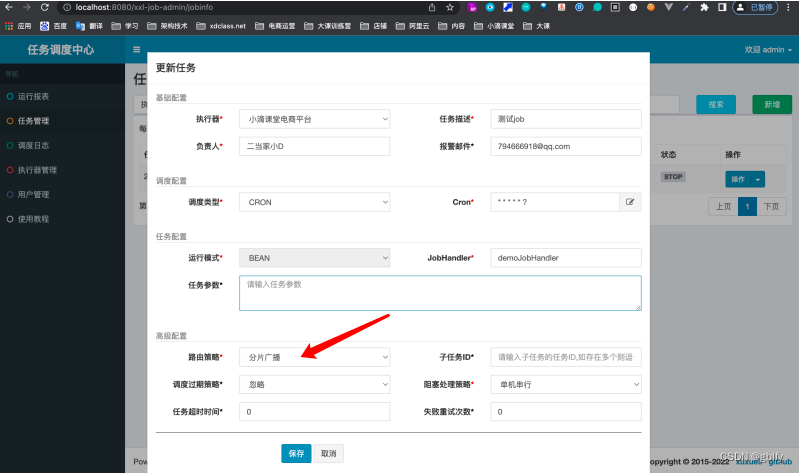
帧间编码入口函数:
从 Analysis::compressCTU 是ctu编码的入口函数,根据 slice 类型判断是 I 还是 BP,如果是BP则执行帧间编码函数 Analysis::compressInterCU_rdx_x::
/*
压缩分析CTU
过程:
1.为当前CTU加载QP/熵编码上下文
2.是否有编码信息输入来方便快速最优模式分析
·bCTUInfo,加载depth/content/prevCtuInfoChange
·analysisMultiPassRefine,加载之前pass计算分析得到的mv/mvpIdx/ref/modes/depth
·analysisLoad && 非Islice,加载load数据中的Ref/Depth/Modes/PartSize/MergeFlag
3.对CTU压缩编码
·Islice 执行帧内预测压缩编码
1.若analysisLoad,则加载cuDepth/partSize/lumaIntraDir/chromaIntraDir
2.compressIntraCU
·P/Bslice 执行帧间预测压缩编码
1.判断是否有可用的编码分析数据
2.若有可用编码分析数据则拷贝这些可用数据:cuDepth/predMode/partSize/skipFlag/lumaIntraDir/chromaIntraDir
3.进行实际的P/Bslice编码
·若开启bIntraRefresh,且CTU处于Pir范围内,则对CTU进行compressIntraCU编码
·若rdlevel = 0
1.将原始YUV数据拷贝到recon图像中
2.进行compressInterCU_rd0_4压缩编码
3.进行encodeResidue编码残差
·若analysisLoad
1.拷贝cuDepth/predMode/partSize/lumaIntraDir/chromaIntraDir
2.进行qprdRefine优化rd qp
3.返回CTU的bestMode
·若开启bDistributeModeAnalysis,且rdlevel>=2,则进行compressInterCU_dist分布式压缩编码
·若rdlevel 0~4,则进行compressInterCU_rd0_4压缩编码
·若rdlevel 5~6,则进行compressInterCU_rd5_6压缩编码
4.若使用 rd优化 或 CU级qp优化,则进行qprdRefine优化
5.若csvlog等级>=2,则collectPUStatistics进行PU信息统计
6.返回CTU的bestMode
*/
Mode& Analysis::compressCTU(CUData& ctu, Frame& frame, const CUGeom& cuGeom, const Entropy& initialContext)
{
//h265有slice条带的划分,一个ctu在一个slice上,这里取当前ctu所在条带引用
m_slice = ctu.m_slice;
//取当前ctu所在的帧引用
m_frame = &frame;
//如果rd级别大于等于3则还需要计算色度的 sa8dcost
m_bChromaSa8d = m_param->rdLevel >= 3;
m_param = m_frame->m_param;
#if _DEBUG || CHECKED_BUILD
invalidateContexts(0);
#endif
int qp = setLambdaFromQP(ctu, m_slice->m_pps->bUseDQP ? calculateQpforCuSize(ctu, cuGeom) : m_slice->m_sliceQp);
ctu.setQPSubParts((int8_t)qp, 0, 0);
// 初始化四叉树划分上下文,初始深度为0
m_rqt[0].cur.load(initialContext);
ctu.m_meanQP = initialContext.m_meanQP;
// 复制当前ctu的 yuv 数据到四叉树划分上下文中
m_modeDepth[0].fencYuv.copyFromPicYuv(*m_frame->m_fencPic, ctu.m_cuAddr, 0);
// 开启了ssim rdo
if (m_param->bSsimRd)
calculateNormFactor(ctu, qp);
// 取当前ctu 4*4划分块数
uint32_t numPartition = ctu.m_numPartitions;
if (m_param->bCTUInfo && (*m_frame->m_ctuInfo + ctu.m_cuAddr))
{
// 取当前ctu的info
x265_ctu_info_t* ctuTemp = *m_frame->m_ctuInfo + ctu.m_cuAddr;
int32_t depthIdx = 0; // 深度0
uint32_t maxNum8x8Partitions = 64;
// 取目标数据存储 depthInfoPtr/contentInfoPtr/prevCtuInfoChangePtr
uint8_t* depthInfoPtr = m_frame->m_addOnDepth[ctu.m_cuAddr];
uint8_t* contentInfoPtr = m_frame->m_addOnCtuInfo[ctu.m_cuAddr];
int* prevCtuInfoChangePtr = m_frame->m_addOnPrevChange[ctu.m_cuAddr];
// 遍历所有的partition,拷贝API外的编码分析数据到目标depthInfoPtr/contentInfoPtr/prevCtuInfoChangePtr中
do
{
uint8_t depth = (uint8_t)ctuTemp->ctuPartitions[depthIdx];
uint8_t content = (uint8_t)(*((int32_t *)ctuTemp->ctuInfo + depthIdx));
int prevCtuInfoChange = m_frame->m_prevCtuInfoChange[ctu.m_cuAddr * maxNum8x8Partitions + depthIdx];
memset(depthInfoPtr, depth, sizeof(uint8_t) * numPartition >> 2 * depth);
memset(contentInfoPtr, content, sizeof(uint8_t) * numPartition >> 2 * depth);
memset(prevCtuInfoChangePtr, 0, sizeof(int) * numPartition >> 2 * depth);
//加载之前pass计算分析得到的mv/mvpIdx/ref/modes/depth
for (uint32_t l = 0; l < numPartition >> 2 * depth; l++)
prevCtuInfoChangePtr[l] = prevCtuInfoChange;
depthInfoPtr += ctu.m_numPartitions >> 2 * depth;
contentInfoPtr += ctu.m_numPartitions >> 2 * depth;
prevCtuInfoChangePtr += ctu.m_numPartitions >> 2 * depth;
depthIdx++;
} while (ctuTemp->ctuPartitions[depthIdx] != 0);
m_additionalCtuInfo = m_frame->m_addOnCtuInfo[ctu.m_cuAddr];
m_prevCtuInfoChange = m_frame->m_addOnPrevChange[ctu.m_cuAddr];
memcpy(ctu.m_cuDepth, m_frame->m_addOnDepth[ctu.m_cuAddr], sizeof(uint8_t) * numPartition);
//Calculate log2CUSize from depth
for (uint32_t i = 0; i < cuGeom.numPartitions; i++)
ctu.m_log2CUSize[i] = (uint8_t)m_param->maxLog2CUSize - ctu.m_cuDepth[i];
}
// 如果开启了 analysisMultiPassRefine 并且当前ctu所在slice类型不是I,并且 bStatRead
if (m_param->analysisMultiPassRefine && m_param->rc.bStatRead && (m_slice->m_sliceType != I_SLICE))
{
int numPredDir = m_slice->isInterP() ? 1 : 2;
m_reuseInterDataCTU = m_frame->m_analysisData.interData;
for (int dir = 0; dir < numPredDir; dir++)
{
m_reuseMv[dir] = &m_reuseInterDataCTU->mv[dir][ctu.m_cuAddr * ctu.m_numPartitions];
m_reuseMvpIdx[dir] = &m_reuseInterDataCTU->mvpIdx[dir][ctu.m_cuAddr * ctu.m_numPartitions];
}
m_reuseRef = &m_reuseInterDataCTU->ref[ctu.m_cuAddr * ctu.m_numPartitions];
m_reuseModes = &m_reuseInterDataCTU->modes[ctu.m_cuAddr * ctu.m_numPartitions];
m_reuseDepth = &m_reuseInterDataCTU->depth[ctu.m_cuAddr * ctu.m_numPartitions];
}
int reuseLevel = X265_MAX(m_param->analysisSaveReuseLevel, m_param->analysisLoadReuseLevel);
//若开启了编码器外第三方编码信息读取,则将读取的信息载入,用于后续编码
if ((m_param->analysisSave || m_param->analysisLoad) && m_slice->m_sliceType != I_SLICE && reuseLevel > 1 && reuseLevel < 10)
{
int numPredDir = m_slice->isInterP() ? 1 : 2; //预测方向
m_reuseInterDataCTU = m_frame->m_analysisData.interData; //取interData/ref/depth/mode数据
if (((m_param->analysisSaveReuseLevel > 1) && (m_param->analysisSaveReuseLevel < 7)) ||
((m_param->analysisLoadReuseLevel > 1) && (m_param->analysisLoadReuseLevel < 7)))
m_reuseRef = &m_reuseInterDataCTU->ref[ctu.m_cuAddr * X265_MAX_PRED_MODE_PER_CTU * numPredDir];
m_reuseDepth = &m_reuseInterDataCTU->depth[ctu.m_cuAddr * ctu.m_numPartitions];
m_reuseModes = &m_reuseInterDataCTU->modes[ctu.m_cuAddr * ctu.m_numPartitions];
if (reuseLevel > 4)
{
m_reusePartSize = &m_reuseInterDataCTU->partSize[ctu.m_cuAddr * ctu.m_numPartitions];
m_reuseMergeFlag = &m_reuseInterDataCTU->mergeFlag[ctu.m_cuAddr * ctu.m_numPartitions];
}
if (m_param->analysisSave && !m_param->analysisLoad)
for (int i = 0; i < X265_MAX_PRED_MODE_PER_CTU * numPredDir; i++)
m_reuseRef[i] = -1;
}
ProfileCUScope(ctu, totalCTUTime, totalCTUs);
// 帧类型m_sliceType BPI 分别是 012
// 判断是否为ISlice,I执行帧内预测,非I执行帧间预测
if (m_slice->m_sliceType == I_SLICE){
x265_analysis_intra_data* intraDataCTU = m_frame->m_analysisData.intraData;
if (m_param->analysisLoadReuseLevel > 1)
{
memcpy(ctu.m_cuDepth, &intraDataCTU->depth[ctu.m_cuAddr * numPartition], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_lumaIntraDir, &intraDataCTU->modes[ctu.m_cuAddr * numPartition], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_partSize, &intraDataCTU->partSizes[ctu.m_cuAddr * numPartition], sizeof(char) * numPartition);
memcpy(ctu.m_chromaIntraDir, &intraDataCTU->chromaModes[ctu.m_cuAddr * numPartition], sizeof(uint8_t) * numPartition);
}
// 帧内预测入口
compressIntraCU(ctu, cuGeom, qp);
}
else // BP类型的slice里面的ctu
{
bool bCopyAnalysis = ((m_param->analysisLoadReuseLevel == 10) || (m_param->bAnalysisType == AVC_INFO && m_param->analysisLoadReuseLevel >= 7 && ctu.m_numPartitions <= 16));
bool bCompressInterCUrd0_4 = (m_param->bAnalysisType == AVC_INFO && m_param->analysisLoadReuseLevel >= 7 && m_param->rdLevel <= 4);
bool bCompressInterCUrd5_6 = (m_param->bAnalysisType == AVC_INFO && m_param->analysisLoadReuseLevel >= 7 && m_param->rdLevel >= 5 && m_param->rdLevel <= 6);
bCopyAnalysis = bCopyAnalysis || bCompressInterCUrd0_4 || bCompressInterCUrd5_6;
if (bCopyAnalysis)
{
// 读取 interDataCTU 用于后续帧间编码
x265_analysis_inter_data* interDataCTU = m_frame->m_analysisData.interData;
// 取ctu所在位置下标
int posCTU = ctu.m_cuAddr * numPartition;
//复制analysisData中的cuDepth/predMode/partSize/skipFlag到CTU信息中,用于编码
memcpy(ctu.m_cuDepth, &interDataCTU->depth[posCTU], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_predMode, &interDataCTU->modes[posCTU], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_partSize, &interDataCTU->partSize[posCTU], sizeof(uint8_t) * numPartition);
for (int list = 0; list < m_slice->isInterB() + 1; list++)
memcpy(ctu.m_skipFlag[list], &m_frame->m_analysisData.modeFlag[list][posCTU], sizeof(uint8_t) * numPartition);
// PSlice 或者开启帧内预测的 BSlice 内的 ctu 还需要保存 intraDataCTU 用于后续帧内编码
if ((m_slice->m_sliceType == P_SLICE || m_param->bIntraInBFrames) && !(m_param->bAnalysisType == AVC_INFO))
{
x265_analysis_intra_data* intraDataCTU = m_frame->m_analysisData.intraData;
memcpy(ctu.m_lumaIntraDir, &intraDataCTU->modes[posCTU], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_chromaIntraDir, &intraDataCTU->chromaModes[posCTU], sizeof(uint8_t) * numPartition);
}
//Calculate log2CUSize from depth
for (uint32_t i = 0; i < cuGeom.numPartitions; i++)
ctu.m_log2CUSize[i] = (uint8_t)m_param->maxLog2CUSize - ctu.m_cuDepth[i];
}
// 若开启了bIntraRefresh 并且当前 ctu 位于Pslice上,同时当前ctu处于pirStartCol和pirEndCol之间,则还需要进行帧内编码
if (m_param->bIntraRefresh && m_slice->m_sliceType == P_SLICE &&
ctu.m_cuPelX / m_param->maxCUSize >= frame.m_encData->m_pir.pirStartCol
&& ctu.m_cuPelX / m_param->maxCUSize < frame.m_encData->m_pir.pirEndCol)
compressIntraCU(ctu, cuGeom, qp);
// 如果设置 rd 级别为 0
else if (!m_param->rdLevel)
{
// rdlevel=0时还需要将 ctu 原始像素值复制到 reconstructed block 用于后续帧数内编码
m_modeDepth[0].fencYuv.copyToPicYuv(*m_frame->m_reconPic, ctu.m_cuAddr, 0);
// 帧间预测编码
compressInterCU_rd0_4(ctu, cuGeom, qp);
/* 残差进行编码 */
encodeResidue(ctu, cuGeom);
}
/*开启analysisLoad && analysisReuseLevel=10 && (bAnalysisType!=HEVC || 非Pslice) 或
bAnalysisType = AVC_INFO && analysisReuseLevel >= 7 && 4x4block个数<=16*/
else if ((m_param->analysisLoadReuseLevel == 10 && (!(m_param->bAnalysisType == HEVC_INFO) || m_slice->m_sliceType != P_SLICE)) ||
((m_param->bAnalysisType == AVC_INFO) && m_param->analysisLoadReuseLevel >= 7 && ctu.m_numPartitions <= 16))
{
x265_analysis_inter_data* interDataCTU = m_frame->m_analysisData.interData;
int posCTU = ctu.m_cuAddr * numPartition;
memcpy(ctu.m_cuDepth, &interDataCTU->depth[posCTU], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_predMode, &interDataCTU->modes[posCTU], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_partSize, &interDataCTU->partSize[posCTU], sizeof(uint8_t) * numPartition);
if ((m_slice->m_sliceType == P_SLICE || m_param->bIntraInBFrames) && !(m_param->bAnalysisType == AVC_INFO))
{
x265_analysis_intra_data* intraDataCTU = m_frame->m_analysisData.intraData;
memcpy(ctu.m_lumaIntraDir, &intraDataCTU->modes[posCTU], sizeof(uint8_t) * numPartition);
memcpy(ctu.m_chromaIntraDir, &intraDataCTU->chromaModes[posCTU], sizeof(uint8_t) * numPartition);
}
//Calculate log2CUSize from depth
for (uint32_t i = 0; i < cuGeom.numPartitions; i++)
ctu.m_log2CUSize[i] = (uint8_t)m_param->maxLog2CUSize - ctu.m_cuDepth[i];
qprdRefine (ctu, cuGeom, qp, qp);
return *m_modeDepth[0].bestMode;
