介绍几篇改进Transformer模型实现亮度增强、图像重建的任务:LLFormer(AAAI2023),DLSN(TPAMI2023),CAT(NeurIPS2022)。
Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method, AAAI2023
Project:UHD-LOL and LLFormer (taowangzj.github.io)
解读:【AAAI2023】Ultra-High-Definition Low-Light Image Enhancement - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2212.11548
代码:https://github.com/TaoWangzj/LLFormer
介绍
设备捕捉超高清(UHD)图像和视频的能力对图像处理管道提出了新的要求。
本文考虑了低光亮图像增强(LLIE)的任务,构建了两种不同分辨率的数据集Ultra-High-Definition Low-Light Image Enhancement(UHD-LOL),并在不同方法进行基准测试。
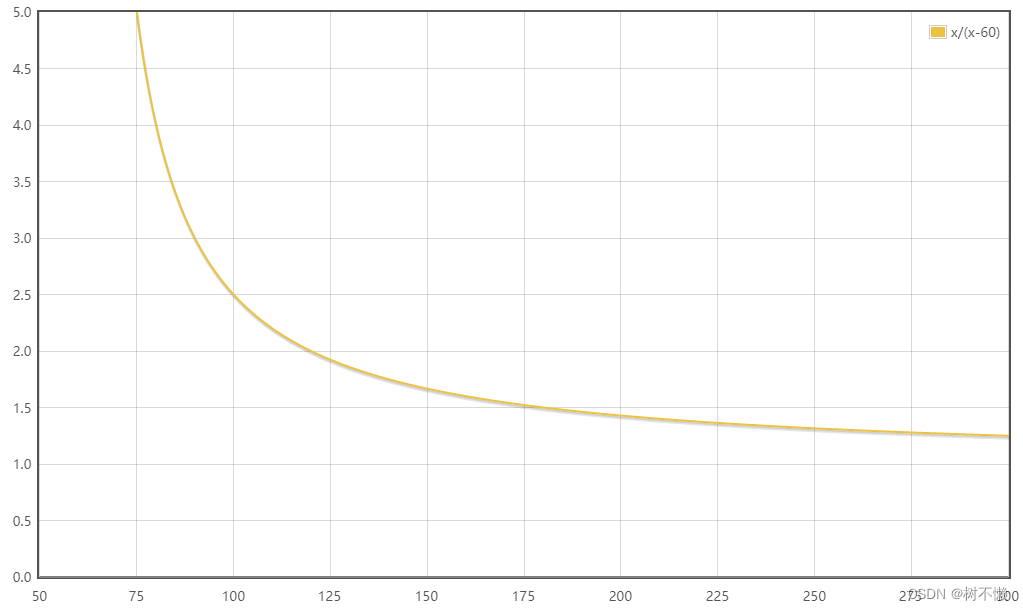
提出一种基于Transformer的微光增强方法LLFormer。LLFormer的核心组件是基于轴的多头自注意和跨层注意融合块,显著降低了线性复杂度。
LLFormer 框架
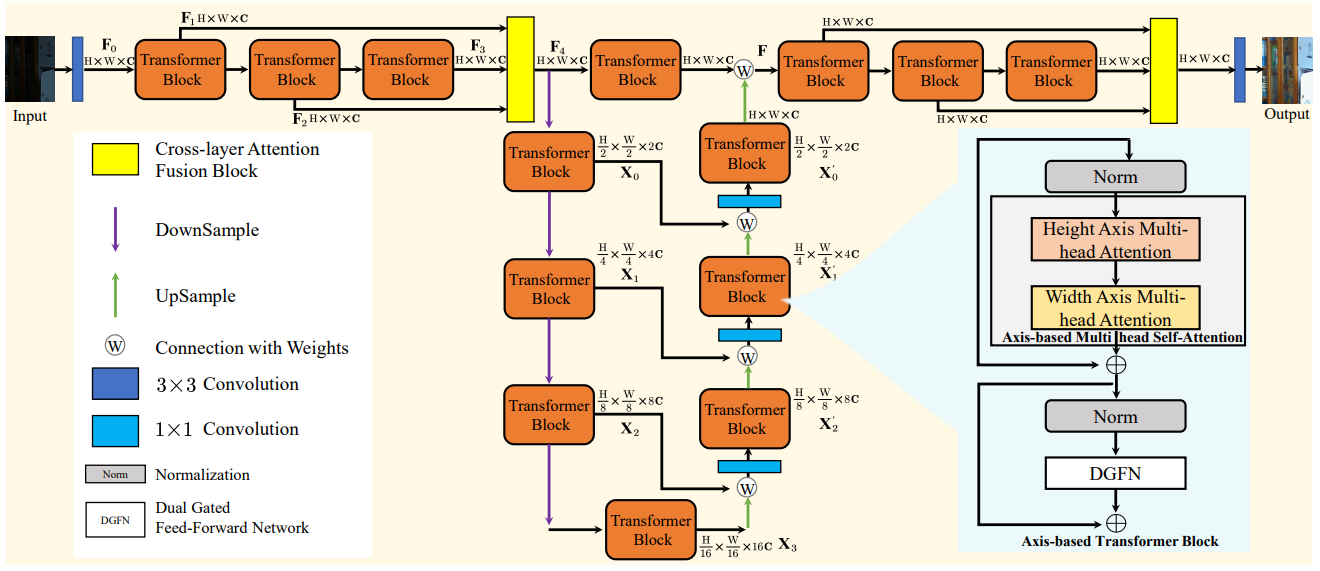
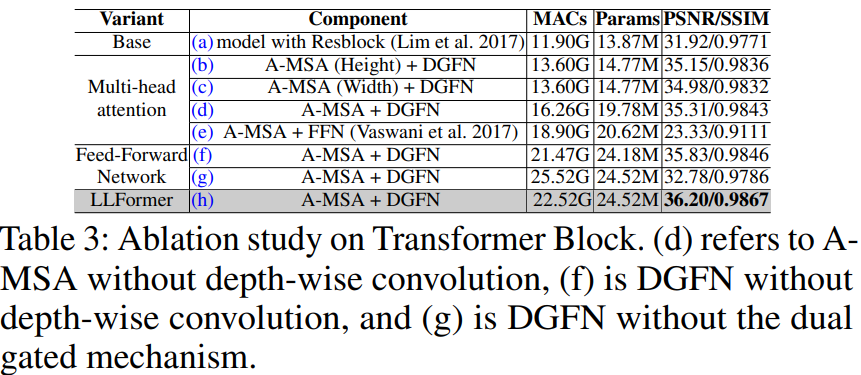
