使用到的库
pandas、matplotlib、numpy
使用到的函数
df.resample(“H”).sum()
参数
B business day frequency
C custom business day frequency (experimental)
D calendar day frequency
W weekly frequency
M month end frequency
BM business month end frequency
CBM custom business month end frequency
MS month start frequency
BMS business month start frequency
CBMS custom business month start frequency
Q quarter end frequency
BQ business quarter endfrequency
QS quarter start frequency
BQS business quarter start frequency
A year end frequency
BA business year end frequency
AS year start frequency
BAS business year start frequency
BH business hour frequency
H hourly frequency
T minutely frequency
S secondly frequency
L milliseonds
U microseconds
N nanoseconds
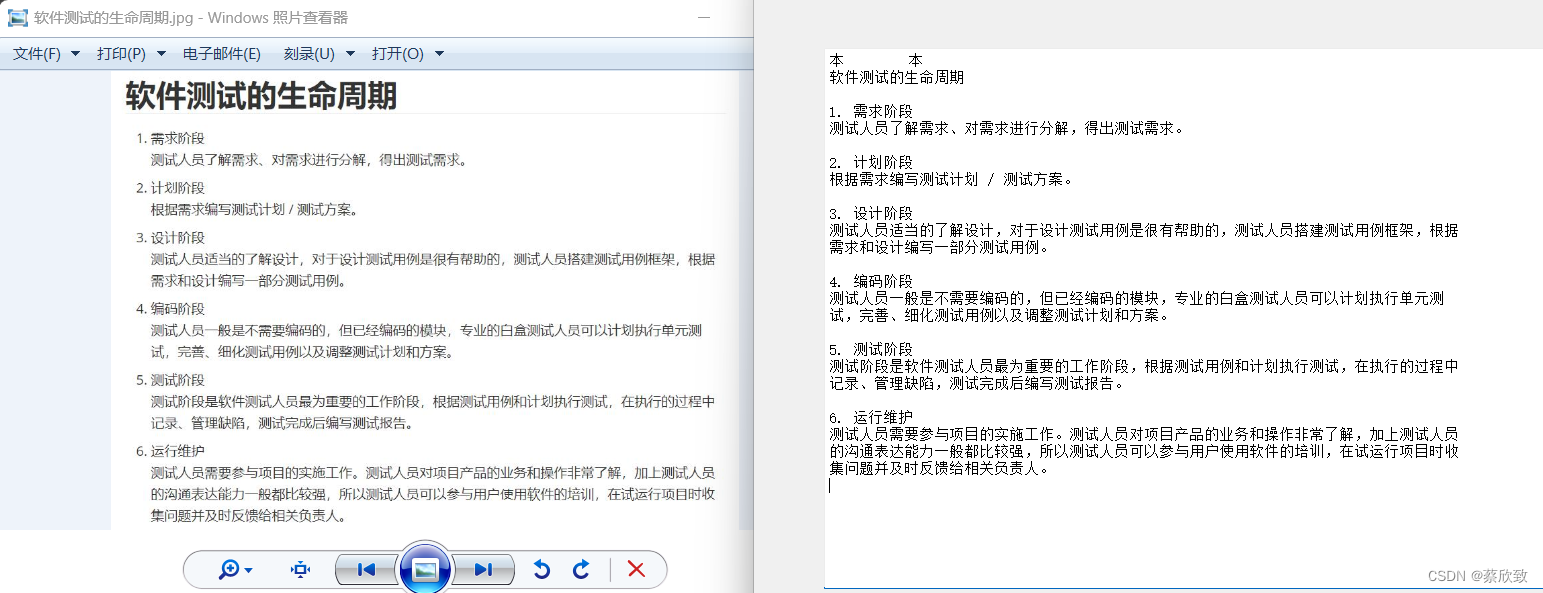
主要思路
- 从csv中读取数据
- 将带有时间的列进行装换
- 将object的字符串转成时间,将字符串转成datetime64[ns],再转成float64
# 时间格式的字符串转datetime64[ns]
df["报修时间"]=pd.to_datetime(df["报修时间"])
# datetime64[ns],再转成float64
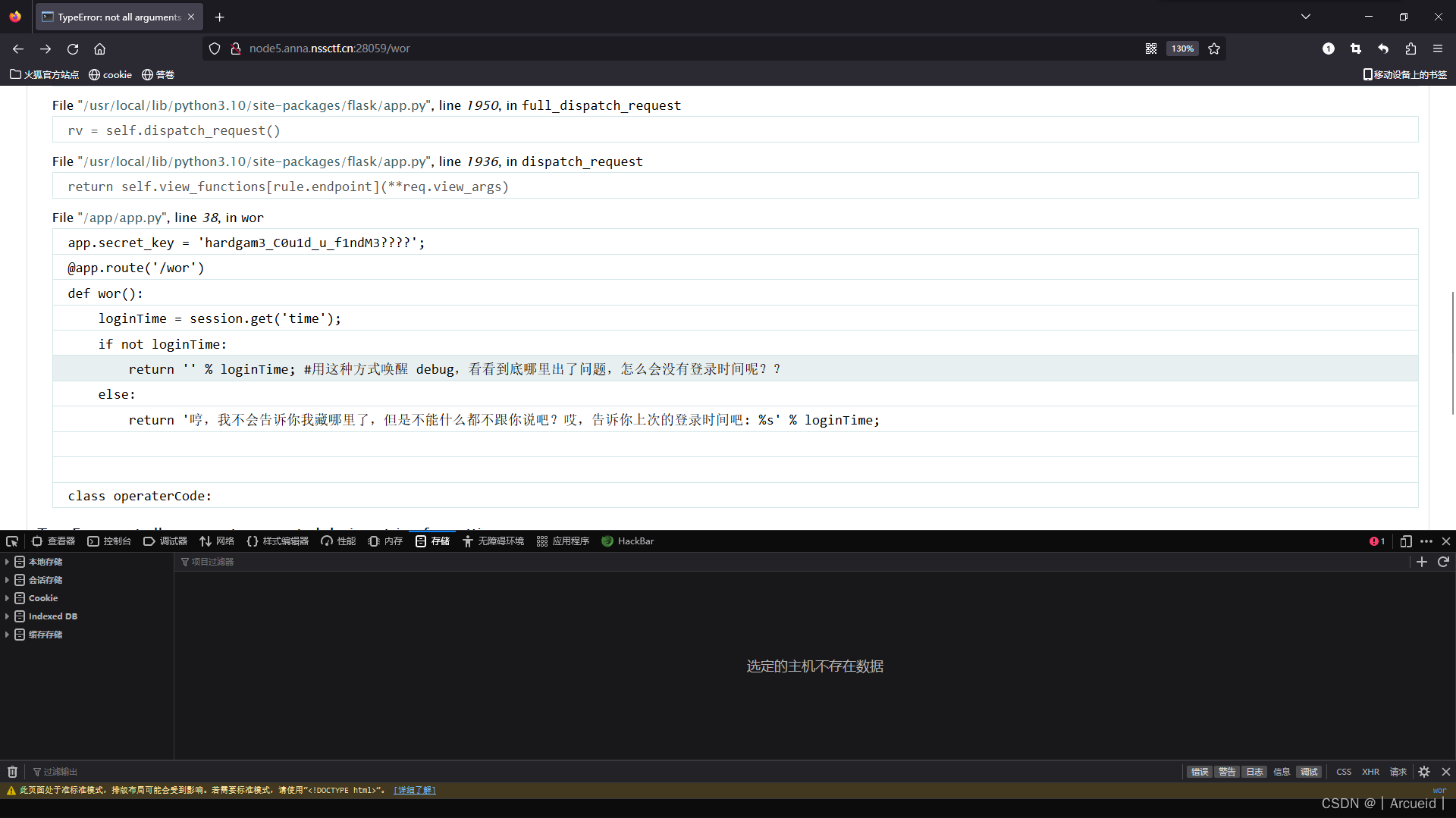
df["报修时间"]=(df["报修时间"] - np.datetime64('1970-01-01T00:00:00Z')) / np.timedelta64(1, 's')
- 将数df设置成使用时间
df=df.set_index(df["date"])
- 利用resample进行统计
新增加一列便于统计
df["new"] = 1
# 统计命令
df["new"].resample("H").sum().head(40)
输出
>>> df["new"].resample("H").sum().head(40)
date
2023-01-01 04:00:00 1
2023-01-01 05:00:00 0
2023-01-01 06:00:00 0
2023-01-01 07:00:00 0
- 画图
需要注意的是df2[“2023-01-02”],针对是第一次做resample,如果使用第二次的resample数据就会报错keyerror