}
else if (m_param->bDistributeModeAnalysis && m_param->rdLevel >= 2)
compressInterCU_dist(ctu, cuGeom, qp);
// 如果设置 rd 级别 1~4
else if (m_param->rdLevel <= 4)
compressInterCU_rd0_4(ctu, cuGeom, qp);
// 如果设置 rd 级别 5~6
else
compressInterCU_rd5_6(ctu, cuGeom, qp);
}
// 开启了 bEnableRdRefine 或者 bOptCUDeltaQP 还需要执行 qp 量化编码的rd优化
if (m_param->bEnableRdRefine || m_param->bOptCUDeltaQP)
qprdRefine(ctu, cuGeom, qp, qp);
if (m_param->csvLogLevel >= 2)
collectPUStatistics(ctu, cuGeom);
// 返回当前深度CTU的最佳预测模式(含帧内预测和帧间预测)
return *m_modeDepth[0].bestMode;
}【源码】Analysis::compressInterCU_rd0_4
以默认的级别 rd=3为例,RDO级别越高,对应的码率越高,编码速率越慢。
|
rd-level 0
|
generates no recon per CU (NO RDO or Quant)
|
* sa8d selection between merge / skip / inter / intra and split
* no recon pixels generated until CTU analysis is complete, requiring
* intra predictions to use source pixels
|
最终会调用
Analysis::compressInterCU_rd0_4:
|
|
rd-level 1
|
uses RDO for merge and skip, sa8d for all else
|
* RDO selection between merge and skip
* sa8d selection between (merge/skip) / inter modes / intra and split
* intra prediction uses reconstructed pixels
|
最终会调用
Analysis::compressInterCU_rd0_4:
|
|
rd-level 2
|
uses RDO for merge/skip and split
|
* RDO selection between merge and skip
* sa8d selection between (merge/skip) / inter modes / intra
* RDO split decisions
|
最终会调用
Analysis::compressInterCU_rd0_4:
|
|
rd-level 3
|
uses RDO for merge/skip/best inter/intra
|
* RDO selection between merge and skip 快速RDO
* sa8d selection of best inter mode
* sa8d decisions include chroma residual cost
* RDO selection between (merge/skip) / best inter mode / intra / split
|
最终会调用
Analysis::compressInterCU_rd0_4:
|
|
rd-level 4
|
enables RDOQuant
|
* chroma residual cost included in satd decisions, including subpel refine
* (as a result of --subme 3 being used by preset slow)
|
最终会调用
Analysis::compressInterCU_rd5_6:
|
|
rd-level 5,6
|
does RDO for each inter mode
|
最终会调用
Analysis::compressInterCU_rd5_6:
|
完整的P/BSlicce编码就是进行CTU递归划分子块,并进行运动搜索得到运动矢量,并且计算残差进行运动补偿,但是因为当前像素块的运动矢量除了通过搜索匹配(运动估计)得到之外,还可以通过空间上相邻像素块的运动矢量来估计得到,如果估计出来的运动矢量不会太大失真(计算rd代价)的话,当前CTU就可以提前退出 Analysis::compressInterCU_rd5_6 的递归,避免了后面的运动搜索和划分,也就是所谓的帧间快速编码算法。因为当前CTU递归划分下,当前子块的运动矢量可以通过其他块的运动矢量来预测,这些其他的块会从空间和时间上在当前块坐标周围选择几个生成候选列表,然后计算列表中失真代价最小的作为最佳参考运动矢量,也就是说最终得到的这个参考MV可能来自当前CTU空间上的相邻块,也可能来自当前CTU在时间上历史相邻块,编码端只需要传递候选列表索引。在解码端根据Merge或者AMVP模式建立相同的候选列表并根据索引找到参考MV,根据参考MV预测出当前块的MV。Merge和AMVP都是根据参考MV对矢量进行预测,但是区别是Merge不管预测值的残差,而Skip是一种特殊的 Merge 模式(残差为零),AMVP 称为高级矢量预测也就是传递参考MV以及预测残差以完美重建。注意 P/BSlicce 编码既可以帧间编码(也就是上面讲的的过程)也可以帧内编码。
帧间快速算法是代码占比很大的一部分,包含多种提前终止算法:
Merge/Skip:针对大面积的静止不动的部分,前一块A计算出运动矢量为0,后续相邻块BC计算的运动矢量也很可能为0,所以直接标记为跳过。只需要传递A的运动矢量,BC的skip标记即可。通过参考MV预测出来的MV不要残差重建YUV和真实YUV计算rdcost(skip),和带上残差重建YUV与真实YUV计算rdcost(merge)。
EarlySkip(SkipRecuision):根据CU复杂度判断是否需要对CTU进行进一步的递归划分。
SkipRectAmp:如果递归划分过程中父级 CTU 的最优尺寸是 2Nx2N,则跳过当前CTU的 AMP 划分的计算。
SkipIntra:如果递归划分过程中子CU的运动矢量最优预测模式都不是 Intra(帧内,空间上找相邻块的运动矢量来估计),则当前CU不进行 Intra(帧内,空间上找相邻块的运动矢量来估计)的计算。
Analysis::compressInterCU_rd0_4 函数源码流程:
Step 1:先判断能否 Merge/Skip 提前终止,因为大部分帧内容都是静止不动。由 Analysis::checkMerge2Nx2N_rd0_4() 计算 Merge 模式、Skip 模式的代价,这一步会构建预测候选列表并挨个计算 satd(sa8d) cost。有了最佳MV之后,计算真正的 rdo 代价。
Step 2:如果 skip 则跳过,否则将当前块四叉树划分 split 并挨个计算代价,根据YUV计算 sa8d,计算结果先放着,暂时先不和前面的 Merge/Skip 比较谁更优。
Step 3: 对当前块进行帧内预测(
AMVP、运动估计、运动补偿)、帧间预测(如果开启PBSlice的帧内预测),并计算各自最优,然后比较谁更优,然后再和第二部的 split 代价相比谁更优。
SplitData Analysis::compressInterCU_rd0_4(const CUData& parentCTU, const CUGeom& cuGeom, int32_t qp)
{
...
if (bHEVCBlockAnalysis || bRefineAVCAnalysis || bNooffloading)
{
md.bestMode = NULL;
// 是否需要继续划分的标记,后面会根据深度等信息来判断
bool mightSplit = !(cuGeom.flags & CUGeom::LEAF);
bool mightNotSplit = !(cuGeom.flags & CUGeom::SPLIT_MANDATORY);
// 每次递归进来都需要检测一下当前的深度大于 minDepth
uint32_t minDepth = topSkipMinDepth(parentCTU, cuGeom);
bool bDecidedDepth = parentCTU.m_cuDepth[cuGeom.absPartIdx] == depth;
bool skipModes = false; /* Skip any remaining mode analyses at current depth */
bool skipRecursion = false; /* Skip recursion */
bool splitIntra = true;
bool skipRectAmp = false;
bool chooseMerge = false;
bool bCtuInfoCheck = false;
int sameContentRef = 0;
......
/* Step 1. Evaluate Merge/Skip candidates for likely early-outs, if skip mode was not set above */
// 第一步计算 Merge/Skip 模式 RDO 代价判断是否可以提前终止递归
if ((mightNotSplit && depth >= minDepth && !md.bestMode && !bCtuInfoCheck) || (m_param->bAnalysisType == AVC_INFO && m_param->analysisLoadReuseLevel == 7 && (m_modeFlag[0] || m_modeFlag[1])))
/* TODO: Re-evaluate if analysis load/save still works */
{
/* Compute Merge Cost */
md.pred[PRED_MERGE].cu.initSubCU(parentCTU, cuGeom, qp);
md.pred[PRED_SKIP].cu.initSubCU(parentCTU, cuGeom, qp);
// 计算Merge模式和Skip模式的RD Cost,会建立候选列表并找出最优参考MV
checkMerge2Nx2N_rd0_4(md.pred[PRED_SKIP], md.pred[PRED_MERGE], cuGeom);
if (m_param->rdLevel)
skipModes = (m_param->bEnableEarlySkip || m_refineLevel == 2)
&& md.bestMode && md.bestMode->cu.isSkipped(0); // TODO: sa8d threshold per depth
}
if (md.bestMode && m_param->recursionSkipMode && !bCtuInfoCheck && !(m_param->bAnalysisType == AVC_INFO && m_param->analysisLoadReuseLevel == 7 && (m_modeFlag[0] || m_modeFlag[1])))
{
//前面已经比较过了 Merge和 Skip,如果 Skip 不是最佳模式则执行下面步骤
skipRecursion = md.bestMode->cu.isSkipped(0);
//如果 skip 不是最佳模式
if (mightSplit && !skipRecursion)
{
// 当前深度大于设置的最小深度,也就是还可以继续划分,并且递归跳过判断模式根据 rd-cost 最优做判断
if (depth >= minDepth && m_param->recursionSkipMode == RDCOST_BASED_RSKIP)
{
// 判断是否还需要进一步划分 recursionDepthCheck(基于rd-cost判断) /complexityCheckCU(基于纹理平坦度)
if (depth)
skipRecursion = recursionDepthCheck(parentCTU, cuGeom, *md.bestMode);
if (m_bHD && !skipRecursion && m_param->rdLevel == 2 && md.fencYuv.m_size != MAX_CU_SIZE)
skipRecursion = complexityCheckCU(*md.bestMode);
}
else if (cuGeom.log2CUSize >= MAX_LOG2_CU_SIZE - 1 && m_param->recursionSkipMode == EDGE_BASED_RSKIP)
{
skipRecursion = complexityCheckCU(*md.bestMode);
}
}
}
if (m_param->bAnalysisType == AVC_INFO && md.bestMode && cuGeom.numPartitions <= 16 && m_param->analysisLoadReuseLevel == 7)
skipRecursion = true;
/* Step 2. Evaluate each of the 4 split sub-blocks in series */
// 如果满足 skip 退出递归划分那么就可以跳过 step2,直接到 step3
// 如果不满足 skip 退出递归,则执行下列步骤,就需要当前块按照四叉树划分,并计算如果划分的话每个子块的预测代价
if (mightSplit && !skipRecursion)
{
.....
splitIntra = false;
// 划分4个子块,复制每个子块的 yuv
for (uint32_t subPartIdx = 0; subPartIdx < 4; subPartIdx++)
{
const CUGeom& childGeom = *(&cuGeom + cuGeom.childOffset + subPartIdx);
if (childGeom.flags & CUGeom::PRESENT)
{
m_modeDepth[0].fencYuv.copyPartToYuv(nd.fencYuv, childGeom.absPartIdx);
m_rqt[nextDepth].cur.load(*nextContext);
if (m_slice->m_pps->bUseDQP && nextDepth <= m_slice->m_pps->maxCuDQPDepth)
nextQP = setLambdaFromQP(parentCTU, calculateQpforCuSize(parentCTU, childGeom));
splitData[subPartIdx] = compressInterCU_rd0_4(parentCTU, childGeom, nextQP);
// 记录分割后的子块中是否由使用 Intra 的
splitIntra |= nd.bestMode->cu.isIntra(0);
splitCU->copyPartFrom(nd.bestMode->cu, childGeom, subPartIdx);
splitPred->addSubCosts(*nd.bestMode);
// 复制每个子块的 reconYUV到 rec 帧中用于下一个子块的预测
if (m_param->rdLevel)
nd.bestMode->reconYuv.copyToPartYuv(splitPred->reconYuv, childGeom.numPartitions * subPartIdx);
else
nd.bestMode->predYuv.copyToPartYuv(splitPred->predYuv, childGeom.numPartitions * subPartIdx);
if (m_param->rdLevel > 1)
nextContext = &nd.bestMode->contexts;
}
else
splitCU->setEmptyPart(childGeom, subPartIdx);
}
....
}
......
/* Split CUs
* 0 1
* 2 3 */
uint32_t allSplitRefs = splitData[0].splitRefs | splitData[1].splitRefs | splitData[2].splitRefs | splitData[3].splitRefs;
/* Step 3. Evaluate ME (2Nx2N, rect, amp) and intra modes at current depth */
// 第三步就是在当前划分深度下对各种划分方式计算运动估计代价、帧内模式代价
// 如果是走帧间预测编码就要划分 2Nx2N/2NxN/Nx2N/非对称AMP划分 并对每一种进行运动估计并进行残差的变换量化编码,求rd-cost
// 如果是走帧内预测同样对帧内每种预测方式求 rd-cost
if (mightNotSplit && (depth >= minDepth || (m_param->bCTUInfo && !md.bestMode)))
{
if (m_slice->m_pps->bUseDQP && depth <= m_slice->m_pps->maxCuDQPDepth && m_slice->m_pps->maxCuDQPDepth != 0)
setLambdaFromQP(parentCTU, qp);
if (!skipModes)
{
uint32_t refMasks[2];
refMasks[0] = allSplitRefs;
md.pred[PRED_2Nx2N].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = 2Nx2N AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_2Nx2N], cuGeom, SIZE_2Nx2N, refMasks);
if (m_param->limitReferences & X265_REF_LIMIT_CU)
{
CUData& cu = md.pred[PRED_2Nx2N].cu;
uint32_t refMask = cu.getBestRefIdx(0);
allSplitRefs = splitData[0].splitRefs = splitData[1].splitRefs = splitData[2].splitRefs = splitData[3].splitRefs = refMask;
}
// 当前CTU的Slice是BSlice的话需要开启
if (m_slice->m_sliceType == B_SLICE)
{
md.pred[PRED_BIDIR].cu.initSubCU(parentCTU, cuGeom, qp);
checkBidir2Nx2N(md.pred[PRED_2Nx2N], md.pred[PRED_BIDIR], cuGeom);
}
Mode *bestInter = &md.pred[PRED_2Nx2N];
// 矩形分区预测
if (!skipRectAmp)
{
if (m_param->bEnableRectInter)
{
.....
int try_2NxN_first = threshold_2NxN < threshold_Nx2N;
if (try_2NxN_first && splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_2NxN)
{
refMasks[0] = splitData[0].splitRefs | splitData[1].splitRefs; /* top */
refMasks[1] = splitData[2].splitRefs | splitData[3].splitRefs; /* bot */
md.pred[PRED_2NxN].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = 2NxN AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_2NxN], cuGeom, SIZE_2NxN, refMasks);
if (md.pred[PRED_2NxN].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_2NxN];
}
if (splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_Nx2N)
{
refMasks[0] = splitData[0].splitRefs | splitData[2].splitRefs; /* left */
refMasks[1] = splitData[1].splitRefs | splitData[3].splitRefs; /* right */
md.pred[PRED_Nx2N].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = Nx2N AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_Nx2N], cuGeom, SIZE_Nx2N, refMasks);
if (md.pred[PRED_Nx2N].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_Nx2N];
}
if (!try_2NxN_first && splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_2NxN)
{
refMasks[0] = splitData[0].splitRefs | splitData[1].splitRefs; /* top */
refMasks[1] = splitData[2].splitRefs | splitData[3].splitRefs; /* bot */
md.pred[PRED_2NxN].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = 2NxN AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_2NxN], cuGeom, SIZE_2NxN, refMasks);
if (md.pred[PRED_2NxN].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_2NxN];
}
}
if (m_slice->m_sps->maxAMPDepth > depth)
{
...
