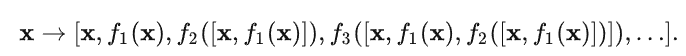一、介绍
文本分类系统,使用Python作为主要开发语言,通过TensorFlow搭建CNN卷积神经网络对十余种不同种类的文本数据集进行训练,最后得到一个h5格式的本地模型文件,然后采用Django开发网页界面,实现用户在界面中输入一段文字,识别其所属的文本种类。
在我们的日常生活和工作中,文本数据无处不在。它们来自各种来源,包括社交媒体、新闻文章、客户反馈、科研论文等。随着大数据和人工智能技术的不断发展,如何从庞大的文本数据中提取有用的信息,识别文本的种类,成为了当前数据处理领域的一个热门课题。我们很高兴向大家介绍一个全新的文本分类系统,它将深度学习技术、Python语言与网页应用开发融为一体,以用户友好的方式提供精确的文本分类服务。
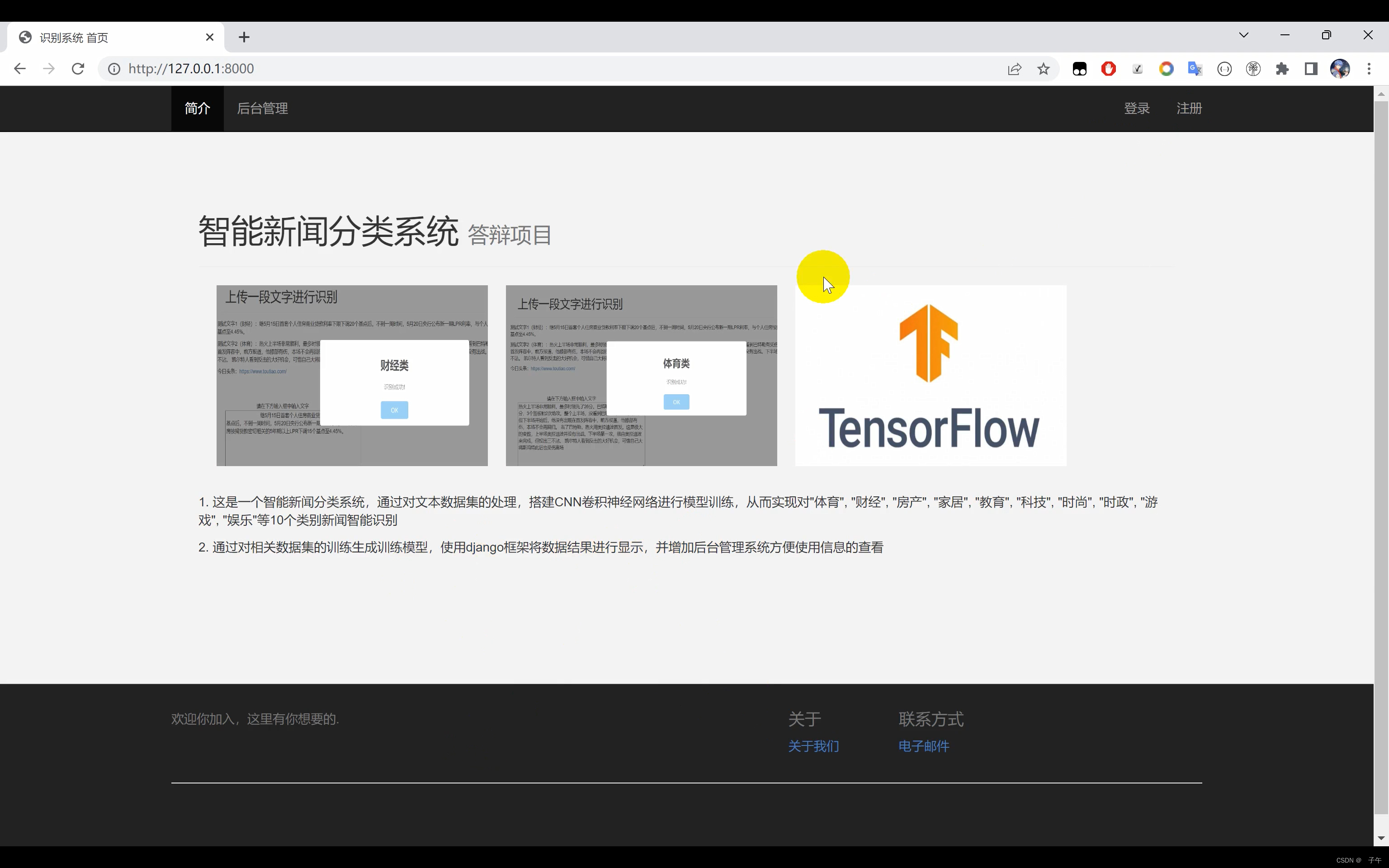
二、效果展示
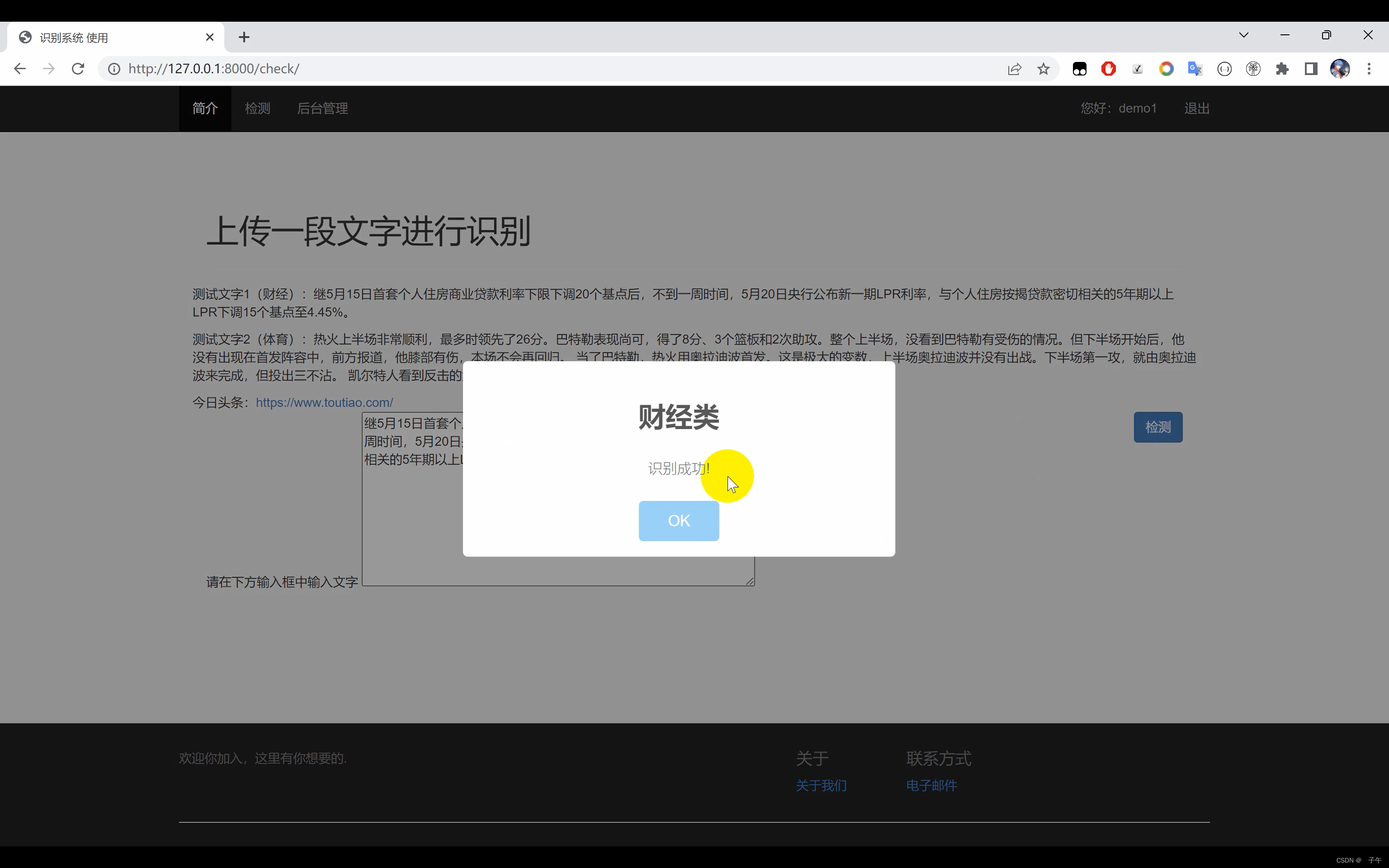
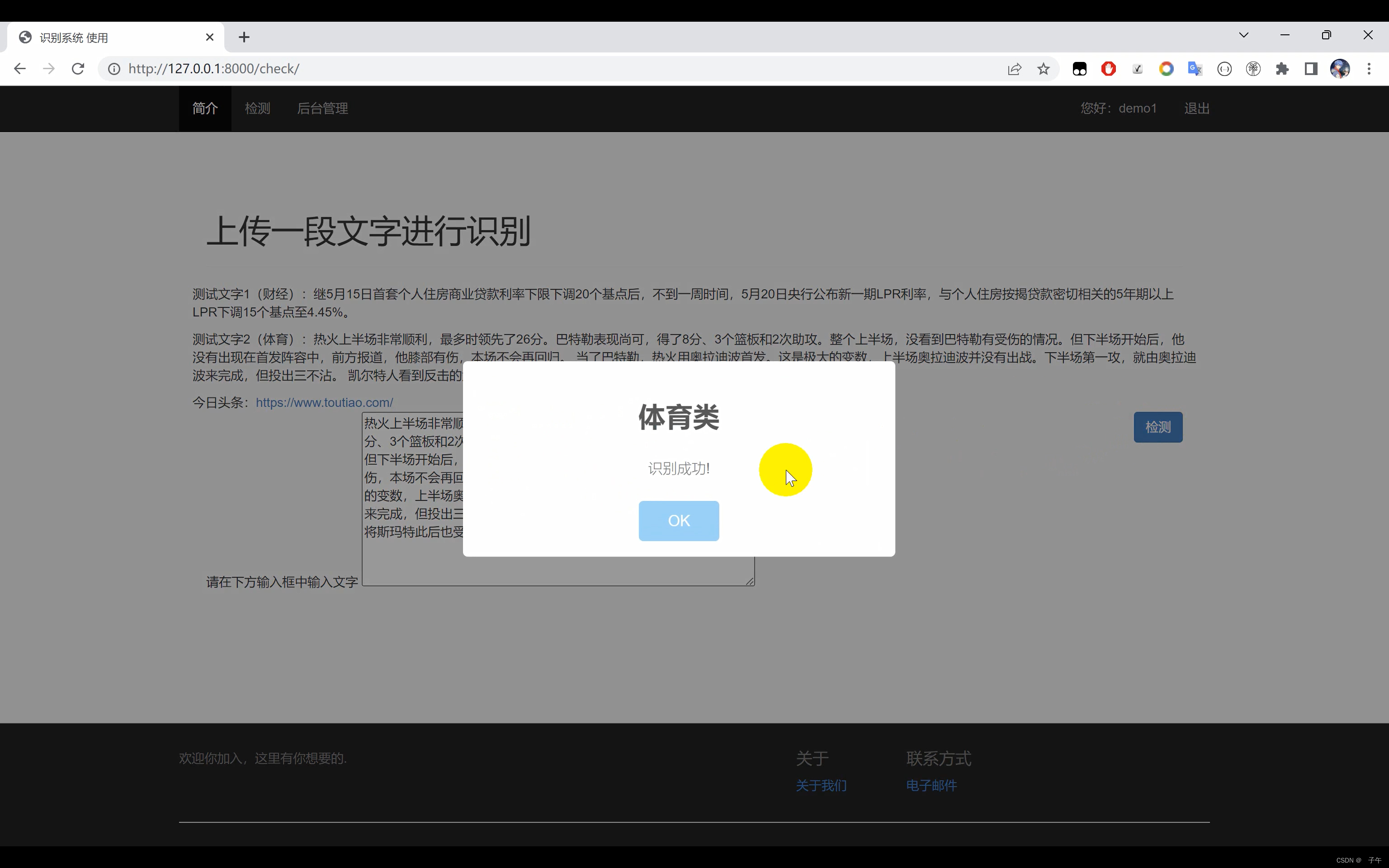
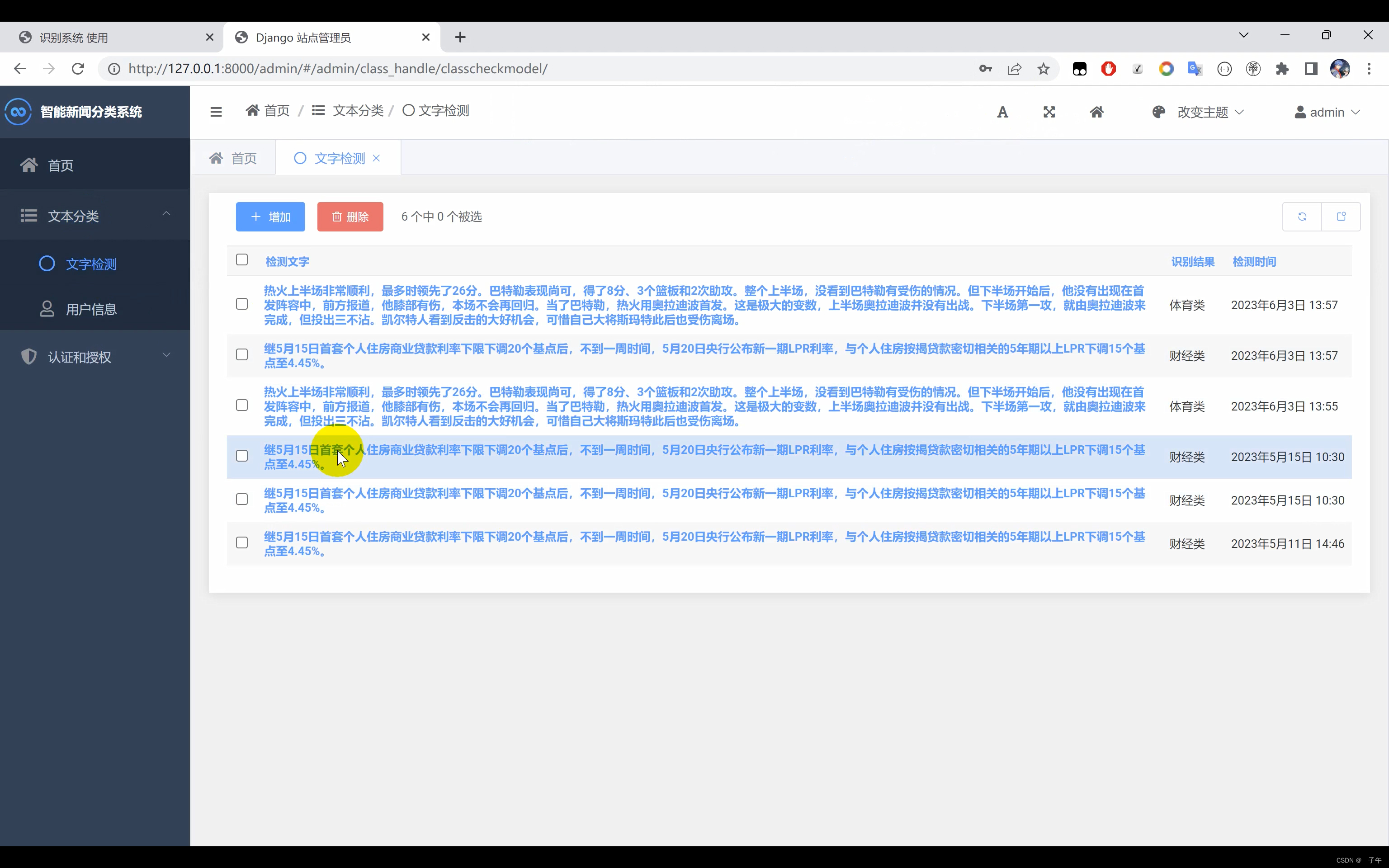
三、演示视频+代码
视频+代码:https://www.yuque.com/ziwu/yygu3z/dm2c902i8cckeayy
四、主要功能