>>> df2["2023-01-02"].plot
<pandas.plotting._core.PlotAccessor object at 0x0000027582973910>
>>> plt.show()
>>> df2["2023-01-02"].plot()
<Axes: xlabel='date'>
>>> plt.show()
>>> df2["2023-01-02"].plot()
<Axes: xlabel='date'>
>>> df2["2023-01-03"].plot()
<Axes: xlabel='date'>
>>> df2["2023-01-01"].plot()
<Axes: xlabel='date'>
>>> plt.show()
参考
https://blog.csdn.net/weixin_42357472/article/details/115301527
https://blog.csdn.net/AlexTan_/article/details/89763389
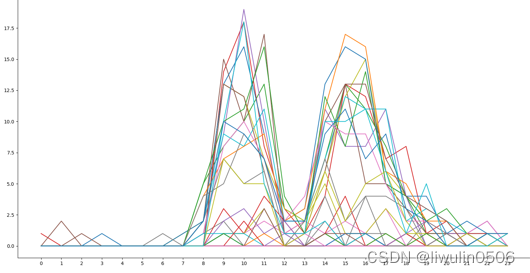
案例
目标
统计一个月的数据,每天24小时的销售数量
数据集类似
- 使用read_csv读取数据,encoding设置为gbk
df=pd.read_csv("xx.csv",encoding="gbk")
- 为df数据添加new列便于统计设定为
df["new"]=1
- 重新设定df的索引
df["报修时间"]=pd.to_datetime(df["报修时间"])
df=df.set_index(df["报修时间"])
- 获取df1的值
df1=df["new"].resample("H").sum()
>>> df1
new
报修时间
2023-06-01 09:41:26 1
2023-06-01 09:37:40 1
2023-06-01 09:35:53 1
2023-06-01 09:34:38 1
2023-06-01 09:30:27 1
... ... ... ...
2023-01-01 14:04:38 1
2023-01-01 12:44:38 1
2023-01-01 10:57:54 1
2023-01-01 08:42:07 1
2023-01-01 04:51:13 1
下面针对df1做操作
- 编写获取每天二十四小时的销售数据
>>> def getV(cc):
... c=[]
... for x in df1[cc]:
... c.append(x)
... return c
测试输出
>>> sc=getV("2023-01-3")
>>> sc
[0, 0, 0, 0, 0, 0, 0, 0, 5, 8, 10, 13, 3, 2, 7, 13, 11, 8, 4, 1, 1, 0, 0, 0]
- 设定x轴的值yy
>>> yy
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]
- 画图
>>> for i in range(30):
... st="2023-01-"+str(i+2)
... plt.plot(yy,getV(st))
... plt.xticks(xticks=yy)
plt.show()
- 结果