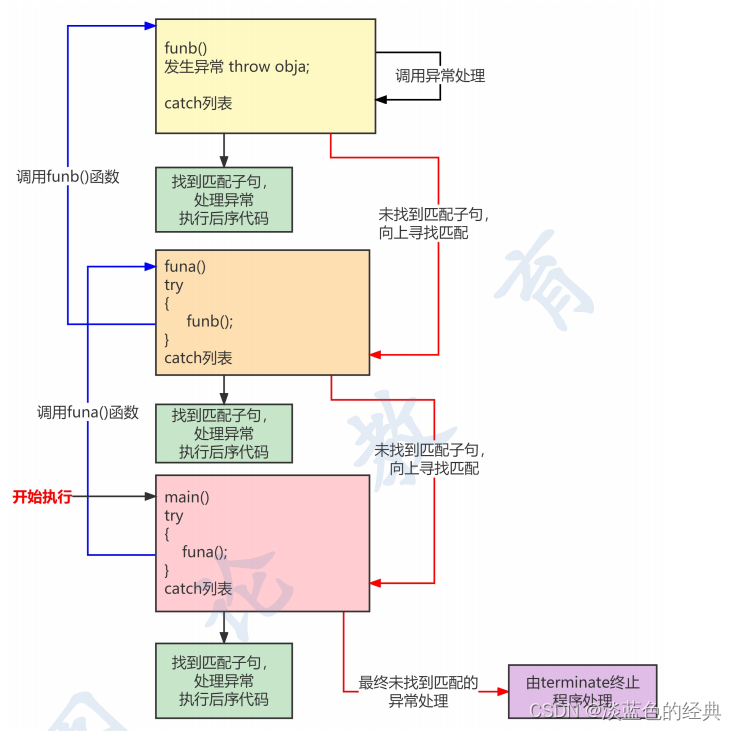
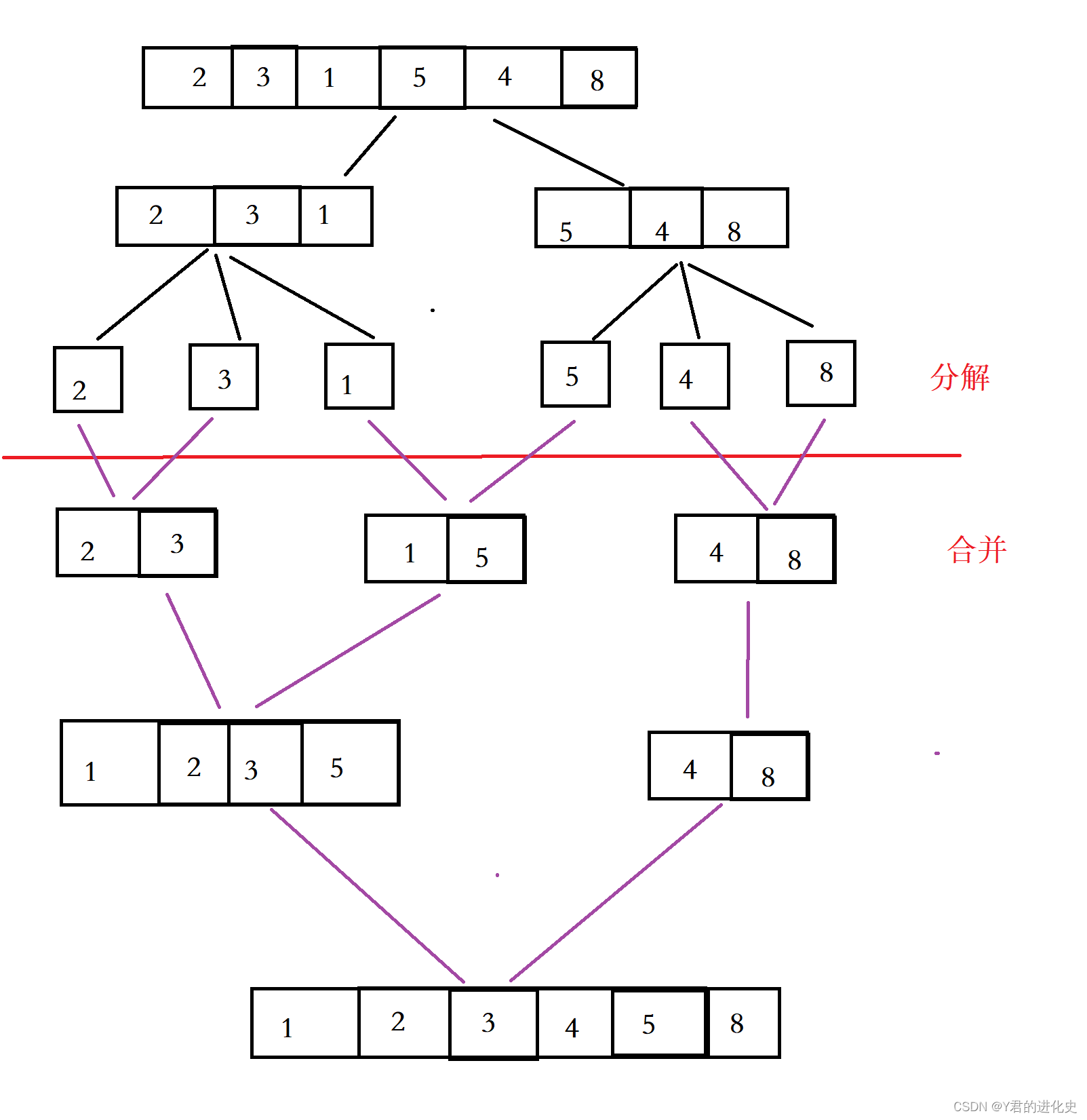
一般形式:
θ
=
∫
a
b
f
(
x
)
d
x
=
∫
a
b
f
(
x
)
p
(
x
)
p
(
x
)
d
x
≈
1
n
∑
i
=
1
n
f
(
x
i
)
p
(
x
i
)
\theta=\int_a^b{f(x)dx}=\int_a^b{\frac{f(x)}{p(x)}p(x)dx}\approx\frac{1}{n}\sum_{i=1}^{n}\frac{f(x_i)}{p(x_i)}
θ=∫abf(x)dx=∫abp(x)f(x)p(x)dx≈n1i=1∑np(xi)f(xi)
p
(
x
)
p(x)
p(x)为
x
x
x的概率密度,
p
(
x
i
)
p(x_i)
p(xi)为从
x
x
x的概率分布
p
(
x
i
)
p(x_i)
p(xi)中随机采样得到的第
i
i
i个样本,然而,当
p
(
x
)
p(x)
p(x)是一个比较复杂的概率密度时,从
p
(
x
)
p(x)
p(x)中随机采样并不容易,那么我们现在的问题就转化为了"如何采样出
x
x
x的分布
p
(
x
)
p(x)
p(x)对应的若干个样本"
重点强调一下,我们所说的采样指的是对
x
x
x采样,而
p
(
x
)
p(x)
p(x)是
x
x
x的概率密度,影响每一个
x
x
x被采样到的概率。
概率分布采样
虽然对于复杂分布
p
(
x
)
p(x)
p(x)而言,采样是一件困难的事情,但在计算机中, 得到一个均匀分布
U
(
0
,
1
)
U(0,1)
U(0,1)上的随机数是很简单的, 因此,我们自然而然的会想要通过这个简单的均匀分布来解决我们的问题。
离散型随机变量情形
我们这里用
θ
\theta
θ表示服从
U
(
0
,
1
)
U(0,1)
U(0,1)的随机变量. 现在我们就探讨如何通过对服从
U
(
0
,
1
)
U(0,1)
U(0,1)的随机变量
θ
\theta
θ采样,来得到我们想要的服从其它离散分布的随机变量
X
X
X的样本.
