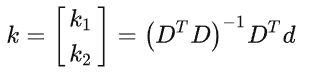专业术语-计算机 / 深度学习与目标检测 / 轨道交通
- 一、 计算机
- 1 IDE
- 2 API
- 3 CUDA Driver API
- 3.1 cuInit - 驱动初始化
- 3.2 关于context,有两种:
- 3.3 CUcontext
- 4 RuntimeAPI
- 5 Memory
- 5.1 关于内存,有两大类:
- 5.1.1 CPU内存,称之为Host Memory
- 5.1.2 GPU内存,称之为Device Memory
- 5.2 Pinned Memory
- 5.2.1 基于前面的理解,我们总结如下:
- 5.2.2 显卡访问Pinned Memory轨迹
- 5.2.3 内存方面总结
- 6 stream - 流
- 7 核函数
- 8 共享内存
- 9 Warpaffine
- 二、 深度学习与目标检测
- 1 TTA(test time augmentation)
- 2 NMS (Non-maximum suppression)
- 3 soft-NMS
- 4 WBF(weighted boxes fusion)
- 三、轨道交通
- 1 ATC 列车自动控制系统
- 2 ATS 列车自动监控系统
- 3 ATP 列车自动防护子系统
- 4 ATO 列车自动运行系统
一、 计算机
1 IDE
集成开发环境,例如:Visual Studio Code;Pycharm等
2 API
操作系统给应用程序的调用接口
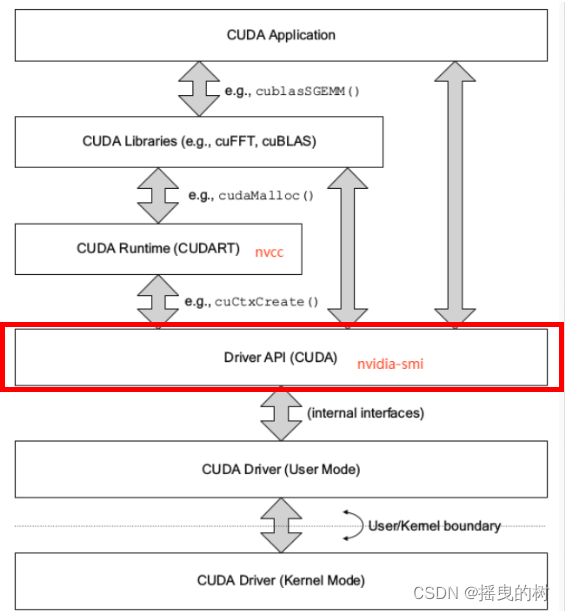
3 CUDA Driver API
- 与GPU沟通的驱动级别底层API
- CUDA Driver随显卡驱动发布,与cudatoolkit分开看 CUDA
- Driver对应于cuda.h和libcuda.so文件
- 主要知识点是Context的管理机制,以及CUDA系列接口的开发习惯(错误检查方法),还有内存模型
参考链接:https://www.cnblogs.com/marsggbo/p/11838823.html
3.1 cuInit - 驱动初始化
- cuInit的意义是,初始化驱动API,如果不执行,则所有API都将返回错误,全局执行一次即可
- 没有对应的cuDestroy,不需要释放,程序销毁自动释放
3.2 关于context,有两种:
- 手动管理的context,cuCtxCreate(手动管理,以堆栈方式push/pop)
- 自动管理的context,cuDevicePrimaryCtxRetain(自动管理,runtime api以此为基础)
