很久没有写文章了,前些天的面试被问到了分布式锁的解决方案,回答的比较简单,只知道Redis,Mysql,Zookeeper能够作为分布式锁应用,今天就来详细的学习一下这三种分布式锁的设计思想及原理。
能够来看这篇文章的小伙伴我觉得应该都知道什么是分布式锁吧,但我还是多说一下吧,在现在普遍微服务架构的时代,我们的项目架构一般是这样的:
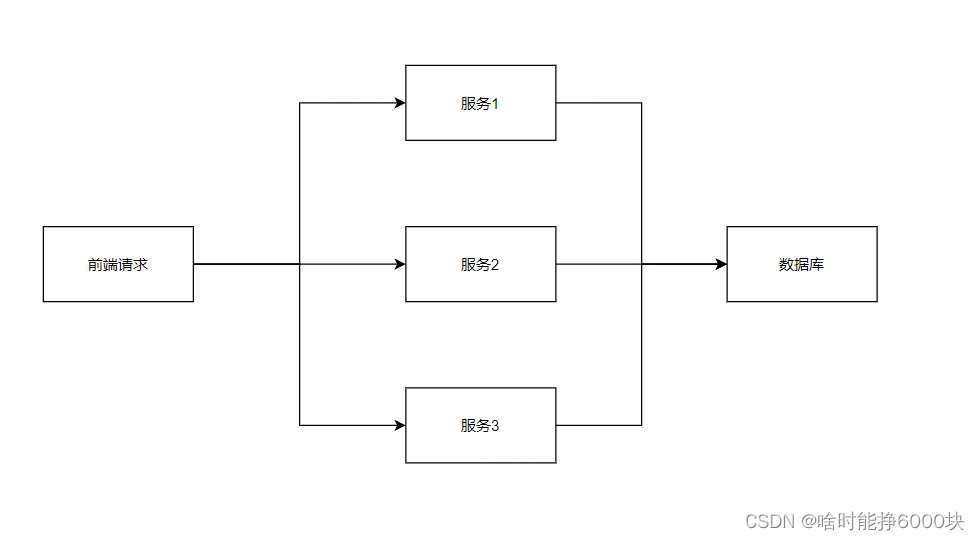
我自己画的这个结构图比较简单,我也不借用网上的图片了,因为太复杂的结构对于初学的同学不是很友好,我们只需要知道在项目中不会只运行单个服务,而是会运行同一套代码的多个服务。
我们描绘一个业务场景。春运时,我们需要在数据库中查询车票数量,返回给服务后进行业务处理,扣减后的车票数量再更新到数据库。因为会并发访问,购买车票,所以我们需要对车票数据进行加锁。又因为java中的锁都是单机锁,作用范围只限于单个服务中,所以我们需要分布式锁来解决多个服务并发访问数据库所造成的数据不安全问题。(如果还是不太懂的小伙伴可以私聊探讨哦)
接下来我们就逐个介绍一下分布式锁的设计方案。
1.通过Mysql创建分布式锁
我们可以使用 select * from table where xxx = xxx for update 通过for update关键字为数据加锁(排他锁,for share为共享锁),如果有查询条件则对查询条件加锁,无查询条件则对表加锁。加锁后需要设置手动提交(重要,不然会造成死锁),当我们通过for update加锁后,就可以对数据进行update操作了,操作后通过commit将整个事务提交进行解锁。但是在工作中mysql分布式锁是不推荐的,因为这会影响数据库的性能;有时不精确的查询条件会造成锁定较多数据;业务流程中出现异常时不好处理(业务异常可以通过事务回滚取消,但宕机等异常会在一段时间内影响数据库)。
2.通过Redis创建分布式锁
redis分布式锁是工作中常用的一种分布式锁,也是我之前工作中使用的类型。
如果小伙伴们有不太知道Redis的可以看一下其他文章。
Redis基本命令集这里有Redis操作使用的基本命令。
在Redis中我们可以使用setnx 命令来进行加锁。通过del 命令进行释放锁。
但这样会有一个问题,那就是当一个服务通过setnx命令获取了锁后,业务处理时异常,这时Redis锁就无法释放——会产生死锁问题,这个问题我们可以通过expire命令添加过期时间,当时间到了该锁会自动释放。但是两个命令不具备原子性,所以我们可以通过 setex 命令或者 set 锁名称 锁的值 EX 过期时间 NX 来创建Redis锁。
上面我们解决了死锁问题后,又发现针对一个锁,任意的服务通过 del 命令都可以释放锁,但正确情况应该是只有当前服务的当前线程才可以进行锁的释放,所以我们在加锁时需要通过将锁的值设置为当前线程ID,或者将线程ID作为部分进行加锁,释放锁前通过 get 锁名称 方式来判断释放锁的线程与加锁线程是否为同一个,只有加锁线程与解锁线程为同一个时才可以进行释放。释放锁时为了保证 get 命令与 del 命令的原子性,我们可以使用lua脚本去进行处理。
如果Redis锁的过期时间不好确定,此时我们可以通过守护线程+延时队列(DelayQueue)去延长锁的过期时间。设置守护线程,当主线程执行时,守护线程通过延时队列去获取需要延长时间的锁,并对其进行延时,如果获取不到锁则进行阻塞等待。
我之前的工作中使用的是redission框架生成的分布式锁,我也将简单的引用放在下面的连接中了,有需要的小伙伴们可以看一下:
Redis分布式锁
此时我们的分布式锁还是存在问题的,上面说的内容只限于单机Redis,但在实际工作中一般都是Redis集群,主从+哨兵的配置模式,如果不了解分布式集群的小伙伴们,我这里也有文章,可以稍微了解一下:
Redis学习笔记(六)——发布订阅、主从复制及缓存击穿、穿透、雪崩