 LLFormer的核心设计包括一个基于轴的变压器块和一个跨层注意力融合块。在前者中,基于轴的多头自注意在通道维度上依次对高度和宽度轴进行自注意,以降低计算复杂度,而双门控前馈网络采用门控机制来更多地关注有用的特征。跨层注意力融合块在融合不同层中的特征时学习它们的注意力权重。
LLFormer的核心设计包括一个基于轴的变压器块和一个跨层注意力融合块。在前者中,基于轴的多头自注意在通道维度上依次对高度和宽度轴进行自注意,以降低计算复杂度,而双门控前馈网络采用门控机制来更多地关注有用的特征。跨层注意力融合块在融合不同层中的特征时学习它们的注意力权重。
Axis-based Transformer Block & Dual Gated Feed-forward Network(GDFN)
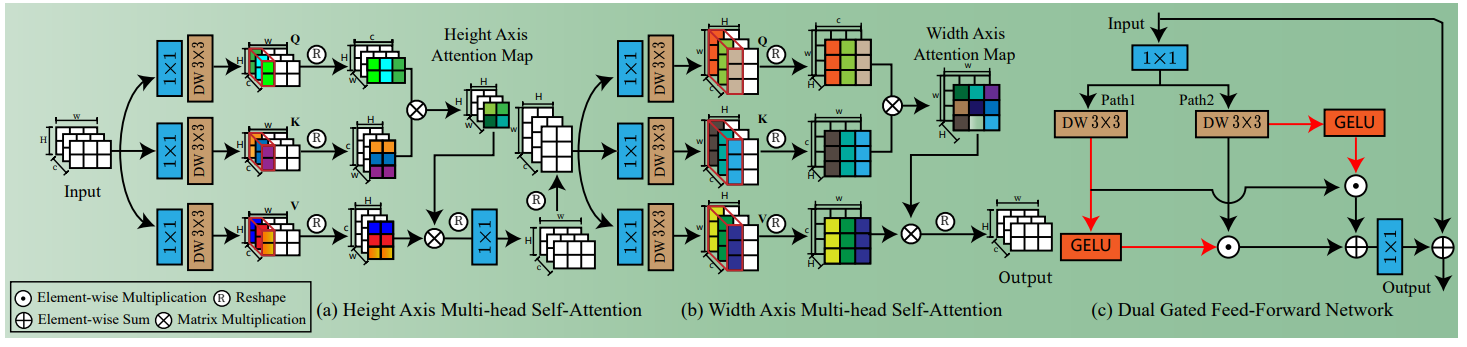

Transformer 在图像修复中应用的难点在于计算复杂度高。论文使用基于轴的多头注意力。分两个步骤,第一步相似性计算的是HxH,叫做 height-axis attention。第二步相似性计算的是 WxW,叫做 width-axis attention。
随后在FFN中引入双门控机制,提出双门控前馈网络DGCN来捕获特征中的更重要的信息。FFN两个分支都使用 GELU 激活,再互相给另外一个分支添加门控增强非线性建模能力。
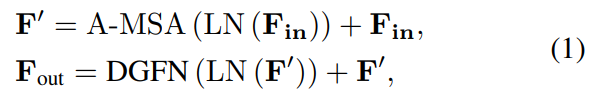
其中,DGFN公式如下:
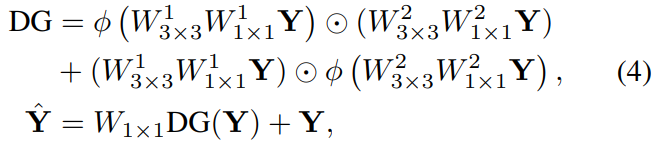
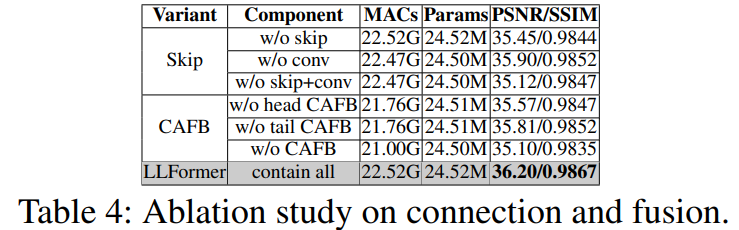
Cross-layer Attention Fusion Block
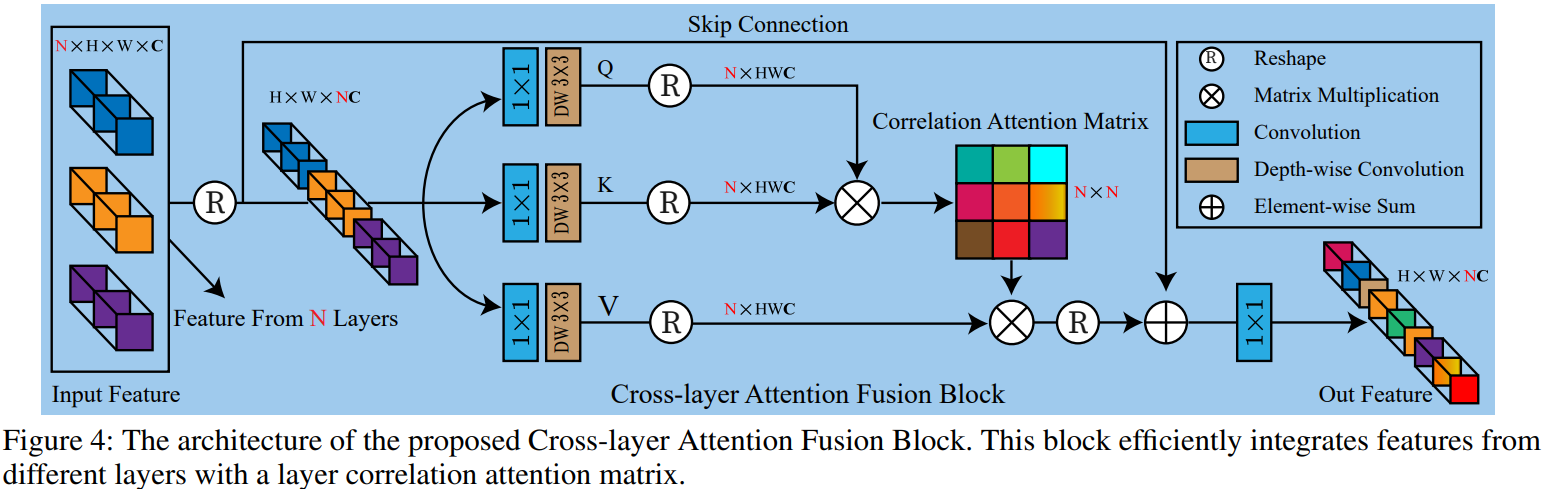
