HyperLogLog的介绍
- 这并不是一种全新的数据结构、实际类型是一种字符串类型。
- 通过一种基数(不重复的元素数量就是基数)算法,便可以使用很小的内存空间完成独立总数的统计。
- 数据集可以是IP、Email、ID等
- 官方给出的统计误差是0.81%,能满足市面上绝大多数的UV统计需求。
HyperLogLog的常用操作命令
操作命令中的pf为了纪念这个算法的提出者 Philippe Flajolet

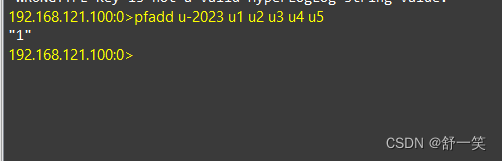
- 向HyperLogLog添加元素、添加成功返回1
- pfadd key element [element …]
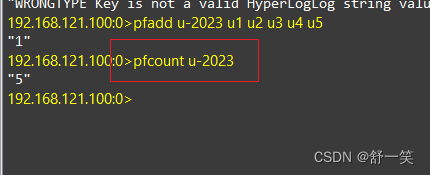
- 计算一个或者多个HyperLogLog的独立总数
- 重复向HyperLogLog中插入元素,统计值会存在误差、存在误差的概率

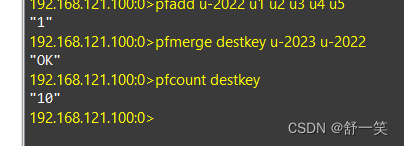
- 求多个HyperLogLog的并集
- pfmerge destkey sourcekey [sourcekey … ]
- 求出的结果放到 sourcekey
原理概述
基本原理便是HyperLogLog基于概率论中的伯努利试验并结合了极大的似然估算方法,做了分桶优化。
redis中的HyperLogLog在传统的分桶优化基础之上,还采用调和平均数过滤掉不健康的统计值。
Redis中的原理分析
- 通过hash函数将传入的数据转化为64位的二进制比特串,并根据比特串的位数求出转化为1的最大位置k_max来求出存入了多少数据
- 根据转化为的64位比特串的后14位作为分桶的依据,也就是2的14次方,一共分16384个桶。达到降低误判的作用
- 然后比特串的前50位则依据从左往右第一个出现1的位数分别进入不同的桶中。所以每个桶中最大就存储50,总共是6位二进制比特串。110010
计算一个HyperLogLog的key占用的存储空间
一个key占用16384个桶x6位/8=12288b/1024=12KB