if (bHor)
{
int try_2NxnD_first = threshold_2NxnD < threshold_2NxnU;
if (try_2NxnD_first && splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_2NxnD)
{
refMasks[0] = allSplitRefs; /* 75% top */
refMasks[1] = splitData[2].splitRefs | splitData[3].splitRefs; /* 25% bot */
md.pred[PRED_2NxnD].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = 2NxnD AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_2NxnD], cuGeom, SIZE_2NxnD, refMasks);
if (md.pred[PRED_2NxnD].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_2NxnD];
}
if (splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_2NxnU)
{
refMasks[0] = splitData[0].splitRefs | splitData[1].splitRefs; /* 25% top */
refMasks[1] = allSplitRefs; /* 75% bot */
md.pred[PRED_2NxnU].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = 2NxnU AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_2NxnU], cuGeom, SIZE_2NxnU, refMasks);
if (md.pred[PRED_2NxnU].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_2NxnU];
}
if (!try_2NxnD_first && splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_2NxnD)
{
refMasks[0] = allSplitRefs; /* 75% top */
refMasks[1] = splitData[2].splitRefs | splitData[3].splitRefs; /* 25% bot */
md.pred[PRED_2NxnD].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = 2NxnD AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_2NxnD], cuGeom, SIZE_2NxnD, refMasks);
if (md.pred[PRED_2NxnD].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_2NxnD];
}
}
if (bVer)
{
int try_nRx2N_first = threshold_nRx2N < threshold_nLx2N;
if (try_nRx2N_first && splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_nRx2N)
{
refMasks[0] = allSplitRefs; /* 75% left */
refMasks[1] = splitData[1].splitRefs | splitData[3].splitRefs; /* 25% right */
md.pred[PRED_nRx2N].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = nRx2N AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_nRx2N], cuGeom, SIZE_nRx2N, refMasks);
if (md.pred[PRED_nRx2N].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_nRx2N];
}
if (splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_nLx2N)
{
refMasks[0] = splitData[0].splitRefs | splitData[2].splitRefs; /* 25% left */
refMasks[1] = allSplitRefs; /* 75% right */
md.pred[PRED_nLx2N].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = nLx2N AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_nLx2N], cuGeom, SIZE_nLx2N, refMasks);
if (md.pred[PRED_nLx2N].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_nLx2N];
}
if (!try_nRx2N_first && splitCost < md.pred[PRED_2Nx2N].sa8dCost + threshold_nRx2N)
{
refMasks[0] = allSplitRefs; /* 75% left */
refMasks[1] = splitData[1].splitRefs | splitData[3].splitRefs; /* 25% right */
md.pred[PRED_nRx2N].cu.initSubCU(parentCTU, cuGeom, qp);
// interMode = nRx2N AMVP计算、运动估计、运动补偿
checkInter_rd0_4(md.pred[PRED_nRx2N], cuGeom, SIZE_nRx2N, refMasks);
if (md.pred[PRED_nRx2N].sa8dCost < bestInter->sa8dCost)
bestInter = &md.pred[PRED_nRx2N];
}
}
}
}
// 如果是PSlice或者开始B帧情况下的BSlice则还可以将帧内编码纳入比较,后续进行帧内编码模式选择以及 rd-cost 计算
// 会调用 checkIntraInInter/encodeIntraInInter 计算帧内模式以及编码
bool bTryIntra = (m_slice->m_sliceType != B_SLICE || m_param->bIntraInBFrames) && cuGeom.log2CUSize != MAX_LOG2_CU_SIZE && !((m_param->bCTUInfo & 4) && bCtuInfoCheck);
// 3/4/5/6 的 rd-level 帧内预测模式选择(普通级别) 如果
if (m_param->rdLevel >= 3)
{
.....
if (!chooseMerge)
{
// 计算 inter 帧间最佳 interMode 的 rd-cost
encodeResAndCalcRdInterCU(*bestInter, cuGeom);
// 比较 最佳inter Skip/Merge 中最优
checkBestMode(*bestInter, depth);
/* If BIDIR is available and within 17/16 of best inter option, choose by RDO */
if (m_slice->m_sliceType == B_SLICE && md.pred[PRED_BIDIR].sa8dCost != MAX_INT64 &&
md.pred[PRED_BIDIR].sa8dCost * 16 <= bestInter->sa8dCost * 17)
{
uint32_t numPU = md.pred[PRED_BIDIR].cu.getNumPartInter(0);
if (m_frame->m_fencPic->m_picCsp == X265_CSP_I400 && m_csp != X265_CSP_I400)
for (uint32_t puIdx = 0; puIdx < numPU; puIdx++)
{
PredictionUnit pu(md.pred[PRED_BIDIR].cu, cuGeom, puIdx);
motionCompensation(md.pred[PRED_BIDIR].cu, pu, md.pred[PRED_BIDIR].predYuv, true, true);
}
encodeResAndCalcRdInterCU(md.pred[PRED_BIDIR], cuGeom);
checkBestMode(md.pred[PRED_BIDIR], depth);
}
}
// 如果运行PBSlice帧内编码
if ((bTryIntra && md.bestMode->cu.getQtRootCbf(0)) ||
md.bestMode->sa8dCost == MAX_INT64)
{
if (!m_param->limitReferences || splitIntra)
{
ProfileCounter(parentCTU, totalIntraCU[cuGeom.depth]);
md.pred[PRED_INTRA].cu.initSubCU(parentCTU, cuGeom, qp);
// 帧内预测编码
checkIntraInInter(md.pred[PRED_INTRA], cuGeom);
encodeIntraInInter(md.pred[PRED_INTRA], cuGeom);
// 再将前面 最佳inter Skip/Merge 中最优者再加入 intra 帧内比较得到最终最优
checkBestMode(md.pred[PRED_INTRA], depth);
}
else
{
ProfileCounter(parentCTU, skippedIntraCU[cuGeom.depth]);
}
}
}
// 0/1/2 的 rd-level 帧内预测模式选择(快速级别)
else
{
...
if (bTryIntra || md.bestMode->sa8dCost == MAX_INT64)
{
if (!m_param->limitReferences || splitIntra)
{
ProfileCounter(parentCTU, totalIntraCU[cuGeom.depth]);
md.pred[PRED_INTRA].cu.initSubCU(parentCTU, cuGeom, qp);
checkIntraInInter(md.pred[PRED_INTRA], cuGeom);
if (md.pred[PRED_INTRA].sa8dCost < md.bestMode->sa8dCost)
md.bestMode = &md.pred[PRED_INTRA];
}
else
{
ProfileCounter(parentCTU, skippedIntraCU[cuGeom.depth]);
}
}
.....
}
} // !earlyskip
if (m_bTryLossless)
tryLossless(cuGeom);
if (mightSplit)
addSplitFlagCost(*md.bestMode, cuGeom.depth);
}
// 前面已经比较过 Skip/Merge 最优Inter 最优Intra ,这里再将 SPLIT 模式纳入比较
if (mightSplit && !skipRecursion)
{
Mode* splitPred = &md.pred[PRED_SPLIT];
if (!md.bestMode)
md.bestMode = splitPred;
else if (m_param->rdLevel > 1)
checkBestMode(*splitPred, cuGeom.depth);
else if (splitPred->sa8dCost < md.bestMode->sa8dCost)
md.bestMode = splitPred;
checkDQPForSplitPred(*md.bestMode, cuGeom);
}
....
}
else
{
...
}
return splitCUData;
}【源码】Search::checkIntraInInter 和 Search::encodeIntraInInter
在 Analysis::compressInterCU_rd0_4 中 P/B 除了帧间预测之外还可以进行帧内预测,同样计算出帧内预测的最优模式选择并编码计算 rd-cost,最终才将所有编码方式进行综合判断。在经过判断后根据 bTryIntra 标记来判断是否调用这两个函数。
调用过程:
Analysis::compressInterCU_rd0_4() -> 判断 bTryIntra
Search::checkIntraInInter() 使用 sa8d 计算最佳帧内模式
Search::encodeIntraInInter() 亮度色度编码
Search::checkIntraInInter,找到最优帧内预测方向,DC?PNANAR?angle2~34?并记录最优帧内预测方向的sa8d、bits和cost,过程:
1.设置partSize为2Nx2N,predMode为intra
2.加载neighbor可用参考信息
3.对neighbor参考像素进行填充,并平滑滤波
4.若TU大小为64x64,则将其收缩到32x32,为什么要这么做?
5.进行DC预测计算,得到sa8d、bits、cost开销,初始化为最优帧内预测bestMode
6.进行PLANAR预测计算,得到sa8d、bits、cost开销,更新最优帧内预测bestMode
7.进行angle2~34预测计算
开启快速帧内预测方向决定
1.在5、10、15、20、25、30里面根据cost选择最优mode1
2.在最优mode1的±2个角度之内选择最优mode2
3.若最优mode2=33,则再计算下角度34,选择最优mode3
4.更新最优帧内预测bestMode
否则,遍历angle2~34进行预测计算,更新最优帧内预测bestMode
8.记录下最优帧内预测bestMode及其sa8d、bits和cost
void Search::checkIntraInInter(Mode& intraMode, const CUGeom& cuGeom)
{
ProfileCUScope(intraMode.cu, intraAnalysisElapsedTime, countIntraAnalysis);
CUData& cu = intraMode.cu;
uint32_t depth = cuGeom.depth;
//设置partSize为2Nx2N
cu.setPartSizeSubParts(SIZE_2Nx2N);
//设置predMode为intra
cu.setPredModeSubParts(MODE_INTRA);
const uint32_t initTuDepth = 0;
uint32_t log2TrSize = cuGeom.log2CUSize - initTuDepth;
uint32_t tuSize = 1 << log2TrSize;
const uint32_t absPartIdx = 0;
// Reference sample smoothing 初始化向量宏块像素
IntraNeighbors intraNeighbors;
//得到相邻CU的可用信息
initIntraNeighbors(cu, absPartIdx, initTuDepth, true, &intraNeighbors);
//对相邻CU的参考像素进行平滑滤波预处理
initAdiPattern(cu, cuGeom, absPartIdx, intraNeighbors, ALL_IDX);
//原始YUV及其stride
const pixel* fenc = intraMode.fencYuv->m_buf[0];
uint32_t stride = intraMode.fencYuv->m_size;
int sad, bsad;
uint32_t bits, bbits, mode, bmode;
uint64_t cost, bcost;
// 33 Angle modes once
int scaleTuSize = tuSize;
int scaleStride = stride;
int costShift = 0;
int sizeIdx = log2TrSize - 2;
if (tuSize > 32) //若tu的大小为64x64
{
// CU is 64x64, we scale to 32x32 and adjust required parameters
//将64x64伸缩成32x32
primitives.scale2D_64to32(m_fencScaled, fenc, stride);
fenc = m_fencScaled;
pixel nScale[129];
//将为filter的neighbor像素拷贝
intraNeighbourBuf[1][0] = intraNeighbourBuf[0][0];
primitives.scale1D_128to64[NONALIGNED](nScale + 1, intraNeighbourBuf[0] + 1);
// we do not estimate filtering for downscaled samples
memcpy(&intraNeighbourBuf[0][1], &nScale[1], 2 * 64 * sizeof(pixel)); // Top & Left pixels
memcpy(&intraNeighbourBuf[1][1], &nScale[1], 2 * 64 * sizeof(pixel));
scaleTuSize = 32;
scaleStride = 32;
costShift = 2;
sizeIdx = 5 - 2; // log2(scaleTuSize) - 2
}
pixelcmp_t sa8d = primitives.cu[sizeIdx].sa8d;
int predsize = scaleTuSize * scaleTuSize;
m_entropyCoder.loadIntraDirModeLuma(m_rqt[depth].cur);
/* there are three cost tiers for intra modes:
* pred[0] - mode probable, least cost
* pred[1], pred[2] - less probable, slightly more cost
* non-mpm modes - all cost the same (rbits) */
uint64_t mpms;
uint32_t mpmModes[3];
//计算mpms映射和三个mpmModes,得到未命中mpm时候的bits开销
uint32_t rbits = getIntraRemModeBits(cu, absPartIdx, mpmModes, mpms);
/* 进行DC预测计算 */
//DC预测,输出到m_intraPredAngs
primitives.cu[sizeIdx].intra_pred[DC_IDX](m_intraPredAngs, scaleStride, intraNeighbourBuf[0], 0, (scaleTuSize <= 16));
//计算sa8d
bsad = sa8d(fenc, scaleStride, m_intraPredAngs, scaleStride) << costShift;
//存储mode
bmode = mode = DC_IDX;
//计算bits
bbits = (mpms & ((uint64_t)1 << mode)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, mode) : rbits;
//计算rdcost = sa8d + lambda * mode_bits,计算的比较粗略
bcost = m_rdCost.calcRdSADCost(bsad, bbits);
/* 进行PLANAR预测计算 */
pixel* planar = intraNeighbourBuf[0];
if (tuSize & (8 | 16 | 32))
planar = intraNeighbourBuf[1];
//进行PLANAR预测
primitives.cu[sizeIdx].intra_pred[PLANAR_IDX](m_intraPredAngs, scaleStride, planar, 0, 0);
//计算sa8d
sad = sa8d(fenc, scaleStride, m_intraPredAngs, scaleStride) << costShift;
//存储mode
mode = PLANAR_IDX;
//计算bits
bits = (mpms & ((uint64_t)1 << mode)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, mode) : rbits;
//计算rdcost = sa8d + lambda * mode_bits,计算的比较粗略
cost = m_rdCost.calcRdSADCost(sad, bits);
/* 选择DC和PLANAR之间的较优,存储到bcost、bmode、bsad和bbits中 */
COPY4_IF_LT(bcost, cost, bmode, mode, bsad, sad, bbits, bits);
bool allangs = true;
//若存在intra_pred_allangs函数,则通过其计算angle
if (primitives.cu[sizeIdx].intra_pred_allangs)
{
//对CU进行转置
primitives.cu[sizeIdx].transpose(m_fencTransposed, fenc, scaleStride);
//进行33种angle预测计算,将它们输出到m_intraPredAngs中
primitives.cu[sizeIdx].intra_pred_allangs(m_intraPredAngs, intraNeighbourBuf[0], intraNeighbourBuf[1], (scaleTuSize <= 16));
}
else
allangs = false;
/*
定义angle预测计算函数 try_angle(angle)
*/
#define TRY_ANGLE(angle) \
if (allangs) { \
if (angle < 18) \
sad = sa8d(m_fencTransposed, scaleTuSize, &m_intraPredAngs[(angle - 2) * predsize], scaleTuSize) << costShift; \
else \
sad = sa8d(fenc, scaleStride, &m_intraPredAngs[(angle - 2) * predsize], scaleTuSize) << costShift; \
bits = (mpms & ((uint64_t)1 << angle)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, angle) : rbits; \
cost = m_rdCost.calcRdSADCost(sad, bits); \
} else { \
int filter = !!(g_intraFilterFlags[angle] & scaleTuSize); \
primitives.cu[sizeIdx].intra_pred[angle](m_intraPredAngs, scaleTuSize, intraNeighbourBuf[filter], angle, scaleTuSize <= 16); \
sad = sa8d(fenc, scaleStride, m_intraPredAngs, scaleTuSize) << costShift; \
bits = (mpms & ((uint64_t)1 << angle)) ? m_entropyCoder.bitsIntraModeMPM(mpmModes, angle) : rbits; \
cost = m_rdCost.calcRdSADCost(sad, bits); \
}
/*
结束TRY_ANGLE(angle)函数定义
*/
//若使用intra快速决定
if (m_param->bEnableFastIntra)
{
int asad = 0;
uint32_t lowmode, highmode, amode = 5, abits = 0;
uint64_t acost = MAX_INT64;
/* pick the best angle, sampling at distance of 5
五个一跨度计算最优angle */
for (mode = 5; mode < 35; mode += 5)
{
TRY_ANGLE(mode);
COPY4_IF_LT(acost, cost, amode, mode, asad, sad, abits, bits);
}
/* refine best angle at distance 2, then distance 1
在之前五个一跨度计算的最优angle上下个计算两个angle,找到最优 */
for (uint32_t dist = 2; dist >= 1; dist--)
{
lowmode = amode - dist;
highmode = amode + dist;
//下angle合法检查
X265_CHECK(lowmode >= 2 && lowmode <= 34, "low intra mode out of range\n");
//下angle预测计算
TRY_ANGLE(lowmode);
//更新最优
COPY4_IF_LT(acost, cost, amode, lowmode, asad, sad, abits, bits);
//上angle合法检查
X265_CHECK(highmode >= 2 && highmode <= 34, "high intra mode out of range\n");
//上angle预测计算
TRY_ANGLE(highmode);
//更新最优
COPY4_IF_LT(acost, cost, amode, highmode, asad, sad, abits, bits);
}
//若最优angle为33,则尝试angle34。因为该算法无法到达angle34
if (amode == 33)
{
TRY_ANGLE(34);
COPY4_IF_LT(acost, cost, amode, 34, asad, sad, abits, bits);
}
//在DC、PLANR和angle间选择最优
COPY4_IF_LT(bcost, acost, bmode, amode, bsad, asad, bbits, abits);
}
//若不使用intra快速决定,则所有angle全遍历
else // calculate and search all intra prediction angles for lowest cost
{
for (mode = 2; mode < 35; mode++)
{
TRY_ANGLE(mode);
COPY4_IF_LT(bcost, cost, bmode, mode, bsad, sad, bbits, bits);
}
}
//记录最优预测方向
cu.setLumaIntraDirSubParts((uint8_t)bmode, absPartIdx, depth + initTuDepth);
//初始化intraMode的开销,并存储最优帧内预测方向的bits、sa8d以及cost
intraMode.initCosts();
intraMode.totalBits = bbits;
intraMode.distortion = bsad;
intraMode.sa8dCost = bcost;
intraMode.sa8dBits = bbits;
}【源码】Anaylsis::checkMerge2Nx2N_rd0_4
该函数就是计算 Merge/Skip ,用于后续判断 Skip 是否胜出。
调用顺序:
Anaylsis::compressInterCU_rd0_4() ->
Anaylsis::checkMerge2Nx2N_rd0_4()
流程:
/*
对CU进行merge和skip开销计算,并选择最优。
过程:
1.取当前CU的depth/modeDepth和编码YUV数据
2.构建当前CU的merge备选集
3.遍历每一个备选集,得到最优备选MV
1.对当前备选MV进行motionCompensation运动补偿
2.计算当前备选MV的bits(字节数)/distortion(失真)以及rdcost(率失真损失)
3.根据rdcost更新bestPred(最优参考MV,后续AMVP计算以及运动估计起始点用到)
4.若无最优备选MV,则return,该CU不适合merge
5.执行encodeResAndCalcRdSkipCU,得到在最优备选MV下无残差 skip 模式的rdcost
6.执行encodeResAndCalcRdInterCU,得到在最优备选MV下有残存 merge 模式下的rdcost
7.根据skip和merge模式下的rdcost,选择最优模式给予该CU的bestMode
8.将最优备选MV信息给予CU
*/
void Analysis::checkMerge2Nx2N_rd0_4(Mode& skip, Mode& merge, const CUGeom& cuGeom)
{
// 取当前CU的划分深度、YUV
uint32_t depth = cuGeom.depth;
ModeDepth& md = m_modeDepth[depth];
Yuv *fencYuv = &md.fencYuv;
Mode* tempPred = &merge;
Mode* bestPred = &skip;
X265_CHECK(m_slice->m_sliceType != I_SLICE, "Evaluating merge in I slice\n");
// 初始化 tempPred的 cost、size=2Nx2N、mode=inter、mergeFlag=true
tempPred->initCosts();
tempPred->cu.setPartSizeSubParts(SIZE_2Nx2N);
tempPred->cu.setPredModeSubParts(MODE_INTER);
tempPred->cu.m_mergeFlag[0] = true;
// 初始化 bestPred的 cost、size=2Nx2N、mode=inter、mergeFlag=true
bestPred->initCosts();
bestPred->cu.setPartSizeSubParts(SIZE_2Nx2N);
bestPred->cu.setPredModeSubParts(MODE_INTER);
bestPred->cu.m_mergeFlag[0] = true;
// 用于存储候选块的MV
MVField candMvField[MRG_MAX_NUM_CANDS][2];
uint8_t candDir[MRG_MAX_NUM_CANDS];
// 构建候选列表 getInterMergeCandidates 将候选列表保存在 candMvField 变量中
uint32_t numMergeCand = tempPred->cu.getInterMergeCandidates(0, 0, candMvField, candDir);
// 构造PU
PredictionUnit pu(merge.cu, cuGeom, 0);
bestPred->sa8dCost = MAX_INT64;
int bestSadCand = -1;
int sizeIdx = cuGeom.log2CUSize - 2;
int safeX, maxSafeMv;
// PSlice开启了正帧内刷新
if (m_param->bIntraRefresh && m_slice->m_sliceType == P_SLICE)
{
safeX = m_slice->m_refFrameList[0][0]->m_encData->m_pir.pirEndCol * m_param->maxCUSize - 3;
maxSafeMv = (safeX - tempPred->cu.m_cuPelX) * 4;
}
// 遍历候选列表中最优的参考 MV,这里便利所有候选 MV 计算 satd-cost
// 注意区别 satd-cost 和 rd-cost 的区别,前者根据像素块重建评估预测是否准确,后者是通过变换量化编码评估是否满足一定的率失真水平
// 计算得到的最优MV保存在 bestPred 中
for (uint32_t i = 0; i < numMergeCand; ++i)
{
...