网络一般有多层,但大多方法没有考虑层与层之间特征的关联,限制了表示能力。论文使用cross-layer attention获取不同层特征间的相关性并融合。从论文整体架构图中可看到,网络输入有三个Transformer block,能得到三个特征输出。论文通过cross-layer attention 运算,计算一个3x3的相似性矩阵,给输入的特征进行加权,从而达到强调重要特征、抑制不重要特征的作用。(不同层的激活是对特定类别的响应,并且可以使用子注意力机制自适应地学习特征相关性。)
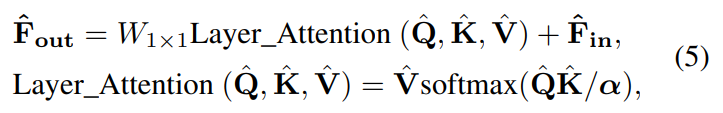
实验
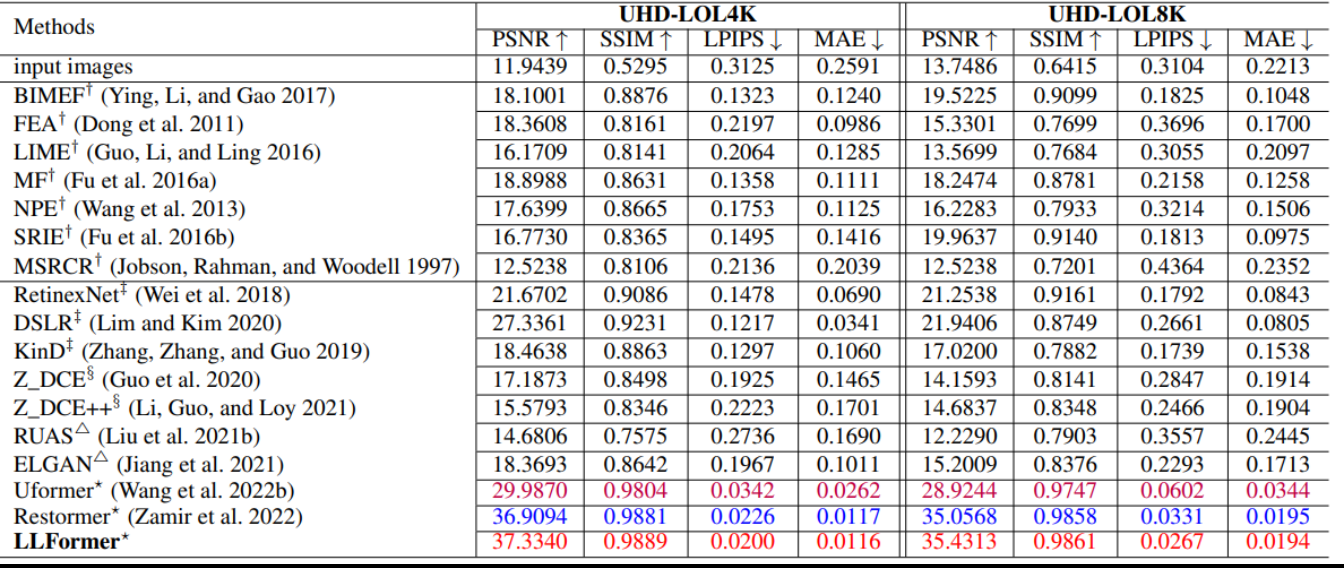
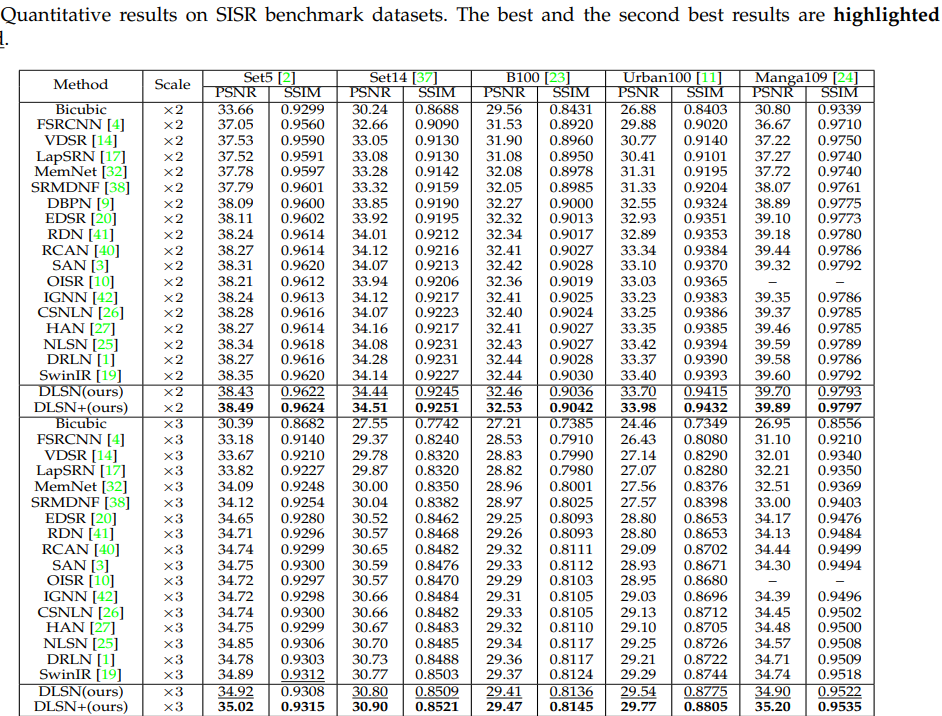
现有方法在所提出的UHD-LOL数据集的性能测试实验。

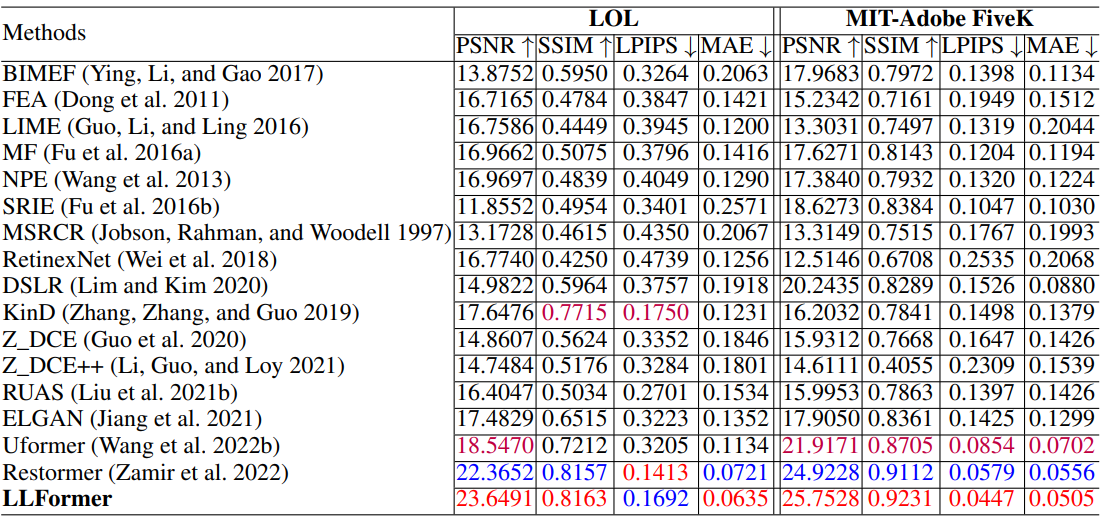


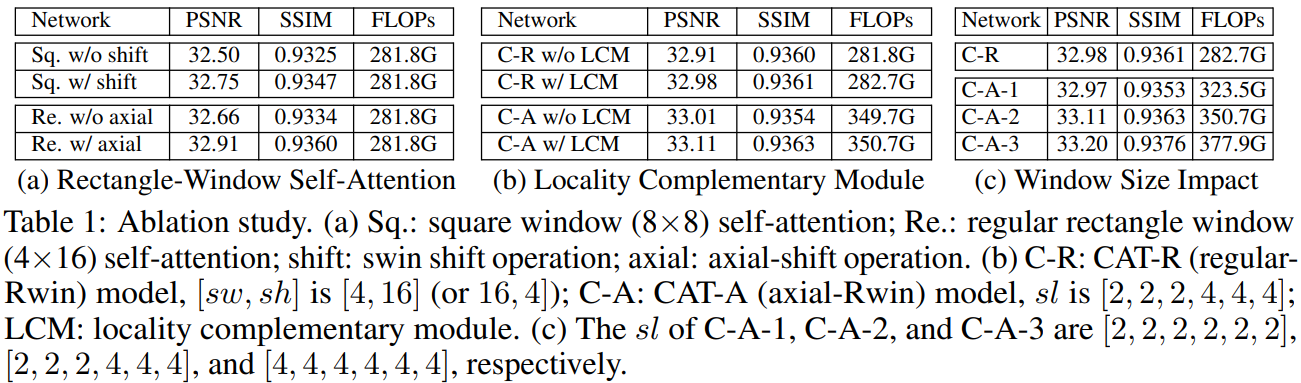
消融实验:
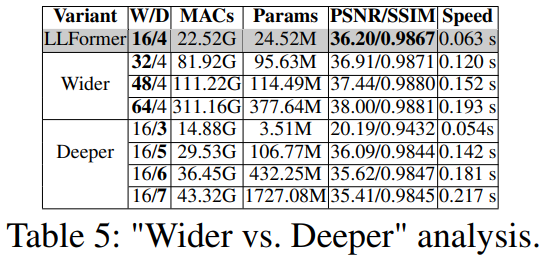
UHD-LOL数据集
The UHD-LOL4K subset consists of 8099 paired 4K images, and 5999 for training and 2100 for testing.
| Name | Size | Type | Links | Description |
|---|---|---|---|---|
| UHD-4K | 94.9 G | 百度网盘 | Main folder | |
| ├ Train Set | 25.2 G | normal/low | - | 8099 paired normal/low-light 8K images. |