设有一个离散型随机变量
X
∼
(
x
1
x
2
⋯
x
n
p
1
p
2
⋯
p
n
)
X\sim\left( \begin{array}{ccc} x_1&x_2&\cdots&x_n\\ p_1&p_2&\cdots&p_n \end{array} \right)
X∼(x1p1x2p2⋯⋯xnpn),
X
X
X与
θ
\theta
θ之间存在如下映射关系
X
=
G
(
θ
)
X=G(\theta)
X=G(θ)
由于
θ
\theta
θ恰好服从
U
(
0
,
1
)
U(0,1)
U(0,1),因此,我们只需要将
θ
\theta
θ依概率映射到 样本空间
X
X
X中每个值即可,即
X
=
G
(
θ
)
=
{
x
1
0
≤
θ
<
p
1
x
2
p
1
≤
θ
<
p
1
+
p
2
⋯
⋯
x
n
∑
1
n
−
1
p
i
≤
θ
<
1
X=G(\theta)=\left\{ \begin{array}{c} x_1&0\le\theta<p_1 \\ x_2 &p_1\le\theta<p_1+p_2 \\ \cdots &\cdots\\ x_{n} &\sum_1^{n-1}p_i\le\theta<1 \\ \end{array} \right.
X=G(θ)=⎩⎨⎧x1x2⋯xn0≤θ<p1p1≤θ<p1+p2⋯∑1n−1pi≤θ<1 其实可以将右边的不等式看作累积分布概率作用下的结果,比如第二行
p
1
≤
θ
<
p
1
+
p
2
p_1\le\theta<p_1+p_2
p1≤θ<p1+p2,其实它区间的长度就等于
p
2
+
p
1
−
p
1
=
p
2
p_2+p_1-p_1=p_2
p2+p1−p1=p2,也就是
x
2
x_2
x2对应的概率
p
2
p_2
p2
这样就实现了在离散型随机变量的情形之下,找到了服从
U
(
0
,
1
)
U(0,1)
U(0,1)的随机变量
θ
\theta
θ与
X
X
X之间的映射关系
G
G
G,也就可以通过对
θ
\theta
θ采样的结果转化为对
X
X
X的采样结果
设有一个连续型随机变量
X
X
X,其概率密度为
f
(
x
)
f(x)
f(x),累积分布函数为
F
(
x
)
F(x)
F(x),
X
X
X与
θ
\theta
θ之间存在如下映射关系
X
=
G
(
θ
)
X=G(\theta)
X=G(θ)
由累积分布函数的定义可得
P
{
X
<
a
}
=
F
(
a
)
P\{X<a\}=F(a)
P{X<a}=F(a)将
X
=
G
(
θ
)
X=G(\theta)
X=G(θ)代入可得
P
{
G
(
θ
)
<
a
}
=
F
(
a
)
P\{G(\theta)<a\}=F(a)
P{G(θ)<a}=F(a)
由累积分布函数的性质可得,
F
(
x
)
F(x)
F(x)为一个单调递增函数,因此,对不等式两边同时取
G
G
G的反函数可得
P
{
θ
<
G
−
1
(
a
)
}
=
F
(
a
)
P\{\theta<G^{-1}(a)\}=F(a)
P{θ<G−1(a)}=F(a)
又已知
θ
\theta
θ服从
U
(
0
,
1
)
U(0,1)
U(0,1),因此有