// 当前为PSlice并且开启了帧内刷新,如果备选集超过安全区域则当前备选MV无效,continue跳过计算下一个
if (m_param->bIntraRefresh && m_slice->m_sliceType == P_SLICE &&
tempPred->cu.m_cuPelX / m_param->maxCUSize < m_frame->m_encData->m_pir.pirEndCol &&
candMvField[i][0].mv.x > maxSafeMv)
// skip merge candidates which reference beyond safe reference area
continue;
tempPred->cu.m_mvpIdx[0][0] = (uint8_t)i; // merge candidate ID is stored in L0 MVP idx
X265_CHECK(m_slice->m_sliceType == B_SLICE || !(candDir[i] & 0x10), " invalid merge for P slice\n");
tempPred->cu.m_interDir[0] = candDir[i];
tempPred->cu.m_mv[0][0] = candMvField[i][0].mv;
tempPred->cu.m_mv[1][0] = candMvField[i][1].mv;
tempPred->cu.m_refIdx[0][0] = (int8_t)candMvField[i][0].refIdx;
tempPred->cu.m_refIdx[1][0] = (int8_t)candMvField[i][1].refIdx;
// 运动补偿,也就是计算运动前后YUV的残差
motionCompensation(tempPred->cu, pu, tempPred->predYuv, true, m_bChromaSa8d && (m_csp != X265_CSP_I400 && m_frame->m_fencPic->m_picCsp != X265_CSP_I400));
// 开始计算亮度失真
tempPred->sa8dBits = getTUBits(i, numMergeCand);
tempPred->distortion = primitives.cu[sizeIdx].sa8d(fencYuv->m_buf[0], fencYuv->m_size, tempPred->predYuv.m_buf[0], tempPred->predYuv.m_size);
// 如果有色度也需要计算色度失真并累加
if (m_bChromaSa8d && (m_csp != X265_CSP_I400 && m_frame->m_fencPic->m_picCsp != X265_CSP_I400))
{
tempPred->distortion += primitives.chroma[m_csp].cu[sizeIdx].sa8d(fencYuv->m_buf[1], fencYuv->m_csize, tempPred->predYuv.m_buf[1], tempPred->predYuv.m_csize);
tempPred->distortion += primitives.chroma[m_csp].cu[sizeIdx].sa8d(fencYuv->m_buf[2], fencYuv->m_csize, tempPred->predYuv.m_buf[2], tempPred->predYuv.m_csize);
}
tempPred->sa8dCost = m_rdCost.calcRdSADCost((uint32_t)tempPred->distortion, tempPred->sa8dBits);
// 取最优 satd-cost 所在的参考 MV
if (tempPred->sa8dCost < bestPred->sa8dCost)
{
bestSadCand = i;
std::swap(tempPred, bestPred);
}
}
// skip/merge 不支持则直接返回
if (bestSadCand < 0)
return;
// 色度运动补偿
if ((!m_bChromaSa8d && (m_csp != X265_CSP_I400)) || (m_frame->m_fencPic->m_picCsp == X265_CSP_I400 && m_csp != X265_CSP_I400)) /* Chroma MC was done above */
motionCompensation(bestPred->cu, pu, bestPred->predYuv, false, true);
if (m_param->rdLevel)
{
// 无损编码则不使用 skip
if (m_param->bLossless)
bestPred->rdCost = MAX_INT64;
else
// 计算 SKIP 模式的 RDO,得到真正得 RD-Cost,需要变换、量化、熵编码
encodeResAndCalcRdSkipCU(*bestPred);
// 前面计算的是无残差的失真也就是skip,这里计算有残差的失真也就是merge
tempPred->cu.m_mvpIdx[0][0] = (uint8_t)bestSadCand;
tempPred->cu.setPUInterDir(candDir[bestSadCand], 0, 0);
tempPred->cu.setPUMv(0, candMvField[bestSadCand][0].mv, 0, 0);
tempPred->cu.setPUMv(1, candMvField[bestSadCand][1].mv, 0, 0);
tempPred->cu.setPURefIdx(0, (int8_t)candMvField[bestSadCand][0].refIdx, 0, 0);
tempPred->cu.setPURefIdx(1, (int8_t)candMvField[bestSadCand][1].refIdx, 0, 0);
tempPred->sa8dCost = bestPred->sa8dCost;
tempPred->sa8dBits = bestPred->sa8dBits;
tempPred->predYuv.copyFromYuv(bestPred->predYuv);
// 计算 Merge 模式的 RDO,得到真正得 RD-Cost,需要变换、量化、熵编码
encodeResAndCalcRdInterCU(*tempPred, cuGeom);
// Merge 和 Skip 模式比较返回最优模式,是根据 RDO 来比较的
md.bestMode = tempPred->rdCost < bestPred->rdCost ? tempPred : bestPred;
}
else
md.bestMode = bestPred;
md.bestMode->cu.setPUInterDir(candDir[bestSadCand], 0, 0);
// 记录前后向MV
md.bestMode->cu.setPUMv(0, candMvField[bestSadCand][0].mv, 0, 0);
md.bestMode->cu.setPUMv(1, candMvField[bestSadCand][1].mv, 0, 0);
// 记录前后向参考帧所有 refIdx
md.bestMode->cu.setPURefIdx(0, (int8_t)candMvField[bestSadCand][0].refIdx, 0, 0);
md.bestMode->cu.setPURefIdx(1, (int8_t)candMvField[bestSadCand][1].refIdx, 0, 0);
checkDQP(*md.bestMode, cuGeom);
}【源码】Anaysis::checkInter_rd0_4
在计算完 Merge/Skip 模式之后,还需要进行 AMVP 模式的判断,因为AMVP相比 Merge/Skip之外需要计算真实运动矢量减去估计运动矢量得到残差。也就是需要知道真实的运动矢量,就需要进行运动估计。另外运动估计还需要AMVP的最优MV所在块的位置作为搜索起始点,所以 AMVP 和 运动估计、运动补偿都顺带在这一个函数作为入口实现的。
函数需要传入 interMode ,也就是帧间分割形式,也就是 AMP 技术,帧间预测进行运动估计和补偿时可以将PU按照不同的矩形划分(开启了AMP矩形划分的帧间预测)。这个方法就时
就是为了处理 rect(矩形)、amp(非对称)等等不同形状的运动估计。
调用顺序:
Anaylsis::compressInterCU_rd0_4() -> 帧间编码入口函数
Anaylsis::
checkInter_rd0_4
() -> 计算AMVP、调用运动搜索、调用运动估计,调用后续的
predInterSearch()函数。函数最终得到当前CU每个PU在指定 interMode 帧间预测的 rd-cost。
源码:
/*
* 帧间预测:当前CU划分下,指定 interMode形状划分的帧间预测编码实现
* */
void Analysis::checkInter_rd0_4(Mode& interMode, const CUGeom& cuGeom, PartSize partSize, uint32_t refMask[2])
{
interMode.initCosts();
interMode.cu.setPartSizeSubParts(partSize);
interMode.cu.setPredModeSubParts(MODE_INTER);
int numPredDir = m_slice->isInterP() ? 1 : 2;//单项预测/双向预测
if (m_param->analysisLoadReuseLevel > 1 && m_param->analysisLoadReuseLevel != 10 && m_reuseInterDataCTU)
{
int refOffset = cuGeom.geomRecurId * 16 * numPredDir + partSize * numPredDir * 2;
int index = 0;
// 当前CU中预测单元PU的个数
uint32_t numPU = interMode.cu.getNumPartInter(0);
// 针对每个PU初始化 ref
for (uint32_t part = 0; part < numPU; part++)
{
MotionData* bestME = interMode.bestME[part];
for (int32_t i = 0; i < numPredDir; i++)
bestME[i].ref = m_reuseRef[refOffset + index++];
}
}
...
// 运动估计,根据当前的 interMode 划分计算返回运动矢量和参考帧序号,注意里面对每个PU都执行了计算
predInterSearch(interMode, cuGeom, m_bChromaSa8d && (m_csp != X265_CSP_I400 && m_frame->m_fencPic->m_picCsp != X265_CSP_I400), refMask);
const Yuv& fencYuv = *interMode.fencYuv;//原始真实YUV
Yuv& predYuv = interMode.predYuv;//预测得到的YUV
int part = partitionFromLog2Size(cuGeom.log2CUSize);
// 计算帧内预测失真(这一步只算了亮度)
interMode.distortion = primitives.cu[part].sa8d(fencYuv.m_buf[0], fencYuv.m_size, predYuv.m_buf[0], predYuv.m_size);
// 如果有亮度,也计算亮度失真并且累加上去
if (m_bChromaSa8d && (m_csp != X265_CSP_I400 && m_frame->m_fencPic->m_picCsp != X265_CSP_I400))
{
interMode.distortion += primitives.chroma[m_csp].cu[part].sa8d(fencYuv.m_buf[1], fencYuv.m_csize, predYuv.m_buf[1], predYuv.m_csize);
interMode.distortion += primitives.chroma[m_csp].cu[part].sa8d(fencYuv.m_buf[2], fencYuv.m_csize, predYuv.m_buf[2], predYuv.m_csize);
}
// 根据失真和码率,计算 rd-cost
interMode.sa8dCost = m_rdCost.calcRdSADCost((uint32_t)interMode.distortion, interMode.sa8dBits);
if (m_param->analysisSaveReuseLevel > 1 && m_reuseInterDataCTU)
{
int refOffset = cuGeom.geomRecurId * 16 * numPredDir + partSize * numPredDir * 2;
int index = 0;
// 遍历每个PU 保存其 ref
uint32_t numPU = interMode.cu.getNumPartInter(0);
for (uint32_t puIdx = 0; puIdx < numPU; puIdx++)
{
MotionData* bestME = interMode.bestME[puIdx];
for (int32_t i = 0; i < numPredDir; i++)
m_reuseRef[refOffset + index++] = bestME[i].ref;
}
}
}【源码】Search::predInterSearch
在帧间编码中需要进行运动估计,Search::predInterSearch中实现运动估计,返回运动矢量和参考帧的序号。运动估计需要确定搜索起始点,是根据AMVP候选列表最优参考MV对应像素块为起始点。
调用顺序:
Anaylsis::compressInterCU_rd0_4() -> 帧间编码
Anaylsis::
checkInter_rd0_4
() -> 计算AMVP最优参考MV,为起始点
Search::predInterSearch() 设置搜索返回开始进行搜索,也就是运动估计
流程:
/*
为CU中的每一个PU找到最佳inter pred,并累加上其ME cost 。 最佳inter pred指的是mv,mvd,mvpIdx,dir,list等
过程:
1.遍历每一个PU,以PU为计算单位
1.为运动估计加载PU的YUV,初始化失真函数指针,设置运动估计方法及下采样等级
2.进行merge估计,得到最优merge备选MV及其cost
3.初始化前后向运动估计bestME[dir]开销为MAX,用来存储当前运动方向上的最优预测
4.得到当前block模式的bits开销
5.加载当前PU相邻PU的MV
6.初始化前后向运动估计的ref,加载其refMask
7.对当前PU,针对其每个预测方向(前向/后向)遍历,找到当前预测方向上的最优预测bestME[dir]
1.对当前PU,当前预测方向,遍历参考帧列表中每一帧
1.若refMask表示当前参考帧不可用,则跳过该参考帧分析
2.累计bits = block模式bits + mvp_idx_bits + refIdx_bits
3.构造AMVP备选集
4.基于sad,选择AMVP备选集中最优MVP
5.根据最优MVP及searchRange设置运动估计搜索窗口
6.进行运动估计,得到最优MV及其satd
7.累计bits+=AMVP最优MVP与运动估计最优MV之差的bits
8.计算运动估计最优MV的mvcost
9.得到最优MV的cost
10.若当前cost小于bestME[dir]的cost,则更新
8.若是Bslice,且没有双向预测限制,且PUsize!=2Nx2N,且前后向都又bestME,则进行双向预测计算
1.取前后向的bestME为双向预测的前后向MV
2.计算satd
·若bChromaSATD,则
1.拷贝前后向的MV及其refIdx
2.进行运动估计
3.累加Luma和Chroma的satd到satd
·若非bChromaSATD,则
1.取前后向参考帧的YUV
2.对前后向参考像素进行均值计算,结果即为双向参考预测像素
3.计算其satd
3.计算双向预测的bits及cost
4.若前后向运动估计最优MV存在非0向量,则以0向量为中心重新设置搜索窗口,并检查mvp是否超出窗口
5.若前后向运动估计最优MV存在非0向量,且mvp都没有超出搜索窗口,则
·若bChromaSATD
1.则设置mv为0向量
2.进行运动补偿
3.并计算重新累计luma和chroma的satd
·若非bChromaSATD
1.取前后向参考帧co-located像素值(其实也就是0向量)
2.对前后向参考帧co-located像素值进行均值计算,得到0向量的预测像素
3.进行satd计算
6.以0向量为运动估计最优MV,重新计算MVP,得到其mvp, mvpidx, bits, cost
7.若MV为0向量且重新计算后的mvp的cost小于最初计算的双向预测cost,则将其更新为双向预测最优
9.为当前PU选择最优的预测模式
·merge最优,写mergeFlag为true、记录mergeIdx、将merge前后向的MV和refIdx记录到PU
·双向最优,设置PU预测方向为双向,写mergeFlag为false、将双向预测前后向的MV和refIdx记录到PU,记录双向mvpIdx和mvd
·前向最优,设置PU预测方向为前向,写mergeFlag为false、将前向预测的MV和refIdx记录到PU,记录前向mvpIdx和mvd
·后向最优,设置PU预测方向为后向,写mergeFlag为false、将后向预测的MV和refIdx记录到PU,记录后向mvpIdx和mvd
10.对当前PU的最优预测模式进行运动补偿
2.累加上运动估计的bits到当前interMode的bits上,并返回
*/
调用的几个核心函数如下:
int numMvc = cu.getPMV(interMode.interNeighbours, list, ref, interMode.amvpCand[list][ref], mvc); //加载AMVP备选集到amvpCand中
int mvpIdx = selectMVP(cu, pu, amvp, list, ref); //选择AMVP备选集中最优备选MV,基于sad开销,用于确定运动估计起始点
mvp = checkBestMVP(amvp, outmv, mvpIdx, bits, cost); //确定是否有更优的MPV
m_me.motionEstimate(); //运动估计
motionCompensation(cu, pu, *predYuv, true, bChromaMC); // 根据最优的模式重建 YUV 然后进行运动补偿,也就是计算残差
源码:
void Search::predInterSearch(Mode& interMode, const CUGeom& cuGeom, bool bChromaMC, uint32_t refMasks[2])
{
std::cout << "encoder/serach.cpp Search::predInterSearch()" << std::endl;
ProfileCUScope(interMode.cu, motionEstimationElapsedTime, countMotionEstimate);
CUData& cu = interMode.cu;
Yuv* predYuv = &interMode.predYuv;
// 12 mv candidates including lowresMV
// 这个是 lookHead 时对1/2下采样后的帧进行运动估计的MV
MV mvc[(MD_ABOVE_LEFT + 1) * 2 + 2];
const Slice *slice = m_slice;
int numPart = cu.getNumPartInter(0);
// 单向预测?双向预测?