3.3 CUcontext
- context是一种上下文,关联对GPU的所有操作 context与一块显卡关联,一个显卡可以被多个context关联
- 每个线程都有一个栈结构储存context,栈顶是当前使用的context,对应有push、pop函数操作
- context的栈,所有api都以当前context为操作目标
- 试想一下,如果执行任何操作你都需要传递一个device决定送到哪个设备执行,得多麻烦
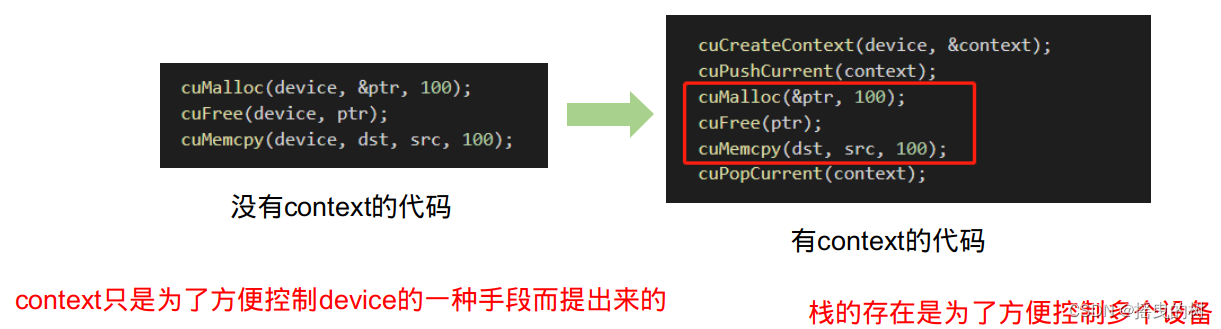
- 由于高频操作,是一个线程基本固定访问一个显卡不变,且只使用一个context,很少会用到多context
- CreateContext、PushCurrent、PopCurrent这种多context管理就显得麻烦,还得再简单
- 因此推出了cuDevicePrimaryCtxRetain,为设备关联主context,分配、释放、设置、栈都不用你管
- primaryContext:给我设备id,给你context并设置好,此时一个显卡对应一个primary context
不同线程,只要设备id一样,primary context就一样。context是线程安全的

4 RuntimeAPI
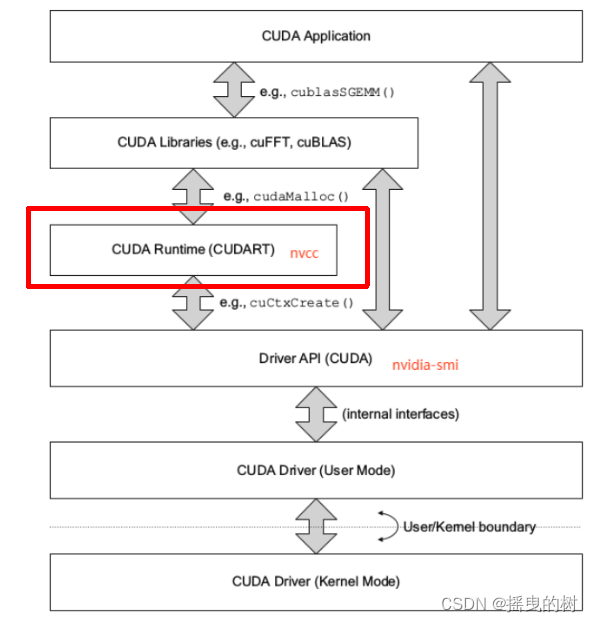
- 对于runtimeAPI,与driver最大区别是懒加载
- 即,第一个runtime API调用时,会进行cuInit初始化,避免驱动api的初始化窘境
- 即,第一个需要context的API调用时,会进行context关联并创建context和设置当前context,调用cuDevicePrimaryCtxRetain实现
- 绝大部分api需要context,例如查询当前显卡名称、参数、内存分配、释放等
- CUDA Runtime是封装了CUDA Driver的高级别更友好的API
- 使用cuDevicePrimaryCtxRetain为每个设备设置context,不再手工管理context,并且不提供直接管理context的API(可Driver
API管理,通常不需要) - 可以更友好的执行核函数,.cpp可以与.cu文件无缝对接
- 对应cuda_runtime.h和libcudart.so
- runtime api随cuda toolkit发布
- 主要知识点是核函数的使用、线程束布局、内存模型、流的使用
- 主要实现归约求和、仿射变换、矩阵乘法、模型后处理,就可以解决绝大部分问题
5 Memory
内存模型是CUDA中很重要的知识点
- 主要理解pinned memory、global memory、shared memory即可,其他不常用
