分类目录:《自然语言处理从入门到应用》总目录
与文本分类问题不同,在结构预测问题中,输出类别之间具有较强的相互关联性。例如,在词性标注任务中,一句话中不同词的词性之间往往相互影响,如副词之后往往出现动词或形容词,形容词之后往往跟着名词等。结构预测任务通常是自然语言处理独有的。下面介绍三种典型的结构预测问题——序列标注、序列分割和图结构生成。
序列标注
所谓序列标注(Sequence Labeling),指的是为输入文本序列中的每个词标注相应的标签,如词性标注是为每个词标注一个词性标签,包括名词、动词和形容词等。其中,输入词和输出标签数目相同且一一对应。下图展示了一个序列标注(词性标注)示例。序列标注问题可以简单地看成多个独立的文本分类问题,即针对每个词提取特征,然后进行标签分类,并不考虑输出标签之间的关系。《深入理解机器学习——概率图模型(Probabilistic Graphical Model):条件随机场(Conditional Random Field,CRF)》中介绍的条件随机场模型是一种被广泛应用的序列标注模型,其不但考虑了每个词属于某一标签的概率(发射概率),还考虑了标签之间的相互关系(转移概率)。我们将要介绍的循环神经网络模型也隐含地建模了标签之间的相互关系,为了进一步提高准确率,也可以在循环神经网络之上再使用条件随机场模型。

序列分割
除了序列标注问题,还有很多自然语言处理问题可以被建模为序列分割问题,如分词问题,就是将字符序列切分成若干连续的子序列;命名实体识别问题,也是在文本序列中切分出子序列,并为每个子序列赋予一个实体的类别,如人名、地名和机构名等。可以使用专门的序列分割模型对这些问题进行建模,不过为了简化,往往将它们转换为序列标注任务统一加以解决。如命名实体识别,序列标注的输出标签可以为一个实体的开始(B-XXX)、中间(I-XXX)或者非实体(O)等,其中B代表开始(Begin)、I代表中间(Inside),O代表其他(Other),XXX代表实体的类型,如人名(PER)、地名(LOC)和机构名(ORG)等。分词问题也可以转换为序列标注问题,即为每个字符标注一个标签,指明该字符是一个词的开始(B)或者中间(I)等。下图展示了使用序列标注方法解决序列分割(分词和命名实体识别)问题示例。其中,对于输入:“我爱北京天安门。”分词输出结果是:“我爱北京天安门。”命名实体识别输出结果是:“北京天安门=LOC”。