int numPredDir = slice->isInterP() ? 1 : 2;
// 参考帧列表中的帧数量
const int* numRefIdx = slice->m_numRefIdx;
//lastMode记录上一个PU的dir,前向0后向1双向2
uint32_t lastMode = 0;
int totalmebits = 0;
MV mvzero(0, 0);
Yuv& tmpPredYuv = m_rqt[cuGeom.depth].tmpPredYuv;
MergeData merge;
memset(&merge, 0, sizeof(merge));
bool useAsMVP = false;
// 一个CU中,遍历每个PU预测单元
for (int puIdx = 0; puIdx < numPart; puIdx++)
{
// 获取当前PU的 bestME
MotionData* bestME = interMode.bestME[puIdx];
PredictionUnit pu(cu, cuGeom, puIdx);
//为m_me加载PU的YUV,并初始化失真计算函数指针,设置运动估计方法及下采样等级
m_me.setSourcePU(*interMode.fencYuv, pu.ctuAddr, pu.cuAbsPartIdx, pu.puAbsPartIdx, pu.width, pu.height, m_param->searchMethod, m_param->subpelRefine, bChromaMC);
//初始化useAsMVP为false
useAsMVP = false;
//定义初始化x265_analysis_inter_data
x265_analysis_inter_data* interDataCTU = NULL;
//定义并计算当前CU的索引
int cuIdx;
cuIdx = (interMode.cu.m_cuAddr * m_param->num4x4Partitions) + cuGeom.absPartIdx;
if (m_param->analysisLoadReuseLevel == 10 && m_param->interRefine > 1)
{
//加载API外加载的编码分析数据
interDataCTU = m_frame->m_analysisData.interData;
if ((cu.m_predMode[pu.puAbsPartIdx] == interDataCTU->modes[cuIdx + pu.puAbsPartIdx])
&& (cu.m_partSize[pu.puAbsPartIdx] == interDataCTU->partSize[cuIdx + pu.puAbsPartIdx])
&& !(interDataCTU->mergeFlag[cuIdx + puIdx])
&& (cu.m_cuDepth[0] == interDataCTU->depth[cuIdx]))
useAsMVP = true;
}
/* find best cost merge candidate. note: 2Nx2N merge and bidir are handled as separate modes */
// 找到最优merge备选集,并返回其cost
uint32_t mrgCost = numPart == 1 ? MAX_UINT : mergeEstimation(cu, cuGeom, pu, puIdx, merge);
bestME[0].cost = MAX_UINT;
bestME[1].cost = MAX_UINT;
//得到block模式(模式包含partSize和预测方向)的bits开销,即2Nx2N、2NxN、2NxnU等等
getBlkBits((PartSize)cu.m_partSize[0], slice->isInterP(), puIdx, lastMode, m_listSelBits);
bool bDoUnidir = true;
//加载当前PU相邻MV备选集到interNeighbours中,这里是构建AMVP备选
cu.getNeighbourMV(puIdx, pu.puAbsPartIdx, interMode.interNeighbours);
/* Uni-directional prediction */
if ((m_param->analysisLoadReuseLevel > 1 && m_param->analysisLoadReuseLevel != 10)
|| (m_param->analysisMultiPassRefine && m_param->rc.bStatRead) || (m_param->bAnalysisType == AVC_INFO) || (useAsMVP))
{
//遍历前后向参考方向
for (int list = 0; list < numPredDir; list++)
{
int ref = -1;
//加载当前PU当前预测方向上的ref
if (useAsMVP)
ref = interDataCTU->refIdx[list][cuIdx + puIdx];
else
ref = bestME[list].ref;
//若仍然无ref,则该参考方向不可用,continue
if (ref < 0)
{
continue;
}
uint32_t bits = m_listSelBits[list] + MVP_IDX_BITS;
bits += getTUBits(ref, numRefIdx[list]);
//加载AMVP备选集到amvpCand中
int numMvc = cu.getPMV(interMode.interNeighbours, list, ref, interMode.amvpCand[list][ref], mvc);
//取AMVP备选集
const MV* amvp = interMode.amvpCand[list][ref];
//选择AMVP备选集中最优备选MV,基于sad开销,用于确定运动估计起始点
int mvpIdx = selectMVP(cu, pu, amvp, list, ref);
MV mvmin, mvmax, outmv, mvp;
//取最优AMVP备选MV
if (useAsMVP)
{
mvp = interDataCTU->mv[list][cuIdx + puIdx].word;
mvpIdx = interDataCTU->mvpIdx[list][cuIdx + puIdx];
}
else
mvp = amvp[mvpIdx];
if (m_param->searchMethod == X265_SEA)
{
int puX = puIdx & 1;
int puY = puIdx >> 1;
for (int planes = 0; planes < INTEGRAL_PLANE_NUM; planes++)
m_me.integral[planes] = interMode.fencYuv->m_integral[list][ref][planes] + puX * pu.width + puY * pu.height * m_slice->m_refFrameList[list][ref]->m_reconPic->m_stride;
}
//根据mvp计算搜索范围,输出到[mvmin,mvmax]
setSearchRange(cu, mvp, m_param->searchRange, mvmin, mvmax);
MV mvpIn = mvp;
int satdCost;
if (m_param->analysisMultiPassRefine && m_param->rc.bStatRead && mvpIdx == bestME[list].mvpIdx)
mvpIn = bestME[list].mv;
if (useAsMVP && m_param->mvRefine > 1)
{
MV bestmv, mvpSel[3];
int mvpIdxSel[3];
satdCost = m_me.COST_MAX;
mvpSel[0] = mvp;
mvpIdxSel[0] = mvpIdx;
mvpIdx = selectMVP(cu, pu, amvp, list, ref);
mvpSel[1] = interMode.amvpCand[list][ref][mvpIdx];
mvpIdxSel[1] = mvpIdx;
if (m_param->mvRefine > 2)
{
mvpSel[2] = interMode.amvpCand[list][ref][!mvpIdx];
mvpIdxSel[2] = !mvpIdx;
}
for (int cand = 0; cand < m_param->mvRefine; cand++)
{
if (cand && (mvpSel[cand] == mvpSel[cand - 1] || (cand == 2 && mvpSel[cand] == mvpSel[cand - 2])))
continue;
setSearchRange(cu, mvpSel[cand], m_param->searchRange, mvmin, mvmax);
// 开始运动估计
int bcost = m_me.motionEstimate(&m_slice->m_mref[list][ref], mvmin, mvmax, mvpSel[cand], numMvc, mvc, m_param->searchRange, bestmv, m_param->maxSlices,
m_param->bSourceReferenceEstimation ? m_slice->m_refFrameList[list][ref]->m_fencPic->getLumaAddr(0) : 0);
if (satdCost > bcost)
{
satdCost = bcost;
outmv = bestmv;
mvp = mvpSel[cand];
mvpIdx = mvpIdxSel[cand];
}
}
mvpIn = mvp;
}
else
{
// 开始运动估计
satdCost = m_me.motionEstimate(&slice->m_mref[list][ref], mvmin, mvmax, mvpIn, numMvc, mvc, m_param->searchRange, outmv, m_param->maxSlices,
m_param->bSourceReferenceEstimation ? m_slice->m_refFrameList[list][ref]->m_fencPic->getLumaAddr(0) : 0);
}
/* Get total cost of partition, but only include MV bit cost once */
bits += m_me.bitcost(outmv);
uint32_t mvCost = m_me.mvcost(outmv);
uint32_t cost = (satdCost - mvCost) + m_rdCost.getCost(bits);
/* Refine MVP selection, updates: mvpIdx, bits, cost */
if (!(m_param->analysisMultiPassRefine || useAsMVP))
mvp = checkBestMVP(amvp, outmv, mvpIdx, bits, cost);
else
{
/* It is more accurate to compare with actual mvp that was used in motionestimate than amvp[mvpIdx]. Here
the actual mvp is bestME from pass 1 for that mvpIdx */
int diffBits = m_me.bitcost(outmv, amvp[!mvpIdx]) - m_me.bitcost(outmv, mvpIn);
if (diffBits < 0)
{
mvpIdx = !mvpIdx;
uint32_t origOutBits = bits;
bits = origOutBits + diffBits;
cost = (cost - m_rdCost.getCost(origOutBits)) + m_rdCost.getCost(bits);
}
mvp = amvp[mvpIdx];
}
if (cost < bestME[list].cost)
{
bestME[list].mv = outmv;
bestME[list].mvp = mvp;
bestME[list].mvpIdx = mvpIdx;
bestME[list].cost = cost;
bestME[list].bits = bits;
bestME[list].mvCost = mvCost;
bestME[list].ref = ref;
}
bDoUnidir = false;
}
}
else if (m_param->bDistributeMotionEstimation)
{
PME pme(*this, interMode, cuGeom, pu, puIdx);
pme.m_jobTotal = 0;
pme.m_jobAcquired = 1; /* reserve L0-0 or L1-0 */
uint32_t refMask = refMasks[puIdx] ? refMasks[puIdx] : (uint32_t)-1;
for (int list = 0; list < numPredDir; list++)
{
int idx = 0;
for (int ref = 0; ref < numRefIdx[list]; ref++)
{
if (!(refMask & (1 << ref)))
continue;
pme.m_jobs.ref[list][idx++] = ref;
pme.m_jobTotal++;
}
pme.m_jobs.refCnt[list] = idx;
/* the second list ref bits start at bit 16 */
refMask >>= 16;
}
if (pme.m_jobTotal > 2)
{
pme.tryBondPeers(*m_frame->m_encData->m_jobProvider, pme.m_jobTotal - 1);
processPME(pme, *this);
int ref = pme.m_jobs.refCnt[0] ? pme.m_jobs.ref[0][0] : pme.m_jobs.ref[1][0];
singleMotionEstimation(*this, interMode, pu, puIdx, 0, ref); /* L0-0 or L1-0 */
bDoUnidir = false;
ProfileCUScopeNamed(pmeWaitScope, interMode.cu, pmeBlockTime, countPMEMasters);
pme.waitForExit();
}
/* if no peer threads were bonded, fall back to doing unidirectional
* searches ourselves without overhead of singleMotionEstimation() */
}
if (bDoUnidir)
{
interMode.bestME[puIdx][0].ref = interMode.bestME[puIdx][1].ref = -1;
uint32_t refMask = refMasks[puIdx] ? refMasks[puIdx] : (uint32_t)-1;
//遍历每个预测方向
for (int list = 0; list < numPredDir; list++)
{
//遍历当前预测方向参考列表中每一帧
for (int ref = 0; ref < numRefIdx[list]; ref++)
{
ProfileCounter(interMode.cu, totalMotionReferences[cuGeom.depth]);
if (!(refMask & (1 << ref)))
{
ProfileCounter(interMode.cu, skippedMotionReferences[cuGeom.depth]);
continue;
}
uint32_t bits = m_listSelBits[list] + MVP_IDX_BITS;
bits += getTUBits(ref, numRefIdx[list]);
//获取AMVP备选集
//基于sad选AMVP备选集中的最优MVP
int numMvc = cu.getPMV(interMode.interNeighbours, list, ref, interMode.amvpCand[list][ref], mvc);
const MV* amvp = interMode.amvpCand[list][ref];
int mvpIdx = selectMVP(cu, pu, amvp, list, ref);
MV mvmin, mvmax, outmv, mvp = amvp[mvpIdx], mvp_lowres;
bool bLowresMVP = false;
//若既不analysisSave,也不analysisLoad
if (!m_param->analysisSave && !m_param->analysisLoad) /* Prevents load/save outputs from diverging when lowresMV is not available */
{
//得到低分辨率的运动向量lmv
MV lmv = getLowresMV(cu, pu, list, ref);
//若低分辨率的mv可用,则存储下来
if (lmv.notZero())
mvc[numMvc++] = lmv;
//若允许层级运动估计,则拷贝lmv到mvp_lowres
if (m_param->bEnableHME)
mvp_lowres = lmv;
}
if (m_param->searchMethod == X265_SEA)
{
int puX = puIdx & 1;
int puY = puIdx >> 1;
for (int planes = 0; planes < INTEGRAL_PLANE_NUM; planes++)
m_me.integral[planes] = interMode.fencYuv->m_integral[list][ref][planes] + puX * pu.width + puY * pu.height * m_slice->m_refFrameList[list][ref]->m_reconPic->m_stride;
}
//基于amvp最优备选MV和searchRange设置搜索窗口[mvmin~mvmax]
setSearchRange(cu, mvp, m_param->searchRange, mvmin, mvmax);
//进行运动估计,得到最优MV到outmv,及其satd
int satdCost = m_me.motionEstimate(&slice->m_mref[list][ref], mvmin, mvmax, mvp, numMvc, mvc, m_param->searchRange, outmv, m_param->maxSlices,
m_param->bSourceReferenceEstimation ? m_slice->m_refFrameList[list][ref]->m_fencPic->getLumaAddr(0) : 0);
//使用3层级像素运动估计 && mvp低分辨率非零 && mvp低分辨率!=mvp
if (m_param->bEnableHME && mvp_lowres.notZero() && mvp_lowres != mvp)