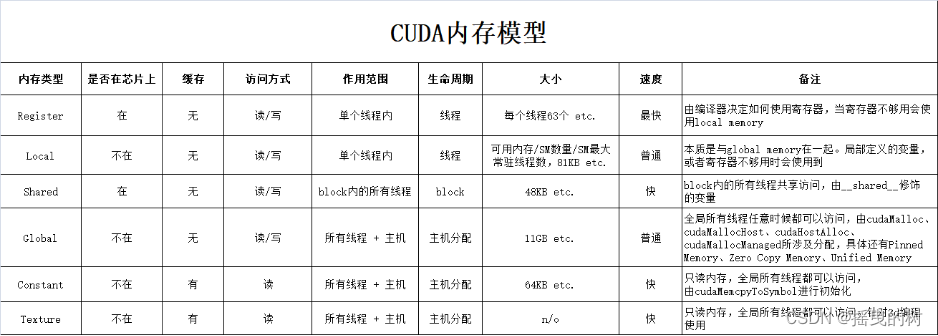
5.1 关于内存,有两大类:
5.1.1 CPU内存,称之为Host Memory
- Pageable Memory:可分页内存
- Page-Locked Memory:页锁定内存
5.1.2 GPU内存,称之为Device Memory
- Global Memory:全局内存
- Shared Memory:共享内存
- …以及其他多种内存
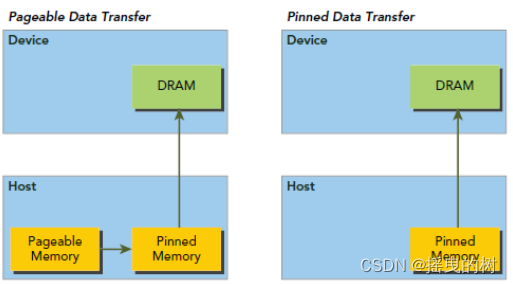

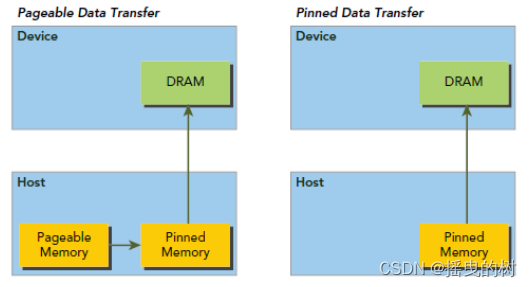
5.2 Pinned Memory

对于整个Host Memory内存条而言,操作系统区分为两个大类(逻辑区分,物理上是同一个东西):
- Pageable memory,可分页内存
- Page lock memory,页锁定内存
你可以理解为Page lock memory是vip房间,锁定给你一个人用。而Pageable memory是普通房间,在酒店房间不够的时候,选择性的把你的房间腾出来给其他人交换用,这就可以容纳更多人了。造成房间很多的假象,代价是性能降低
5.2.1 基于前面的理解,我们总结如下:
- pinned memory具有锁定特性,是稳定不会被交换的(这很重要,相当于每次去这个房间都一定能找到你)
- pageable memory没有锁定特性,对于第三方设备(比如GPU),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据(每次去房间找,说不准你的房间被人交换了)
- pageable memory的性能比pinned memory差,很可能降低你程序的优先级然后把内存交换给别人用
- pageable memory策略能使用内存假象,实际8GB但是可以使用15GB,提高程序运行数量(不是速度)
- pinned memory太多,会导致操作系统整体性能降低(程序运行数量减少),8GB就只能用8GB。注意不是你的应用程序性能降低,这一点一般都是废话,不用当回事
- GPU可以直接访问pinned memory而不能访问pageable memory(因为第二条)
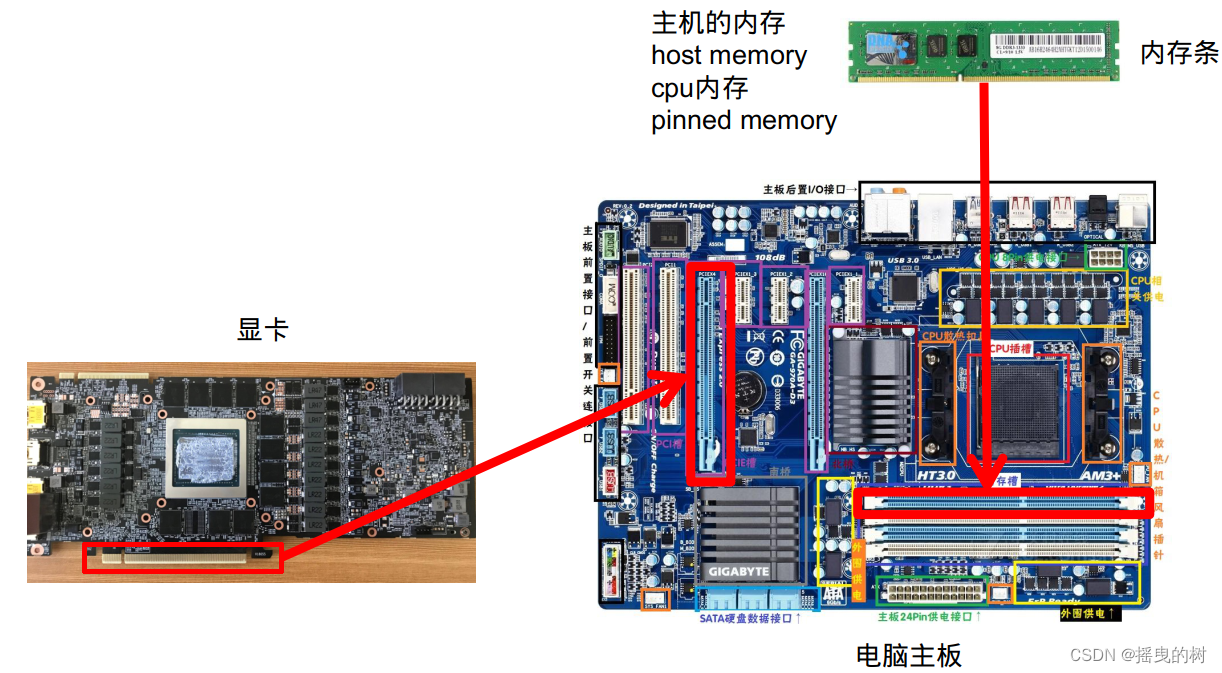
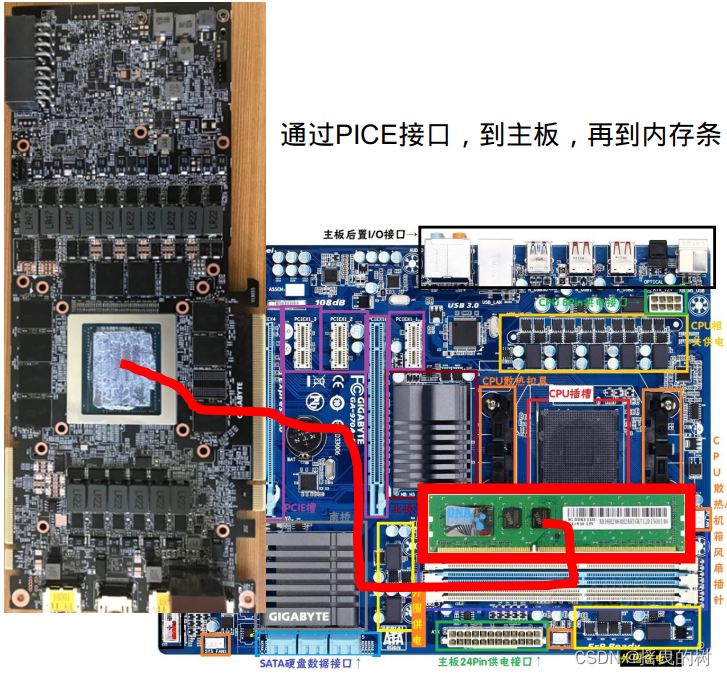
5.2.2 显卡访问Pinned Memory轨迹
5.2.3 内存方面总结
原则:
- GPU可以直接访问pinned memory,称之为(DMA Direct Memory Access)