| ├ Test Set | 69.7 G | normal/low | - | 2100 paired normal/low-light 8K images. |
The UHD-LOL8K subset consists of 2966 paired 8K images, and 2029 for training and 937 for testing.
| Name | Size | Type | Links | Description |
|---|---|---|---|---|
| UHD-8K | 97.8 G | 百度网盘 | Main folder | |
| ├ Train Set | 67.3 G | normal/low | - | 2029 paired normal/low-light 8K images. |
| ├ Test Set | 30.5 G | normal/low | - | 937 paired normal/low-light 8K images. |


Global Learnable Attention for Single Image Super-Resolution, TPAMI2023
解读:【TPAMI2023】Global Learnable Attention for Single Image Super-Resolution_AI前沿理论组@OUC的博客-CSDN博客
论文:https://arxiv.org/abs/2212.01057
代码:https://github.com/laoyangui/DLSN
介绍
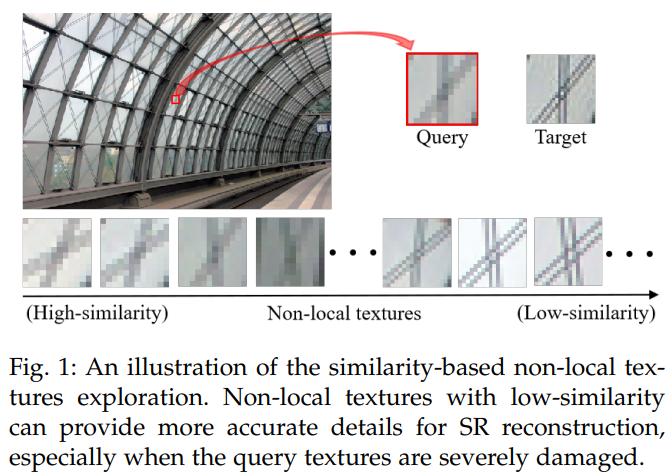
