一、数据库的存储结构:页
1.磁盘与内存的交互基本单位:页
InnoDB将表中数据划分多个页来存储,InnoDB中页的大小默认是16KB
在数据库中,不论读一行,还是读多行,都是将这些行所在的页从磁盘加载到内存。数据库管理存储空间的单位是页,数据库I/O操作的最小单位是页。一个页可以存储多个行记录。数据库的读取是以页为单位。

2.页结构概述
页a,页b,页c这些页是双向链表连接,逻辑上是连续的。每个数据页根据页中记录按照主键值从小到大顺序组成单链表,每个数据页会为记录生成页目录,在通过主键查找记录的时候在页目录使用二分法快速定位对应的槽,然后遍历该槽对应分组的记录
3.页的大小
在MySQL数据库中,页的大小是16KB
mysql> show variables like '%innodb_page_size%';4.页的上层结构
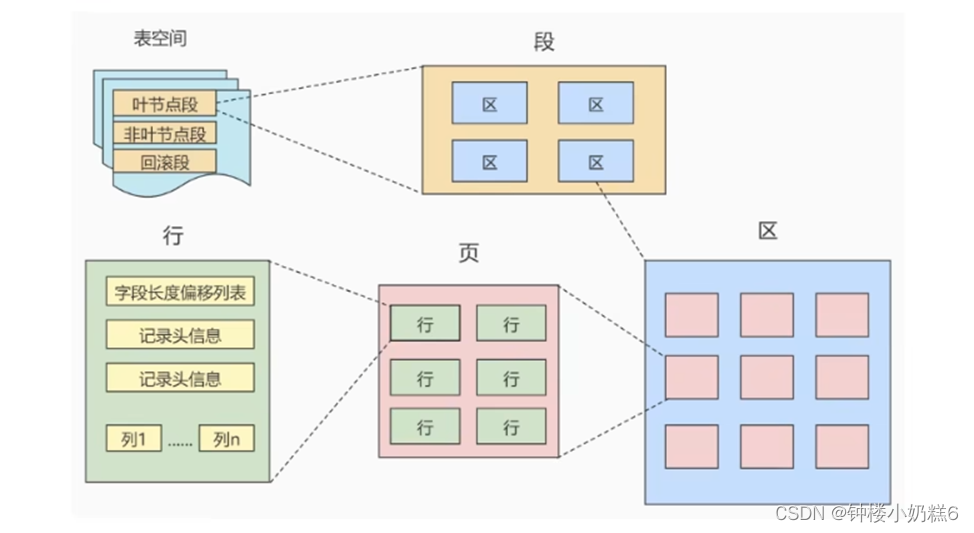
①区:页的上层结构是区,一个区分配64个连续的页。64*16=1024KB=1M
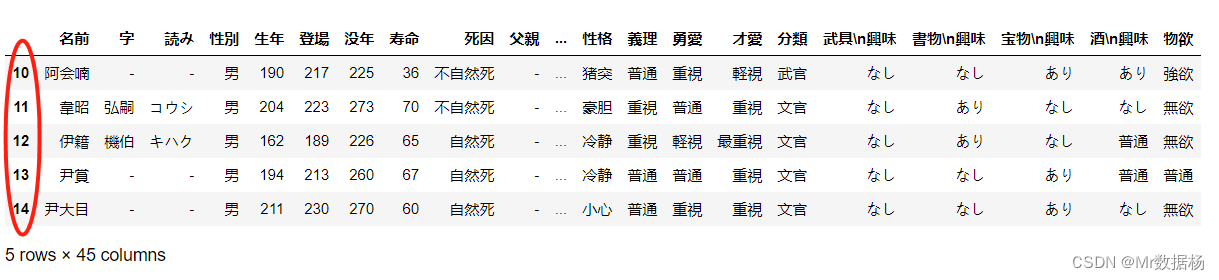
②段:有一个或多个区组成。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。
③表空间:是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
二、页的内部结构
1.页的概念
页按照类型划分,常见是数据页(B+树),系统页,Undo页和事务数据页。
数据页的16kb的存储空间的划分:

各部分的作用:

2.第1部分:文件头和文件尾
①文件头作用
描述各种页的通用信息,比如页的编号,上一页,下一页
②文件头的结构

FIL_PAGE_OFFSET
存放页号的
FIL_PAGE_TYPE
当前页的类型
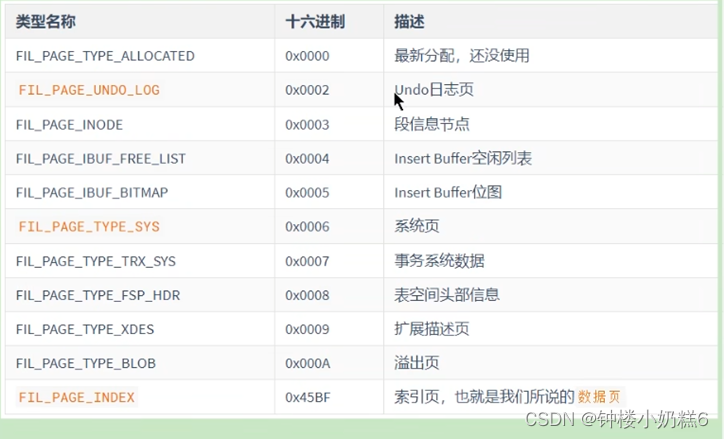
FIL_PAGE_PREV和FIL_PAGE_NEXT
上一页的页号,下一页的页号
FIL_PAGE_SPACE_OR_CHKSUM
代表校验和
为了检测修改后的页是否完整(断电了,可能页不完整)。每当一个页在内存中修改,同步之前就把它的校验和计算出来。开始先写入文件头的校验和,当完全写完了,最后会写入文件尾的校验和。比较文件头和文件尾的校验和,如果两个相等,那么同步成功。不相等说明同步中间出错(有记录,继续刷盘。没有记录,回滚)。校验方式就是采用Hash 算法进行校验。
FIL_PAGE_LSN
页面修改时的日志文件。
③文件尾的结构
校验和+LSN页面修改时的日志文件
3.第2部分:空闲空间,用户记录,最大最小记录

空闲空间
每当插入一条记录,都会从空闲空间部分申请一个空间存储用户记录。当空闲空间没有了,意味着页满了,新记录的插入需要新的页了。
用户记录
将用户数据按照指定的行格式一条一条存储在用户记录部分,相互之间是单链表。记录头信息
用户记录的单链表的形成:(记录头信息)Compact
①创建表
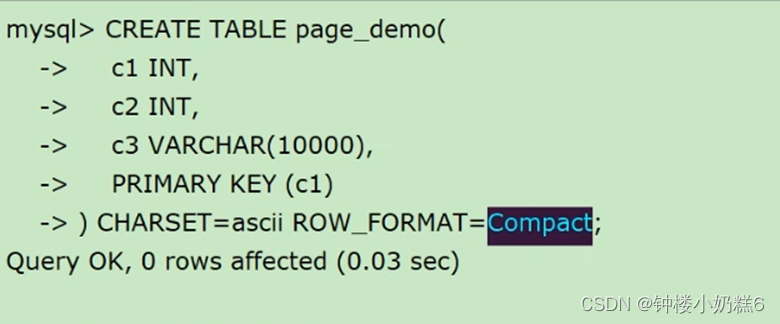
②表中记录的行格式