- 对于GPU访问而言,距离计算单元越近,效率越高,所以PinnedMemory<GlobalMemory<SharedMemory
- 代码中,由new、malloc分配的,是pageable memory,由cudaMallocHost分配的是PinnedMemory,由cudaMalloc分配的是GlobalMemory
- 尽量多用PinnedMemory储存host数据,或者显式处理Host到Device时,用PinnedMemory做缓存,都是提高性能的关键
6 stream - 流
- 流是一种基于context之上的任务管道抽象,一个context可以创建n个流
- 流是异步控制的主要方式
- nullptr表示默认流,每个线程都有自己的默认流
- 要十分注意,指令发出后,流队列中储存的是指令参数,不能加入队列后立即释放参数指针,这会导致流队列执行该指令时指针失效而出错
- 应当在十分肯定流已经不需要这个指针后,才进行修改或者释放,否则会有非预期结果出现
- 举个粒子:你给钱让男朋友买西瓜,他刚到店拿好西瓜,你把转的钱撤回去了。此时你无法预知他是否会跟店家闹起来矛盾,还是屁颠的回去。如果想得到预期结果,必须得让卖西瓜结束再处理钱的事情
7 核函数
- 核函数是cuda编程的关键
- 通过xxx.cu创建一个cudac程序文件,并把cu交给nvcc编译,才能识别cuda语法
- __global__表示为核函数,由host调用。__device__表示为设备函数,由device调用
- __host__表示为主机函数,由host调用。__shared__表示变量为共享变量
- host调用核函数:function<<<gridDim, blockDim, sharedMemorySize,
stream>>>(args…); - 只有__global__修饰的函数才可以用<<<>>>的方式调用
- 调用核函数是传值的,不能传引用,可以传递类、结构体等,核函数可以是模板
- 核函数的执行,是异步的,也就是立即返回的
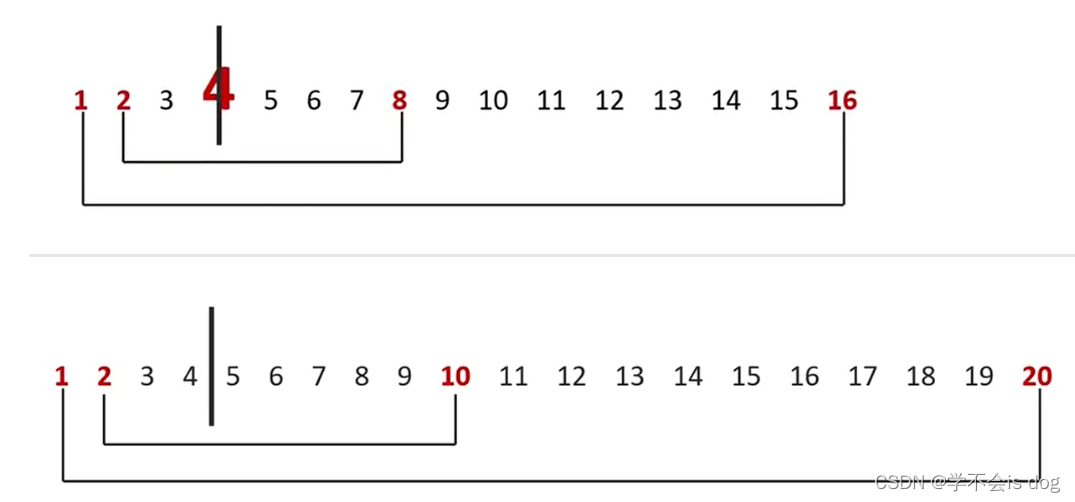
- 线程layout主要用到blockDim、gridDim
- 核函数内访问线程索引主要用到threadIdx、blockIdx、blockDim、gridDim这些内置变量
核函数里面,把blockDim、gridDim看作shape,把threadIdx、blockIdx看做index
则可以按照维度高低排序看待这个信息:

8 共享内存
- 共享内存因为更靠近计算单元,所以访问速度更快
- 共享内存通常可以作为访问全局内存的缓存使用