自相似性对于单图像超分辨率(SISR)中非局部纹理的探索具有重要意义。研究人员通常认为非局部纹理的重要性与其相似性得分呈正相关。本文发现,在修复严重受损的查询纹理时,一些相似度较低、更接近目标的非局部纹理可以提供比高相似度纹理更准确、更丰富的细节。在这些情况下,低相似性并不意味着较差,而是通常由不同的尺度或方向引起的。利用这一发现,本文提出了一种全局可学习注意力(GLA),以在训练过程中自适应地修改非局部纹理的相似性得分,而不是仅使用固定的相似性评分函数(如点积)。所提出的GLA可以探索相似度较低但细节更准确的非局部纹理,以修复严重受损的纹理。此外,采用超比特位置敏感哈希(SB-LSH)作为GLA的预处理方法,减少其计算复杂度。基于GLA,论文提出了一个可深度学习的相似性网络(DLSN)。
当前方法大多使用 non-local attention 来计算图像块之间的相似性,而且认为与query更为相似的图像块能够提供更丰富的信息,但是作者认为并不总是这样。如下图所示, 当query严重损坏时,查询到高相似度的图像块就不能提供有效的重建信息,但是低相似度的图像块却能提供丰富的信息。
DLSN网络
为了解决上面的问题,作者提出了一个 Global Learnable Attention 模块。GLA可以动态的调整特征间的相似性,同时因为使用了Locality-Sensitive Hashing,降低了计算的复杂度。

DLSN由带有基于全局可学习注意力的特征融合模块(GLAFFM)的骨干组成。对于SISR任务,有两种信息对提高重建结果至关重要:局部邻接信息和可学习的非局部自相似信息。
GLAFFM用于融合分别由局部特征融合块(LFFB)和全局可学习注意力(GLA)捕获的这两种类型的关键信息。
GLAFFM是DLSN的基本模块。具体地说,每个GLAFFM也具有残差架构,并且由局部特征融合块(LFFB)、全局可学习注意力(GLA)和特征细化转化层组成。LFFB负责捕捉局部感应偏差,而GLA则在探索全局信息。