P
{
θ
<
b
}
=
b
,
b
∈
[
0
,
1
]
P\{\theta<b\}=b,b\in[0,1]
P{θ<b}=b,b∈[0,1]
令
b
=
G
−
1
(
a
)
b=G^{-1}(a)
b=G−1(a)可得
P
{
θ
<
G
−
1
(
a
)
}
=
G
−
1
(
a
)
P\{\theta<G^{-1}(a)\}=G^{-1}(a)
P{θ<G−1(a)}=G−1(a)
又因为刚才证得
P
{
θ
<
G
−
1
(
a
)
}
=
F
(
a
)
P\{\theta<G^{-1}(a)\}=F(a)
P{θ<G−1(a)}=F(a),所以有
F
(
a
)
=
G
−
1
(
a
)
F(a)=G^{-1}(a)
F(a)=G−1(a)
因此
G
(
a
)
=
F
−
1
(
a
)
G(a)=F^{-1}(a)
G(a)=F−1(a)
所以
X
=
G
(
θ
)
=
F
−
1
(
θ
)
X=G(\theta)=F^{-1}(\theta)
X=G(θ)=F−1(θ)
根据以上结论,我们可以得出在连续型随机变量的情形下,
θ
\theta
θ与随机变量
X
X
X的映射关系就是
x
x
x的累积分布函数的反函数
接收—拒绝采样
刚刚介绍了概率分布采样方法,对于连续型随机变量的情形而言,我们可以通过使用随机变量
X
X
X的的累积分布函数的反函数,也就是如下式子
X
=
G
(
θ
)
=
F
−
1
(
θ
)
X=G(\theta)=F^{-1}(\theta)
X=G(θ)=F−1(θ)来将
θ
\theta
θ转化为
X
X
X,但众所周知,累积分布函数是不好求的,尤其是对于复杂的概率密度
p
(
x
)
p(x)
p(x)而言,难以通过积分得到累积分布函数
F
(
θ
)
F(\theta)
F(θ)。
现在假设我们想要得到从一个复杂的分布
p
(
x
)
p(x)
p(x)中进行采样,既然
p
(
x
)
p(x)
p(x)太复杂在程序中没法直接采样,那么我设定一个便于程序采样的分布
q
(
x
)
q(x)
q(x),比如高斯分布,然后从
q
(
x
)
q(x)
q(x)中进行采样,并按照一定的方法拒绝某些不合理的样本,以达到接近
p
(
x
)
p(x)
p(x)分布的目的,其中
q
(
x
)
q(x)
q(x)被称为提议分布
采样步骤如下:
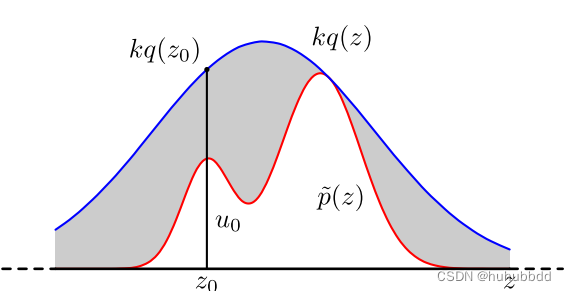
我们设置一个常量
k
k
k,使得
k
q
(
x
)
kq(x)
kq(x)总是在
p
(
x
)
p(x)
p(x)的上方
首先,我们使用概率分布采样方法对
q
(
x
)
q(x)
q(x)进行采样,得到一个样本
z
0
z_0
z0
然后,从均匀分布
U
(
0
,
1
)
U(0,1)
U(0,1)中随机采样得到一个样本
u
0
u_0
u0
如果
u
0
≤
p
(
z
0
)
k
q
(
z
0
)
u_0\le\frac{p(z_0)}{kq(z_0)}
u0≤kq(z0)p(z0),那么就接受
z
0
z_0
z0这个样本,否则拒绝这次采样
重复以上过程,得到
n
n
n个接受的样本
z
0
,
z
1
,
.
.