- 可以利用共享内存实现线程间的通信
- 通常与__syncthreads同时出现,这个函数是同步block内的所有线程,全部执行到这一行才往下走
- 使用方式,通常是在线程id为0的时候从global memory取值,然后syncthreads,然后再使用
9 Warpaffine
主要解决图像的缩放和平移,来处理目标检测中常见的预处理行为
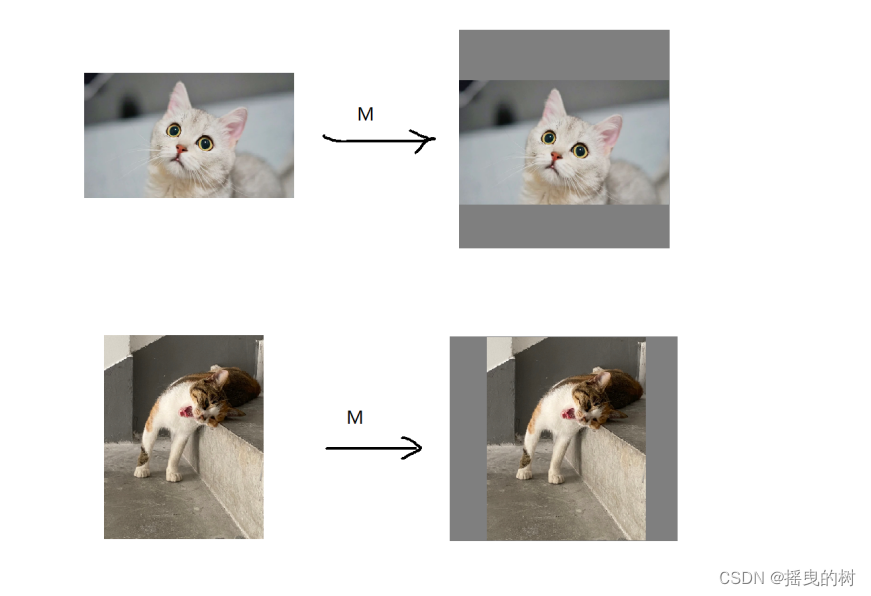
- warpaffine是对图像做平移缩放旋转变换进行综合统一描述的方法
- 同时也是一个很容易实现cuda并行加速的算法
- 在深度学习领域通常需要做预处理,比如CopyMakeBorder,RGB->BGR,减去均值除以标准差,BGRBGRBGR -> BBBGGGRRR
- 如果使用cuda进行并行加速实现,那么可以对整个预处理都进行统一,并且性能贼好
- 由于warpaffine是标准的矩阵映射坐标,并且可逆,所以逆变换就是其变换矩阵的逆矩阵
- 对于缩放和平移的变换矩阵,其有效自由度为3

二、 深度学习与目标检测
1 TTA(test time augmentation)
测试时数据增强:指的是在推理(预测)阶段,将原始图片进行水平翻转、垂直翻转、对角线翻转、旋转角度等数据增强操作,得到多张图,分别进行推理,再对多个结果进行综合分析,得到最终输出结果。
2 NMS (Non-maximum suppression)
非极大抑制:经典NMS最初第一次应用到目标检测中是在RCNN算法中,其实现严格按照搜索局部极大值,抑制非极大值元素的思想来实现的,具体的实现步骤如下:
- 设定目标框的置信度阈值,常用的阈值是0.5左右
- 根据置信度降序排列候选框列表
- 选取置信度最高的框A添加到输出列表,并将其从候选框列表中删除
- 计算A与候选框列表中的所有框的IoU值,删除大于阈值的候选框
- 重复上述过程,直到候选框列表为空,返回输出列表
当NMS的阈值设为0.2时:
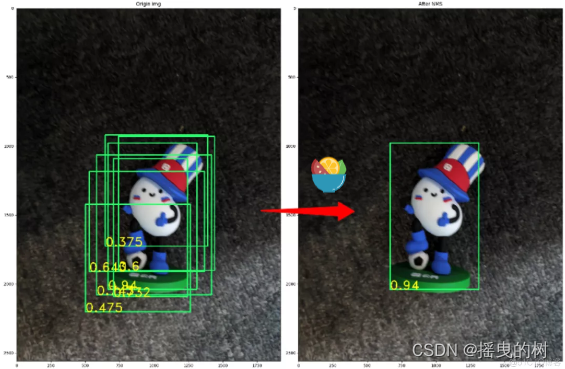
python实现:
def nms(bounding_boxes, Nt):
if len(bounding_boxes) == 0:
return [], []
bboxes = np.array(bounding_boxes)
# 计算 n 个候选框的面积大小
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
scores = bboxes[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# 对置信度进行排序, 获取排序后的下标序号, argsort 默认从小到大排序