{
MV outmv_lowres;
setSearchRange(cu, mvp_lowres, m_param->searchRange, mvmin, mvmax);
int lowresMvCost = m_me.motionEstimate(&slice->m_mref[list][ref], mvmin, mvmax, mvp_lowres, numMvc, mvc, m_param->searchRange, outmv_lowres, m_param->maxSlices,
m_param->bSourceReferenceEstimation ? m_slice->m_refFrameList[list][ref]->m_fencPic->getLumaAddr(0) : 0);
if (lowresMvCost < satdCost)
{
outmv = outmv_lowres;
satdCost = lowresMvCost;
bLowresMVP = true;
}
}
/* Get total cost of partition, but only include MV bit cost once */
//累加AMVP的最优MVP与运动估计最优MV之间差值mvd的bit开销
bits += m_me.bitcost(outmv);
uint32_t mvCost = m_me.mvcost(outmv);
uint32_t cost = (satdCost - mvCost) + m_rdCost.getCost(bits);
/* Update LowresMVP to best AMVP cand*/
if (bLowresMVP)
updateMVP(amvp[mvpIdx], outmv, bits, cost, mvp_lowres);
/* Refine MVP selection, updates: mvpIdx, bits, cost */
// 检查是否AMVP中另一个备选项相对当前的MVP,cost更优?若是则更新
mvp = checkBestMVP(amvp, outmv, mvpIdx, bits, cost);
//更新当前list方向的最优运动信息
if (cost < bestME[list].cost)
{
bestME[list].mv = outmv;//运动估计最优MV
bestME[list].mvp = mvp;//AMVP最优MV
bestME[list].mvpIdx = mvpIdx;//AMVP最优MV在备选集中的索引
bestME[list].ref = ref;//参考帧索引
bestME[list].cost = cost;//开销
bestME[list].bits = bits;//bist开销
bestME[list].mvCost = mvCost; //mvCost
}
}
/* the second list ref bits start at bit 16 */
refMask >>= 16;
}
}
/* Bi-directional prediction */
MotionData bidir[2];
uint32_t bidirCost = MAX_UINT;
int bidirBits = 0;
// BSlice 需要双向预测
//Bslice && 当前CU无双向预测限制 && pu非2Nx2N && 前后向都存在bestME
if (slice->isInterB() && !cu.isBipredRestriction() && /* biprediction is possible for this PU */
cu.m_partSize[pu.puAbsPartIdx] != SIZE_2Nx2N && /* 2Nx2N biprediction is handled elsewhere */
bestME[0].cost != MAX_UINT && bestME[1].cost != MAX_UINT)
{
bidir[0] = bestME[0];
bidir[1] = bestME[1];
int satdCost;
if (m_me.bChromaSATD)
{
cu.m_mv[0][pu.puAbsPartIdx] = bidir[0].mv;
cu.m_refIdx[0][pu.puAbsPartIdx] = (int8_t)bidir[0].ref;
cu.m_mv[1][pu.puAbsPartIdx] = bidir[1].mv;
cu.m_refIdx[1][pu.puAbsPartIdx] = (int8_t)bidir[1].ref;
motionCompensation(cu, pu, tmpPredYuv, true, true);
satdCost = m_me.bufSATD(tmpPredYuv.getLumaAddr(pu.puAbsPartIdx), tmpPredYuv.m_size) +
m_me.bufChromaSATD(tmpPredYuv, pu.puAbsPartIdx);
}
else
{
PicYuv* refPic0 = slice->m_refReconPicList[0][bestME[0].ref];
PicYuv* refPic1 = slice->m_refReconPicList[1][bestME[1].ref];
Yuv* bidirYuv = m_rqt[cuGeom.depth].bidirPredYuv;
/* Generate reference subpels */
predInterLumaPixel(pu, bidirYuv[0], *refPic0, bestME[0].mv);
predInterLumaPixel(pu, bidirYuv[1], *refPic1, bestME[1].mv);
primitives.pu[m_me.partEnum].pixelavg_pp[(tmpPredYuv.m_size % 64 == 0) && (bidirYuv[0].m_size % 64 == 0) && (bidirYuv[1].m_size % 64 == 0)](tmpPredYuv.m_buf[0], tmpPredYuv.m_size, bidirYuv[0].getLumaAddr(pu.puAbsPartIdx), bidirYuv[0].m_size,
bidirYuv[1].getLumaAddr(pu.puAbsPartIdx), bidirYuv[1].m_size, 32);
satdCost = m_me.bufSATD(tmpPredYuv.m_buf[0], tmpPredYuv.m_size);
}
bidirBits = bestME[0].bits + bestME[1].bits + m_listSelBits[2] - (m_listSelBits[0] + m_listSelBits[1]);
bidirCost = satdCost + m_rdCost.getCost(bidirBits);
bool bTryZero = bestME[0].mv.notZero() || bestME[1].mv.notZero();
if (bTryZero)
{
/* Do not try zero MV if unidir motion predictors are beyond
* valid search area */
MV mvmin, mvmax;
int merange = X265_MAX(m_param->sourceWidth, m_param->sourceHeight);
setSearchRange(cu, mvzero, merange, mvmin, mvmax);
mvmax.y += 2; // there is some pad for subpel refine
mvmin <<= 2;
mvmax <<= 2;
bTryZero &= bestME[0].mvp.checkRange(mvmin, mvmax);
bTryZero &= bestME[1].mvp.checkRange(mvmin, mvmax);
}
if (bTryZero)
{
/* coincident blocks of the two reference pictures */
if (m_me.bChromaSATD)
{
cu.m_mv[0][pu.puAbsPartIdx] = mvzero;
cu.m_refIdx[0][pu.puAbsPartIdx] = (int8_t)bidir[0].ref;
cu.m_mv[1][pu.puAbsPartIdx] = mvzero;
cu.m_refIdx[1][pu.puAbsPartIdx] = (int8_t)bidir[1].ref;
motionCompensation(cu, pu, tmpPredYuv, true, true);
satdCost = m_me.bufSATD(tmpPredYuv.getLumaAddr(pu.puAbsPartIdx), tmpPredYuv.m_size) +
m_me.bufChromaSATD(tmpPredYuv, pu.puAbsPartIdx);
}
else
{
const pixel* ref0 = m_slice->m_mref[0][bestME[0].ref].getLumaAddr(pu.ctuAddr, pu.cuAbsPartIdx + pu.puAbsPartIdx);
const pixel* ref1 = m_slice->m_mref[1][bestME[1].ref].getLumaAddr(pu.ctuAddr, pu.cuAbsPartIdx + pu.puAbsPartIdx);
intptr_t refStride = slice->m_mref[0][0].lumaStride;
primitives.pu[m_me.partEnum].pixelavg_pp[(tmpPredYuv.m_size % 64 == 0) && (refStride % 64 == 0)](tmpPredYuv.m_buf[0], tmpPredYuv.m_size, ref0, refStride, ref1, refStride, 32);
satdCost = m_me.bufSATD(tmpPredYuv.m_buf[0], tmpPredYuv.m_size);
}
MV mvp0 = bestME[0].mvp;
int mvpIdx0 = bestME[0].mvpIdx;
uint32_t bits0 = bestME[0].bits - m_me.bitcost(bestME[0].mv, mvp0) + m_me.bitcost(mvzero, mvp0);
MV mvp1 = bestME[1].mvp;
int mvpIdx1 = bestME[1].mvpIdx;
uint32_t bits1 = bestME[1].bits - m_me.bitcost(bestME[1].mv, mvp1) + m_me.bitcost(mvzero, mvp1);
uint32_t cost = satdCost + m_rdCost.getCost(bits0) + m_rdCost.getCost(bits1);
/* refine MVP selection for zero mv, updates: mvp, mvpidx, bits, cost */
mvp0 = checkBestMVP(interMode.amvpCand[0][bestME[0].ref], mvzero, mvpIdx0, bits0, cost);
mvp1 = checkBestMVP(interMode.amvpCand[1][bestME[1].ref], mvzero, mvpIdx1, bits1, cost);
if (cost < bidirCost)
{
bidir[0].mv = mvzero;
bidir[1].mv = mvzero;
bidir[0].mvp = mvp0;
bidir[1].mvp = mvp1;
bidir[0].mvpIdx = mvpIdx0;
bidir[1].mvpIdx = mvpIdx1;
bidirCost = cost;
bidirBits = bits0 + bits1 + m_listSelBits[2] - (m_listSelBits[0] + m_listSelBits[1]);
}
}
}
// 帧间预测包括前向预测,后向预测和双向预测。后向预测和双向预测一般不会在实时应用中使用
// 这里就是在当前PU的 前向/后向/双向/merge 四种模式中选择最优
// 如果 merge最优
if (mrgCost < bidirCost && mrgCost < bestME[0].cost && mrgCost < bestME[1].cost)
{
cu.m_mergeFlag[pu.puAbsPartIdx] = true;
cu.m_mvpIdx[0][pu.puAbsPartIdx] = merge.index; /* merge candidate ID is stored in L0 MVP idx */
cu.setPUInterDir(merge.dir, pu.puAbsPartIdx, puIdx);
cu.setPUMv(0, merge.mvField[0].mv, pu.puAbsPartIdx, puIdx);
cu.setPURefIdx(0, merge.mvField[0].refIdx, pu.puAbsPartIdx, puIdx);
cu.setPUMv(1, merge.mvField[1].mv, pu.puAbsPartIdx, puIdx);
cu.setPURefIdx(1, merge.mvField[1].refIdx, pu.puAbsPartIdx, puIdx);
totalmebits += merge.bits;
}
// 如果双向最优
else if (bidirCost < bestME[0].cost && bidirCost < bestME[1].cost)
{
lastMode = 2;
cu.m_mergelag[pu.puAbsPartIdx] = false;
cu.setPUInterDir(3, pu.puAbsPartIdx, puIdx);
cu.setPUMv(0, bidir[0].mv, pu.puAbsPartIdx, puIdx);
cu.setPURefIdx(0, bestME[0].ref, pu.puAbsPartIdx, puIdx);
cu.m_mvd[0][pu.puAbsPartIdx] = bidir[0].mv - bidir[0].mvp;
cu.m_mvpIdx[0][pu.puAbsPartIdx] = bidir[0].mvpIdx;
cu.setPUMv(1, bidir[1].mv, pu.puAbsPartIdx, puIdx);
cu.setPURefIdx(1, bestME[1].ref, pu.puAbsPartIdx, puIdx);
cu.m_mvd[1][pu.puAbsPartIdx] = bidir[1].mv - bidir[1].mvp;
cu.m_mvpIdx[1][pu.puAbsPartIdx] = bidir[1].mvpIdx;
totalmebits += bidirBits;
}
// 前向最优
else if (bestME[0].cost <= bestME[1].cost)
{
lastMode = 0;
cu.m_mergeFlag[pu.puAbsPartIdx] = false;
cu.setPUInterDir(1, pu.puAbsPartIdx, puIdx);
cu.setPUMv(0, bestME[0].mv, pu.puAbsPartIdx, puIdx);
cu.setPURefIdx(0, bestME[0].ref, pu.puAbsPartIdx, puIdx);
cu.m_mvd[0][pu.puAbsPartIdx] = bestME[0].mv - bestME[0].mvp;
cu.m_mvpIdx[0][pu.puAbsPartIdx] = bestME[0].mvpIdx;
cu.setPURefIdx(1, REF_NOT_VALID, pu.puAbsPartIdx, puIdx);
cu.setPUMv(1, mvzero, pu.puAbsPartIdx, puIdx);
totalmebits += bestME[0].bits;
}
// 后向最优
else
{
lastMode = 1;
cu.m_mergeFlag[pu.puAbsPartIdx] = false;
cu.setPUInterDir(2, pu.puAbsPartIdx, puIdx);
cu.setPUMv(1, bestME[1].mv, pu.puAbsPartIdx, puIdx);
cu.setPURefIdx(1, bestME[1].ref, pu.puAbsPartIdx, puIdx);
cu.m_mvd[1][pu.puAbsPartIdx] = bestME[1].mv - bestME[1].mvp;
cu.m_mvpIdx[1][pu.puAbsPartIdx] = bestME[1].mvpIdx;
cu.setPURefIdx(0, REF_NOT_VALID, pu.puAbsPartIdx, puIdx);
cu.setPUMv(0, mvzero, pu.puAbsPartIdx, puIdx);
totalmebits += bestME[1].bits;
}
// 根据最优的模式重建 YUV 然后进行运动补偿,也就是计算残差
motionCompensation(cu, pu, *predYuv, true, bChromaMC);
}
// 记录当前CU的运动估计 bits
interMode.sa8dBits += totalmebits;
}
【源码】MotionEstimate::motionEstimate()
会调用实际的运动估计函数。也就是按照菱形等搜索方式从起始点开始搜索PU块。运动估计最终得到运动矢量MV。首
先进行一轮整数搜索、然后在进行1/2像素搜索(需要亚像素插值)、然后进行1/4像素搜索(需要亚像素插值)。搜索得到最优MV。
调用流程:
Anaylsis::compressInterCU_rd0_4() -> 帧间编码入口函数
Anaylsis::checkInter_rd0_4() -> 计算AMVP、调用运动搜索、调用运动估计,调用后续的 predInterSearch()函数。函数最终得到当前CU每个PU在指定 interMode 帧间预测的 rd-cost。
Search::predInterSearch -> 帧间运动估计、运动补偿
MotionEstimate::motionEstimate() -> 运动搜索,运动估计之后,得到运动矢量MV,返回到 MV &outQMv 对象中。
搜索算法:
(1)菱形搜索DAI:AMVP确定起始点,搜索半径为1,菱形找到rd-cost最小点,迭代merange次,多次迭代找到MV。
(2)六边形搜索HEX:AMVP确定起始点,六边形搜索,迭代次数 merange/2,搜索步长为2。
(3)星形搜索STAR:TZSerach搜索方法。
(4)SEA:Successive Elimination Algorithm。
(5)UMH:AMVP确定起始pmv,步长为1菱形搜索,若 pmv不为(0,0)则以(0,0)为起始搜索点进行一次搜索步长为1的菱形搜索。
/** 函数功能 : 运动估计,获取最优的MV
/* 调用范围 :只在Search::predInterSearch、singleMotionEstimation和CostEstimateGroup::estimateCUCost函数中被调用
* \参数 mvmin :最小MV(整像素精度)
* \参数 mvmax :最大MV(整像素精度)
* \参数 qmvp :MVP(分像素精度(1/4))
* \参数 numCandidates :当前的候选参考帧个数 ?????