.
z
n
−
1
z_0,z_1,...z_{n−1}
z0,z1,...zn−1
直观上理解这个采样过程就是:
从均匀分布
U
(
0
,
1
)
U(0,1)
U(0,1)中生成一个随机概率
u
0
u_0
u0
由于我们需要近似的概率分布
p
(
x
)
p(x)
p(x)是图中的红色线条,对于我们采集到的样本点
z
0
z_0
z0而言,它有
p
(
z
0
)
k
q
(
z
0
)
\frac{p(z_0)}{kq(z_0)}
kq(z0)p(z0)的概率可以被认为是一个合理的样本(
p
(
z
0
)
k
q
(
z
0
)
\frac{p(z_0)}{kq(z_0)}
kq(z0)p(z0)代表的就是在
x
=
z
0
x=z_0
x=z0这条竖直的线上
p
(
z
0
)
p(z_0)
p(z0)与
k
q
(
z
0
)
kq(z_0)
kq(z0)的比值,可以按几何概率的思想来理解)
随机概率
u
0
u_0
u0如果没有超过
p
(
z
0
)
k
q
(
z
0
)
\frac{p(z_0)}{kq(z_0)}
kq(z0)p(z0)这个阈值,则认为这次采样的结果是合理的,并接受
z
0
z_0
z0
总之,通过我们通过提议分布
q
(
x
)
q(x)
q(x),最终采集到的样本为
z
0
,
z
1
,
.
.
.
z
n
−
1
z_0,z_1,...z_{n−1}
z0,z1,...zn−1,我们可以通过这组样本,应用蒙特卡洛方法解决最开始的积分问题
θ
=
∫
a
b
f
(
x
)
d
x
=
∫
a
b
f
(
x
)
p
(
x
)
p
(
x
)
d
x
≈
1
n
∑
i
=
1
n
f
(
z
i
)
p
(
z
i
)
\theta=\int_a^b{f(x)dx}=\int_a^b{\frac{f(x)}{p(x)}p(x)dx}\approx\frac{1}{n}\sum_{i=1}^{n}\frac{f(z_i)}{p(z_i)}
θ=∫abf(x)dx=∫abp(x)f(x)p(x)dx≈n1i=1∑np(zi)f(zi)
但此采样方法的效率深受提议分布的影响,如果提议分布与原始分布相差巨大,那么采样结果被拒绝的概率就会非常高,导致采样的效率低下,同时,对于一些高维的复杂非常见分布
p
(
x
1
,
x
2
,
.
.
.
,
x
n
)
p(x_1,x_2,...,x_n)
p(x1,x2,...,xn),我们要找到一个合适的
q
(
x
)
q(x)
q(x)和
k
k
k非常困难。
总结
当我们需要求解一个复杂积分时,我们可以对此积分稍作变换
∫
a
b
f
(
x
)
d
x
=
∫
a
b
f
(
x
)
p
(
x
)
p
(
x
)
d
x
\int_a^b{f(x)dx}=\int_a^b{\frac{f(x)}{p(x)}p(x)dx}
∫abf(x)dx=∫abp(x)f(x)p(x)dx以便于应用蒙特卡洛方法,因为蒙特卡洛方法最重要的思想便是使用均值来逼近期望,这就要求我们抽取一系列的
x
x
x的样本,然后令
∫
a
b
f
(
x
)
p
(
x
)
p
(
x
)
d
x
≈
1
n
∑
i
=
1
n
f
(
x
i
)
p
(
x
i
)
\int_a^b{\frac{f(x)}{p(x)}p(x)dx}\approx\frac{1}{n}\sum_{i=1}^{n}\frac{f(x_i)}{p(x_i)}
∫abp(x)f(x)p(x)dx≈n1i=1∑np(xi)f(xi) 以此来近似积分的结果.
在抽取
x
x
x的样本的过程中,又出现了新的问题,对于常见的概率分布,我们可以通过概率分布采样方法进行采样,然而对于不常见的分布而言,我们很难积分得到它的累积分布函数,更不必说它的反函数,因此我们又引入了接收—拒绝采样方法,使用提议分布为中介进行采样.
目录 场景:
现象:
版本:
分析: 解决方式: 场景: 今天遇到现场环境连接Postgre数据库,日志提示could not determine data type of parameter $4,通过日志复制出完整sqlÿ…