order = np.argsort(scores)
picked_boxes = [] # 返回值
while order.size > 0:
# 将当前置信度最大的框加入返回值列表中
index = order[-1]
picked_boxes.append(bounding_boxes[index])
# 获取当前置信度最大的候选框与其他任意候选框的相交面积
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11 + 1)
h = np.maximum(0.0, y22 - y11 + 1)
intersection = w * h
# 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除
ious = intersection / (areas[index] + areas[order[:-1]] - intersection)
left = np.where(ious < Nt)
order = order[left]
return picked_boxes
3 soft-NMS
经典NMS算法存在着一些问题:对于重叠物体无法很好的检测。经典NMS算法的做法是直接删除Iou大于阈值的Bounding box;而Soft-NMS则是使用一个基于Iou的衰减函数,降低Iou大于阈值Nt的Bounding box的置信度,IoU越大,衰减程度越大。
python代码
def soft_nms(bboxes, Nt=0.3, sigma2=0.5, score_thresh=0.3, method=2):
# 在 bboxes 之后添加对于的下标[0, 1, 2...], 最终 bboxes 的 shape 为 [n, 5], 前四个为坐标, 后一个为下标
res_bboxes = deepcopy(bboxes)
N = bboxes.shape[0] # 总的 box 的数量
indexes = np.array([np.arange(N)]) # 下标: 0, 1, 2, ..., n-1
bboxes = np.concatenate((bboxes, indexes.T), axis=1) # concatenate 之后, bboxes 的操作不会对外部变量产生影响
# 计算每个 box 的面积
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
scores = bboxes[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