那么就有以下问题,当我们在Redis主节点中创建了一个分布式锁后,准备去执行业务逻辑时,Redis主节点不小心挂掉了,此时主节点的数据还没有完全同步到从节点,所以此时从节点中选举产生的新的主节点中就没有该锁存在,其他线程可以重新加锁执行业务,那么就会导致线程不安全。这种问题我们可以通过RedLock(红锁)处理。
RedLock处理方式:
1.需要多个非集群的单个主节点,单独用来进行RedLock逻辑处理(一般为5台,我们也用5台来举例)。
2.客户端先获取当前的时间戳T1
3.客户端依次向Redis实例发起加锁请求
4.如果大于半数(此时为3台)成功,且大于半数成功时的时间戳T2-T1 < 锁的过期时间则成功
5.释放锁时需要向5台Redis发起释放请求
大于半数成功是因为只要大于半数实例加锁成功,其他实例肯定加锁失败(因为达不到半数加锁成功),并且加锁成功的实例越少,性能越好,所以大于半数加锁成功为最终成功。
其次需要判断时间戳T2-T1 < 锁的过期时间,防止我们依次加锁的时候最后一个锁添加成功时第一个实例的锁已经过期。
释放锁需要向所有实例发起请求,是防止有部分实例残存已经释放的锁。
RedLock存在NPC问题:N (Network Delay) 网络延迟;P (Process Pause) 进程暂停(GC);C (Clock Drift) 时钟漂移 (多个服务中的时间可能存在差异)。
前两种可以通过时间戳判断进行解决,时钟漂移很难解决。工作中不太建议用,但是需要了解。
3.通过Zookeeper创建分布式锁
Zookeeper实际就是一个文件系统,通过数据目录的原子性特征实现分布式锁(原理与同一目录层级下无法创建两个相同名称的文件或文件夹相似)。
我们通过创建文件节点的方式来创建锁,文件系统天然唯一,同一层级下不会出现多个相同名称的文件节点,保证了锁的唯一性。
死锁问题我们可以通过创建临时节点来解决,当前线程在zookeeper中会通过会话session来创建临时节点,当线程挂掉后临时节点也会随之释放,所以不会产生死锁问题。
锁被释放后,其他等待锁的线程如何通知?这个问题可以通过
1.等待线程主动轮询的方式解决,但此方式会导致zookeeper服务压力过大,并且会有轮询间隔时间延迟,比如5秒轮询一次,当前轮询完毕后1秒锁被释放,其他线程还需要等待4秒才能再次轮询。
2.我们可以通过watch机制来解决延迟问题,监听节点是否释放删除,当锁释放后第一时间等待线程就可以进行请求,但是此时服务过多还是会导致压力问题。
3.所以最终方式是我们通过排队,按序号创建临时节点,每个节点watch监听前一个节点,如果前一个节点释放删除了,我们再判断是否为第一个节点,如果为第一个节点则获取锁,如果非第一个节点则重新watch上一个节点(zk分布式锁是公平锁)。
在项目中使用zookeeper创建分布式锁
zk属于不可重入锁,借助curator框架实现可重入性。
先导入依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.8.0</version>
</dependency>
<!-- zookeeper客户端-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.2.1</version>
</dependency>编写配置文件:
#Zookeeper配置信息
curator:
#服务器连接地址
connectString: 127.0.0.1:2181
#重试次数,当会话超时后,curator会间隔elapsedTimeMs毫秒重试一次,共重试retryCount次
retryCount: 5
elapsedTimeMs: 5000
#会话超时时间
sessionTimeoutMs: 60000
#连接超时时间
connectionTimeoutMs: 5000
编写配置信息:
package com.project.springtest.zk;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
/**
