文章目录
- 子查询
- 单行子查询
- 多行子查询
- 相关子查询 exists
子查询

所谓子查询就是 select 查询语句中还有 select 查询语句,里面的称为子查询或内查询,外面的称为主查询或外查询。
根据查询结果记录数量,子查询可以分为两类:
- 单行子查询
- 多行子查询
根据内外查询的相关性,又可以分为:
- 不相关子查询
- 相关子查询
使用子查询需要注意以下几点:
- 子查询要放在小括号对里面;
- 子查询一般放在条件判断的右侧;
- 对于单行子查询,常用搭配操作符有:>、<、=、<>、>=、<=等;
- 对于多行子查询,常用搭配操作符有:in、any、all 等;
- 不相关子查询,子查询先于主查询,用子查询的结果构造外查询的条件;
- 相关子查询:以 exists 为代表,是一个内外一一匹配的过程。
单行子查询
只返回一行结果的子查询,称为单行子查询。对于单行子查询的结果我们可以使用单行操作符来构造外查询条件,如 >、<、= 等等。
例如想要知道 city 表中,人口数量超过 Tokyo 的城市有哪些,并显示这些城市的所有信息。
采用子查询形式的 SQL 语句如下:
select * from city
where population >
(select population from city where name='tokyo');
输出结果:
MariaDB [world]> select * from city
-> where population >
-> (select population from city where name='tokyo');
+------+-------------------+-------------+------------------+------------+
| ID | Name | CountryCode | District | Population |
+------+-------------------+-------------+------------------+------------+
| 206 | São Paulo | BRA | São Paulo | 9968485 |
| 939 | Jakarta | IDN | Jakarta Raya | 9604900 |
| 1024 | Mumbai (Bombay) | IND | Maharashtra | 10500000 |
| 1890 | Shanghai | CHN | Shanghai | 9696300 |
| 2331 | Seoul | KOR | Seoul | 9981619 |
| 2515 | Ciudad de México | MEX | Distrito Federal | 8591309 |
| 2822 | Karachi | PAK | Sindh | 9269265 |
| 3357 | Istanbul | TUR | Istanbul | 8787958 |
| 3580 | Moscow | RUS | Moscow (City) | 8389200 |
| 3793 | New York | USA | New York | 8008278 |
+------+-------------------+-------------+------------------+------------+
10 rows in set (0.004 sec)
这就是单行子查询,其含义是先查询城市 Tokyo 的人口数量,以此结果为算子参与 < 运算作为主查询的过滤条件。
多行子查询
返回多行结果的子查询,称为多行子查询。对于多行子查询的结果我们可以使用多行操作符来进一步构造查询条件,如 in、any、all。
简单说一下这三个多行操作符的含义:
- in:等于多行子查询返回的结果中的任意一个即可;
- any:和多行子查询返回的某一个值进行比较即可;
- all:和多行子查询返回的所有值进行比较;
下面就这三个多行子查询操作运算符进行举例:
1.查询所有和国家 ‘ABW’ 有共同语言的国家。