LFFB利用卷积的局部性来捕获自然图像的局部信息。LFFB是SR重建的基石,它是通过堆叠n个简化的残差块而形成的。
GLA可以通过从输入特征图中总结相关特征来探索全局信息。
算法流程:

实验


使用LSS的时候,能够动态的找到真正具有相似纹理以及信息比较强的区域。


Cross Aggregation Transformer for Image Restoration, NeurIPS2022
解读:【NeurIPS2022】Cross Aggregation Transformer for Image Restoration - 知乎 (zhihu.com)
[NIPS 2022-图像复原]Cross Aggregation Transformer for Image Restoration - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2211.13654
代码:https://github.com/zhengchen1999/CAT
介绍
Transformer架构被引入到图像复原领域并取得了很好的结果,考虑到transformer全局注意力需要很高的计算复杂度,一些方法尝试使用局部方窗口来限制自注意力计算的范围(Uformer, SwinIR)。但是,这些方法缺少不同窗口之间的直接交互,从而限制了远程依赖的建立。为此,本文提出一种新的图像复原模型-交叉聚合transformer(cross aggregation transformer (CAT))。CAT的核心为Rectangle-window self-attention (Rwin-SA),它利用不同头部的水平和垂直矩形窗口注意力来并行扩展注意力区域并聚合不同窗口的特征。