for i in range(N):
# 找出 i 后面的最大 score 及其下标
pos = i + 1
if i != N - 1:
maxscore = np.max(scores[pos:], axis=0)
maxpos = np.argmax(scores[pos:], axis=0)
else:
maxscore = scores[-1]
maxpos = 0
# 如果当前 i 的得分小于后面的最大 score, 则与之交换, 确保 i 上的 score 最大
if scores[i] < maxscore:
bboxes[[i, maxpos + i + 1]] = bboxes[[maxpos + i + 1, i]]
scores[[i, maxpos + i + 1]] = scores[[maxpos + i + 1, i]]
areas[[i, maxpos + i + 1]] = areas[[maxpos + i + 1, i]]
# IoU calculate
xx1 = np.maximum(bboxes[i, 0], bboxes[pos:, 0])
yy1 = np.maximum(bboxes[i, 1], bboxes[pos:, 1])
xx2 = np.minimum(bboxes[i, 2], bboxes[pos:, 2])
yy2 = np.minimum(bboxes[i, 3], bboxes[pos:, 3])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
intersection = w * h
iou = intersection / (areas[i] + areas[pos:] - intersection)
# Three methods: 1.linear 2.gaussian 3.original NMS
if method == 1: # linear
weight = np.ones(iou.shape)
weight[iou > Nt] = weight[iou > Nt] - iou[iou > Nt]
elif method == 2: # gaussian
weight = np.exp(-(iou * iou) / sigma2)
else: # original NMS
weight = np.ones(iou.shape)
weight[iou > Nt] = 0
scores[pos:] = weight * scores[pos:]