* \参数 mvc :当前的MVC(MV candidates)列表
* \参数 merange :当前的搜索窗口
* \参数 outQMv :
返回最优的MV
* \返回 :
返回最优MV所花费的cost **/
case X265_HEX_SEARCH: // x265默认搜索方式,先六边形搜索,再正方形搜索细化
COST_MV(mx, my) // 实际计算两个MV的 sad
COST_MV_X3_DIR(2, 0, 1, -2, -1, -2, costs); //搜索六边形的三点,并将cost存入costs中
COST_MV_X4_DIR(m0x, m0y, m1x, m1y, m2x, m2y, m3x, m3y, costs); //搜索菱形或者正方形的四个顶点,并将cost存入costs中
int cost = sad(fenc, FENC_STRIDE, fref + (mx) + (my) * stride, stride); // 计算两个MV的 sad-cost
bcost = subpelCompare(ref, bmv, satd) + mvcost(bmv); // 如果分像素搜索中使用satd,则进行标准的分像素插值并使用satd计算cost
bcost = subpelCompare(ref, bmv, satd) + mvcost(bmv); // 如果分像素搜索使用的是sad,则使用satd再做一次搜索
return bcost; //返回cost值: 如果当前搜索的参考帧是1/2分辨率采样参考帧:satd + mvcost 如果当前为普通参考帧:则返回标准分像素搜索得到的cost
sad就是求像素块的相似度,每个像素差值绝对值求和:
当前需要做运动搜索的块 当前搜索路径点所在块
44 34 32 33 32 31 34 31 51 45 39 36 32 31 33 31 7 11 7 3 0 0 1 0
37 36 37 35 30 35 29 30 47 44 39 33 35 34 31 33 10 8 2 2 5 1 2 3
36 37 37 35 34 30 31 35 47 45 37 35 38 37 33 31 11 8 0 0 4 7 2 4
44 37 36 37 30 32 34 36 - 48 42 38 36 34 35 34 31 = 4 5 2 1 4 3 0 5 = 249(sad)
42 39 39 32 38 39 39 40 47 42 42 36 37 36 33 37 5 3 3 4 1 3 6 3
41 38 33 36 35 34 38 38 45 42 41 38 34 32 34 33 4 4 8 2 1 2 4 5
43 31 36 38 37 40 35 38 43 46 41 34 31 36 34 38 0 15 5 4 6 4 1 0
33 34 40 35 36 33 35 36 44 46 38 30 36 34 34 34 11 13 2 5 0 1 1 2
运动估计之后,得到运动矢量MV,返回到 MV &outQMv 对象中。
【源码】MotionEstimate::subpelCompare
/** 函数功能 : 对一个分像素MV位置进行插值,并估计所花费的cost
/* 调用范围 :只在MotionEstimate::motionEstimate函数中被调用
* \参数 ref :参考帧
* \参数 qmv :1/4像素精度的MV
* \参数 cmp :计算distortion所使用的函数
* \返回 :所花费的cost **/
int MotionEstimate::subpelCompare(ReferencePlanes *ref, const MV& qmv, pixelcmp_t cmp)
{
intptr_t refStride = ref->lumaStride;
pixel *fref = ref->fpelPlane[0] + blockOffset + (qmv.x >> 2) + (qmv.y >> 2) * refStride;
int xFrac = qmv.x & 0x3; // 得到MV中的x分量中的分像素MV
int yFrac = qmv.y & 0x3; // 得到MV中的y分量中的分像素MV
int cost;
intptr_t lclStride = fencPUYuv.m_size;
X265_CHECK(lclStride == FENC_STRIDE, "fenc buffer is assumed to have FENC_STRIDE by sad_x3 and sad_x4\n");
if (!(yFrac | xFrac)) // 如果输入的MV为整像素MV,则直接跳过插值,使用整像素参考帧计算cost
cost = cmp(fencPUYuv.m_buf[0], lclStride, fref, refStride);
else // 否则需要首先插值,再计算cost
{
/* we are taking a short-cut here if the reference is weighted. To be
* accurate we should be interpolating unweighted pixels and weighting
* the final 16bit values prior to rounding and down shifting. Instead we
* are simply interpolating the weighted full-pel pixels. Not 100%
* accurate but good enough for fast qpel ME */
ALIGN_VAR_32(pixel, subpelbuf[64 * 64]);
if (!yFrac) // 如果是整数行,则只需进行横向插值
primitives.pu[partEnum].luma_hpp(fref, refStride, subpelbuf, lclStride, xFrac);
else if (!xFrac) // 如果是整数列,则只需进行纵向插值
primitives.pu[partEnum].luma_vpp(fref, refStride, subpelbuf, lclStride, yFrac);
else // 如果既不是整数行也不是整数列,那么就需要先进行横向插值,再进行纵向插值
primitives.pu[partEnum].luma_hvpp(fref, refStride, subpelbuf, lclStride, xFrac, yFrac);
cost = cmp(fencPUYuv.m_buf[0], lclStride, subpelbuf, lclStride); // 得到分像素位置的cost,
}
if (bChromaSATD) // 如果对chroma也计算satd
{
int csp = fencPUYuv.m_csp; // 读取YUV的数据格式
int hshift = fencPUYuv.m_hChromaShift; // 色度宽度需要移位个数
int vshift = fencPUYuv.m_vChromaShift; // 色度高度需要移位个数
int shiftHor = (2 + hshift); // 对于YUV420,hshift=vshift=1,shiftHor=shiftVer=2+1 = 3。MV右移shiftHor/shiftVer位,其中右移的两位相当于找到亮度分量的整数MV位置,而再右移的hshift/vshift,则找到色度分量的整数MV位置
int shiftVer = (2 + vshift);
lclStride = fencPUYuv.m_csize;
intptr_t refStrideC = ref->reconPic->m_strideC; // 得到参考帧色度的步长
intptr_t refOffset = (qmv.x >> shiftHor) + (qmv.y >> shiftVer) * refStrideC; // 得到色度分量在YUV数据中的地址偏移
const pixel* refCb = ref->getCbAddr(ctuAddr, absPartIdx) + refOffset; // 得到cb分量的地址
const pixel* refCr = ref->getCrAddr(ctuAddr, absPartIdx) + refOffset; // 得到cr分量的地址
xFrac = qmv.x & ((1 << shiftHor) - 1); // 得到MV中的x分量中的分像素MV,对于YUV420,由于色度块的长和宽均为亮度的1/2,所以色度MV是1/8像素精度。
yFrac = qmv.y & ((1 << shiftVer) - 1); // 得到MV中的y分量中的分像素MV
if (!(yFrac | xFrac)) // 如果输入的MV为整像素MV,则直接跳过插值,使用整像素参考帧计算cost(色度分量的cost包括cb/cr两部分)
{
cost += chromaSatd(fencPUYuv.m_buf[1], lclStride, refCb, refStrideC);
cost += chromaSatd(fencPUYuv.m_buf[2], lclStride, refCr, refStrideC);
}
else // 否则需要首先插值,再计算cost
{
ALIGN_VAR_32(pixel, subpelbuf[64 * 64]); // 申请子像素存储的buffer
if (!yFrac) // 如果是整数行,则只需进行横向插值
{
primitives.chroma[csp].pu[partEnum].filter_hpp(refCb, refStrideC, subpelbuf, lclStride, xFrac << (1 - hshift)); // cb色度分量横向插值
cost += chromaSatd(fencPUYuv.m_buf[1], lclStride, subpelbuf, lclStride); // 计算cb分量的cost
primitives.chroma[csp].pu[partEnum].filter_hpp(refCr, refStrideC, subpelbuf, lclStride, xFrac << (1 - hshift)); // cr色度分量横向插值
cost += chromaSatd(fencPUYuv.m_buf[2], lclStride, subpelbuf, lclStride); // 计算cr分量的cost
}
else if (!xFrac) // 如果是整数列,则只需进行纵向插值
{
primitives.chroma[csp].pu[partEnum].filter_vpp(refCb, refStrideC, subpelbuf, lclStride, yFrac << (1 - vshift)); // cb色度分量纵向插值
cost += chromaSatd(fencPUYuv.m_buf[1], lclStride, subpelbuf, lclStride); // 计算cb分量的cost
primitives.chroma[csp].pu[partEnum].filter_vpp(refCr, refStrideC, subpelbuf, lclStride, yFrac << (1 - vshift)); // cr色度分量纵向插值
cost += chromaSatd(fencPUYuv.m_buf[2], lclStride, subpelbuf, lclStride); // 计算cr分量的cost
}
else // 如果既不是整数行也不是整数列,那么就需要先进行横向插值,再进行纵向插值
{
ALIGN_VAR_32(int16_t, immed[64 * (64 + NTAPS_CHROMA)]);
int extStride = blockwidth >> hshift;
int filterSize = NTAPS_CHROMA;
int halfFilterSize = (filterSize >> 1);
primitives.chroma[csp].pu[partEnum].filter_hps(refCb, refStrideC, immed, extStride, xFrac << (1 - hshift), 1); // cb色度分量横向插值
primitives.chroma[csp].pu[partEnum].filter_vsp(immed + (halfFilterSize - 1) * extStride, extStride, subpelbuf, lclStride, yFrac << (1 - vshift)); // cb色度分量纵向插值
cost += chromaSatd(fencPUYuv.m_buf[1], lclStride, subpelbuf, lclStride); // 计算cb分量的cost
primitives.chroma[csp].pu[partEnum].filter_hps(refCr, refStrideC, immed, extStride, xFrac << (1 - hshift), 1); // cr色度分量横向插值
primitives.chroma[csp].pu[partEnum].filter_vsp(immed + (halfFilterSize - 1) * extStride, extStride, subpelbuf, lclStride, yFrac << (1 - vshift)); // cr色度分量纵向插值
cost += chromaSatd(fencPUYuv.m_buf[2], lclStride, subpelbuf, lclStride); // 计算cr分量的cost
}
}
}
return cost;
}
【源码】Predict::motionCompensation
运动估计得到的是运动矢量,之后需要对估计信息进行运动补偿。
调用流程:
Anaylsis::compressInterCU_rd0_4() -> 帧间编码入口函数。
Anaylsis::checkInter_rd0_4() -> 计算AMVP、调用运动搜索、调用运动估计,调用后续的 predInterSearch()函数。函数最终得到当前CU每个PU在指定 interMode 帧间预测的 rd-cost。
Search::predInterSearch -> 帧间运动估计、运动补偿。
MotionEstimate::motionEstimate() 和 Predict::motionCompensation -> 运动搜索/运动补偿。
调用的核心函数是亮度和色的帧间补偿,主要是亚像素插值,然后和原始YUV(参考YUV都是整像素)计算残差:
Search::predInterLumaPixel(const PredictionUnit& pu, Yuv& dstYuv, const PicYuv& refPic, const MV& mv) 亮度运动补偿,整像素补偿
Search::predInterChromaPixel(const PredictionUnit& pu, Yuv& dstYuv, const PicYuv& refPic, const MV& mv) 色度运动补偿,整像素补偿
Search::predInterLumaShort(const PredictionUnit& pu, ShortYuv& dstSYuv, const PicYuv& refPic, const MV& mv) 亮度运动补偿,亚像素补偿,内部需要插值。
Search::predInterChromaShort(const PredictionUnit& pu, ShortYuv& dstSYuv, const PicYuv& refPic, const MV& mv) 色度运动补偿,亚像素补偿,内部需要插值。
void Predict::addWeightBi()
双向加权,运动补偿之前需要进行加权
void Predict::addWeightUni() 单向加权,运动补偿之前需要进行加权
为了对光影变化时运动前后色度有整体变化造成残差不理想,于是进行加权将两块提升到相同水平再求残差
根据h265原理,会评估两帧的整体水平得到一个粗略的权重,HEVC:
P =(PLX+2LWD-1)>>LWD 默认(default)加权预测(单向)
P =(PL0+PL1+2LWD)>>(LWD+1) 默认(default)加权预测(双向)
P =Clip1((PLX*WLX+2LWD-1)>>LWD+OLX) 显示(explict)加权预测(单向预测)
P =Clip1(((PL0*WL0+PL1*WL1+2LWD)>>(LWD+1))+(OL0+OL1+1)>>1) 显示(explict)加权预测(双向预测)
P是目标图像的预测值,PLX则是参考列表X(0或1)中相应参考帧的重建像素值。>>操作对应于亚像素精度运动补偿过程中对预测值的放大,LWD为具体系数,W为权重,O为偏移量,其中W与O在码流中获得。
void Predict::motionCompensation(const CUData& cu, const PredictionUnit& pu, Yuv& predYuv, bool bLuma, bool bChroma)
{
// 先获取当前PU的参考帧的索引值 refIdx0、refIdx1
int refIdx0 = cu.m_refIdx[0][pu.puAbsPartIdx];
int refIdx1 = cu.m_refIdx[1][pu.puAbsPartIdx];
// PSlice
if (cu.m_slice->isInterP())
{
/* P Slice */
// 定义一个加权预测数组,长度3对应YUV三个分量
// 加权预测是为了对光影变化时运动前后色度有整体变化造成残差不理想,于是进行加权将两块提升到相同水平再求残差
// 根据h265原理,会评估两帧的整体水平得到一个粗略的权重
// HEVC:
// P =(PLX+2LWD-1)>>LWD 默认(default)加权预测(单向)
// P =(PL0+PL1+2LWD)>>(LWD+1) 默认(default)加权预测(双向)
// P =Clip1((PLX*WLX+2LWD-1)>>LWD+OLX) 显示(explict)加权预测(单向预测)
// P =Clip1(((PL0*WL0+PL1*WL1+2LWD)>>(LWD+1))+(OL0+OL1+1)>>1) 显示(explict)加权预测(双向预测)
// P是目标图像的预测值,PLX则是参考列表X(0或1)中相应参考帧的重建像素值。>>操作对应于亚像素精度运动补偿过程中对预测值的放大,LWD为具体系数,W为权重,O为偏移量,其中W与O在码流中获得。
WeightValues wv0[3];
X265_CHECK(refIdx0 >= 0, "invalid P refidx\n");
X265_CHECK(refIdx0 < cu.m_slice->m_numRefIdx[0], "P refidx out of range\n");
// 获取当前CU的加权参数,保存到临时变量中 wp0
const WeightParam *wp0 = cu.m_slice->m_weightPredTable[0][refIdx0];
MV mv0 = cu.m_mv[0][pu.puAbsPartIdx];
cu.clipMv(mv0);
// 加权预测,并且亚像素插值
if (cu.m_slice->m_pps->bUseWeightPred && wp0->wtPresent)
{
for (int plane = 0; plane < (bChroma ? 3 : 1); plane++)
{
wv0[plane].w = wp0[plane].inputWeight;
wv0[plane].offset = wp0[plane].inputOffset * (1 << (X265_DEPTH - 8));
wv0[plane].shift = wp0[plane].log2WeightDenom;
wv0[plane].round = wp0[plane].log2WeightDenom >= 1 ? 1 << (wp0[plane].log2WeightDenom - 1) : 0;
}
ShortYuv& shortYuv = m_predShortYuv[0];
if (bLuma)
predInterLumaShort(pu, shortYuv, *cu.m_slice->m_refReconPicList[0][refIdx0], mv0);
if (bChroma)
predInterChromaShort(pu, shortYuv, *cu.m_slice->m_refReconPicList[0][refIdx0], mv0);
addWeightUni(pu, predYuv, shortYuv, wv0, bLuma, bChroma);
}
else
{ // 亮度、色度运动补偿处理,不需要亚像素插值
if (bLuma)
predInterLumaPixel(pu, predYuv, *cu.m_slice->m_refReconPicList[0][refIdx0], mv0);
if (bChroma)
predInterChromaPixel(pu, predYuv, *cu.m_slice->m_refReconPicList[0][refIdx0], mv0);
}
}
// BSlice(和PSlice的区别就是双向预测需要双向补偿)
else
{
....