这个系统的核心是一个基于卷积神经网络(CNN)的深度学习模型,通过TensorFlow框架搭建而成。我们知道,CNN是一种强大的模型,最初用于图像识别,但近年来在自然语言处理领域也展现了惊人的性能。我们的系统训练了一个CNN模型,通过对十余种不同种类的文本数据集进行学习,最后得到了一个h5格式的本地模型文件,它可以准确地识别输入文本的种类。
我们选择Python作为主要的开发语言,不仅因为Python的简洁、易学和丰富的开源库,更因为Python在数据科学和机器学习领域的广泛应用。使用Python,我们能更高效地开发和维护系统,同时也能让更多的开发者参与到我们的项目中来。
为了让用户能更方便地使用我们的文本分类系统,我们利用Django开发了一个网页界面。Django是一款开源的Web开发框架,能够帮助我们快速构建高质量的Web应用。在我们的系统中,用户可以在界面中输入一段文字,系统会立即返回该段文字的分类结果。无论你是数据科学家需要处理大量文本数据,还是一位普通用户想要了解你的文本可能属于哪个类别,我们的系统都能为你提供方便、快捷的服务。
通过文本分类系统不仅能够提供精确的分类结果,还具有极高的可扩展性。我们的系统设计师希望这个系统能适应未来的需求,因此在设计时充分考虑了模块化和组件化。这意味着我们的系统可以轻松地添加新的文本种类,或者用新的模型替换现有的模型。这样,无论未来的需求如何变化,我们的系统都能轻松应对。
