大家好,我是微学AI,今天给大家介绍一下python的基本知识与面试问题的汇总,看完之后会对python巩固有很大的帮助哦。

- Python中的多线程:
多线程是指在一个程序中同时运行多个线程以提高程序的执行效率。Python中的threading模块提供了多线程支持。线程是操作系统中最小的执行单元,它们共享进程的内存空间,但拥有各自的栈空间。
- Python互斥锁与死锁:
互斥锁(Mutex)是一种同步原语,用于保护共享资源的访问,防止多个线程同时访问。死锁是指两个或多个线程在等待对方释放资源,导致无法继续执行的情况。
- Python中的Lambda:
Lambda是Python中的一种匿名函数,它能够简化代码并使其更加易读。Lambda函数的语法非常简单,只需要使用lambda关键字定义即可。下面是几个Lambda函数的例子:
计算两个数的和并返回结果
add = lambda x, y: x + y
print(add(2, 3)) # 输出 5
这个Lambda函数接受两个参数x和y,计算它们的和,并返回结果。
- Python的深拷贝与浅拷贝:
浅拷贝是指创建一个新对象,但只复制原对象的引用。深拷贝是指创建一个新对象,并递归地复制原对象的所有元素及其子元素。copy模块提供了copy()(浅拷贝)和deepcopy()(深拷贝)方法。
- Python多线程是否能用多个CPU:
Python多线程不能充分利用多个CPU,因为全局解释器锁(GIL)限制了同一时间只能有一个线程执行。要充分利用多核CPU,可以使用multiprocessing模块实现多进程。
- Python垃圾回收机制:
Python使用引用计数和循环垃圾收集器(cyclic garbage collector)来管理内存。当一个对象的引用计数为0时,它会被回收。循环垃圾收集器用于检测并回收引用循环中的对象。
- Python里的生成器:
生成器是一种特殊的迭代器,使用yield关键字返回值。生成器函数在每次调用时返回一个新值,同时保留函数的执行状态,以便下次调用时从上次停止的地方继续执行。
- 迭代器与生成器的区别:
迭代器是一个实现了__iter__()和__next__()方法的对象,用于遍历容器中的元素。生成器是一种特殊的迭代器,使用yield关键字返回值,具有更简洁的语法和更高的内存效率。
- Python列表的del, remove和pop等用法和区别:
del是一个语句,用于删除列表中的元素或切片;remove()方法用于删除列表中第一个匹配的元素;pop()方法用于删除并返回指定索引的元素(默认为最后一个元素)。
- Python中什么是闭包:
闭包是一个嵌套函数,它可以捕获并记住外部函数的局部变量的值,即使外部函数已经退出。
- Python的装饰器:
装饰器的本质是一个Python函数或类,它可以用于包装其他函数或类,并使其具有特定的行为,例如修改其输入和输出、检查其错误、添加日志记录、缓存调用结果等。装饰器定义的过程通常需要使用@符号将其应用到目标函数或类上,在调用目标函数或类时,装饰器就会自动生效。
- Python中yield和return的区别:
return用于从函数中返回一个值并终止函数的执行;yield用于从生成器函数中返回一个值,同时保留函数的执行状态,以便下次调用时从上次停止的地方继续执行。
- Python中set的底层实现:
Python中的set是基于哈希表实现的。哈希表是一种数据结构,它使用哈希函数将键映射到存储桶。set中的元素必须是可哈希的。
- Python中字典与set区别:
字典是一个键值对的集合,键必须是唯一的;set是一个无序的、不重复的元素集合。它们的底层实现都是基于哈希表。
- Python中init和new和call的区别:
__init__()是类的初始化方法,用于设置对象的属性;__new__()是类的构造方法,用于创建并返回一个新的对象实例;__call__()是类的可调用方法,使得类的实例可以像函数一样被调用。
-
Python内存管理:
Python内存管理包括内存分配、引用计数、垃圾回收等。内存分配器负责分配和释放内存;引用计数用于跟踪对象的引用数量;垃圾回收器负责回收不再使用的对象。 -
Python中类方法和静态方法的区别:
类方法是一个使用@classmethod装饰器的方法,它的第一个参数是类本身(通常命名为cls);静态方法是一个使用@staticmethod装饰器的方法,它不接受特殊的第一个参数(即没有self或cls参数)。类方法可以被子类覆盖,而静态方法不可以。 -
遍历字典的方法:
可以使用items()、keys()和values()方法遍历字典的键值对、键和值。
d = {'a': 1, 'b': 2, 'c': 3}
for key, value in d.items():
print(key, value)
for key in d.keys():
print(key)
for value in d.values():
print(value)
-
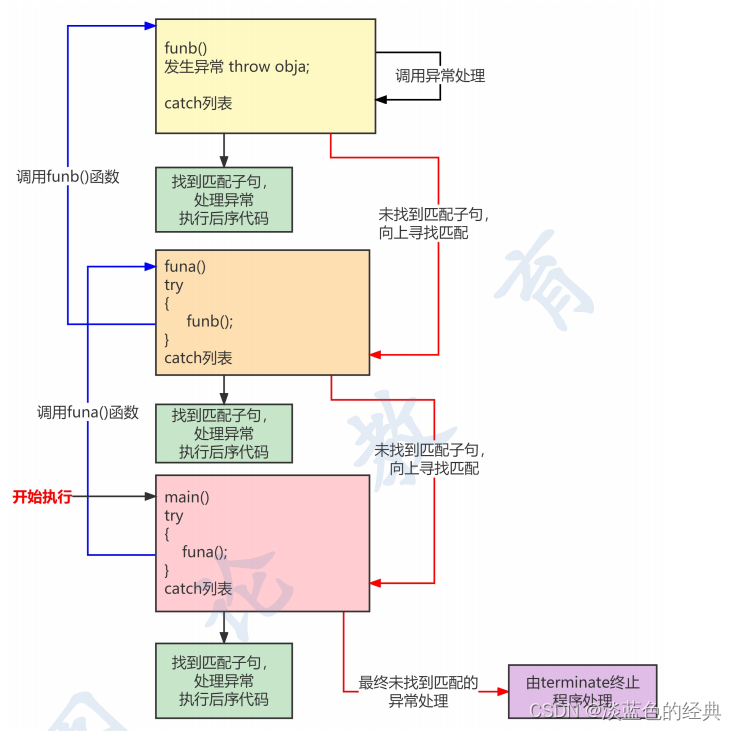
Python中错误和异常处理:错误是编程时的问题,如语法错误;异常是程序运行时的问题,如除以零。异常处理使用
try和except语句捕获和处理异常。 -
Python中try else与finally区别:
else子句在try块没有抛出异常时执行;finally子句无论try块是否抛出异常都会执行。 -
Python中的is和==区别:
is比较两个对象的身份(内存地址),==比较两个对象的值。 -
gbk和utf8的区别:
GBK是一种简体中文字符编码,它包含全部的汉字;UTF-8是一种通用的字符编码,它包含世界上几乎所有的字符。 -
反转列表的方法:
可以使用reverse()方法或切片操作。
lst = [1, 2, 3, 4, 5]
lst.reverse()
print(lst)
lst = [1, 2, 3, 4, 5]
lst = lst[::-1]
print(lst)
- 元组转为字典的方法:
可以使用dict()函数将包含键值对的元组列表转换为字典。
tuples = [('a', 1), ('b', 2), ('c', 3)]
d = dict(tuples)
print(d)
25.函数调用参数的传递方式:
Python中的参数传递是通过对象引用传递的。
-
__init__.py文件的作用以及意义:__init__.py文件表示一个目录是Python包,它可以包含包的初始化代码或定义__all__变量来控制from package import *的行为。 -
列表去重的几种方式:可以使用集合、列表推导式或
collections.OrderedDict。
#方法1
lst = [1, 2, 2, 3, 3, 4, 4, 5]
unique_lst = list(set(lst))
unique_lst = [x for i, x in enumerate(lst) if x not in lst[:i]]
#方法2
from collections import OrderedDict
unique_lst = list(OrderedDict.fromkeys(lst).keys())
-
Python常见的列表推导式:
列表推导式是一种简洁的创建列表的方法,如[x**2 for x in range(10) if x % 2 == 0]。 -
map与reduce函数:
map()函数将一个函数应用于一个序列的所有元素;reduce()函数将一个函数应用于一个序列的元素,从左到右,以便将序列缩减为单个值。 -
except的作用和用法:
except子句用于捕获和处理try块中抛出的异常。
try:
1 / 0
except ZeroDivisionError:
print("Cannot divide by zero")
-
Python中什么是断言:
断言是一种调试辅助工具,它用于检查程序的某个条件是否为真。如果条件为假,assert语句将抛出AssertionError异常。 -
如何理解Python中字符串中的字符:
Python中的字符串是由Unicode字符组成的不可变序列。 -
Python是如何进行类型转换的:
Python提供了内置函数(如int()、float()、str()等)进行类型转换。
34.提高Python运行效率的方法:
使用内置函数和标准库、避免全局变量、使用局部变量、使用列表推导式、使用生成器、使用多线程或多进程、使用C扩展等。