}
}【源码】Predict::predInterLumaPixel() 和 Predict::predInterChromaPixel()
亮度运动补偿,整像素补偿。
色度运动补偿,整像素补偿。
调用流程:
Anaylsis::compressInterCU_rd0_4() -> 帧间编码入口函数。
Anaylsis::checkInter_rd0_4() -> 计算AMVP、调用运动搜索、调用运动估计,调用后续的 predInterSearch()函数。函数最终得到当前CU每个PU在指定 interMode 帧间预测的 rd-cost。
Search::predInterSearch -> 帧间运动估计、运动补偿。
MotionEstimate::motionEstimate() 和 Predict::motionCompensation -> 运动搜索/运动补偿。
Search::
predInterLumaPixel()
和
Search::predInterChromaPixel()
-> 亮度和色度运动补偿
/* 亮度整像素插值 */
void Predict::predInterLumaPixel(const PredictionUnit& pu, Yuv& dstYuv, const PicYuv& refPic, const MV& mv) const
{
// 亮度地址
pixel* dst = dstYuv.getLumaAddr(pu.puAbsPartIdx);
intptr_t dstStride = dstYuv.m_size;
intptr_t srcStride = refPic.m_stride;
intptr_t srcOffset = (mv.x >> 2) + (mv.y >> 2) * srcStride;
int partEnum = partitionFromSizes(pu.width, pu.height);
// 根据亮度地址再当前 CU在CTU中z-order偏移、PU在CU中z-order偏移
const pixel* src = refPic.getLumaAddr(pu.ctuAddr, pu.cuAbsPartIdx + pu.puAbsPartIdx) + srcOffset;
// 判断是否有分像素
int xFrac = mv.x & 3;
int yFrac = mv.y & 3;
// 如果都是整像素MV 分别对水平和锤子方向进行补偿,下列 copy_pp、luma_hpp、luma_vpp、luma_hvpp 均是指令集优化函数
if (!(yFrac | xFrac))
primitives.pu[partEnum].copy_pp(dst, dstStride, src, srcStride);
else if (!yFrac)
primitives.pu[partEnum].luma_hpp(src, srcStride, dst, dstStride, xFrac);
else if (!xFrac)
primitives.pu[partEnum].luma_vpp(src, srcStride, dst, dstStride, yFrac);
else
primitives.pu[partEnum].luma_hvpp(src, srcStride, dst, dstStride, xFrac, yFrac);
}【源码】Search::encodeResAndCalcRdInterCU 和 Search::encodeResAndCalcRdSkipCU
调用流程:
Analysis::compressInterCU_rd0_4 -> 在 rd 级别 0到4结果 Merge/Skip、AMVP 运动估计补偿等等操作之后,会判断当前模式是否最优
Search::encodeResAndCalcRdInterCU -> 判断当前 Skip 模式是否最优,计算 rd-cost 量化、编码等
Search::encodeResAndCalcRdSkipCU -> 判断当前 Inter 模式是否最优(注意当前Inter模式也是一系列Inter模式选出来的最优Inter),计算 rd-cost 量化、编码等。
Search::encodeResAndCalcRdSkipCU(),计算interMode为skip mode时的rdcost
过程:
1.计算luma+chroma的distiortion
2.计算skipFlag+mergeIdx的bits开销,skip模式无残差bits开销。
3.更新energe和rdcost
4.保存熵编码上下文
Search::encodeResAndCalcRdInterCU,
为CU编码残差并计算rdcost。该函数可能重写rdcost,但不会改变sa8d cost,
过程:
1.取interMode的CUData、reconYUV、fencYUV、predYUV、resiYUV以及当前CU深度depth
2.根据fencYUV和predYUV计算resiYUV,即resiYUV = fencYUV - predYUV
3.加载熵编码上下文
4.对残差resiYUV进行编码并得到cost
5.若不允许transform-quantization旁路,则计算cbf = 0时候的rdcost
1.计算cbf = 0时候的distortion
2.计算cbf = 0时候的bits
3.根据distortion和bits得到cbf = 0时候的rdcost
4.若cbf = 0时的rdcost<有残差时候的rdcost,则设置cbf = 0
6.若cbf != 0,也就是有残差,则保存残差数据
7.编码TransquantBypassFlag
8.计算bits
若是skip,则bits = SkipFlag + MergeIndex
若非skip,则bits = SkipFlag + PredMode + PartSize + PredInfo + Coeff
9.恢复reconYUV,即reconYUV = predYUV + resiYUV
10.更新interMode的distortion
11.更新interMode的energy、bits、rdcost
void Search::encodeResAndCalcRdSkipCU(Mode& interMode)
{
//取interMode的CUData
CUData& cu = interMode.cu;
//取interMode的reconYUV、fencYUV、predYUV
Yuv* reconYuv = &interMode.reconYuv;
const Yuv* fencYuv = interMode.fencYuv;
Yuv* predYuv = &interMode.predYuv;
X265_CHECK(!cu.isIntra(0), "intra CU not expected\n");
//得到当前CU的深度
uint32_t depth = cu.m_cuDepth[0];
// No residual coding : SKIP mode
//设置CU为skip
cu.setPredModeSubParts(MODE_SKIP);
//清空cbf
cu.clearCbf();
//设置TU深度
cu.setTUDepthSubParts(0, 0, depth);
//将interMode的预测YUV拷贝给recon
reconYuv->copyFromYuv(interMode.predYuv);
// 计算Luma的distortion
int part = partitionFromLog2Size(cu.m_log2CUSize[0]);
interMode.lumaDistortion = primitives.cu[part].sse_pp(fencYuv->m_buf[0], fencYuv->m_size, reconYuv->m_buf[0], reconYuv->m_size);
interMode.distortion = interMode.lumaDistortion;
// 若有色度,则累加上Chroma的distortion
if (m_csp != X265_CSP_I400 && m_frame->m_fencPic->m_picCsp != X265_CSP_I400)
{
interMode.chromaDistortion = m_rdCost.scaleChromaDist(1, primitives.chroma[m_csp].cu[part].sse_pp(fencYuv->m_buf[1], fencYuv->m_csize, reconYuv->m_buf[1], reconYuv->m_csize));
interMode.chromaDistortion += m_rdCost.scaleChromaDist(2, primitives.chroma[m_csp].cu[part].sse_pp(fencYuv->m_buf[2], fencYuv->m_csize, reconYuv->m_buf[2], reconYuv->m_csize));
interMode.distortion += interMode.chromaDistortion;
}
cu.m_distortion[0] = interMode.distortion;
//加载熵编码上下文
m_entropyCoder.load(m_rqt[depth].cur);
//重置bits
m_entropyCoder.resetBits();
if (m_slice->m_pps->bTransquantBypassEnabled)
m_entropyCoder.codeCUTransquantBypassFlag(cu.m_tqBypass[0]);
//编码skipFlag
m_entropyCoder.codeSkipFlag(cu, 0);
//得到skipFlag的bits开销
int skipFlagBits = m_entropyCoder.getNumberOfWrittenBits();
//编码merge备选集索引
m_entropyCoder.codeMergeIndex(cu, 0);
//得到merge备选集索引开销
interMode.mvBits = m_entropyCoder.getNumberOfWrittenBits() - skipFlagBits;
//skip无系数开销
interMode.coeffBits = 0;
//总开销 = mv开销 + merge备选集索引开销
interMode.totalBits = interMode.mvBits + skipFlagBits;
//更新psy/ssim能量
if (m_rdCost.m_psyRd)
interMode.psyEnergy = m_rdCost.psyCost(part, fencYuv->m_buf[0], fencYuv->m_size, reconYuv->m_buf[0], reconYuv->m_size);
else if(m_rdCost.m_ssimRd)
interMode.ssimEnergy = m_quant.ssimDistortion(cu, fencYuv->m_buf[0], fencYuv->m_size, reconYuv->m_buf[0], reconYuv->m_size, cu.m_log2CUSize[0], TEXT_LUMA, 0);
//更新残差能量
interMode.resEnergy = primitives.cu[part].sse_pp(fencYuv->m_buf[0], fencYuv->m_size, predYuv->m_buf[0], predYuv->m_size);
//更新rdcost
updateModeCost(interMode);
//保持上下文
m_entropyCoder.store(interMode.contexts);
}void Search::encodeResAndCalcRdInterCU(Mode& interMode, const CUGeom& cuGeom)
{
ProfileCUScope(interMode.cu, interRDOElapsedTime[cuGeom.depth], countInterRDO[cuGeom.depth]);
//取interMode的cu
CUData& cu = interMode.cu;
//取interMode的recon、pred、enc YUV
Yuv* reconYuv = &interMode.reconYuv;
Yuv* predYuv = &interMode.predYuv;
const Yuv* fencYuv = interMode.fencYuv;
//取当前CU的depth
uint32_t depth = cuGeom.depth;
//取残差YUV
ShortYuv* resiYuv = &m_rqt[depth].tmpResiYuv;
X265_CHECK(!cu.isIntra(0), "intra CU not expected\n");
uint32_t log2CUSize = cuGeom.log2CUSize;
int sizeIdx = log2CUSize - 2;
//计算残差YUV,即resiYuv = fencYuv - predYuv
resiYuv->subtract(*fencYuv, *predYuv, log2CUSize, m_frame->m_fencPic->m_picCsp);
uint32_t tuDepthRange[2];
cu.getInterTUQtDepthRange(tuDepthRange, 0);
//加载熵编码上下文
m_entropyCoder.load(m_rqt[depth].cur);
if ((m_limitTU & X265_TU_LIMIT_DFS) && !(m_limitTU & X265_TU_LIMIT_NEIGH))
m_maxTUDepth = -1;
else if (m_limitTU & X265_TU_LIMIT_BFS)
memset(&m_cacheTU, 0, sizeof(TUInfoCache));
/*
计算残差值并得到cost
*/
Cost costs;
if (m_limitTU & X265_TU_LIMIT_NEIGH)
{
/* Save and reload maxTUDepth to avoid changing of maxTUDepth between modes */
int32_t tempDepth = m_maxTUDepth;
if (m_maxTUDepth != -1)
{
uint32_t splitFlag = interMode.cu.m_partSize[0] != SIZE_2Nx2N;
uint32_t minSize = tuDepthRange[0];
uint32_t maxSize = tuDepthRange[1];
maxSize = X265_MIN(maxSize, cuGeom.log2CUSize - splitFlag);
m_maxTUDepth = x265_clip3(cuGeom.log2CUSize - maxSize, cuGeom.log2CUSize - minSize, (uint32_t)m_maxTUDepth);
}
estimateResidualQT(interMode, cuGeom, 0, 0, *resiYuv, costs, tuDepthRange);
m_maxTUDepth = tempDepth;
}
else
estimateResidualQT(interMode, cuGeom, 0, 0, *resiYuv, costs, tuDepthRange);
//是否旁路transform和quantization,即无损编码
uint32_t tqBypass = cu.m_tqBypass[0];
//若不旁路,则有损
if (!tqBypass)
{
/*
计算cbf = 0时候的distortion
*/
sse_t cbf0Dist = primitives.cu[sizeIdx].sse_pp(fencYuv->m_buf[0], fencYuv->m_size, predYuv->m_buf[0], predYuv->m_size);
//若有色度,则累加chroma的失真
if (m_csp != X265_CSP_I400 && m_frame->m_fencPic->m_picCsp != X265_CSP_I400)
{
cbf0Dist += m_rdCost.scaleChromaDist(1, primitives.chroma[m_csp].cu[sizeIdx].sse_pp(fencYuv->m_buf[1], predYuv->m_csize, predYuv->m_buf[1], predYuv->m_csize));
cbf0Dist += m_rdCost.scaleChromaDist(2, primitives.chroma[m_csp].cu[sizeIdx].sse_pp(fencYuv->m_buf[2], predYuv->m_csize, predYuv->m_buf[2], predYuv->m_csize));
}
/* Consider the RD cost of not signaling any residual
计算cbf = 0时候的bits开销 */
//加载熵编码上下文
m_entropyCoder.load(m_rqt[depth].cur);
//重置bits
m_entropyCoder.resetBits();
//cbf为0时,进行编码
m_entropyCoder.codeQtRootCbfZero();
//得到cbf为0时的bits开销
uint32_t cbf0Bits = m_entropyCoder.getNumberOfWrittenBits();
/*
根据distortion和bits计算energy和rdcost
*/
uint32_t cbf0Energy; uint64_t cbf0Cost;
if (m_rdCost.m_psyRd)
{
cbf0Energy = m_rdCost.psyCost(log2CUSize - 2, fencYuv->m_buf[0], fencYuv->m_size, predYuv->m_buf[0], predYuv->m_size);
cbf0Cost = m_rdCost.calcPsyRdCost(cbf0Dist, cbf0Bits, cbf0Energy);
}
else if(m_rdCost.m_ssimRd)
{
cbf0Energy = m_quant.ssimDistortion(cu, fencYuv->m_buf[0], fencYuv->m_size, predYuv->m_buf[0], predYuv->m_size, log2CUSize, TEXT_LUMA, 0);
cbf0Cost = m_rdCost.calcSsimRdCost(cbf0Dist, cbf0Bits, cbf0Energy);
}
else
cbf0Cost = m_rdCost.calcRdCost(cbf0Dist, cbf0Bits);
//若cbf = 0时候的rdcost < 有残差的rdcost,则cbf置0
if (cbf0Cost < costs.rdcost)
{
cu.clearCbf();
cu.setTUDepthSubParts(0, 0, depth);
}
}
//若cbf!=0,则保存残差数据
if (cu.getQtRootCbf(0))
saveResidualQTData(cu, *resiYuv, 0, 0);
/* calculate signal bits for inter/merge/skip coded CU */
//加载熵编码上下文
m_entropyCoder.load(m_rqt[depth].cur);
//重置bits
m_entropyCoder.resetBits();
if (m_slice->m_pps->bTransquantBypassEnabled)
m_entropyCoder.codeCUTransquantBypassFlag(tqBypass);
/*
计算bits
*/
uint32_t coeffBits, bits, mvBits;
//若是merge,且2Nx2N,且CBF = 0,则是skip模式
if (cu.m_mergeFlag[0] && cu.m_partSize[0] == SIZE_2Nx2N && !cu.getQtRootCbf(0))
{
//设置为skip模式
cu.setPredModeSubParts(MODE_SKIP);
/* Merge/Skip */
coeffBits = mvBits = 0;
//编码skipFlag
m_entropyCoder.codeSkipFlag(cu, 0);
//得到skipFlag的bits开销
int skipFlagBits = m_entropyCoder.getNumberOfWrittenBits();
//编码mergeIdx
m_entropyCoder.codeMergeIndex(cu, 0);
//得到mergeIdx的bits开销
mvBits = m_entropyCoder.getNumberOfWrittenBits() - skipFlagBits;
//总计skip模式下的bits总开销
bits = mvBits + skipFlagBits;
}
//若非skip模式下
else
{
//编码skipFlag
m_entropyCoder.codeSkipFlag(cu, 0);
//得到skipFlag的bits开销
int skipFlagBits = m_entropyCoder.getNumberOfWrittenBits();
//编码PredMode
m_entropyCoder.codePredMode(cu.m_predMode[0]);
//编码partSize
m_entropyCoder.codePartSize(cu, 0, cuGeom.depth);
//编码PredInfo
m_entropyCoder.codePredInfo(cu, 0);
//得到PredMode/partSize/PredInfo的bits总开销
mvBits = m_entropyCoder.getNumberOfWrittenBits() - skipFlagBits;
//是否DQP
bool bCodeDQP = m_slice->m_pps->bUseDQP;
//编码coeff
m_entropyCoder.codeCoeff(cu, 0, bCodeDQP, tuDepthRange);
//得到coeff的bits开销
bits = m_entropyCoder.getNumberOfWrittenBits();
coeffBits = bits - mvBits - skipFlagBits;
}
//保存熵编码上下文
m_entropyCoder.store(interMode.contexts);
/*
得到reconYUV,用于后续计算distortion
*/
if (cu.getQtRootCbf(0)) //若有cbf,则reconYUV = predYUV+resiYUV
reconYuv->addClip(*predYuv, *resiYuv, log2CUSize, m_frame->m_fencPic->m_picCsp);
else //若无cbf,则reconYUV = predYUV
reconYuv->copyFromYuv(*predYuv);
/*
update with clipped distortion and cost (qp estimation loop uses unclipped values)
记录luma和chroma的distortion
*/
//记录interMode的Luma最优distortion
sse_t bestLumaDist = primitives.cu[sizeIdx].sse_pp(fencYuv->m_buf[0], fencYuv->m_size, reconYuv->m_buf[0], reconYuv->m_size);
interMode.distortion = bestLumaDist;
//若有色度,则记录interMode的chroma最优distortion
if (m_csp != X265_CSP_I400 && m_frame->m_fencPic->m_picCsp != X265_CSP_I400)
{
sse_t bestChromaDist = m_rdCost.scaleChromaDist(1, primitives.chroma[m_csp].cu[sizeIdx].sse_pp(fencYuv->m_buf[1], fencYuv->m_csize, reconYuv->m_buf[1], reconYuv->m_csize));
bestChromaDist += m_rdCost.scaleChromaDist(2, primitives.chroma[m_csp].cu[sizeIdx].sse_pp(fencYuv->m_buf[2], fencYuv->m_csize, reconYuv->m_buf[2], reconYuv->m_csize));
interMode.chromaDistortion = bestChromaDist;
interMode.distortion += bestChromaDist;
}
//记录energy
if (m_rdCost.m_psyRd)
interMode.psyEnergy = m_rdCost.psyCost(sizeIdx, fencYuv->m_buf[0], fencYuv->m_size, reconYuv->m_buf[0], reconYuv->m_size);
else if(m_rdCost.m_ssimRd)
interMode.ssimEnergy = m_quant.ssimDistortion(cu, fencYuv->m_buf[0], fencYuv->m_size, reconYuv->m_buf[0], reconYuv->m_size, cu.m_log2CUSize[0], TEXT_LUMA, 0);
interMode.resEnergy = primitives.cu[sizeIdx].sse_pp(fencYuv->m_buf[0], fencYuv->m_size, predYuv->m_buf[0], predYuv->m_size);
/*
记录interMode的totalBits/lumaDistortion/coeffBits/mvBits/distortion
*/
interMode.totalBits = bits;
interMode.lumaDistortion = bestLumaDist;
interMode.coeffBits = coeffBits;
interMode.mvBits = mvBits;
cu.m_distortion[0] = interMode.distortion;
//更新interMode的rdcost
updateModeCost(interMode);
checkDQP(interMode, cuGeom);
}【源码】Search:: estimateResidualQT
用于计算当前预测模式下残差的 失真cost,比特cost。得到 rd-cost,以及量化编码。
调用流程:
Analysis::compressInterCU_rd0_4 -> 在 rd 级别 0到4结果 Merge/Skip、AMVP 运动估计补偿等等操作之后,会判断当前模式是否最优
Search::encodeResAndCalcRdInterCU -> 判断当前 Skip 模式是否最优,计算 rd-cost 量化、编码等
Search::encodeResAndCalcRdSkipCU -> 判断当前 Inter 模式是否最优(注意当前Inter模式也是一系列Inter模式选出来的最优Inter),计算 rd-cost 量化、编码等。
Search:: estimateResidualQT -> 当前模式,失真代价、比特代价,量化、编码入口。
源码流程:
1.检查不做TU划分
1.调用transQuant进行LUMA的变换和量化,返回非0系数个数
2.记录cbf
3.调用codeCoeffNxN编码系数,记录bits(视上下文可能需要编码codeTransformSubdivFlag)
4.如果有非0系数,
1.调用InvTransQuant进行反量化和反变换,再重建记录到m_aRqtData[u32QtLayer].m_cRecYuv
2.算SSE,再算rdcost
3.再算如果量化成全0时的SSE和bits,算rdcost,决定是否要量化为全0
5.如果是全0,算rdcost,此时bits只有编码cbf为0的开销
6.类似方式处理UV
7.算出YUV整体的bits和distortion,算出rdcost
8.如果m_pParam->limitTU,检查是否要限制不再划分TU
2.如果可以划分TU
1.先做熵编码环境的保存和恢复
2.算编码splitflag的开销
3.调用splitTU测试划分TU,返回bTotalCbf



![Numpy入门[17]——数组广播机制](https://img-blog.csdnimg.cn/4283925b156f4fb9b123ead14e10073f.png)



![[附源码]Python计算机毕业设计Django框架的资产管理系统设计与实现](https://img-blog.csdnimg.cn/cd497e7d75fe42c2aead197392c16eef.png)
![[附源码]Python计算机毕业设计SSM京津冀区域产学研项目管理信息系统(程序+LW)](https://img-blog.csdnimg.cn/b8ce38ee822940c4af0211c39b52e157.png)