此外,本文还引入轴向移位操作(axial-shift operation)实现不同窗口交互。另外,提出局部补充模块(locality complementary module)来补充注意力机制,将CNN的平移不变性和局部性的归纳偏差合并到transformer中,从而实现全局-局部耦合。
CAT架构
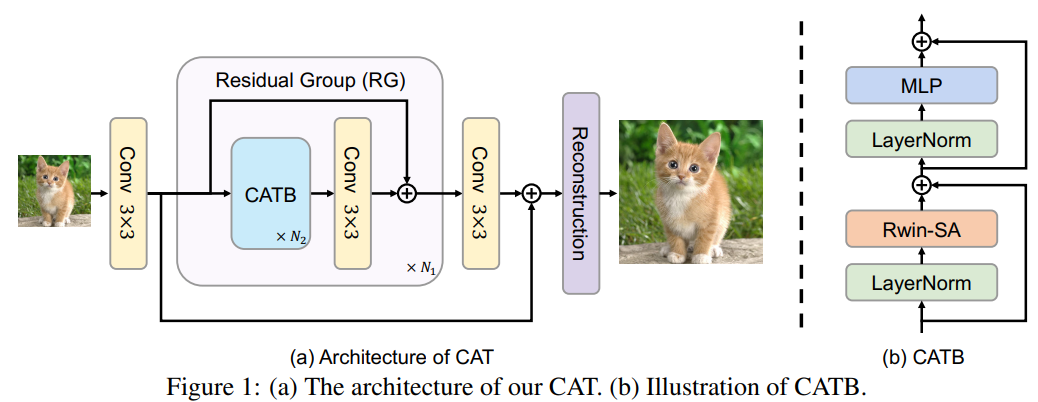
CAT由三个模块组成:浅层特征提取、深层特征提取和重建部分。它用残差通道注意力网络(RCAN)作为主干,并用 cross aggregation Transformer block(CATB)替换了RCAN中提出的residual channel attention block(RCAB)。
Cross Aggregation Transformer Block(CATB)
交叉聚合Transformer块(CATB)采用了一种新的注意机制,具有三种新颖的设计:矩形窗口自注意Rectangle-Window Self-Attention、轴向移动操作 Axial-Shift Operation 和局部互补模块Locality Complementary Module。
Rectangle-Window Self-Attention
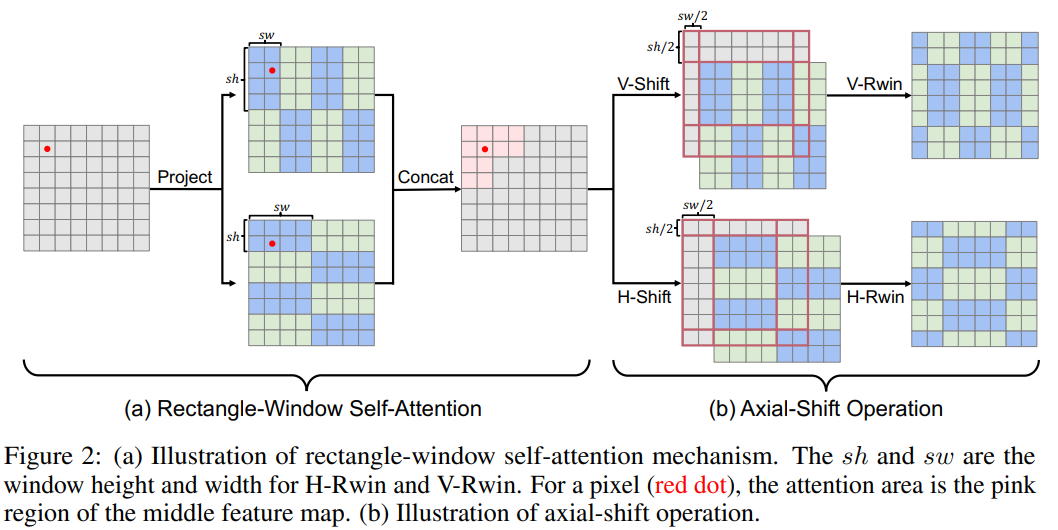
矩形窗口自注意力(Rwin SA)。Rwin SA使用矩形窗口(sh≠sw)而不是方形窗口(sℎ=sw ,其中sh和sw表示矩形的高度和宽度)。此外,作者将矩形窗口分为水平窗口( sℎ<sw ,表示为H-Rwin)和垂直窗口( sℎ>sw,标记为V-Rwin),并将它们并行应用于不同的注意力头。
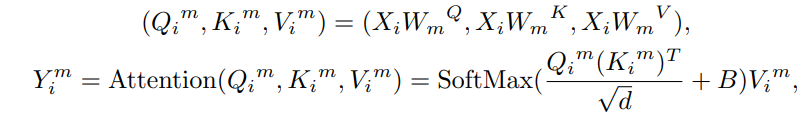