综上所述,这个全新的文本分类系统是一个将深度学习技术、Python语言和Web应用开发结合在一起的高级工具。它不仅能帮助我们处理和理解海量的文本数据,也为我们打开了新的可能性。如果你有处理文本数据的需求,或者对新的技术感兴趣,欢迎来试用我们的系统。我们相信,你会发现它是一个强大而有用的工具。
五、示例代码
这是一个基本的示例,描述了如何使用Python和TensorFlow训练一个CNN模型进行文本分类,并使用Django创建一个网页应用来使用这个模型。
- 使用TensorFlow训练一个CNN模型:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 假设我们有一些训练数据
texts = [...] # 输入文本数据
labels = [...] # 输入文本对应的类别
# 设置词汇表大小和序列长度
vocab_size = 10000
sequence_length = 100
# 使用Tokenizer进行文本预处理
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
data = pad_sequences(sequences, maxlen=sequence_length)
# 创建CNN模型
model = Sequential()
model.add(Embedding(vocab_size, 128, input_length=sequence_length))
model.add(Conv1D(128, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(10, activation='softmax')) # 假设我们有10个文本类别
# 编译并训练模型
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(data, labels, epochs=10, validation_split=0.2)
# 保存模型
model.save('text_classification_model.h5')
- 使用Django创建一个Web应用:
首先,你需要在你的Django项目中创建一个新的app。然后,在views.py文件中,你可以加载你的模型并创建一个视图来处理用户的输入。
from django.shortcuts import render
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 加载模型
model = load_model('text_classification_model.h5')
def classify_text(request):
if request.method == 'POST':
text = request.POST['text']
# 对文本进行预处理
sequences = tokenizer.texts_to_sequences([text])
data = pad_sequences(sequences, maxlen=sequence_length)
# 预测文本类别
prediction = model.predict(data)
label = prediction.argmax(axis=-1)
return render(request, 'classification_result.html', {'label': label})
return render(request, 'classify_text.html')
在这个视图中,我们首先检查请求是否是POST请求。如果是,我们从请求中获取用户输入的文本,对其进行预处理,并使用我们的模型进行预测。最后,我们返回一个页面,显示预测的文本类别。
然后,你需要在urls.py文件中添加一个URL模式,以便用户可以访问这个视图:
from django.urls import path
from . import views
urlpatterns = [
path('classify-text/', views.classify_text, name='classify_text'),
]