实现的 SQL 语句如下:
select distinct countrycode
from countrylanguage
where language in (select language from countrylanguage where countrycode='abw');
输出结果:
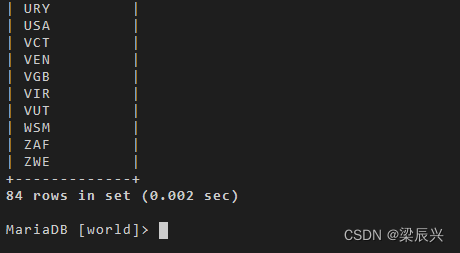
结果解析:子查询首先会查出 ABW 这个国家有 4 个语言,然后利用 in 运算符把使用 4 种语言之一的国家编码显示出来,最后利用 distinct 去掉重复行。
2.查询人口数比 TTO 这个国家下任意城市人口数小的城市信息,换句话说,对某一城市 X,只要 TTO 下任一城市人口数比 X 人口数大,那么 X 就进入查询结果。实现的 SQL 语句如下:
select * from city
where population < any (select population from city where countrycode = 'TTO')
and countrycode<> 'TTO';
输出结果:
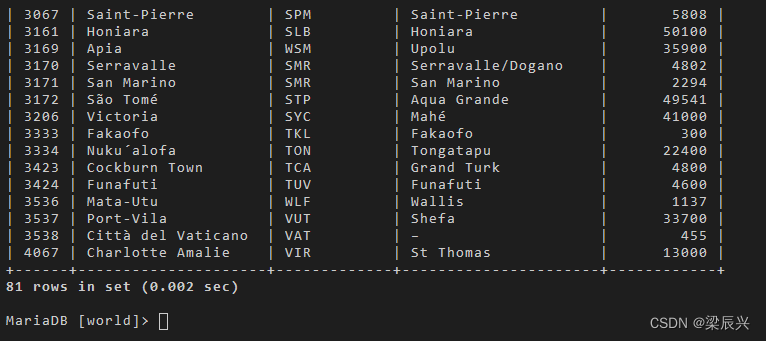
结果解析:在 city 表中 TTO 这个国家共有两个城市,人口数量分别是 56601 和 43396,通过子查询先获取到这两个数据。然后利用 any 操作符,只要比这两个数据中任何一个小的城市信息都被查询出来。这里面包含了 TTO 这个国家本身的城市,与题意不合。所以在主查询后面加了个条件,排除 TTO 这个国家的城市。
3.查询人口数量比 TTO 这个国家所有城市人口数量都小的城市信息,换句话说,人口数小于 TTO 下城市最小人口数的城市会进入查询结果。实现的 SQL 语句如下:
select * from city
where population < all (select population from city where countrycode = 'TTO');
输出结果:
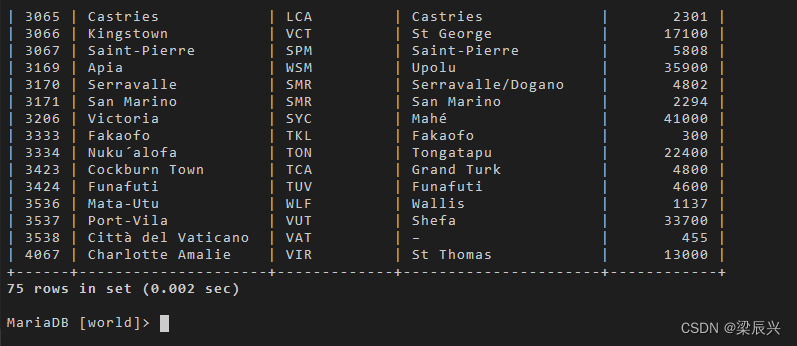
结果解析:使用 all 操作运算符意味着要和子查询所有结果比较(而不是任一),所以结果数据量比使用
any要少。
not 是对 in、between、exists 等取反,读者可自行改写上述例子来体验。
相关子查询 exists
首先,我们需明确不相关子查询和相关子查询的概念:
不相关子查询:子查询的查询条件不依赖于父查询的称为不相关子查询。 相关子查询:子查询的查询条件依赖于外层父查询的某个属性值的称为相关子查询,带 EXISTS 的子查询就是相关子查询。
EXISTS 表示存在量词:带有 EXISTS 的子查询不返回任何记录的数据,只返回逻辑值 True 或 False。
相关子查询执行过程:先在外层查询中取第一行记录,用该记录的相关的属性值(在内层 where 子句中给定的)处理内层查询,若外层的 where 子句返回True值,则这条记录放入结果表中。然后再取下一行记录,重复上述过程直到外层表的记录全部遍历一次为止。
已知国家名Netherlands,查询该国所有城市信息:
select * from city c1
where exists
(select * from country c2 where c1.countrycode = c2.code and c2.name='Netherlands');
输出结果:
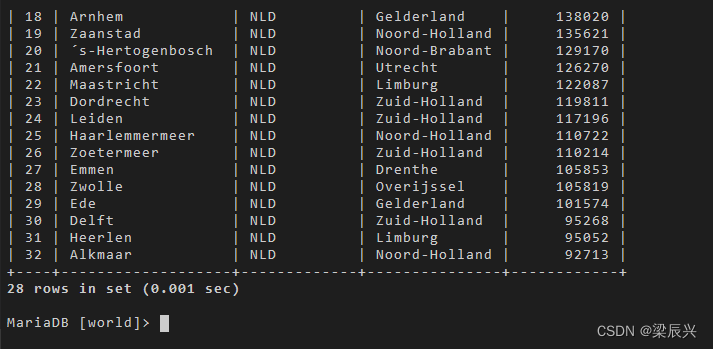
显然,该语句可改写为:
select * from city c1
where c1.countrycode=
(select code from country where name='Netherlands');
就这两条语句而言,第二条的性能优于第一条。exits 语句和其他子查询的性能比较,是一个复杂的问题,此处不打算深究,但可以给大家一个简单的规则做参考:子查询结果大(行数多)可用 exists,子查询结果小可用 = 或 in 等子查询。