将M个head分为两部分,分别计算H-Rwin和V-Rwin; 最后,两个部分的输出沿通道维度拼接。
![]()
通过H-Rwin和V-Rwin,可以在不增加计算复杂性的情况下跨不同窗口聚集特征并扩展感受野。此外,矩形窗口可以捕获每个像素在水平和垂直方向上的不同特征,这对于正方形窗口来说很难用可比的计算资源来处理。
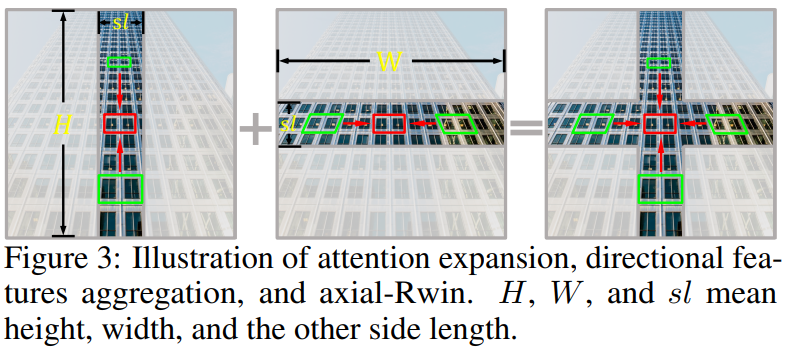
Axial-Shift Operation
如图2(b)所示,轴向位移包括两种位移操作,水平位移称为H-shift,垂直位移称为V-shift,分别对应于H-Rwin和V-Rwin。轴向移动操作将窗口分区向下和向左移动 sℎ/2 和sw/2 像素,其中 sℎ 和 sw 是H-Rwin和V-Rwin的窗口高度和宽度。在实现中,循环地将特征图移到左下方向。然后在相应的移位特征图上执行H-Rwin和V-Rwin。
Locality Complementary Module
为了用局部性补充Transformer并实现全局和局部耦合,作者在计算自注意力时添加了一个独立的卷积运算,称为局部性补充模块。
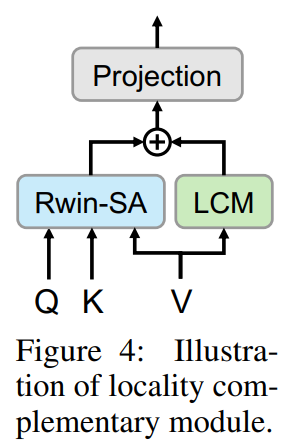
![]()
与顺序执行卷积或在X上使用卷积相比,此操作有两个优点:(1)使用卷积作为并行模块允许Transformer块自适应地选择采用注意力或卷积操作,这比顺序执行更灵活;(2) 自注意力可以被视为一个依赖于内容的动态权重,作用于V。卷积运算相当于一个可学习的静态权重。因此,在与注意力操作相同的特征域中对V进行卷积操作。
实验
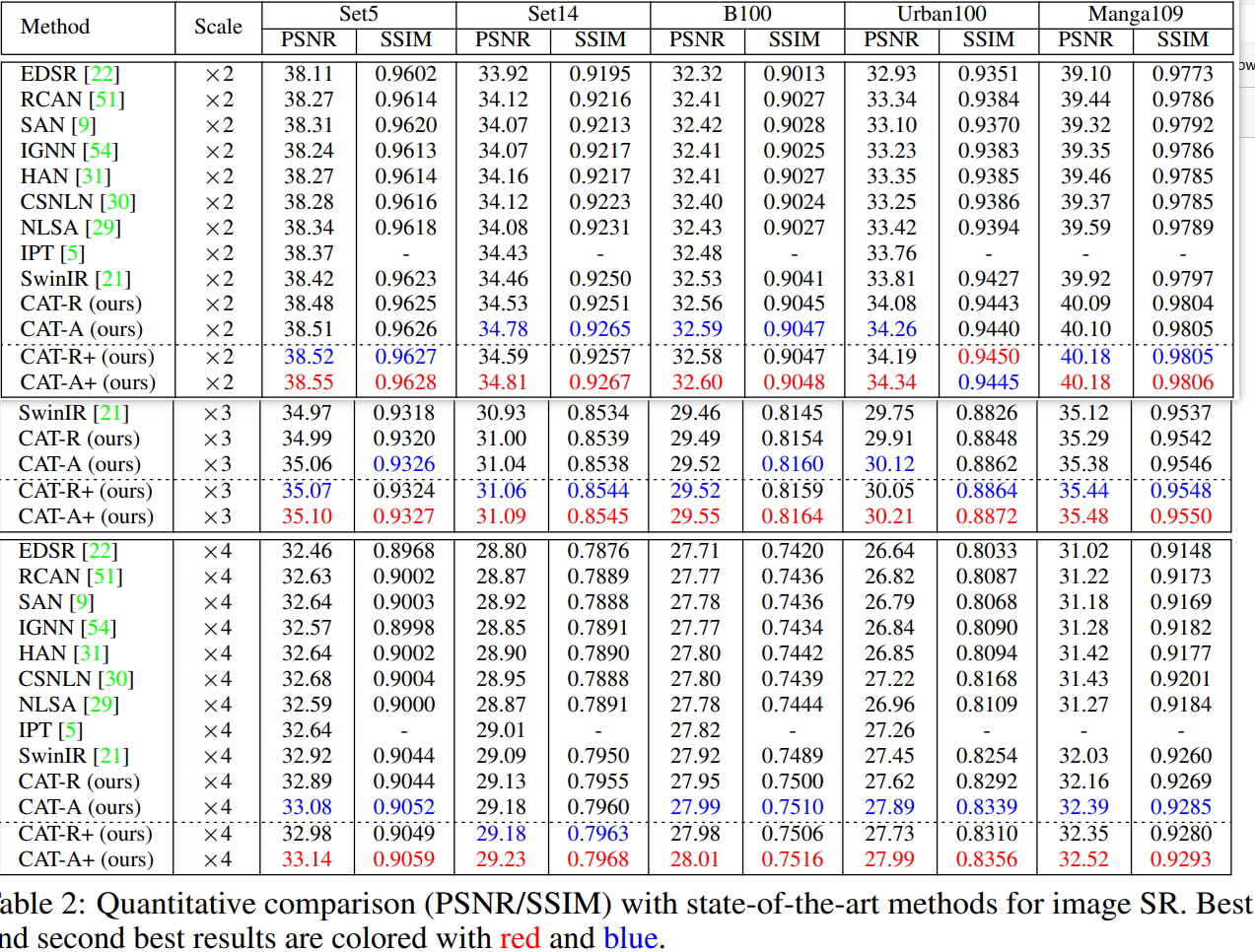
图像超分:

压缩伪影去除:

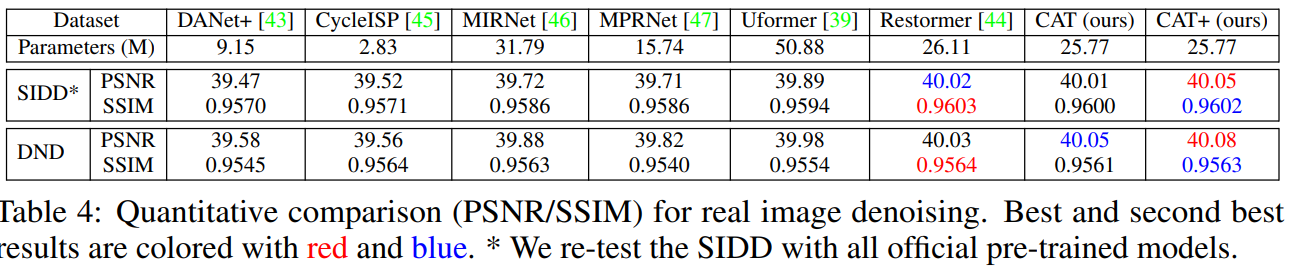
真实图像去噪: