# R语言
R语言学习笔记——入门篇:第四章-基本数据管理
文章目录
- 一、示例
- 二、创建新变量
- 三、变量的重编码
- 四、变量的重命名
- 4.1、交互式编辑器
- 4.2、函数编程
- 五、缺失值
- 5.1、重编码某些值为缺失值
- 5.2、在分析中排除缺失值
- 六、日期值
- 6.1、将日期值转换回字符型变量
- 6.2、进阶函数介绍
- 七、类型判断/转化
- 八、数据排序
- 九、数据集的合并
- 9.1、向数据框添加列
- 9.2、向数据框添加行
- 十、数据集取子集
- 10.1、保留变量
- 10.2、删除变量
- 10.3、筛选变量
- 10.4、subset( )函数
- 10.5、随机抽样
- 十一、使用sql语句操作数据框
一、示例
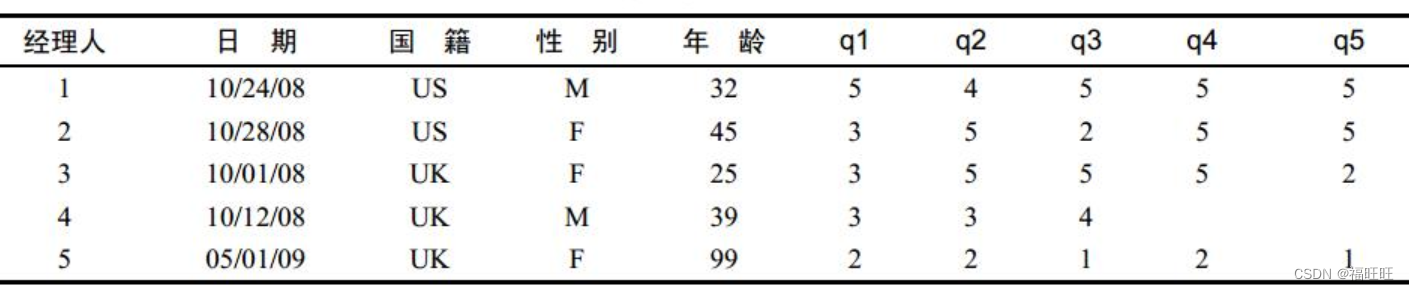
- 一组数据:上司对经理人的服从度的评价,q1-q5表示了"非常不同意",“不同意”,“一般”,“同意”,“非常同意”。
- 其中存在着缺失的数据(经理人4,q4-q5),无效的数据(经理人5,年龄99),为了更好的处理数据还需要对数据重编排等,这些都需要我们对数据进行基本的管理。数据管理前的第一步是创建数据集(详见第二章)
- 第一步——创建数据集:
Sys.setenv(LANGUAGE = "en")
options(stringsAsFactors = F)
rm(list = ls())
setwd("C:/Users/16748/Desktop/R语言学习/R")
manager <- c(1,2,3,4,5)
manager <- c(1,2,3,4,5)
date <- c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country <- c("US","US","UK","UK","UK")
age <- c(32,45,25,39,99)
gender <- c("M","F","F","M","F")
q1 <- c(5,3,3,3,2)
q2 <- c(4,5,5,3,2)
q3 <- c(5,2,5,4,1)
q4 <- c(5,5,5,NA,2)
q5 <- c(5,5,2,NA,1)
leadership <- data.frame(manager,date,country,
gender,age,q1,q2,q3,q4,q5)
二、创建新变量
- 创建新变量或对原变量进行替换
- 方法:
变量名 <- 表达式
# 表达式可以包含多种运算符和函数
- 算数运算符:
| 算数运算符 | 功能 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| ^或** | 求幂 |
| x%%y | 求余 |
| x%/%y | 整数除法(只取整数位),如5.5%/%2=2 |
- 函数:transform( )
- 创建新变量的步骤
- 语法:
变量名 <- transform(数据框名,变量名 = 表达式)
- 示例:展示三种创建新变量的方法
x <- data.frame(x1 = c(1,2,3,4),
x2 = c(4,3,2,1))
# 方法一
x$sum <- x$x1 + x$x2
# 方法二
attach(x)
x$sum <- x1 + x2
detach(x)
# 方法三
x <- transform(x,sum = x1 + x2)
三、变量的重编码
- 定义:根据变量的现有值重新创建新的值