③记录头信息的属性

④插入数据
'
图示

⑤记录头信息属性讲解
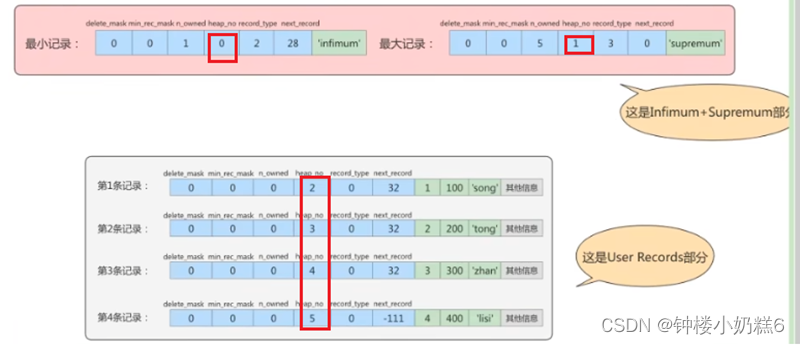
delete_mash:0代表没删除,1代表删除。删除的信息实际上还在磁盘,只是打上一个删除标记。因为移除需要重新排列,导致性能下降。但是新插入的记录可以占用此空间。
min_rec_mask:非叶子节点(目录项的页)最小的主键值记录是1。
record_type:0是用户记录,1是目录项记录,2最小记录,3最大记录
heap_no:当前记录本页的位置。heap_no是0最小记录的,heap_no是1最大记录。所以从2开始
n_owned:页目录每个组多少条记录
next_record:指向的下一条记录,单链表(真实记录的地址偏移量)第一条记录的next_record值为32,意味着从第一条记录的真实数据的地址处向后找32个字节便是下一条记录的真实数据
最小最大记录
比较的主键的大小,这两条记录不是我们自己定义的记录
4.第3部分:页目录,页面头部
页目录
①为什么需要页目录?
在页中,记录是单链表存储的,单链表的特点是插入,删除效率高。但是查找效率低,最差的情况是遍历链表所有的节点才能完成查找。所以,在页中设计了页目录(存储主键的数组),专门给记录做了一个目录,二分查找进行查找,提高效率。
②根据主键值查找页中的某条记录,如何实现快速查找?
通过页目录查找(页目录存放的是把记录分好组的最大主键值,分组为了减少存储空间)
实现:先把记录(删除的除外)分好组,第1组是最小记录分组,最后一组是最大记录分组,中间其余的组4-8条记录。组中最后一个记录头信息n_owned记录组中的多少条记录。页目录存储的是每组最后一条记录的地址偏移量,存放到slot槽中。
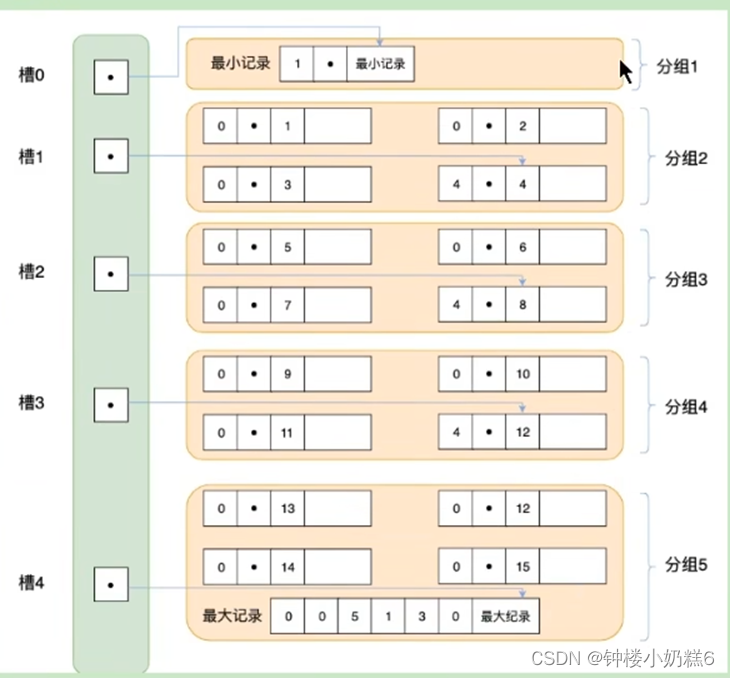
也就是:通过二分法定位记录所在的槽,找到槽所在分组主键最小的那条记录。
通过记录的next_record属性遍历该槽所在组的各个记录。
页头PageHeader
记录数据页存储记录的状态信息:本页存储了多少记录,多少个槽。

5.从数据页角度看B+树如何查询?
B+树按照节点类型:
叶子节点,B+树最底层节点,节点高度0,存储行记录
非叶子节点:存储索引和页面指针

问题1:树是如何进行数据检索的?
先从B+树的根开始,逐层检索。直到找到叶子节点,把对应的数据页加载到内存,通过对页目录进行二分查找记录所在的组,然后在分组中通过链表遍历方式查找记录。
问题2:普通索引和唯一索引有什么不同
普通索引和唯一索引在检索效率上基本没有区别。唯一索引是关键字没有重复的,找到了关键字就停止检索。普通索引的关键字可以重复,但是读取一条记录当把这个记录所在的页加载到内存,一个页存在上千条记录,普通索引多判断下一条记录的操作。普通索引和唯一索引在检索效率上基本没有区别。