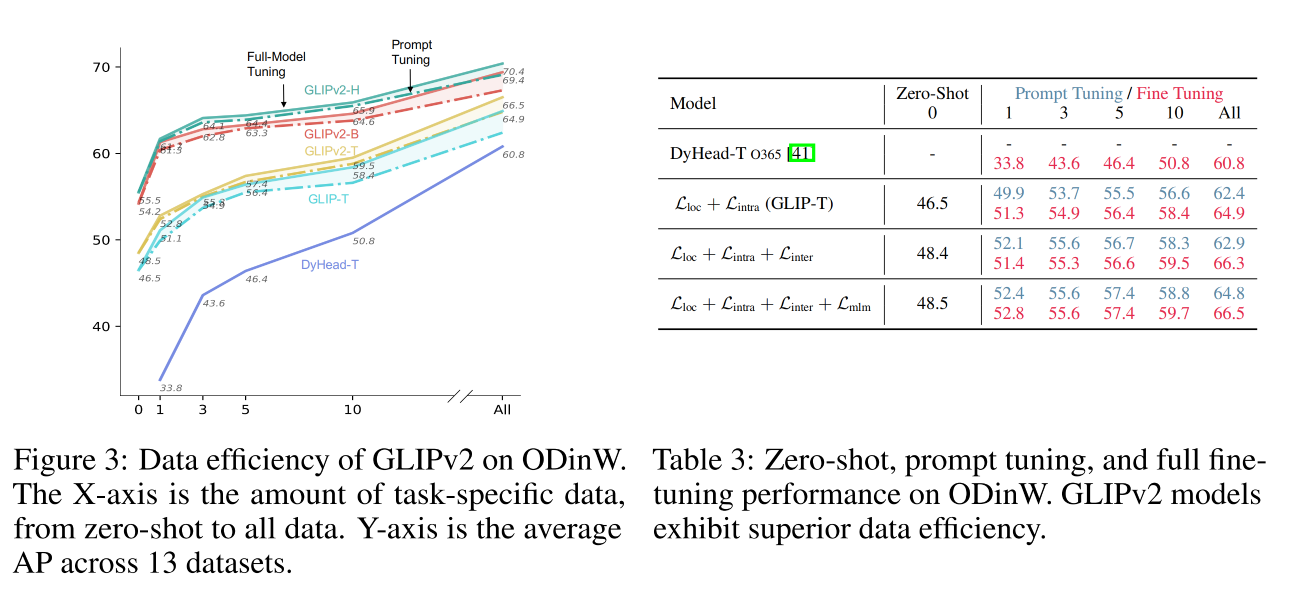
3.4 Analysis
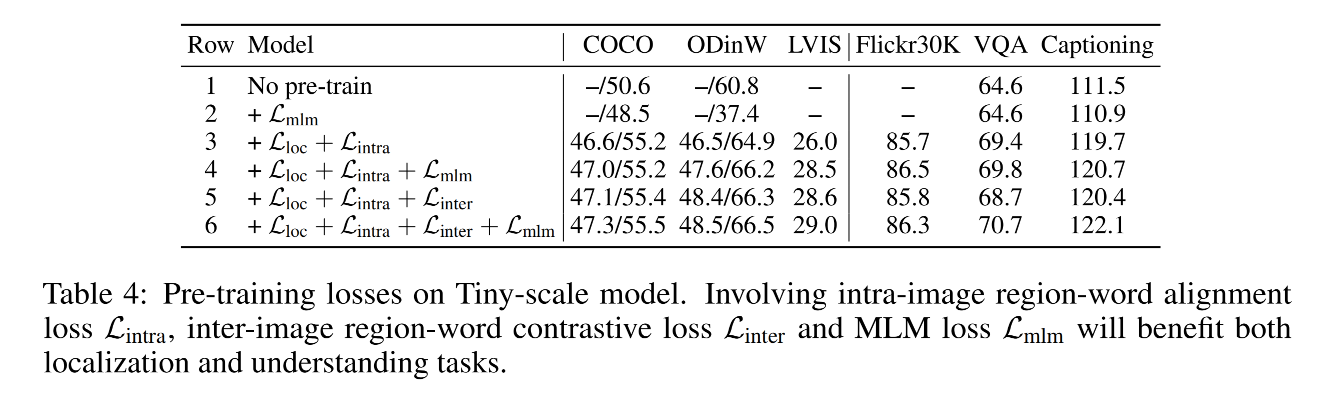
1、pre-training losses
2、pre-training data

3、Grounded VL understanding