- 例如:将误编码的值替换为正确值
- 基于一个指标将值划分为几个区间
- 判定:利用逻辑运算符来对数据进行判定,逻辑运算符的返回值为TRUE或FALSE
- 逻辑运算符:
| 逻辑运算符 | 功能 |
|---|---|
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| == | 等于 |
| != | 不等于 |
| !x | 非x |
| x I y | x或y |
| x & y | x和y |
| isTRUE(x) | 测试x是否为TRUE |
- 示例:
# 将99岁的年龄重编码为缺失值
leadership$age[leadership$age ==99] <- NA
# variable[condition] <- expression将仅在condition的值为TRUE时执行
# 希望将年龄值按照不同年龄段分类
leadership <- within(leadership,{
age[age == 99] <- NA
agecat <- NA
agecat[age > 75] <- "Elder"
agecat[age >= 35 & age <= 75] <- "Middle Aged"
agecat[age < 35 ] <- "Young"
agecat <- factor(agecat,levels = c("Elder","Middle Aged","Young"),ordered = T)
})
四、变量的重命名
有两种方式进行变量重命名
4.1、交互式编辑器
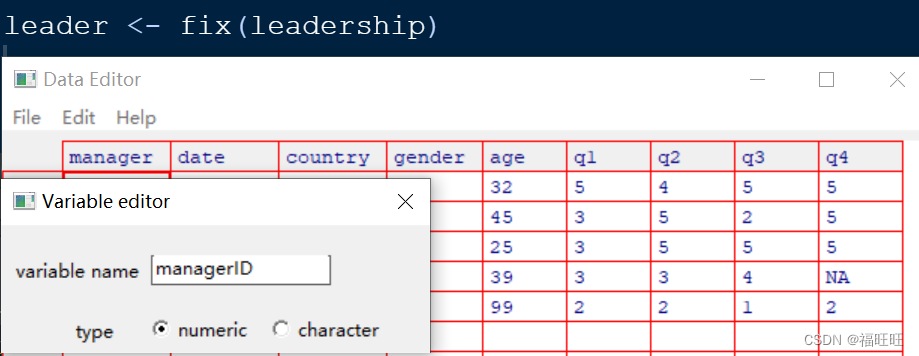
- 函数:
fix(数据框名)
此函数会调用出一个交互式编辑器,然后直接单击变量名就可以重命名。
-
示例:
-
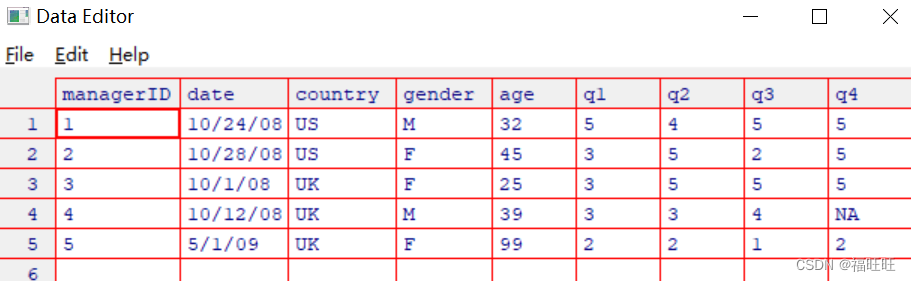
结果:
4.2、函数编程
- 函数:
names( )
rename( )# 属于plyr包
- 语法:
names(数据框名)[需要修改变量的列(数值)] <- "修改后的名字"
rename(dataframe,c(oldname1="newname1",oldname2="newname2",...))
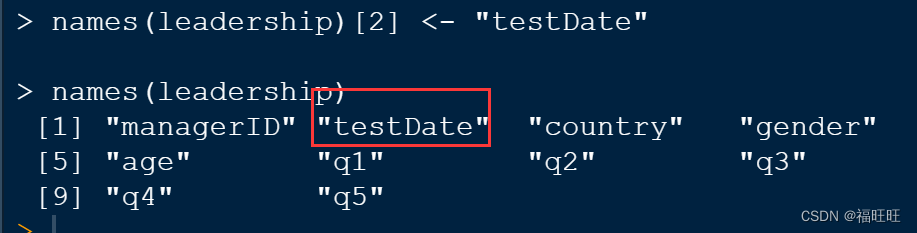
- 示例:
names(leadership)[2] <- "testDate"
leadership <- rename(leadership,c(manager = "managerID",date = "testDate"))
- 结果:
五、缺失值
- 缺失值(NA,Not Available,不可用):项目中不完整的数据,字符型与数值型中都用NA表示。
- 检测缺失值: is.na()函数 ,返回逻辑值
- 注意点:
- 缺失值不可用于比较(即使是与缺失值自身比较)
- 无限大或不可能的值 != 缺失值(在R中)
- 例如:正无穷(负无穷) 标记为 (-)Inf
- 不可能的值(如sin(Inf)) 标记为 NAN(not a number)
- 利用is.infinite()函数 和is.nan()函数 来判断无限大与不可能的值。
5.1、重编码某些值为缺失值
如 三、变量的重编码 演示一般
5.2、在分析中排除缺失值
- 由于含有缺失值的函数计算结果也是缺失值,因此在数据分析之前需要删除缺失值。
- 多数函数中含有na.rm=TRUE的参数选项,可以移除缺失值并将剩余值进行计算.