图结构生成
图结构生成也是自然语言处理特有的一类结构预测问题,顾名思义,其输入是自然语言,输出结果是一个以图表示的结构。图中的节点既可以来自原始输入,也可以是新生成的;边连接了两个节点,并可以赋予相应的类型。《自然语言处理从入门到应用——自然语言处理的基础任务:词性标注(POS Tagging)和句法分析(Syntactic Parsing)》中介绍的句法分析就是典型的图结构生成问题,其中,在依存分析中,节点皆为原始输入的词,而边则连接了有句法关系的两个词,然后在其上标注句法关系类别。此外,还可以对输出的图结构进行一定的约束,如需要为树结构(一种特殊的图结构,要求每个节点有且只有一个父节点)等。在短语结构句法分析中,除了原始输入词作为终结节点,还需要新生成词性以及短语类型节点作为非终结节点,然后,使用边将这些节点相连,并最终形成树结构。不过,树结构也不是必要的限制,如在《自然语言处理从入门到应用——自然语言处理的基础任务:词性标注(POS Tagging)和句法分析(Syntactic Parsing)》中介绍的语义依存图分析中,结果就不必是一棵树,而可以是更灵活的图结构。
图结构生成算法主要包括两大类:
- 基于图(Graph-based)的算法:首先为图中任意两个节点(输入的词)构成的边赋予一定的分数,算法的目标是求解出一个满足约束的分数最大的子图,其中,子图的分数可以简单看作所有边的分数和,如果要求输出结果满足树结构的约束,则需要使用最大生成树(Maximum Spanning Tree,MST)算法进行解码。除了解码算法,基于图的算法还需要解决如何为边打分以及参数如何优化等问题,本文不进行详细的阐述,感兴趣的读者可以查阅相关参考资料。
- 基于转移(Transition-based)的算法:将图结构的构建过程转化为一个状态转移序列,通过转移动作,从一个旧的状态转移到新的状态,也就是说转移动作是状态向前前进一步的方式,体现了状态变化的策略,转移动作的选择本质上就是一个分类问题,其分类器的特征从当前的状态中加以提取。
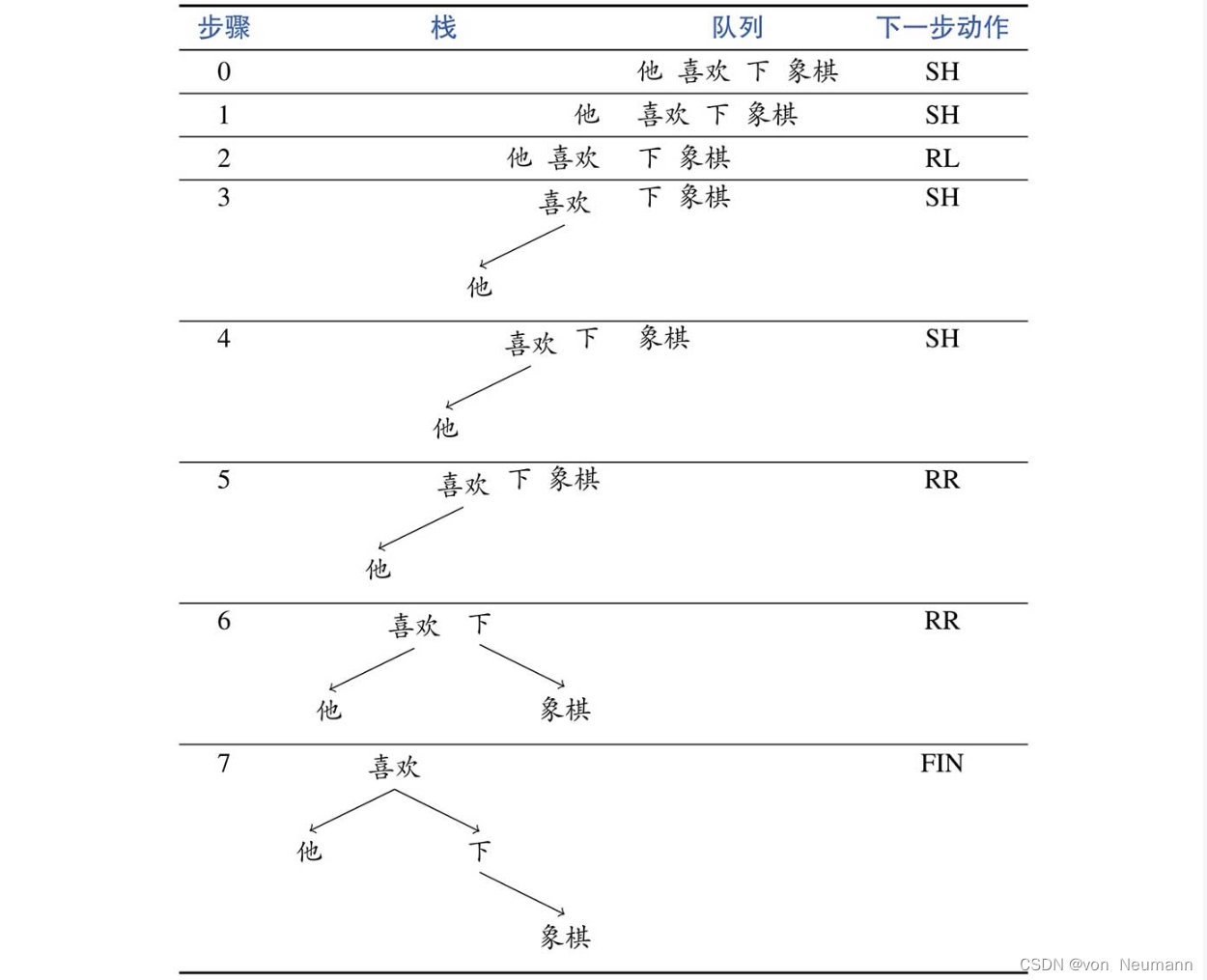
首先,来看如何使用基于转移的算法解决依存句法分析问题。在此以一种非常简单的标准弧(Arc-standard)转移算法为例,转移状态由一个栈(Stack)和一个队列(Queue)构成,栈中存储的是依存结构子树序列 S m ⋯ S 1 S 0 S_m\cdots S_1S_0 Sm⋯S1S0,队列中存储的是未处理的词 Q 0 Q 1 ⋯ Q n Q_0Q_1\cdots Q_n Q0Q1⋯Qn。在初始转移状态中,栈为空,句子当中的所有词有序地填入队列中;在结束转移状态中,栈中存储着一棵完整的依存结构句法分析树,队列为空。另外,算法定义了以下三种转移动作,分别为移进(Shift,SH)、左弧归约(Reduce-Left,RL)和右弧归约(Reduce-Right,RR),具体含义如下:
- SH,将队列中的第一个元素移入栈顶,形成一个仅包含一个节点的依存子树
- RL,将栈顶的两棵依存子树采用一个左弧 S 1 ↶ S 0 S_1↶S_0 S1↶S0进行合并,然后 S 1 S_1 S1下栈
- RR,将栈顶的两棵依存子树采用一个右弧 S 1 ↷ S 0 S_1↷S_0 S1↷S0进行合并,然后 S 0 S_0 S0下栈
下图展示了面向依存句法分析的标准弧转移算法中的三种动作。除了以上三个动作,还定义了一个特殊的完成动作(Finish,FIN)。根据上述的定义,可以使用下图中的动作序列逐步生成《自然语言处理从入门到应用——自然语言处理的基础任务:词性标注(POS Tagging)和句法分析(Syntactic Parsing)》中的依存结构句法树。弧上的句法关系可以在生成弧的时候(采用RL或RR动作),使用额外的句法关系分类器加以预测。

基于转移算法的短语结构句法分析方法过程也类似,只不过栈中存储的是短语结构句法子树序列,队列中同样存储的是未被处理的词。在此不再赘述。
参考文献:
[1] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[2] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[3] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[4] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[5] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.







![[SWPUCTF 2021 新生赛] (WEB二)](https://img-blog.csdnimg.cn/e03adf14e854418ca911ab8fd39a27f0.png)