# select the boxes and keep the corresponding indexes
inds = bboxes[:, 5][scores > score_thresh]
keep = inds.astype(int)
return res_bboxes[keep]
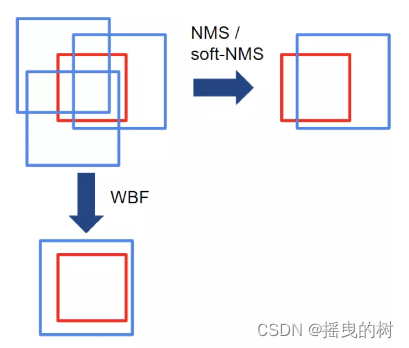
4 WBF(weighted boxes fusion)
加权框融合:假设,我们已经绑定了来自N个不同模型的相同图像的框预测。或者,我们对相同图像的原始和增强版本(即垂直/水平反射,数据增强)有相同模型的N个预测)。
- 每个模型的每个预测框都添加到List B,并将此列表按置信度得分C降序排列
- 建立空List L 和 F(用于融合的)
- 循环遍历B,并在F中找到于之匹配的box(同一类别MIOU > 0.55)
- 如果 step3 中没有找到匹配的box 就将这个框加到L和F的尾部
- 如果 step3 中找到了匹配的box 就将这个框加到L,加入的位置是box在F中匹配框的Index.L中每个位置可能有多个框,需要根据这多个框更新对应F[index]的值。
- F[index]更新方法:x,y对应的是坐标值,对坐标值根据置信值进行加权求和如下图:

NMS/Soft-NMS将只留下一个不准确的框,而WBF将使用所有预测的框来融合它。
三、轨道交通
1 ATC 列车自动控制系统
城市轨道交通信号系统通常由列车自动控制系(Automatic Train Control,简称ATC)组成,ATC 系统包括三个子系统:
(1)列车自动监控系统 (Automatic Train Supervision,简称ATS)
(2)列车自动防护子系统(Automatic Train Protection,简称ATP)
(3)列车自动运行系统 (Automatic Train Operation,简称ATO)
三个子系统通过信息交换网络构成闭环系统,实现地面控制与车上控制结合、现地控制与中央控制结合,构成一个以安全设备为基础,集行车指挥、运行调整以及列车驾驶自动化等功能为一体的列车自动控制系统。
2 ATS 列车自动监控系统
列车自动监控系统 (Automatic Train Supervision,简称ATS)
3 ATP 列车自动防护子系统
列车自动防护子系统(Automatic Train Protection,简称ATP)
4 ATO 列车自动运行系统
列车自动运行系统 (Automatic Train Operation,简称ATO)
![[附源码]Python计算机毕业设计Django考试系统](https://img-blog.csdnimg.cn/a37ed9a3197a4395b6724029aa19f0d6.png)