- na.omit()函数,将含有缺失值的那一行删除(项目中含有少量缺失值时使用)
- 精细操作会在后续章节探讨
- 示例:
x <- c(1,2,NA,4)
y <- sum(x,na.rm = T)
newdata <- na.omit(leadership)
六、日期值
- 概述:通过将日期值改编为日期变量后就可以对日期进行分析与绘图
- 日期变量:日期值会以字符串的形式输入到R中,然后转化为以数值形式存储的日期变量
- 函数:as.Date()
- 语法:
as.Date(x,"input_format")
# x为字符串数据
# input_format为日期格式参数
- 日期格式参数:
| 符号 | 含义 | 示例 |
|---|---|---|
| %d | 天数day(数字) | 01-31 |
| %a | 星期名(缩写) | Mon-Sun |
| %A | 星期名(全称) | Monday-Sunday |
| % m | 月份(数字) | 01-12 |
| % b | 月份(缩写) | Jan-Dec |
| % B | 月份(全称) | January-December |
| %y | 年份(2位数) | 22 |
| %Y | 年份(4位数) | 2022 |
- 默认输入格式:yyyy-mm-dd
- 通过设定日期格式参数来转化输入格式
- 示例:
> date1 <- as.Date("1956-10-12")
> date1
[1] "1956-10-12"
> Dates <- c("01/05/1965","02/05/2000")
> myformat <- "%m/%d/%Y"
> dates <- as.Date(Dates,myformat)
> dates
[1] "1965-01-05" "2000-02-05"
- 函数扩展:
Sys.Date()
# 返回当天的日期
date()
# 返回当前的具体时间
format(TimeData,input_format)
# 将输入的TimeData日期变量,按照input_format日期格式输出
difftime(TimeData1,TimeData2,units = "")
# 计算时间间隔(星期,天,时,分,秒),可以存在负数
# 示例
> Sys.Date()
[1] "2022-12-03"
> # 返回当天的日期
> date()
[1] "Sat Dec 3 17:51:32 2022"
> # 计算时间间隔(星期,天,时,分,秒)
> format(as.Date("1956-10-12"),"%A")
[1] "星期五"
> difftime(as.Date("1956-10-12"),as.Date("2022-12-3"),units = "weeks")
Time difference of -3451.143 weeks
6.1、将日期值转换回字符型变量
- 函数:as.character()
- 转化后,即可使用一系列字符函数处理数据(如取子集,替换,连接等)
6.2、进阶函数介绍
# 了解字符型数据转为日期的更多细节
help(as.Date)
help(strftime)
# 查看日期与时间格式
help(ISOdatetime)
# 简化日期处理的函数,用于识别解析日期-时间数据,抽取日期-时间成分(如年份,月份等),对日期-时间进行算数运算
lubridate
# 进行复杂的日期运算包,处理多时区,历法操作,支持工作日假期等。
timeDate
七、类型判断/转化
- 查询:class( ),mode( ), typeof( )
- 判断:is.arrary(/list/character …) 输出TRUE或FALSE
- 修改:as.arrary(/list/character …)
| 函数 | 类型 |
|---|---|
| is.numeric() / as.numeric | 数值型 |
| is.character() | 字符型 |
| is.logical() | 逻辑型 |
| is.vector() | 向量 |
| is.matrix() | 矩阵 |
| is.array() | 数组 |
| is.data.frame() | 数据框 |
| is.factor() | 因子 |
| is.list() | 列表 |
八、数据排序
- 函数:order(排序变量)
- 默认排序顺序:升序
- 降序:在排序变量前加上负号“-”
- 示例:
# 对行排序,先按照女性到男性的顺序,同性别中按年龄降序排序。
> newdate <- leadership[order(leadership$gender,-leadership$age),]
> newdate
managerID testDate country gender age q1 q2 q3 q4 q5
5 5 5/1/09 UK F 99 2 2 1 2 1
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
1 1 10/24/08 US M 32 5 4 5 5 5
九、数据集的合并
向数据框中添加行或列
9.1、向数据框添加列
有两种函数可以实现该目的
- 函数:merge()
- 语法:
x <- merge(dateframe1,dateframe2,by = "变量名")
x <- merge(dateframe1,dateframe2,by = c("变量名1","变量名2"..))