* @description:
* @author: Me
* @createDate: 2023/6/4 15:26
* @version: 1.0
*/
@Data
@Component
@ConfigurationProperties(prefix = "curator")
public class WrapperZk {
private int retryCount;
private int elapsedTimeMs;
private String connectString;
private int sessionTimeoutMs;
private int connectTimeoutMs;
}
创建客户端对象:
package com.project.springtest.zk;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @description:
* @author: Me
* @createDate: 2023/6/4 15:26
* @version: 1.0
*/
@Configuration
public class CuratorConfig {
@Autowired
private WrapperZk wrapperZk;
// 返回一个zookeeper客户端的bean
@Bean
public CuratorFramework curatorFramework() {
// 配置一个超时策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(wrapperZk.getElapsedTimeMs(), wrapperZk.getRetryCount());
CuratorFramework client = CuratorFrameworkFactory.newClient(wrapperZk.getConnectString(),
wrapperZk.getSessionTimeoutMs(),
wrapperZk.getConnectTimeoutMs(),
retryPolicy);
client.start();
return client;
}
}
简单使用:
package com.project.springtest.controller;
import lombok.Data;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.locks.InterProcessLock;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
@Data
public class MyService {
@Autowired
private CuratorFramework curatorFramework;
static InterProcessLock lock;
public String service() throws Exception {
// 保证同一个应用中只有一个线程来创建锁
synchronized (this) {
if (lock == null) {
lock = new InterProcessMutex(curatorFramework, "/加锁的业务内容");
}
}
// 5秒钟去获取一次锁
if (lock.acquire(5, TimeUnit.SECONDS)) {
// 加锁成功后执行业务逻辑
}
// 锁释放
lock.release();
return "OK";
}
}
工作中一般还是用redis来构建分布式锁,因为redis的性能太好了,但zk也有自己特殊的应用场景,例如并发量不高,且需要保持强一致性(简单来说就是任意时刻所有节点的数据都是一致的)的场景下就需要使用zk来作为分布式锁了。简单来说就是看项目中对可用性和强一致性的侧重点来选择啦。
今天分布式锁就学习到这里了,希望对大家能够有帮助。