-
对象:横向合并两个数据框(数据集),根据一个或多个变量进行联结。
-
函数:cbind()
-
语法:
x <- cbind(A,B)
- 对象:横向合并两个数据框或矩阵,不需要索引变量,要求两个对象拥有相同的函数。
- 预处理:如果行数不同就需要预处理下数据,使得行数相同。例如dateframe1中拥有dateframe2中没有的变量。
- 方法一:删除dateframe1中多余变量
- 方法二:在dateframe2中创建追加变量,并将值设为NA
9.2、向数据框添加行
- 函数:rbind()
- 语法:
x <- merge(dateframe1,dateframe2,by = "变量名")
x <- merge(dateframe1,dateframe2,by = c("变量名1","变量名2"..))
- 对象:纵向合并两个数据框或矩阵,不需要索引变量,要求两个对象拥有相同的函数。
- 预处理:如果行数不同就需要预处理下数据,使得行数相同。例如dateframe1中拥有dateframe2中没有的变量。
- 方法一:删除dateframe1中多余变量
- 方法二:在dateframe2中创建追加变量,并将值设为NA
十、数据集取子集
10.1、保留变量
- 提取原数据集中的变量赋给新的数据集
- 操作:数据提取(详见第二章)
- 示例:
> newdata <- leadership[,c(6:10)]
> newdata
q1 q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1
10.2、删除变量
- 删除原数据集中的变量后赋给新的数据集
- 通过逻辑判为FALSE,变量前加负号“-”,数据赋为NULL(非NA)实现
- 操作:数据删除(详见第二章)
- 示例:
> x <- names(leadership) %in% c("q3","q4")
> x
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE
> newdata <- leadership[!x]
> newdata
managerID date country gender age q1 q2 q5
1 1 10/24/08 US M 32 5 4 5
2 2 10/28/08 US F 45 3 5 5
3 3 10/1/08 UK F 25 3 5 2
4 4 10/12/08 UK M 39 3 3 NA
5 5 5/1/09 UK F 99 2 2 1
10.3、筛选变量
- 通过一系列逻辑运算符来筛选需要的数据集后赋给新的数据集
- 操作:逻辑运算符
- 示例:
> newdata <- leadership[1:3,]
> newdata <- leadership[leadership$gender == "M" & leadership$age >30,]
> newdata
managerID date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
4 4 10/12/08 UK M 39 3 3 4 NA NA
10.4、subset( )函数
- 函数:subset()
- 功能:用于选择变量和观测subset
- 语法:
subset(dateframe,condition,select = c())
# dateframe为数据集
# condition为筛选条件
# select里面为保留的变量名
- 示例:
x <- subset(leadership,age >=35 | age <=24 ,select = c(q1,q2,q3,q4))
x <- subset(leadership,gender =="M" | age > 24 ,select = gender:q4)
# 保留了变量gender到q4及其之间的列
10.5、随机抽样
- 函数:sample()
- 功能:从数据集中(有/无放回的)抽取大小为n的一个随机样本
- 语法:
sample(x,n,replace = T/F)
# x为抽样的范围
# n为抽样的数量
# replace表示有(T)无(F)放回抽样
- 示例:
x <- leadership[sample(1:nrow(leadership),,replace = T),]
十一、使用sql语句操作数据框
- R包:sqldf
- 通过该R包就可以在R中使用SQl语句对数据框等变量进行操作。
- 示例:
install.packages("sqldf")
library(sqldf)
dateframe <- sqldf("select * from x",row.names = T)

![[论文阅读] 颜色迁移-Automated Colour Grading](https://img-blog.csdnimg.cn/63e007a483454a7ba74309f8d628bfc4.png)
![[附源码]计算机毕业设计基于springboot的云网盘设计](https://img-blog.csdnimg.cn/dfa876eb43274eb99aeacdf0493ae889.png)
![[Power Query] 日期和时间处理](https://img-blog.csdnimg.cn/e32e5f205503482ebb264c2715548aa1.png)

![[附源码]Python计算机毕业设计Django考试系统](https://img-blog.csdnimg.cn/a37ed9a3197a4395b6724029aa19f0d6.png)